







作者:后端小肥肠
🍊 有疑问可私信或评论区联系我。
🥑 创作不易未经允许严禁转载。
姊妹篇:
Coze实战:《如果书籍会说话》保姆级教程!全流程拆解(附源码)-CSDN博客
10w+爆文一键生成:Coze文案号PLUS工作流拆解-CSDN博客
用Coze打造内容自动化工作流:公众号一键转小红书图文实战-CSDN博客
Coze+TreeMind实测:秒出ISO标准流程图/脑图(附完整提示词)_coze怎么基于网络和知识库生成知识图谱-CSDN博客
目录
1. 前言
这两天有个朋友和我说想要一个一键生成打字机效果书单视频的Coze工作流,我找了一下市面上的工作流,寥寥无几。找到了几个效果也不好,全程一张图贯穿整个视频。于是我用半天时间搭了一个工作流,先看一下效果:

我将这个工作流发布成了应用,感兴趣的朋友可以直接体验:
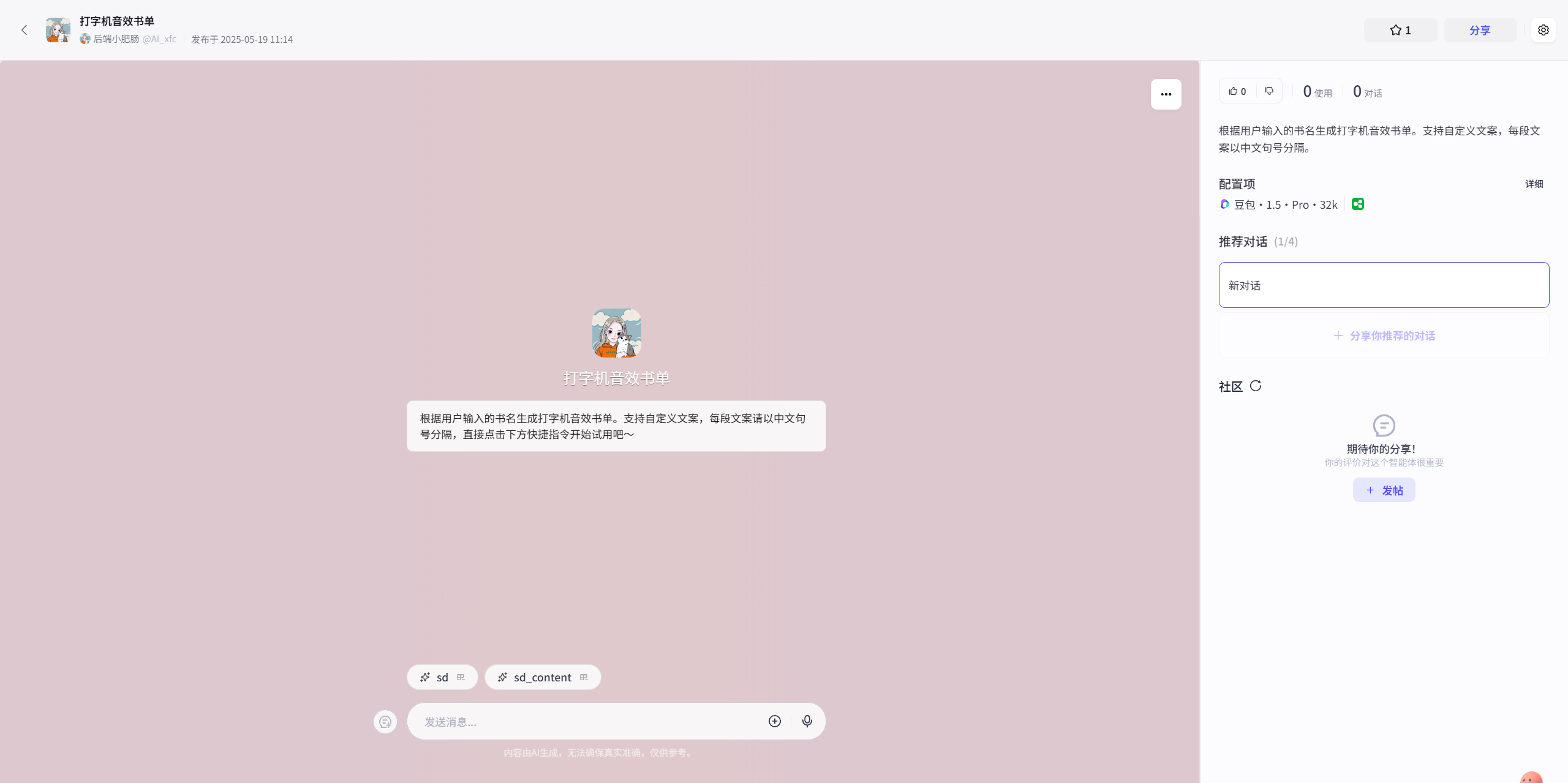
这个工作流支持输入书名一键生成打字机音效书单,也可以由用户自定义文案和书名生成书单视频。
2. 工作流设计
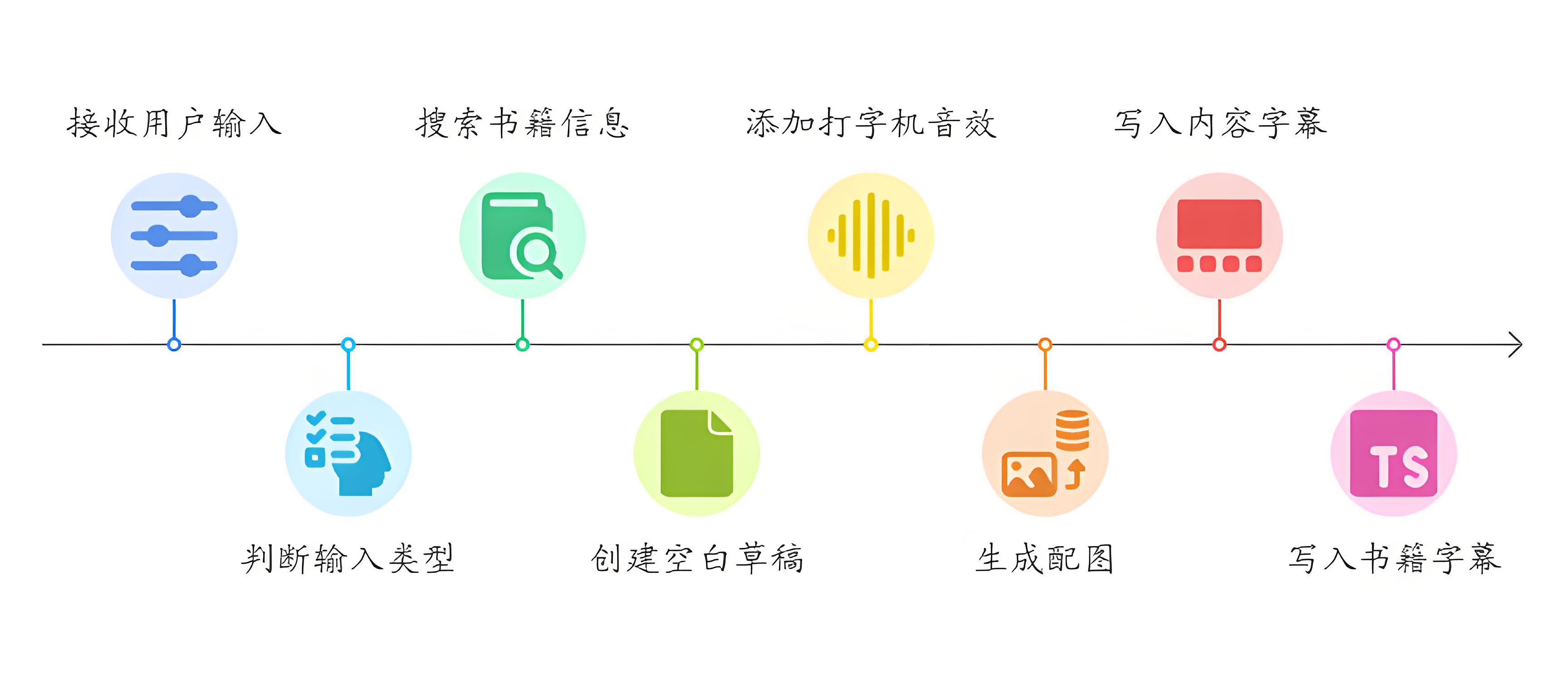
在工作流实现之前,我们需要梳理一下工作流的视线逻辑:
1. 接收用户输入参入;
2. 判断用户输入参数,如果仅仅为书名则基于大模型提炼书中的经典段落,作为书单视频的内容字幕;如果用户输入了自定义书籍内容和书名,则处理用户输入的内容(基于句号分割),作为书单视频的内容字幕;
3. 通过图书搜索插件搜索书籍的标题和作者,作为书单视频的书名字幕;
4. 新建空白草稿;
5. 基于内容字幕分割打字机音效.MP3,写入草稿;
6. 基于内容字幕生成配图,写入草稿;
7. 将内容字幕写入草稿;
8.将书籍字幕写入草稿。
3. 工作流实现
本章节还是按照惯例,会给大家介绍工作流实现的核心节点,完整工作流如下:

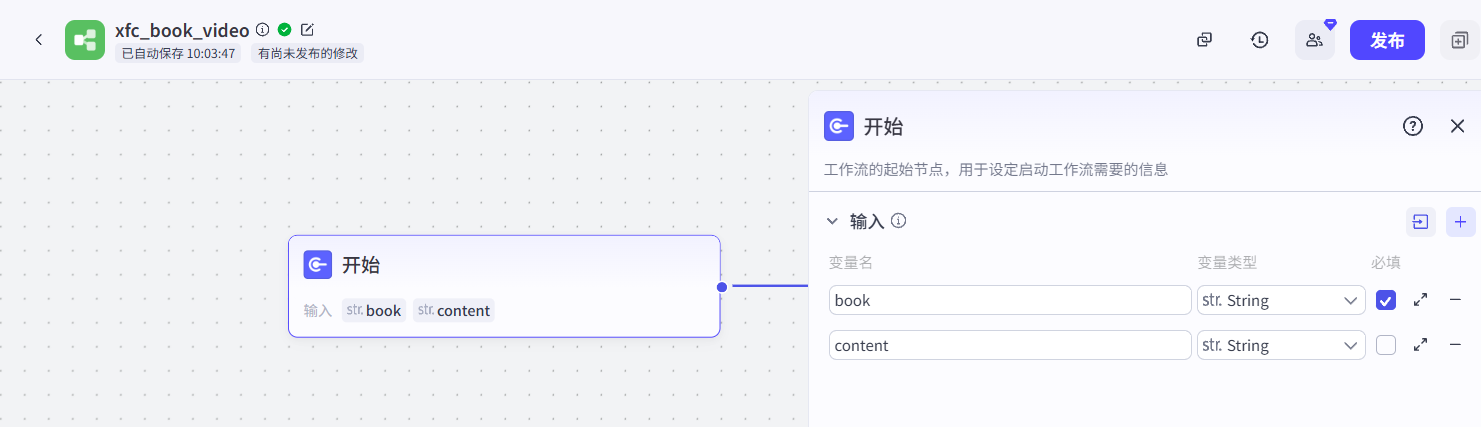
开始节点:开始节点有两个参数,分别为book(书名,这个是必填的);还有一个参数是content(自定义文案,如果你不想要大模型从书籍中提取经典文案,可以自定义输入)。
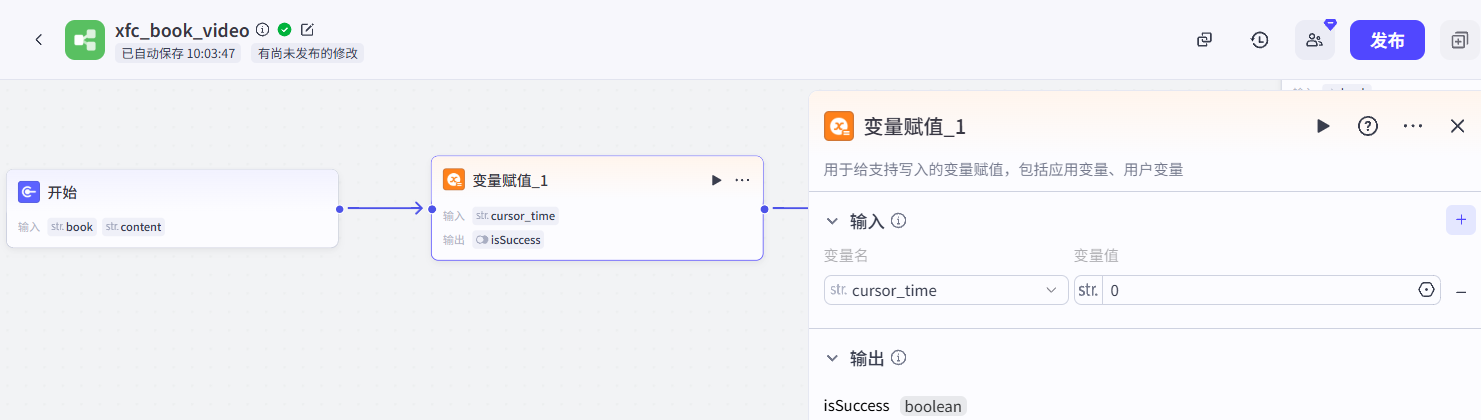
变量赋值: 这个节点的的作用是记录视频播放时的时间游标,我们需要根据这个时间游标进行分段视频的制作,下一个分段的起始时间是上一个分段的结束时间。
