







一:前言
在Vue2中,无论是render()函数,还是template模板,Vue2都是先去解析模板参数,然后生成一颗ats树,然后ats树再去生成一串字符串,最终将这棵树变成一个字符串,也就是我们所说的虚拟DOM,而后才是转换为真实DOM,在本文将会为各位小伙伴讲解一下生成ats树的详细步骤。
本文是基于(2)来接着写的,有时间的小伙伴可以看一下(2)哦,当然不看也不会有太大的影响。链接如下
二:生成ats树的源码
1、项目目录
以下是项目的目录,由于是基于(1)所续写的,这里我们新增的文件主要是dist下的2解析模板参数.index.html文件和 compiler文件夹下的两个文件,index.js是转换为语法树的入口文件,而parse.js是封装的详细方法。
2、HTML文件代码
以下是HTML的代码,在这里我们采用的是el模板,通过vm.$mount挂载了一个id为app的div标签。这里的写法也可以用render函数等,最终在生成ats树的方法里都会进行处理。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="app">
<div style="color: red;">{{name}}</div>
<span>{{age}}</span>
</div>
<script src="vue.js"></script>
<script>
const vm = new Vue({
data: {
name: 'zf',
age: 20,
address: {
content: '回龙观',
num: 30
},
hobby: ['eat', 'drink']
},
// el: '#app' // 我们要将数据解析到el元素上
// template:'<div>hello</div>'
})
vm.$mount('#app')
// 1. 模板引擎 性能很差,使用正则匹配进行替换,因为1.0版本的时候没有虚拟DOM
// 2.采用虚拟DOM,数据变化后比较虚拟DOM的差异,最后更新需要更新的地方
// 3.核心就是将模板变成我们的JS语法,通过JS生成虚拟DOM
// 从一个东西变成另一个东西,比如语法之间的转化,从es6 ==> es5
// CSS压缩,先变成语法树,再重新组装成新的语法 将template语法转换成render函数
</script>
</body>
</html>3、complier文件夹下的index.js文件
这个文件其实没什么可说的,注释很清楚,主要就是封装生成树的方法,因为后续还会转换为虚拟DOM等,所以拆开来各种不同的文件便于观看。
import { parseHTML } from "./parse"
export function compileToFunction(template) {
// 1. 将template 转化成ast语法树
let ast = parseHTML(template)
// 2. 生成render方法(render方法执行后的返回的结果就是虚拟DOM)
console.log(ast)
}4、compiler文件夹下的parse.js文件
该文件是生成树的方法,首先上面是定义的的七个常量,使用正则表达式进行不同的匹配。在这个文件里,首先进入的是parseHTML()方法,由于在Vue2中,要求模板必须是“开始标签”+“内容”+“结束标签”,所以我们就匹配开始标签的“<”,看位置是否是0就好了。
注意:Vue3没有这个要求,可以直接写内容不需要开始标签。因此在Vue3中时一个字符一个字符去匹配的。
在这个方法里,我们定义了一个具有父亲和孩子的结点,进行循环传进来的html模板,匹配“<”的位置,根据位置的不同去执行不同的onXXX()方法,然后对节点进行不同的判断与操作。
同时对于结点的处理, 我们采用的是栈的后进先出策略,去进行匹配弹出对应的开始和结束标签,当栈为空之后,则匹配完成。
//解析模板文件
const ncname = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`;
const qnameCapture = `((?:${ncname}\\:)?${ncname})`;
const startTagOpen = new RegExp(`^<${qnameCapture}`); // 这里匹配到的是一个标签名,<xxx 匹配到的是开始标签的名字
const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`); // 这是一个结束标签,返回的是一个名字
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/; // 这是匹配的一个属性
// ↑ 第一个分组是key,value是 分组3/分组4/分组5
const startTagClose = /^\s*(\/?)>/; // 这里匹配的是单标签
const defaultTagRE = /\{\{((?:.|\r?\n)+?)\}\}/g // {{name}} 匹配的内容就是表达式的变量
// Vue3采用的不是正则,而是一个字符一个字符来判断
// 对模板进行编译处理
export function parseHTML(html) { // Vue2的 开头肯定是一个 <
const ELEMENT_TYPE = 1; // 元素类型是1
const TEXT_TYPE = 3; // 文本类型是3
const stack = [] // 用于存放元素的栈
let currentParent; // 指向栈中的最后一个
let root; // 根节点
function createASTElement(tag, attrs) { // 创建ast节点元素
return {
tag,
type: ELEMENT_TYPE,
children: [], // 孩子
attrs, // 属性
parent: null
