







作者:后端小肥肠
🍊 有疑问可私信或评论区联系我。
🥑 创作不易未经允许严禁转载。
姊妹篇:
10w+爆文一键生成:Coze文案号PLUS工作流拆解-CSDN博客
用Coze打造内容自动化工作流:公众号一键转小红书图文实战-CSDN博客
Coze+TreeMind实测:秒出ISO标准流程图/脑图(附完整提示词)_coze怎么基于网络和知识库生成知识图谱-CSDN博客
目录
1. 前言
最近,一种新型的短视频形式在社交平台上引起了极大关注——《假如书籍会说话》。这类视频通过赋予书籍“生命”,让它们以动画形式与主持人互动,突破了传统的阅读方式,给观众带来了沉浸式的体验。

今天,我将带领大家进行一次全面的技术拆解,从素材准备到工作流实现,我将提供一个保姆级教程,帮助大家快速掌握这一工作流。无论你是视频制作初学者,还是有一定经验的创作者,都能在这篇文章中找到实用的技巧与方法,让我们一起探索这一创意视频背后的技术实现吧!
2. 效果展示及前期准备
2.1 效果展
效果如下面的视频截图所示:

2.2 素材准备
主持人(自己抠图,不喜欢这种风格就丢即梦里面改一下):

书(自己抠图,不喜欢这种风格就丢即梦里面改一下):

开场动画:
p3-bot-workflow-sign.byteimg.com
3. 工作流实现
整体工作流为两大部分,分别为开场白部分以及主持人和书籍的对话部分,完整工作流如下图所示:

3.1. 开场白工作流
开场白这部分的工作流就是视频开头的书籍出场部分,还是按照惯例来讲一下工作流的核心节点:
开始节点:开始节点的接收参数有book(书籍图片)、host(主持人图片)、background(背景图)、book_name(书名,这个视频将围绕这本书展开)、logo(视频作者名)、video(开场视频)、start(时间游标,这个时间游标是开场视频播放完后时间到来到的秒数、单位为微秒,图里为3500000,可以理解为视频开场视频播放完以后,时间来到了3.5秒,我们需要继续在3.5秒这个时间后面追加新内容,如书名,主持人和书籍的对白。)
