







 本文详细介绍了如何使用C++实现哈夫曼编码算法,包括构建哈夫曼树、生成编码表、编码输入文本以及解码编码结果的过程,涉及到优先队列、数据结构和时间复杂度分析。
本文详细介绍了如何使用C++实现哈夫曼编码算法,包括构建哈夫曼树、生成编码表、编码输入文本以及解码编码结果的过程,涉及到优先队列、数据结构和时间复杂度分析。
1.4.1 题目内容
1.4.1-A [问题描述]
对于给定的文本内容,要求采用哈夫曼编码输出编码后的内容,并输出编码内容的解码。文本内容由英文字母构成,这里约定不区分字母的大小写。注意,这里约定构造哈夫曼树时,任一结点的左孩子权值不大于右孩子权值,哈夫曼编码时,左分支写'0'右分支写'1';若两个字母的权值相等,则字典序小的字母优先;对于相等的权值,按出现的先后顺序处理。
1.4.1-B [基本要求]
(1)输入格式:测试数据有多组,处理到文件尾。每组测试数据在一行上输入一个字符 串(仅由大小写英文字母构成且长度不超过360,至少包含2种字母)表示文本内容。
(2)输出格式:对于每组测试数据,输出哈夫曼编码后的内容以及编码结果的解码内容。
1.4.2 算法思想
使用优先队列构建哈夫曼树HuffmanNode。每次从队列中取出两个频率最小的节点,创建一个新节点作为它们的父节点,频率为子节点频率之和。将新节点加入队列,直到队列只剩一个节点,即为根节点。运用generateHuffmanCode函数递归地生成哈夫曼编码。从根节点开始遍历哈夫曼树,左分支标记为0,右分支标记为1,将路径上的编码保存在每个节点中。用encode函数进行编码。对于每个字符,根据编码表找到对应的哈夫曼编码,并将编码拼接成一个编码结果字符串。用decode函数对编码结果进行解码。从根节点开始遍历哈夫曼树,根据编码的0或1选择左分支或右分支,当遇到叶子节点时,将叶子节点对应的字符添加到解码结果字符串中。输出编码结果和解码结果,并释放动态分配的内存。
1.4.3 数据结构
结构体申明如下:
1.4.3-A HuffmanNode
typedef struct HuffmanNode
{
char data; // 存储字符数据
int frequency; // 存储字符出现的频率
string code; // 存储哈夫曼编码
HuffmanNode* left; // 左孩子指针
HuffmanNode* right; // 右孩子指针
}HuffmanNode;
#include <iostream>
#include <string>
#include <map>
#include <queue>
#include <fstream>
#include <windows.h>
using namespace std;
// 定义哈夫曼树节点
typedef struct HuffmanNode
{
char data; // 存储字符数据
int frequency; // 存储字符出现的频率
string code; // 存储哈夫曼编码
HuffmanNode* left; // 左孩子指针
HuffmanNode* right; // 右孩子指针
}HuffmanNode;
// 自定义比较函数,用于优先队列
struct Compare
{
bool operator()(HuffmanNode* a, HuffmanNode* b) const
{
return a->frequency > b->frequency;
}
};
// 自定义优先队列
class PriorityQueue
{
private:
vector<HuffmanNode*> data;
public:
void push(HuffmanNode* node)
{
data.push_back(node);
push_heap(data.begin(), data.end(), Compare());
}
HuffmanNode* top()
{
make_heap(data.begin(), data.end(), Compare());
return data.front();
}
void pop()
{
pop_heap(data.begin(), data.end(), Compare());
data.pop_back();
}
bool empty() const
{
return data.empty();
}
};
// 哈夫曼编码和解码类
class Coding
{
public:
// 构造哈夫曼树
HuffmanNode* buildHuffmanTree(const string& input)
{
// 统一转换输入字符串为小写形式
string lowerCaseInput;
for (char c : input)