}
}
// 下面这三个是暴露出来的方法,最终需要转换成一颗抽象语法树
// 利用栈型结构 来构造一棵树
function onStart(tag, attrs) {
// console.log(tag,attrs,'开始标签')
let node = createASTElement(tag, attrs)
if (!root) { // 判断如果没有根节点,那么就把这个node给根节点,作为树根
root = node
}
if (currentParent) { // 如果当前有currentParent节点,那么就把这个节点的父节点设置成当前的currentParent
node.parent = currentParent
currentParent.children.push(node) // 给父亲的儿子赋值
}
stack.push(node); // 把这个节点丢进栈里面
currentParent = node; // currentParent为栈中的最后一个
}
function onText(text) { // 遇到文本后,直接放进当前指向currentParent的孩子里
// console.log(text,'文本')
text = text.replace(/\s/g,'')
text && currentParent.children.push({ // 文本直接放到当前指向的节点中
type: TEXT_TYPE, // 这个类型是文本
text, // 文本的内容
parent: currentParent
})
}
function onEnd(tag) { // 是结束标签的时候要把栈弹出来,并且更新指向节点
// console.log(tag,'结束标签')
let node = stack.pop(); // 弹出最后一个,校验标签是否合法
currentParent = stack[stack.length - 1]
}
// 前进,删除掉已经匹配的字符串
function advance(n) {
html = html.substring(n);
}
// 开始标签的匹配
function parseStartTag() {
// 匹配开始标签,标签名 之后匹配属性,删掉标签结束
const start = html.match(startTagOpen);
if (start) {
const match = {
tagName: start[1], // 标签名
attrs: [] // 属性
}
advance(start[0].length) // 匹配完成后,截取掉这段,然后再进行匹配
let attr, end
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length)
match.attrs.push({ name: attr[1], value: attr[3] || attr[5] || attr[5] || true })
}
if (end) {
advance(end[0].length)
}
return match
}
// 如果不是开始标签的结束,就一直匹配下去
// console.log(html)
return false; //不是开始标签
}
while (html) {
// 如果textEnd 为0 ,则说明这是一个开始标签
// 如果textEnd >0 ,则说明这是一个结束标签
let textEnd = html.indexOf('<'); // 如果indexOf中的索引是0,则说说明是个标签
if (textEnd == 0) { // 当是一个开始标签的时候
const startTagMatch = parseStartTag(); // 开始标签的匹配结果
if (startTagMatch) {// 解析到了开始标签 跳过本轮循环,因为已经是开始标签了
onStart(startTagMatch.tagName, startTagMatch.attrs)
continue
}
// 这里是第三个执行了,先是上面的开始标签,再是下面的内容,再是结束标签。 如果不是开始标签,那就是结束标签
let endTagMatch = html.match(endTag);
if (endTagMatch) {//匹配结束标签,如果有值,就删掉
advance(endTagMatch[0].length);
onEnd(endTagMatch[1])
continue
}
}
if (textEnd > 0) { // 截取文本,这里大于0 则是结束标签了,所以截取0到textEnd,就是内容了
let text = html.substring(0, textEnd); // 文本内容
if (text) {
onText(text)
advance(text.length); // 解析到的文本
}
}
}
// console.log(root)
return root
}5、运行效果如下
生成的效果图可以看到开始
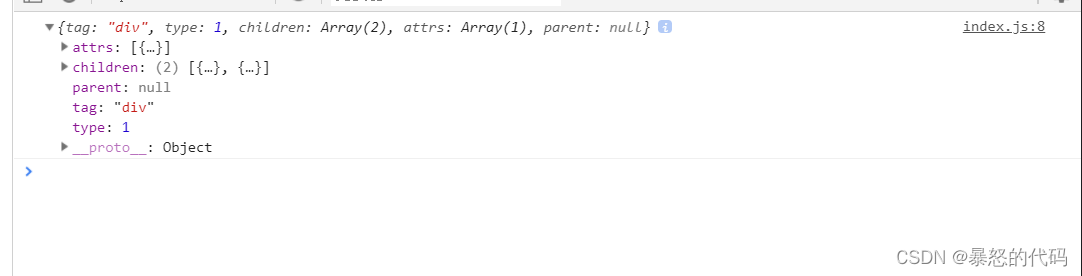
展开后的详细内容,在下图中我们可以看到,这是一个id='app'的div标签,下面有两个子标签,分别是style='color:red;',并且内容为{{name}}的div标签,以及内容为{{age}}的span标签,对比上文HTML的代码,生成的是符合模板的,因此ast树生成成功。

三:总结
ast树是模板想要转换为真实DOM的第一步,其实基本上是使用正则进行不断地匹配,然后根据匹配的结果进行相对应的处理。总体实现来讲不算很难,逻辑也不会太过于复杂。多注意一些细节上的处理就可以了。好啦,本文就讲到这里,希望能对各位小伙伴有所帮助哦!

















 2198
2198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