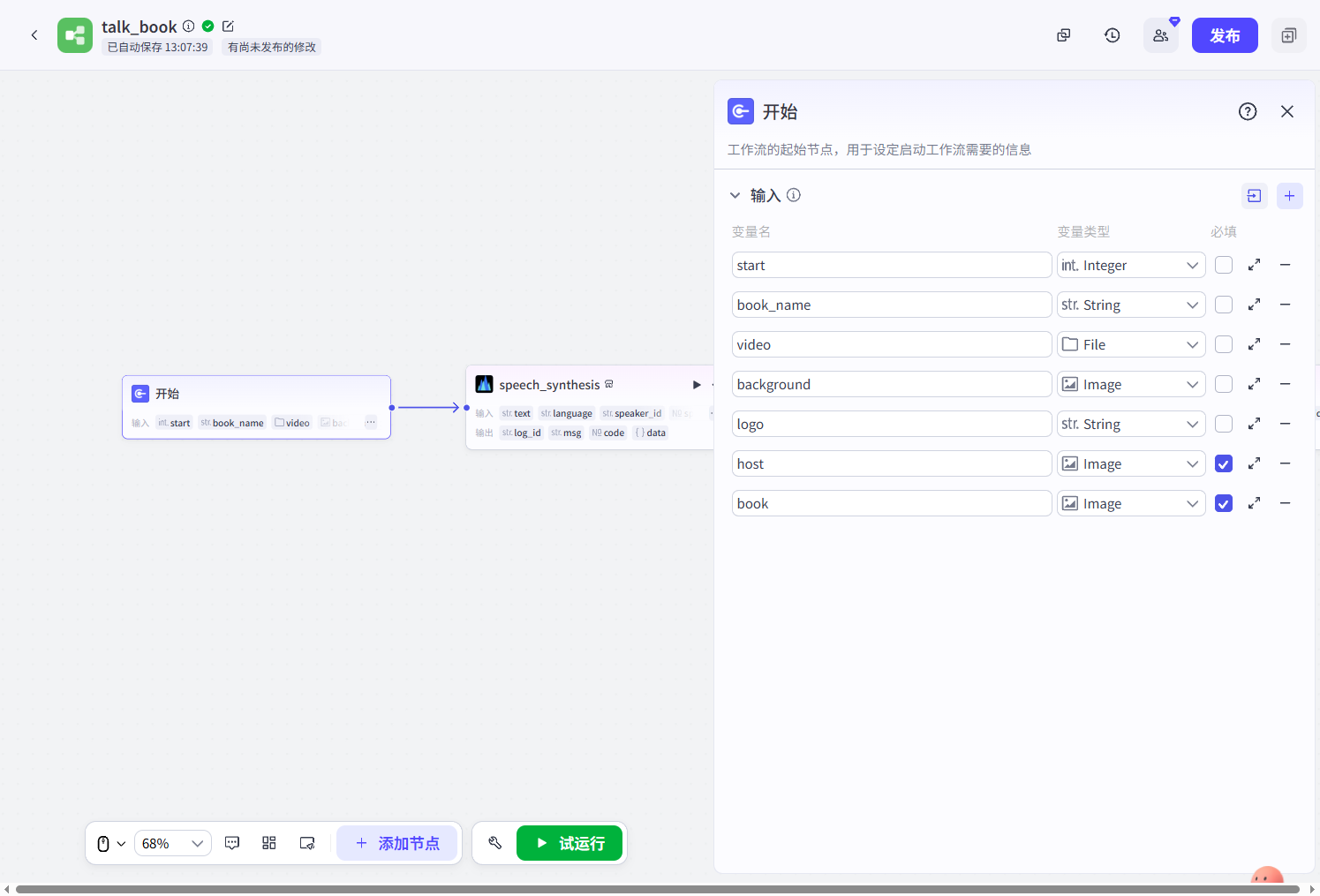
speech_synthesis(插件):这个插件主要是基于开始节点中的book_names生成音频,可以点击插件详情,修改音色和其他参数设置。
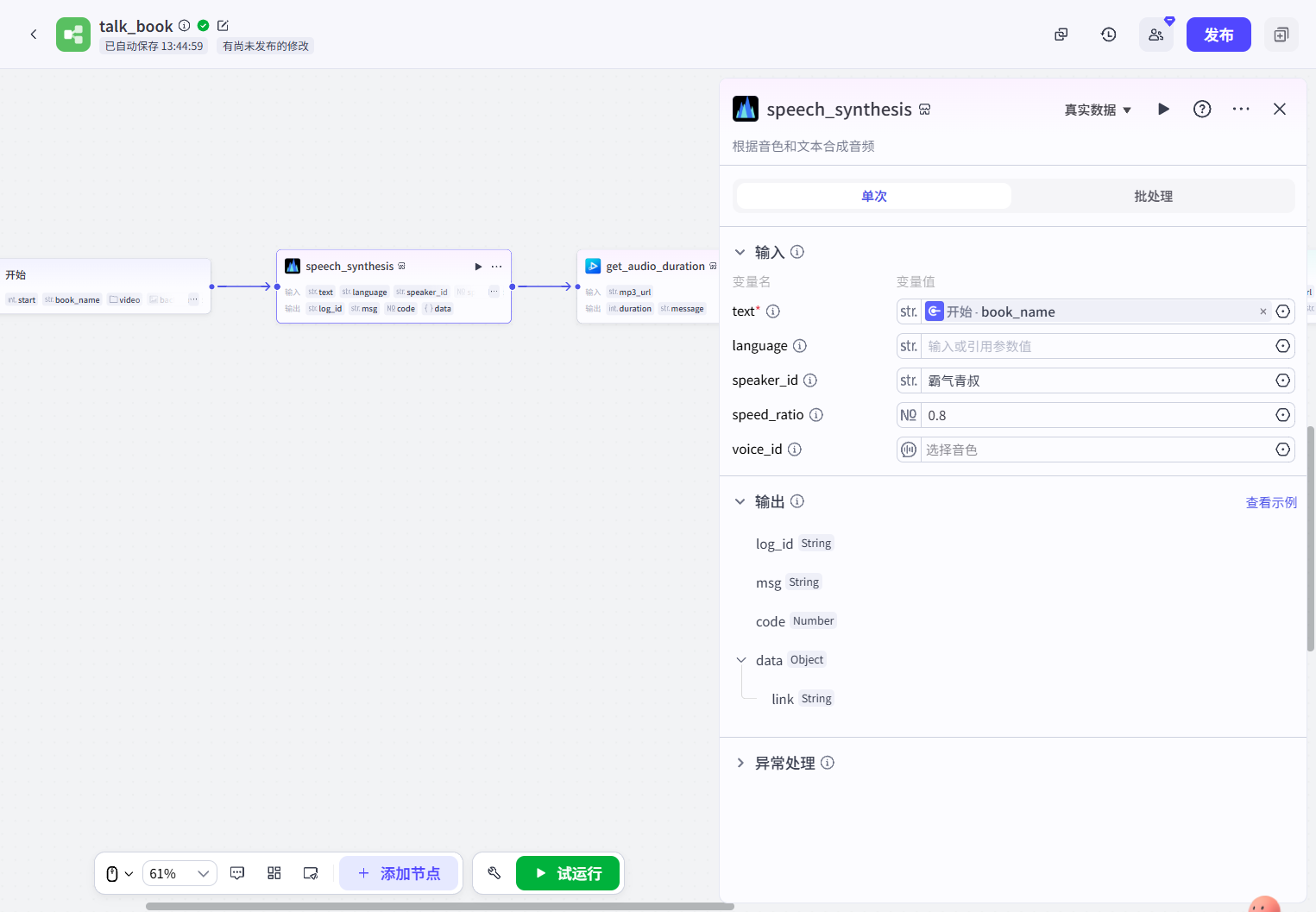
get_audio_duration(插件):获取朗读书名这段音频的时长。
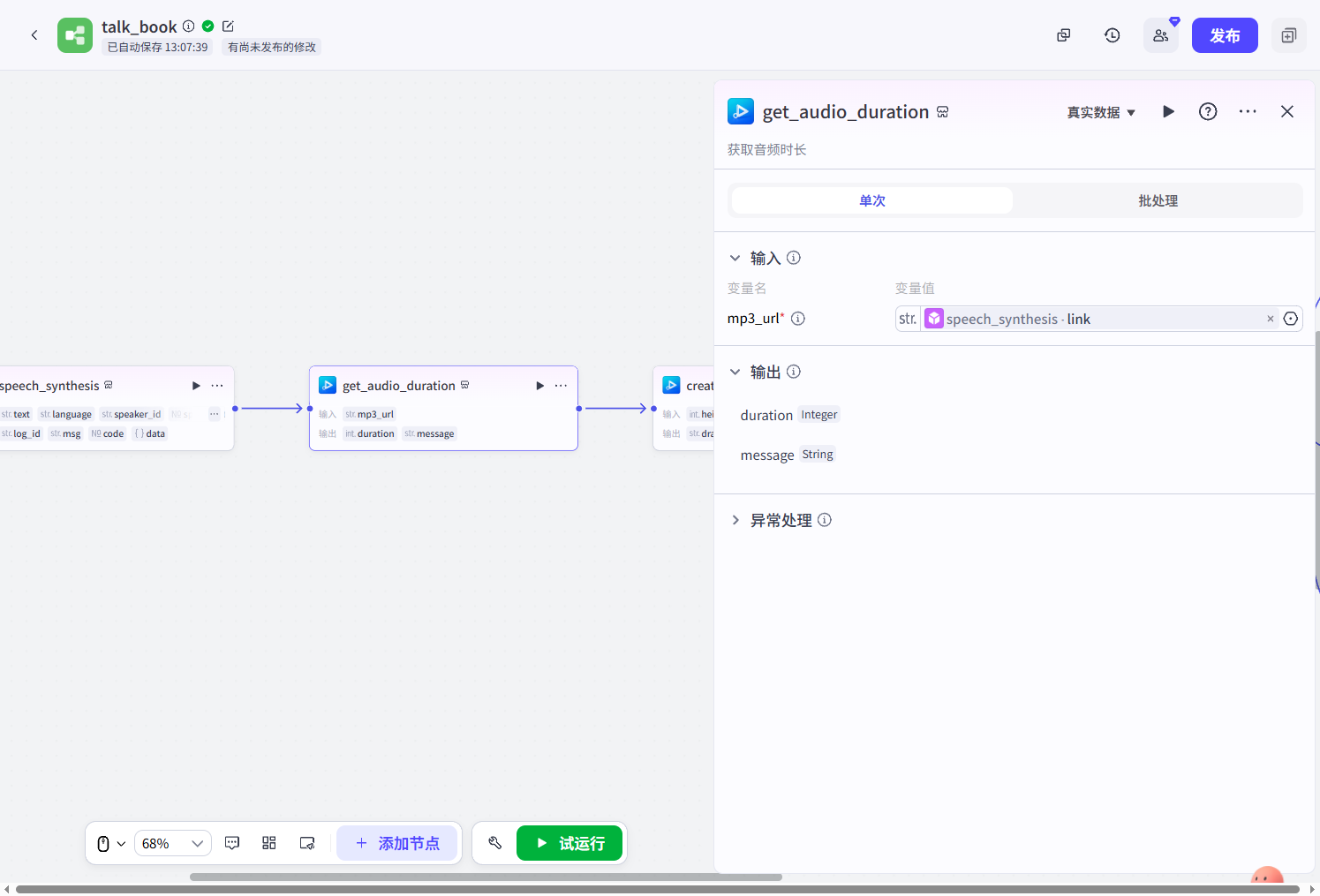
create_draft(插件):创建草稿,需要设置一下草稿视频的宽和高,我设置的是1920*1080。
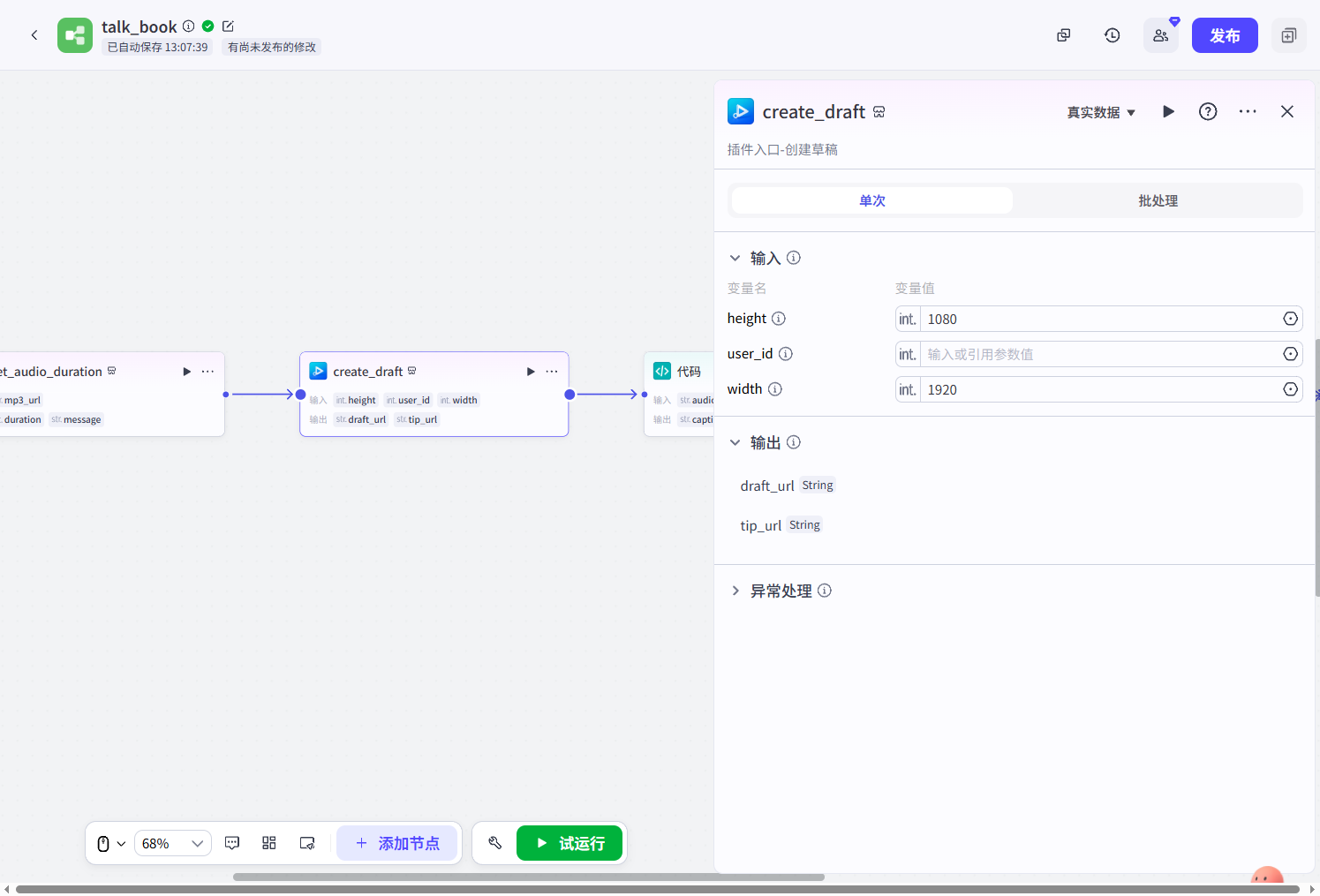
代码(组装数据):我们前置的参数,需要基于剪映小助手插件放入到剪映草稿中,我们就需要转换一下,将其转换为剪映小助手插件要求的输入格式,以下图的add_audios工具为例,我们需要传递给插件的参数为audio_infos和draft_url,audio_infos为一个json数组:
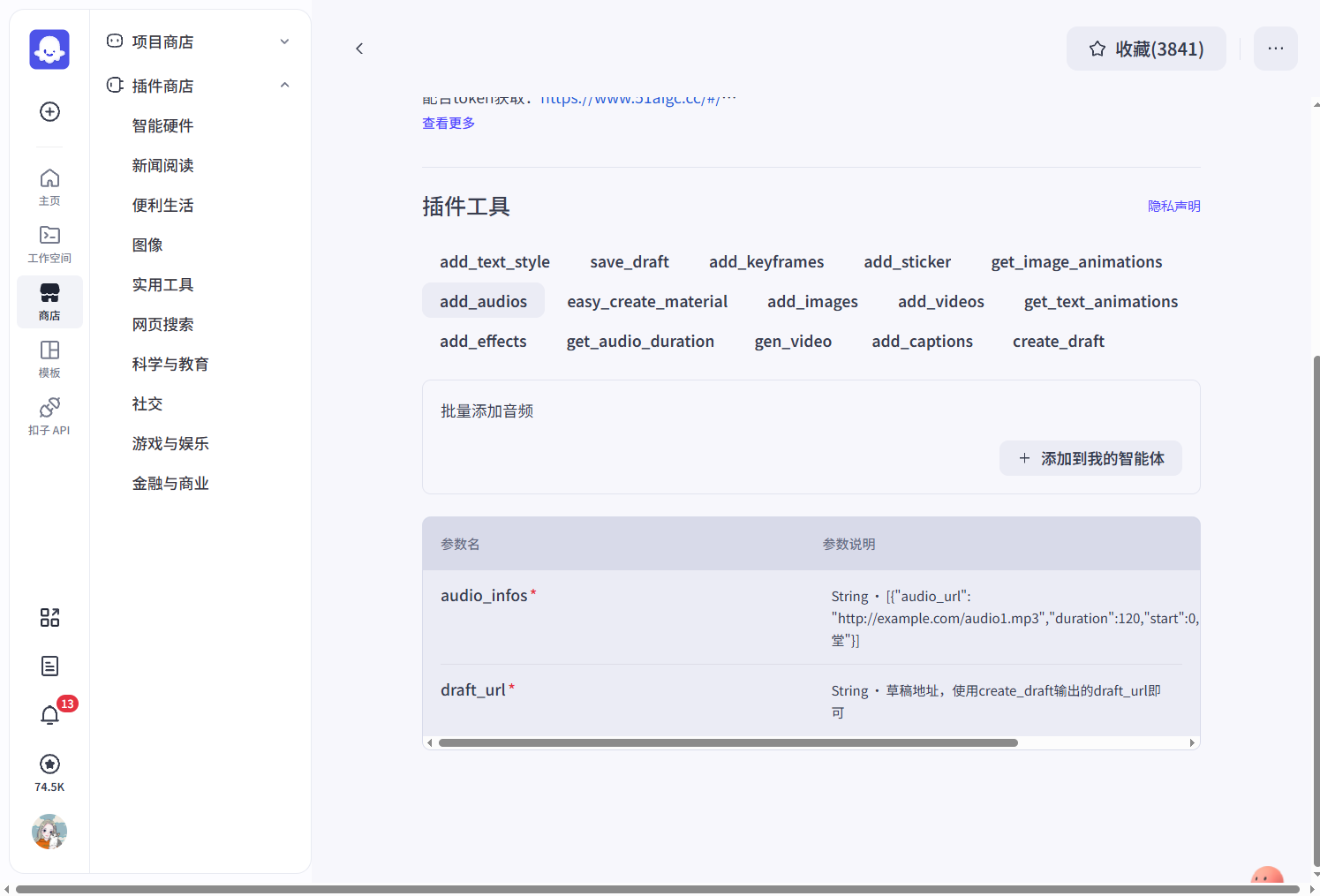
我们就需要基于一个代码节点将我们的前置参数转换为剪映小助手需要的格式,代码的输入参数为:
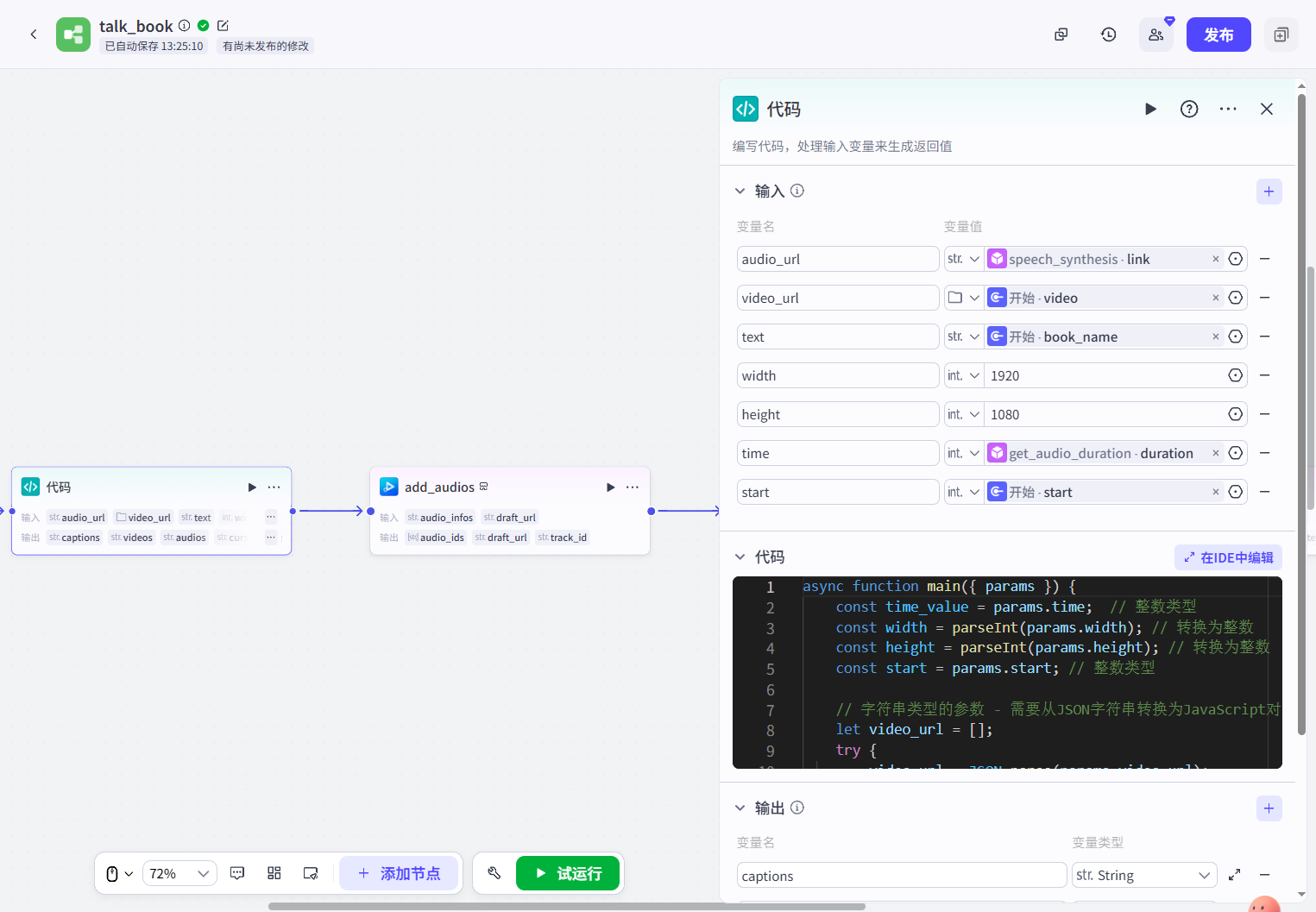
完整代码为:
async function main({ params }) {
const time_value = params.time; // 整数类型
const width = parseInt(params.width); // 转换为整数