书籍内容处理:这一块的作用是判断用户是否输入了自定义文案,如果输入了自定义文案,则基于句号将用户自定义文案转换为字符串数组,否则基于大模型提取书籍经典句子输出到字符串数组。
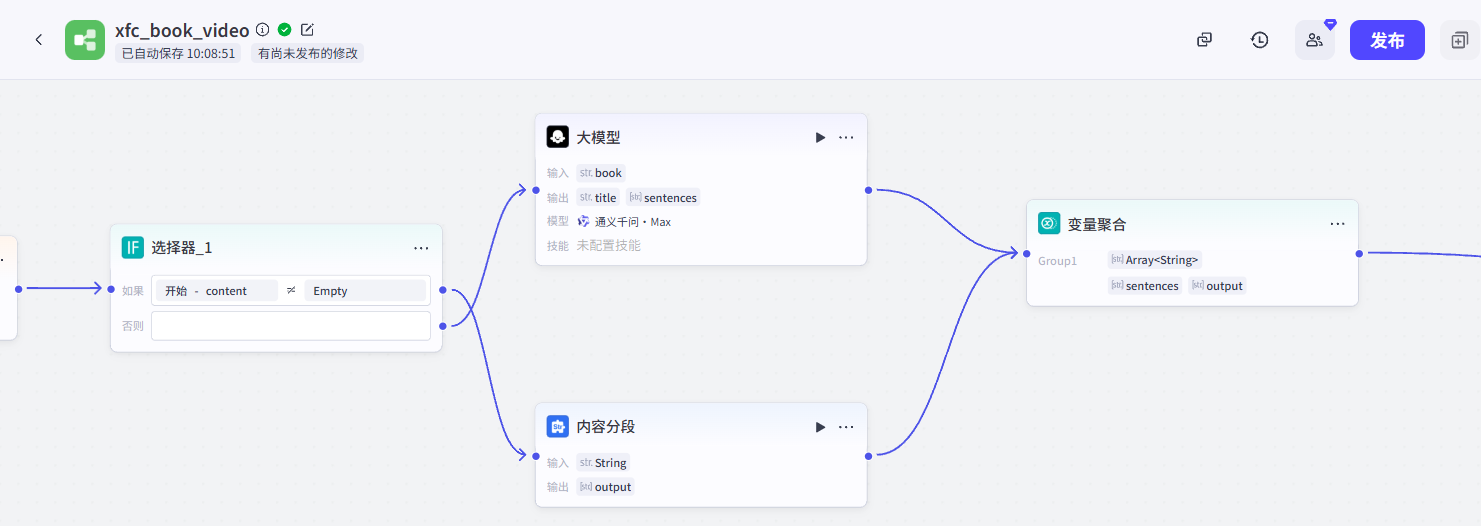
根据书籍分段内容生成文生图提示词(大模型):这个节点的作用是根据书籍分段内容生成文生图提示词。
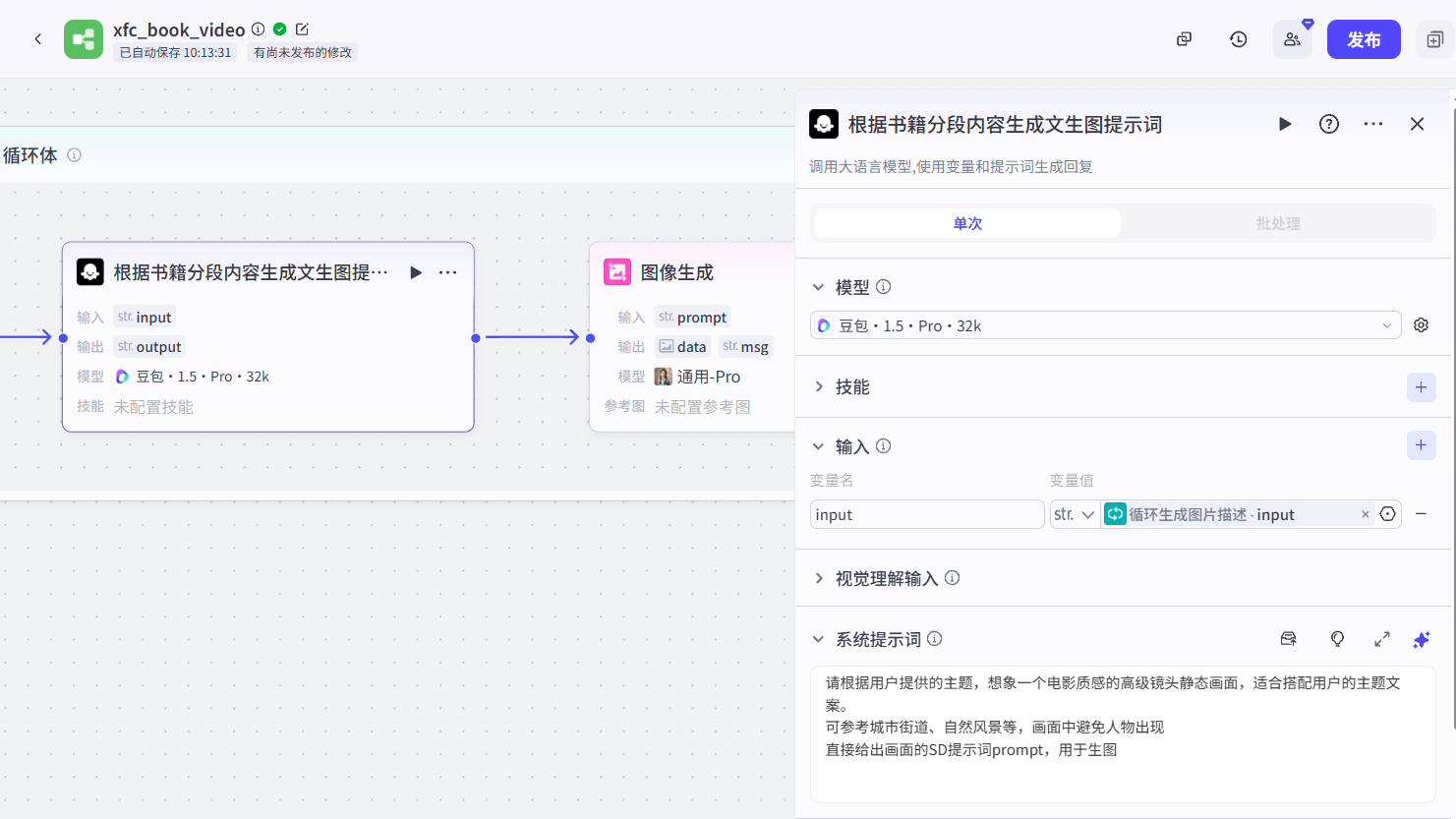
代码(组装数据):这个节点的作用是将前面节点生成的图片、内容、音频组装为剪映小助手需要的格式。
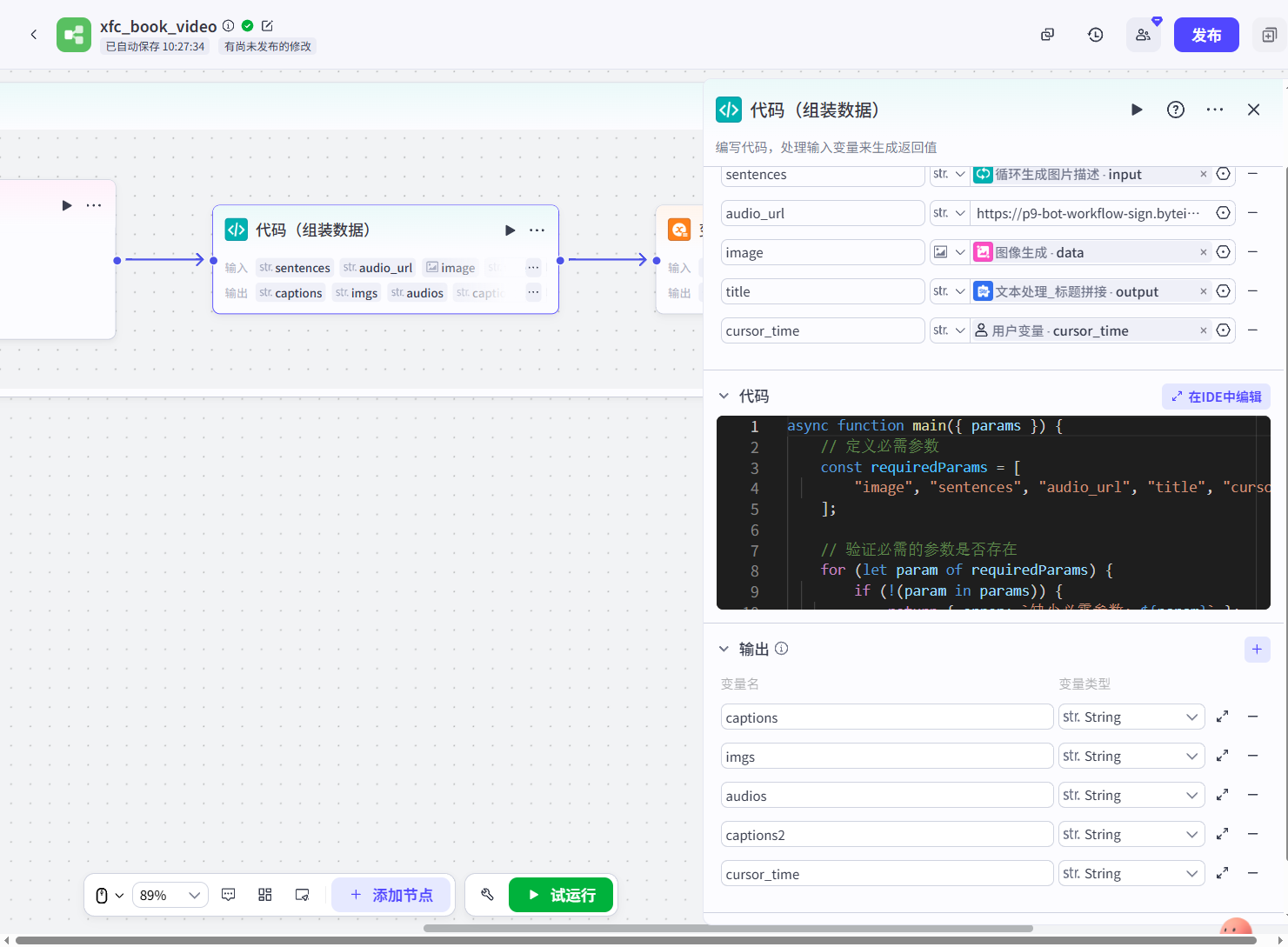
详细代码为:
async function main({ params }) {
// 定义必需参数
const requiredParams = [
"image", "sentences", "audio_url", "title", "cursor_time"
];
// 验证必需的参数是否存在
for (let param of requiredParams) {
if (!(param in params)) {