{
if (isalpha(c))
{
lowerCaseInput += tolower(c);
}
}
// 统计字符出现次数
map<char, int> frequencyMap;
for (char c : lowerCaseInput)
{
frequencyMap[c]++;
}
// 构建优先队列
priority_queue<HuffmanNode*, vector<HuffmanNode*>, Compare> pq;
for (const auto& pair : frequencyMap)
{
HuffmanNode* node = new HuffmanNode{pair.first, pair.second, "", nullptr, nullptr};
pq.push(node);
}
// 构建哈夫曼树
while (pq.size() > 1)
{
HuffmanNode* left = pq.top(); pq.pop();
HuffmanNode* right = pq.top(); pq.pop();
HuffmanNode* parent = new HuffmanNode{'\0', left->frequency + right->frequency, "", left, right};
pq.push(parent);
}
return pq.top();
}
// 生成哈夫曼编码
void generateHuffmanCode(HuffmanNode* root, string code, map<char, string>& codeMap)
{
if (root->left)
{
generateHuffmanCode(root->left, code + "0", codeMap);
}
if (root->right)
{
generateHuffmanCode(root->right, code + "1", codeMap);
}
if (root->data != '\0')
{
root->code = code;
codeMap[root->data] = code;
}
}
// 编码
string encode(const string& input, const map<char, string>& codeMap)
{
string encodedText;
for (char c : input)
{
char lowercaseChar = tolower(c); // 将字符转换为小写形式
if (codeMap.find(lowercaseChar) != codeMap.end())
{
encodedText += codeMap.at(lowercaseChar);
} else {
// 对于无法编码的字符保持原样
encodedText += c;
}
}
return encodedText;
}
// 解码
string decode(const string& encodedText, HuffmanNode* root,string input)
{
string decodedText;
int i=0;
HuffmanNode* current = root;
for (char c : encodedText)
{
if (c == '0')
{
current = current->left;
}
else
{
current = current->right;
}
if (current->data != '\0')
{
// 根据原始输入字符的大小写情况,添加到解码结果中
if (islower(current->data)&&input[i]<='z'&&input[i]>='a')
{
decodedText += current->data;
}
else
{
decodedText += toupper(current->data);
}
current = root;
i++;
}
}
return decodedText;
}
// 释放哈夫曼树内存
void releaseHuffmanTree(HuffmanNode* root)
{
if (root)
{
releaseHuffmanTree(root->left);
releaseHuffmanTree(root->right);
delete root;
}
}
};
//设置字体颜色
void Set_Color(int x)
{
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), x);
//此函数可控制字体颜色,颜色对应列表如下所示
/*
color(0);