const height = parseInt(params.height); // 转换为整数
const start = params.start; // 整数类型
// 字符串类型的参数 - 需要从JSON字符串转换为JavaScript对象
let video_url = [];
try {
video_url = JSON.parse(params.video_url);
} catch {
video_url = [params.video_url]; // 如果解析失败,假设它是单个URL字符串
}
let text = [];
try {
text = JSON.parse(params.text);
} catch {
text = [{ sentence: params.text }]; // 如果解析失败,假设它是单个文本字符串
}
let audio_url = [];
try {
audio_url = JSON.parse(params.audio_url);
} catch {
audio_url = [{ data: { link: params.audio_url } }]; // 如果解析失败,假设它是单个URL字符串
}
// 初始化结果数组
const captions = [];
const videos = [];
const audios = [];
let current_time = start;
let end_time = 0;
// 获取所有数组的最小长度,以防数组长度不一致
const data_length = Math.min(video_url.length, text.length, audio_url.length);
for (let idx = 0; idx < data_length; idx++) {
// 所有元素使用相同的时间长度
const duration = time_value; // 转为微秒
end_time = current_time + duration;
try {
// 获取音频URL
let audioLink = audio_url[idx];
if (audioLink && audioLink.data && audioLink.data.link) {
audioLink = audioLink.data.link;
} else {
audioLink = String(audio_url[idx]);
}
// 获取文本
let sentence = text[idx];
if (sentence && sentence.sentence) {
sentence = sentence.sentence;
} else {
sentence = String(text[idx]);
}
// 获取视频URL
const videoLink = String(video_url[idx]);
// 添加到结果数组
audios.push({
audio_url: audioLink,
duration: duration,
start: current_time,
end: end_time
});
captions.push({
text: sentence,
start: current_time,
end: end_time,
in_animation: "放大",
in_animation_duration: 500000,
loop_animation: "颤抖",
loop_animation_duration: duration
});
videos.push({