return { error: `缺少必需参数: ${param}` };
}
}
// 解析输入参数
let sentence = params.sentences; // 只处理单个句子
let audio_url = params.audio_url;
let title = params.title;
let image = params.image; // 只处理单个图片
let cursor_time = params.cursor_time; // 处理 cursor_time 参数
try {
// 如果 sentence 是字符串,保持它原样
if (typeof sentence === "string") {
sentence = sentence;
} else {
// 如果 sentence 是 JSON 字符串,尝试解析它
sentence = JSON.parse(sentence);
}
// 如果 audio_url 是字符串并且不是 JSON 格式,直接使用它;如果是 JSON 字符串,尝试解析
if (typeof audio_url === "string") {
try {
audio_url = JSON.parse(audio_url); // 尝试解析,如果它是有效的 JSON 字符串
} catch (e) {
audio_url = audio_url; // 如果它是 URL,保持为数组
}
}
} catch (e) {
return { error: `解析输入参数时出错: ${e.message}` };
}
// 将 cursor_time 转换为数字
let current_time = parseFloat(cursor_time); // 转换为浮动数字
let total_duration = 0;
// 初始化结果数组
const captions = [];
const audios = [];
const imgs = [];
let current_time_for_processing = current_time;
// 处理字幕
let chinese = sentence; // 单个句子
let duration = chinese.length * 0.2 * 1000 * 1000; // 按照句子长度计算时长
let end_time = current_time_for_processing + duration;