printf(“黑色\n”);
color(1);
printf(“蓝色\n”);
color(2);
printf(“绿色\n”);
color(3);
printf(“湖蓝色\n”);
color(4);
printf(“红色\n”);
color(5);
printf(“紫色\n”);
color(6);
printf(“黄色\n”);
color(7);
printf(“白色\n”);
color(8);
printf(“灰色\n”);
color(9);
printf(“淡蓝色\n”);
color(10);
printf(“淡绿色\n”);
color(11);
printf(“淡浅绿色\n”);
color(12);
printf(“淡红色\n”);
color(13);
printf(“淡紫色\n”);
color(14);
printf(“淡黄色\n”);
color(15);
printf(“亮白色\n”);
在0-15范围修改的是字体的颜色超过15改变的是文本背景色
*/
}
int main()
{
int flag=0;//为1时表示有非法字符
Set_Color(15);//白色
int i=1;
string input;
// 创建文件输入流对象
ifstream infile("T4.txt");
// 检查文件是否成功打开
if (!infile.is_open())
{
Set_Color(4);//红色
cout << "无法打开文件" << endl;
return 0;
}
cout<<"文件已成功打开"<<endl;
cout<<"正在从T4.txt文件中读取数据"<<endl;
while (getline(infile, input))
{
Set_Color(15);//白色
cout<<"第"<<i<<"次读取文件"<<endl;
cout << "从文件中读取的字符串为:" << input << endl;
i++;
for(char ch:input)
{
if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))
{
continue;
}
else
{
Set_Color(4);//红色
cout<<"警告!这行字符串中有非法字符,无法正常编码解码"<<endl;
Set_Color(15);//白色
cout<<"----------------------------------------"<<endl;
flag=1;
break;
}
}
if(flag==1)
{
flag=0;
continue;
}
Coding huffman;
HuffmanNode* root = huffman.buildHuffmanTree(input);
map<char, string> codeMap;
huffman.generateHuffmanCode(root, "", codeMap);
string encodedText = huffman.encode(input, codeMap);
string decodedText = huffman.decode(encodedText, root,input);
Set_Color(6);//黄色
cout << "编码结果:" << encodedText << endl;
Set_Color(2);//绿色
cout << "解码结果:" << decodedText << endl;
Set_Color(15);//白色
// 释放动态分配的内存
cout<<"----------------------------------------"<<endl;
huffman.releaseHuffmanTree(root);
}
Set_Color(2);//绿色
cout<<"文件读取完毕"<<endl;
// 关闭文件
infile.close();
return 0;
}1.4.5 测试数据与运行结果
1.4.5-A 测试数据
文件T4.txt中的数据如下:
1.4.5-B 运行结果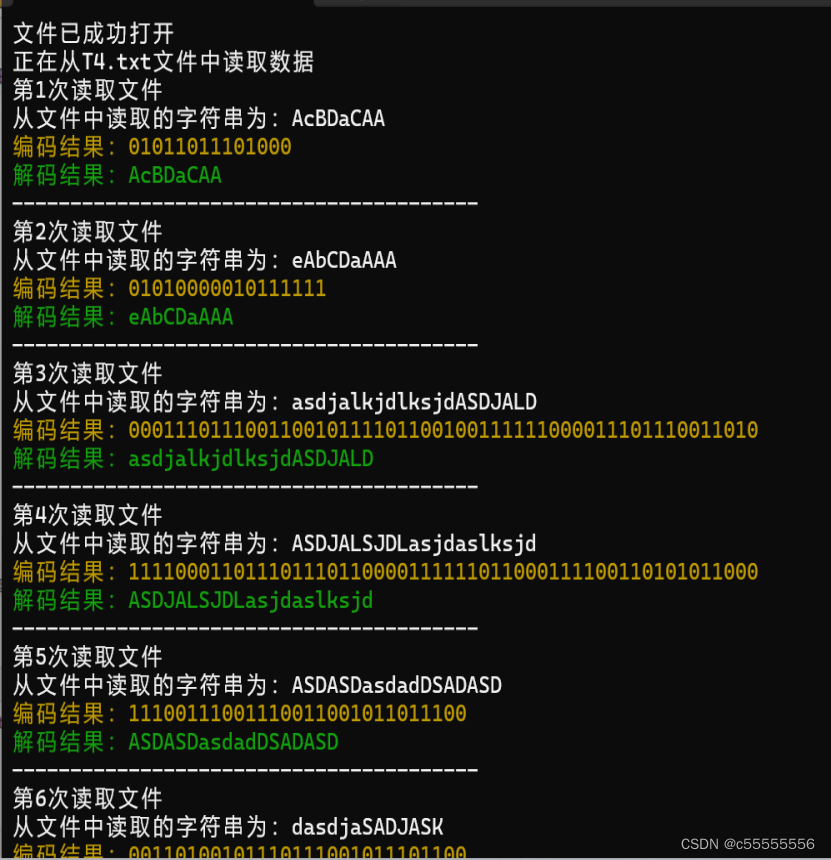
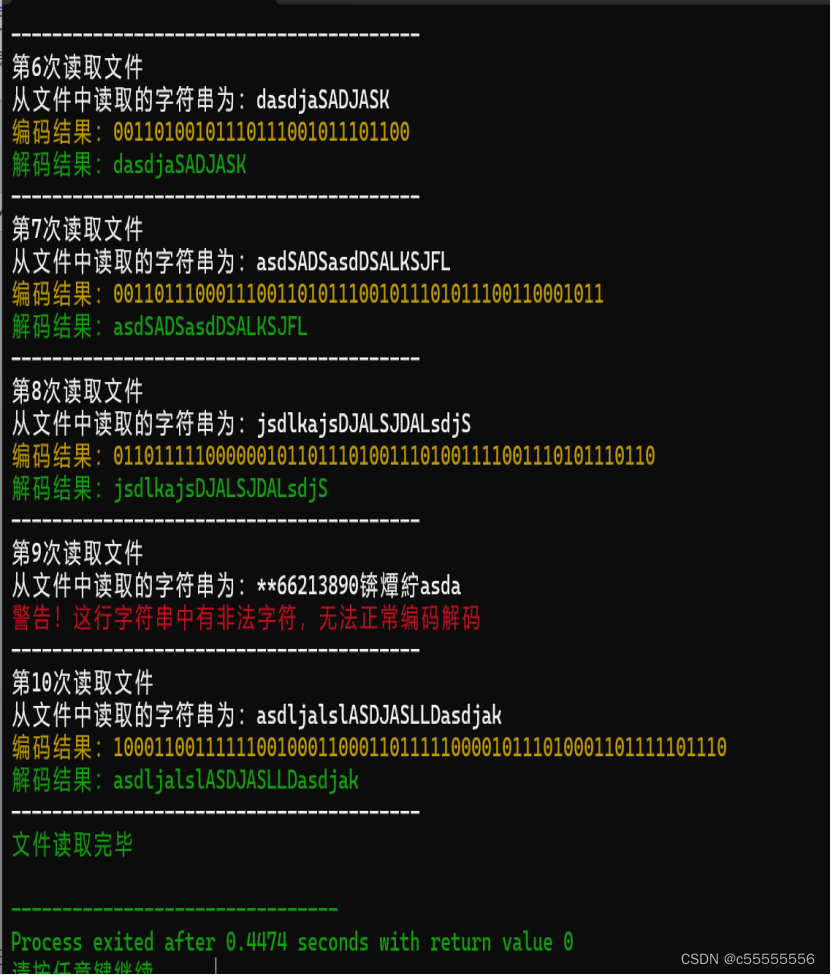
1.4.6 时间复杂度
时间复杂度为O(nlogn).
源码地址:GeekclubC/Course-Design-of-Data-Structure: 用C++完成的数据结构课程设计 (github.com)















 2705
2705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