video_url: videoLink,
width: width,
height: height,
start: 0,
end: end_time,
duration: duration
});
} catch (e) {
// 如果处理某个元素时出错,继续处理下一个
console.log(`处理第${idx}个元素时出错: ${e}`);
continue;
}
}
// 返回结果
return {
captions: JSON.stringify(captions),
videos: JSON.stringify(videos),
audios: JSON.stringify(audios),
cursor_time: end_time
};
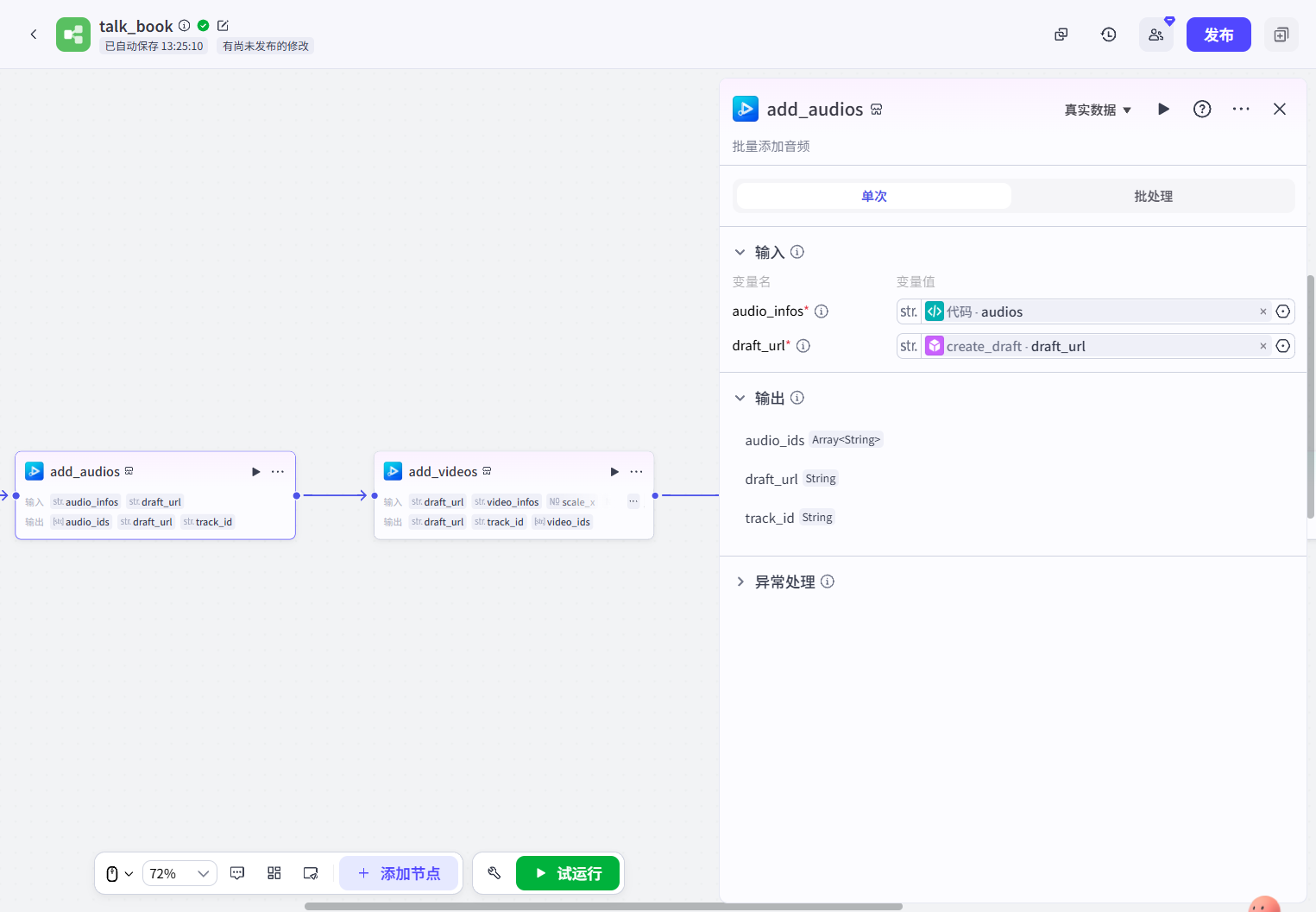
}add_audios(插件)、add_videos(插件)、add_captions(插件):这三个插件我放在一起写,他们的作用就是承接代码输出的audios、videos、captions参数,实现在剪映草稿中批量添加音频、视频和字幕:
大模型_生成对话文案:这个节点的作用是基于书名生成生动有趣的对话口播字幕文案。
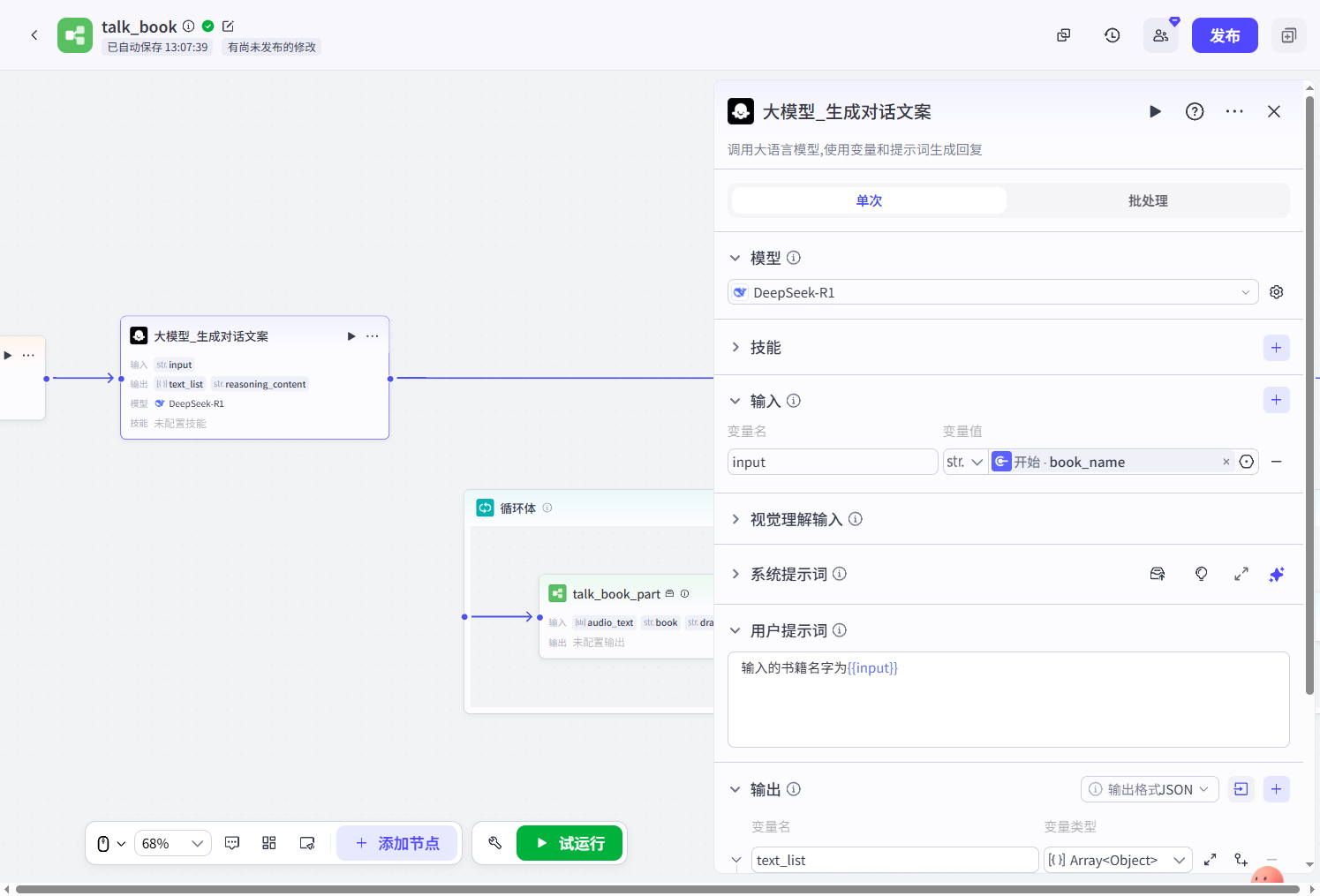
提示词我就不放了,放出去以后会有很多同质化的内容出来,比如我前段时间写的治愈老奶奶手把手教程,更离谱的是很多人直接拿我文章洗稿发出去,体验太差,提示词我之后也不会放,下面提示词输出的结果,大家可以投喂给大模型让大模型反推出提示词就行。
{
"text_list": [
{
"role_name": "主持人",
"line": [
"观众朋友们,欢迎来到思想的盛宴!",
"今天我们有幸请到《[书籍名称]》老师,老师,您好!",
"据说您能洞察人性的[核心奥秘]?"
