







 InfoMap是一种基于最小熵原理的社区发现算法,通过构建图网络上的随机游走来生成序列,再通过层次编码最小化平均编码长度,实现聚类。它具有信息论解释,几乎没有超参数,且适用于多层和重叠社区挖掘。InfoMap的求解算法包括贪心搜索和模拟退火,适用于大规模图网络,且有快速的Python接口。
InfoMap是一种基于最小熵原理的社区发现算法,通过构建图网络上的随机游走来生成序列,再通过层次编码最小化平均编码长度,实现聚类。它具有信息论解释,几乎没有超参数,且适用于多层和重叠社区挖掘。InfoMap的求解算法包括贪心搜索和模拟退火,适用于大规模图网络,且有快速的Python接口。

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为 InfoMap [1],或者 MapEquation。
事实上 InfoMap 已经是 2007 年的成果了,最早的论文是 Maps of random walks on complex networks reveal community structure [2],虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
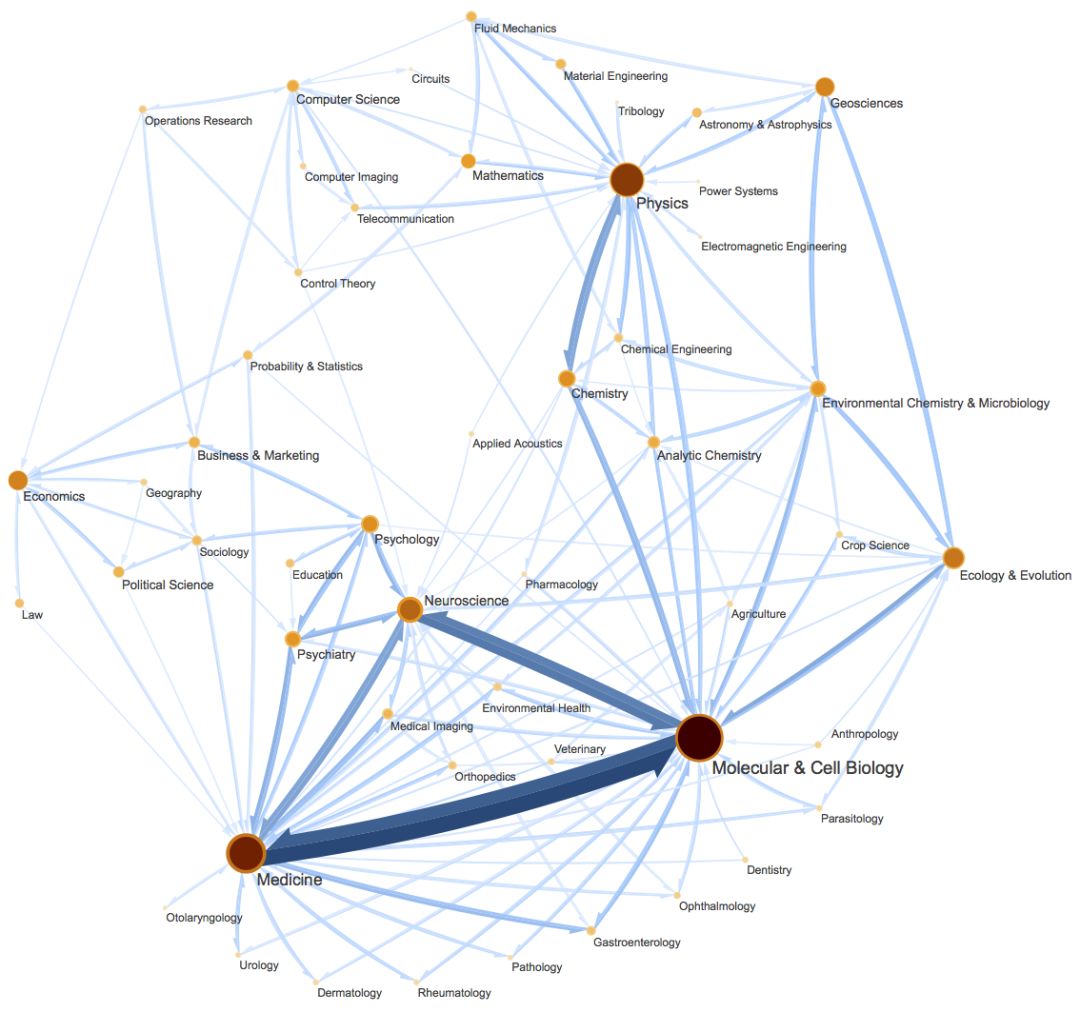
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富(还可以参考《什么是社区发现?》[3])。
熵与编码
在前面几篇文章中,我们一直用信息熵的概念来描述相关概念,而从这篇文章开始,我们引入信息熵的等价概念——平均编码长度,引入它有助于我们更精确地理解和构建最小熵的目标。
二叉树编码
所谓编码,就是只用有限个标记的组合来表示原始信息,最典型的就是二进制编码,即只用 0 和 1 两个数字。编码与原始对象通常是一一对应的,比如“科”可能对应着 11,“学”对应着 1001,那么“科学”就对应着 (11,1001)。
注意这里我们考虑的是静态编码,即每个被编码对象跟编码结果是一一对应的,同时这里考虑的是无分隔符编码,即不需要额外的分隔符就可以解码出单个被编码对象。这只须要求每个编码不能是其余某个编码的前缀(这样我们每次只需要不断读取编码,直至识别出一个编码对象,然后再开始新的读取)。这就意味着所有编码能够构建成一棵二叉树,使得每个编码对应着这棵树的某个叶子,如图所示。
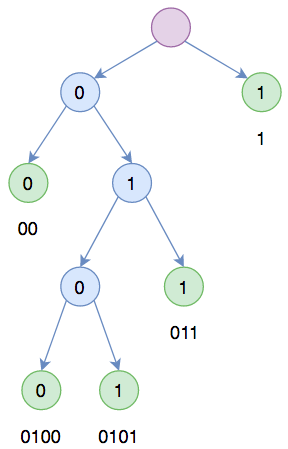
在此基础上,我们可以得到一个很有趣也很有意义的结论,就是假设 n 个不同的字符,它们的编码长度分别为 ,那么我们有:
,那么我们有:

这其实就是这种二叉树表示的直接推论了,读者可以自行尝试去证明它。
最短编码长度
现在想象一个“速记”的场景,我们需要快速地记录下我们所听到的文字,记录的方式正是每个字对应一个二进制编码(暂时别去考虑人怎么记得住字与编码间的对应关系),那为了记得更快,我们显然是希望经常出现的字用短的编码,比如“的”通常出现的很频繁,如果用 11000010001 来表示“的”,那么每次听到“的”我们都需要写这么一长串的数字,会拖慢记录速度,反而如果用短的编码比如 10 来表示“的”,那相对而言记录速度就能有明显提升了。
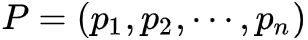 ,那么我们可能会感兴趣两个问题:
第一是如何找到最优的编码方案,使得总的平均编码长度最短;第二是理论上这个平均编码长度最短是多少?
,那么我们可能会感兴趣两个问题:
第一是如何找到最优的编码方案,使得总的平均编码长度最短;第二是理论上这个平均编码长度最短是多少?
对于第一个问题,答案是 Huffman 编码,没错,就是 Word2Vec 里边的 Huffman Softmax 的那个 Huffman,但这不是本文的重点,有兴趣的读者自行找资料阅读就好。而第二个问题的答案,是信息论里边的一个基本结果,它正是信息熵。

在这里我们就前面说的无分隔符编码场景,给出 (2) 的一个简单的证明。依然设 n 个字符的编码长度分别是,那么我们可以计算平均编码长度:

因为我们有不等式 (1),所以定义:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