// 处理音频URL
let audio_duration = duration - 0.2 * 1000000;
audios.push({
audio_url: audio_url,
duration: audio_duration,
start: current_time_for_processing,
end: end_time - 0.5 * 1000000
});
// 处理字幕
captions.push({
text: chinese.replace(/([,。])(?=[^\n]*[,。])/, "$1\n"), // 字符串换行处理
start: current_time_for_processing,
end: end_time,
in_animation: "打字机IV",
in_animation_duration: duration,
out_animation: "渐隐"
});
// 更新当前时间
current_time_for_processing = end_time;
total_duration += duration;
let final_time = current_time_for_processing;
// 处理图片(只处理单个图片)
imgs.push({
image_url: image,
width: 768,
height: 1024,
start: current_time,
end: final_time,
in_animation: "展开",
in_animation_duration: 700000
});
// 标题处理
const captions2 = [{
text: title,
start: current_time,
end: final_time,
in_animation: "渐显",
out_animation: "渐隐"
}];
return {
captions: JSON.stringify(captions),
imgs: JSON.stringify(imgs),
audios: JSON.stringify(audios),
captions2: JSON.stringify(captions2),
cursor_time: final_time
};
}add_audios、add_audios、add_captions、add_captions_书名(插件):这些插件的作用都是将前面节点生成的内容写入到剪映小助手插件中,它们的输入参数是代码节点的输出参数。