]
},
{
"role_name": "[书籍名称]",
"line": [
"主持人谬赞了。",
"我只是记录者,观察时代的变迁,和人心的轨迹。",
"关于[核心奥秘],其实并不神秘。"
]
},
{
"role_name": "主持人",
"line": [
"哦?此话怎讲?",
"我以为会是非常复杂的理论!",
"那您认为,现代人最大的困惑是什么呢?"
]
},
{
"role_name": "[书籍名称]",
"line": [
"现代人啊,信息太多,选择也太多,反而迷失了内心的方向。",
"书中第二章,就曾预言过..."
]
},
{
"role_name": "主持人",
"line": [
"天啊!太准了!",
"这简直就是我们当下的写照!",
"那我们该如何找回方向呢?"
]
}
]
}3.2. 人物与书籍对话工作流
人物与书籍对话是工作流是基于大模型生成的对话数组,是一个子工作流,这个工作流的大概思路和主工作流的思路一样,也是构造内容,输入到剪映小助手插件中。我这里只说几个核心节点。完整工作流如下:

开始节点:开始节点的输入有audio_text(大模型生成的对话元素)、book(书籍图片)、host(主持人图片)、img(背景图)、log_text(视频右下角作者名)、type(对话的主角:主持人或者书籍)、draft_url(草稿地址)。
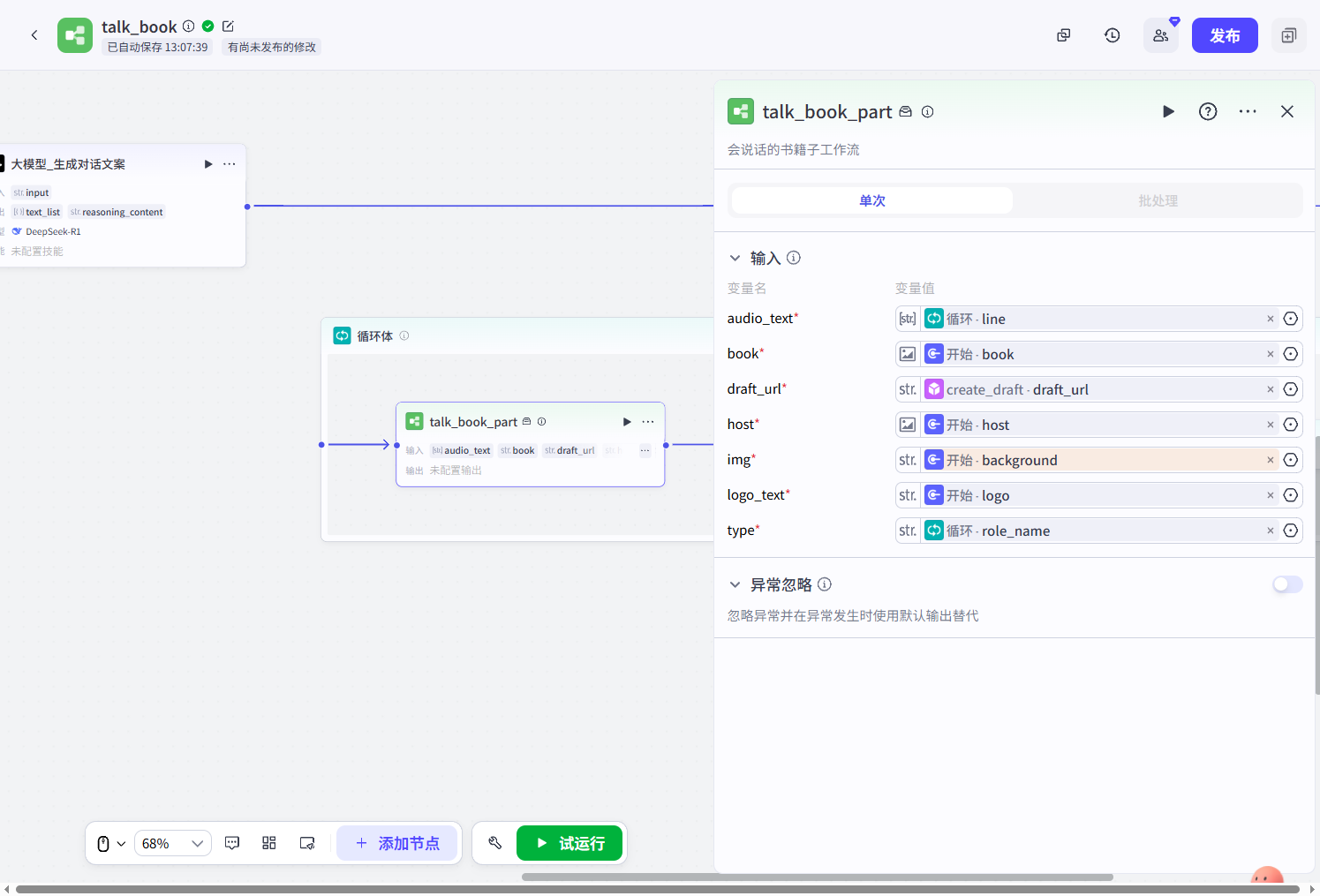
循环:这个节点接收的是一个对话元素,形如:
{
"role_name": "主持人",
"line": [
"观众朋友们,欢迎来到思想的盛宴!",
"今天我们有幸请到《[书籍名称]》老师,老师,您好!",
"据说您能洞察人性的[核心奥秘]?"
]
}我们需要遍历line数组,将line数组元素生成音频,写入到剪映小助手插件当中,如下图,首先我们要先判断role_name为是人为主持人,如果是主持人则合成主持人音频,否则合成书籍音频:
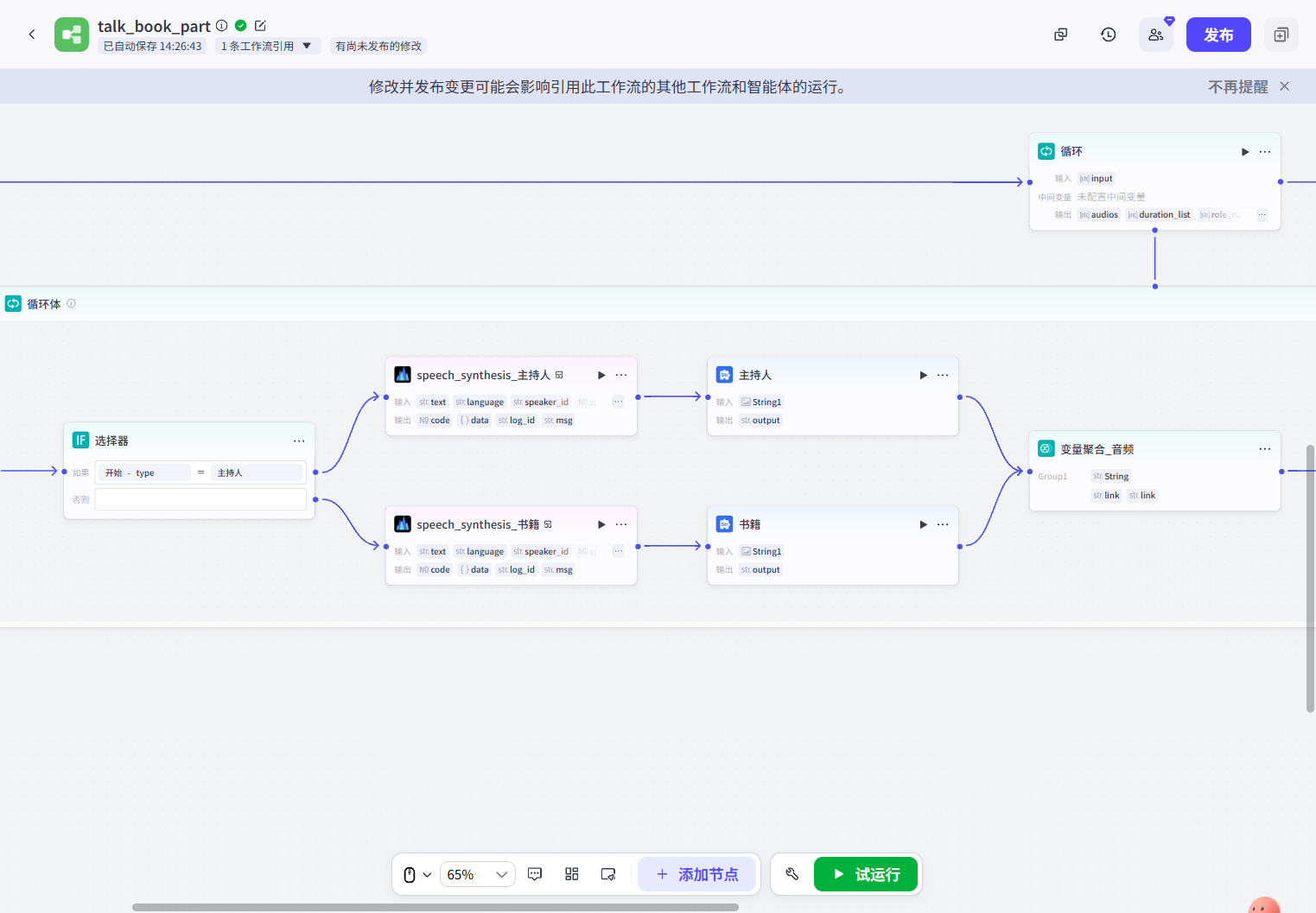
组装数据(代码):这个节点的内容和主工作流一样,目的就是将循环生成的内容转换为剪映小助手需要的输入格式:
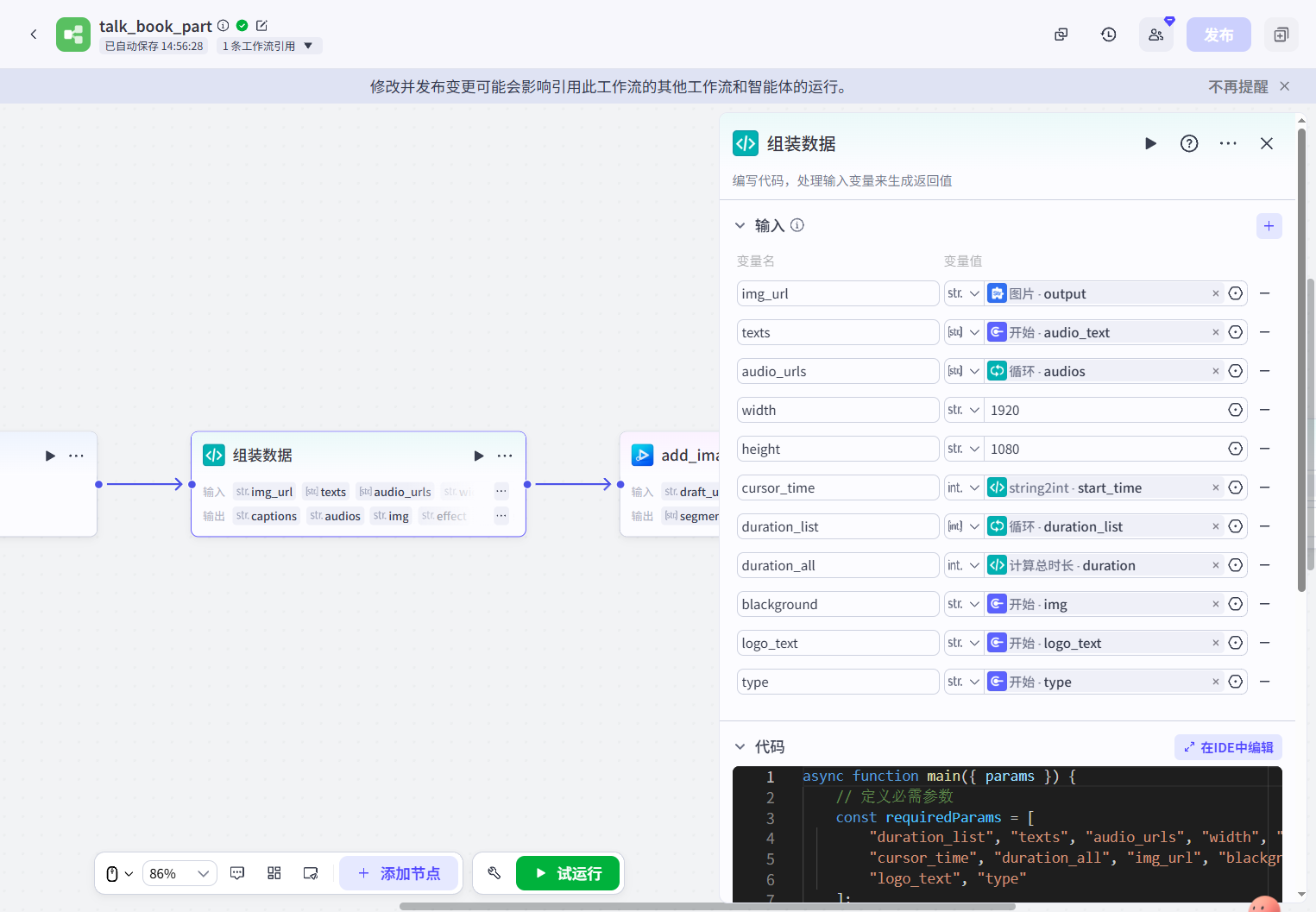
完整代码为:
async function main({ params }) {
// 定义必需参数
const requiredParams = [
"duration_list", "texts", "audio_urls", "width", "height",
"cursor_time", "duration_all", "img_url", "blackground",
"logo_text", "type"
];
// 验证必需的参数是否存在
for (let param of requiredParams) {
if (!(param in params)) {
return { error: `缺少必需参数: ${param}` };
}
}
// 解析所有输入参数为数组
let duration_list = params.duration_list;
let texts = params.texts;
let audio_urls = params.audio_urls;
try {
if (typeof duration_list === "string") {
duration_list = JSON.parse(duration_list);
}
if (typeof texts === "string") {
texts = JSON.parse(texts);
}
if (typeof audio_urls === "string") {
audio_urls = JSON.parse(audio_urls);
}
} catch (e) {
return { error: `解析输入参数时出错: ${e.message}` };
}
// 保证所有参数都是列表类型
if (!Array.isArray(duration_list)) {
duration_list = [duration_list];
}
if (!Array.isArray(texts)) {
texts = [texts];
}
if (!Array.isArray(audio_urls)) {
audio_urls = [audio_urls];
}
// 获取其他参数
let width = parseInt(params.width);
let height = parseInt(params.height);
let cursor_time = parseInt(params.cursor_time);
let duration_all = parseInt(params.duration_all);
let img_url = params.img_url;
let blackground_url = params.blackground;
let logo_text = params.logo_text;
let type = params.type;
// 初始化结果数组
const captions = [];
const videos = []; // 如果不需要,可以移除此变量
const audios = [];
const img = [];
const effect = [];
const blackground = [];
const logo = [];
let current_time = cursor_time;
let total_duration = 0;
// 获取所有数组的最小长度
const data_length = Math.min(duration_list.length, texts.length, audio_urls.length);
for (let idx = 0; idx < data_length; idx++) {
try {
let duration = duration_list[idx];
let end_time = current_time + duration;
// 获取音频URL
let audio_url = audio_urls[idx];
if (typeof audio_url === "object" && audio_url.data && audio_url.data.link) {