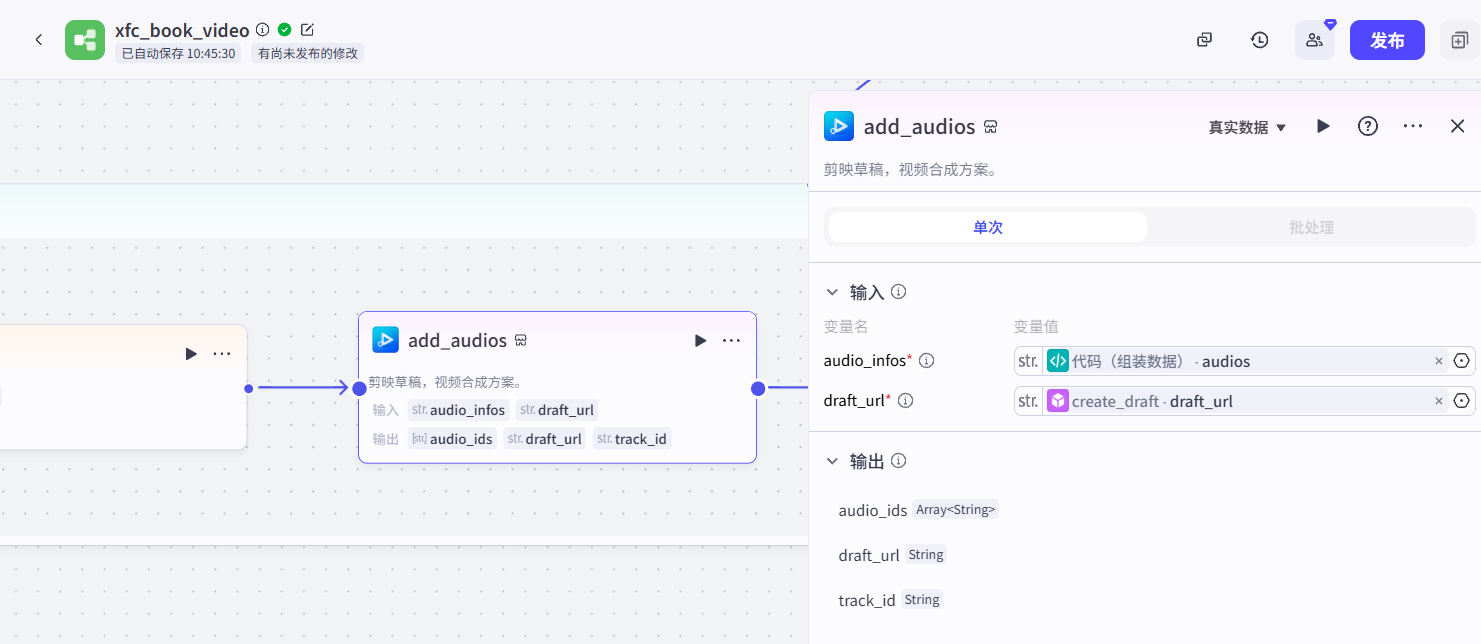
以上就是工作流的实现的完整拆解,大家可以跟着我做一下,有点基础的朋友很快就能搭起来。
4. 资料领取
你觉得大模型不好用,可能是你不会写提示词,小肥肠为你准备了海量提示词模板和DeepSeek相关教程,只需关注gzh后端小肥肠,点击底部【资源】菜单即可领取。
本文的工作流及提示词已经上传至coze空间,感兴趣的朋友可以私信小肥肠详细了解~
5. 结语
至此,这套打字机书单的工作流就完整拆解完毕了。其实实现并不复杂,关键在于对每一步逻辑的把控和内容生成的协调。对于内容创作者来说,这种自动化的能力,不仅提升了效率,还极大拓展了创作的表现力。我一直相信,工具只是手段,创意才是灵魂。希望这个工作流能为你带来一些灵感,不管你是想输出自己的阅读书单,还是打算做一套知识类短视频,它都可以作为一个高效起点。



















 3294
3294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