audio_url = audio_url.data.link;
} else {
audio_url = String(audio_url);
}
// 获取文本
let text = texts[idx];
if (typeof text === "object" && text.sentence) {
text = text.sentence;
} else {
text = String(text);
}
// 添加到音频数组
audios.push({
audio_url: audio_url,
duration: duration,
start: current_time,
end: end_time
});
// 添加到字幕数组
captions.push({
text: text,
start: current_time,
end: end_time,
in_animation: "打字机 II",
in_animation_duration: duration
});
// 更新下一个开始时间
current_time = end_time;
total_duration += duration;
} catch (e) {
console.error(`处理第${idx}个元素时出错: ${e.message}`);
continue;
}
}
let final_time = cursor_time + total_duration;
// 处理图片
if (type === "主持人") {
img.push({
image_url: img_url,
width: width,
height: height,
start: cursor_time,
end: final_time,
in_animation: "向右滑动",
in_animation_duration: 700000
});
} else {
img.push({
image_url: img_url,
width: width,
height: height,
start: cursor_time,
end: final_time,
in_animation: "向左滑动",
in_animation_duration: 700000
});
}
blackground.push({
image_url: blackground_url,
width: width,
height: height,
start: cursor_time,
end: final_time
});
effect.push({
effect_title: "回弹摇摆",
start: cursor_time,
end: final_time
});
logo.push({
text: logo_text,
start: cursor_time,
end: final_time,
loop_animation: "扫光",
loop_animation_duration: total_duration
});
return {
captions: JSON.stringify(captions),
videos: JSON.stringify(videos),
audios: JSON.stringify(audios),
img: JSON.stringify(img),
effect: JSON.stringify(effect),
cursor_time: final_time,
blackground: JSON.stringify(blackground),
logo: JSON.stringify(logo)
};
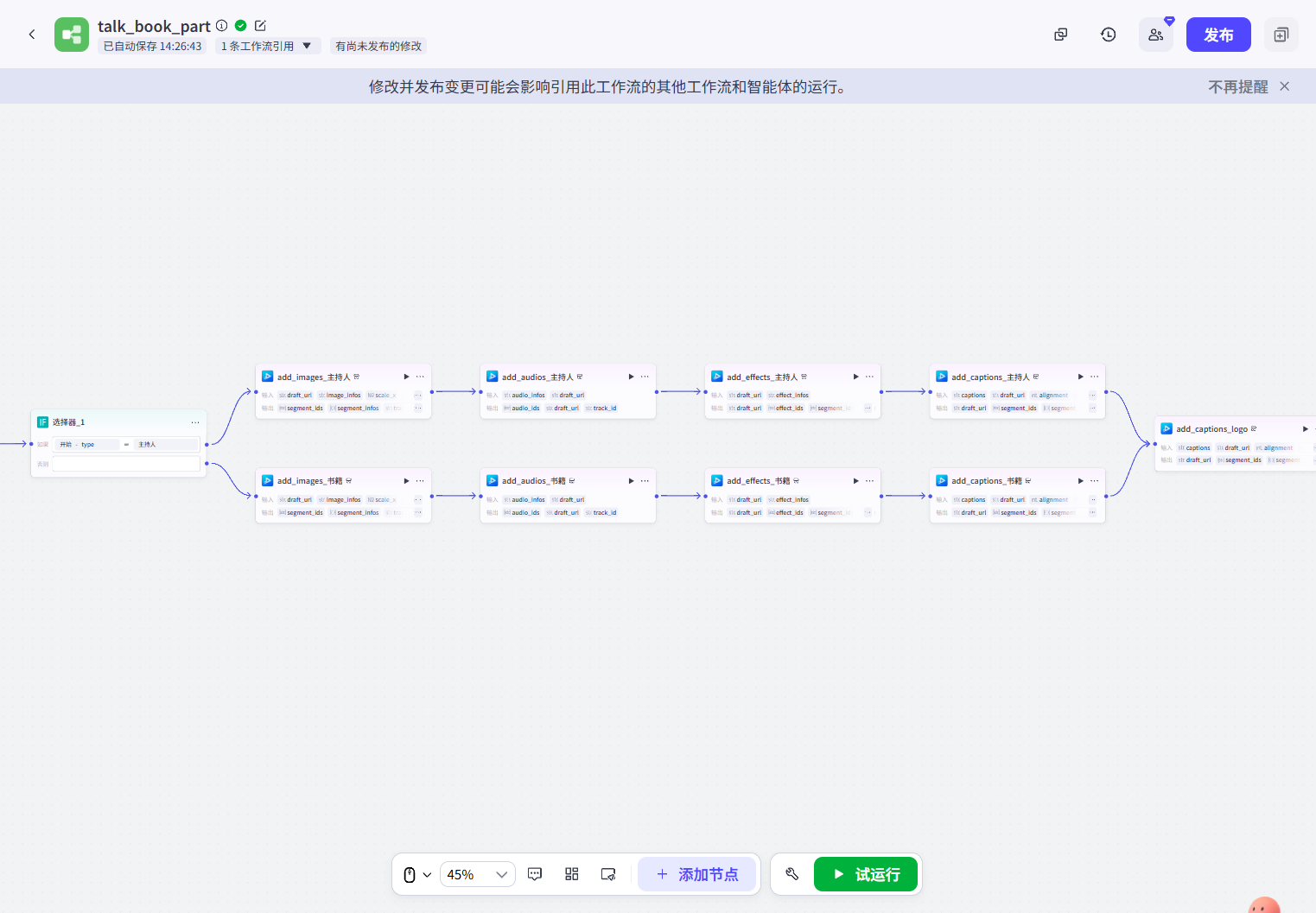
}退出循环后,我们就将音频、图片、特效、字幕依此写入剪映小助手插件就行。
4. 资料领取
你觉得大模型不好用,可能是你不会写提示词,小肥肠为你准备了海量提示词模板和DeepSeek相关教程,只需关注gzh后端小肥肠,点击底部【资源】菜单即可领取。
本文的工作流及提示词已经上传至coze空间,感兴趣的朋友可以私信小肥肠详细了解~
5. 结语
在本文中,我们深入探讨了如何利用 Coze 平台制作《假如书籍会说话》风格的视频内容。从素材准备到工作流实现,每一步都力求详细呈现,旨在帮助创作者快速上手,打造出具有创意和吸引力的 AI 视频作品。在未来,随着 AI 技术的不断发展,我们可以期待 Coze 平台在智能体构建、内容生成等方面带来更多的创新和突破。希望本文能为大家提供有价值的参考,激发更多创作灵感,共同探索 AI 内容创作的无限可能。



















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











