







 本文介绍了如何在数据有限的情况下,通过数据增强和半监督学习提升模型性能。文章以 Global Wheat Detection 比赛为例,探讨 MixMatch 和 STAC 方法在图像分类和目标检测中的应用,强调了数据扩增、一致性正则化和伪标签技术对提高模型泛化能力的重要性。
本文介绍了如何在数据有限的情况下,通过数据增强和半监督学习提升模型性能。文章以 Global Wheat Detection 比赛为例,探讨 MixMatch 和 STAC 方法在图像分类和目标检测中的应用,强调了数据扩增、一致性正则化和伪标签技术对提高模型泛化能力的重要性。

©PaperWeekly 原创 · 作者|燕皖
单位|渊亭科技
研究方向|计算机视觉、CNN
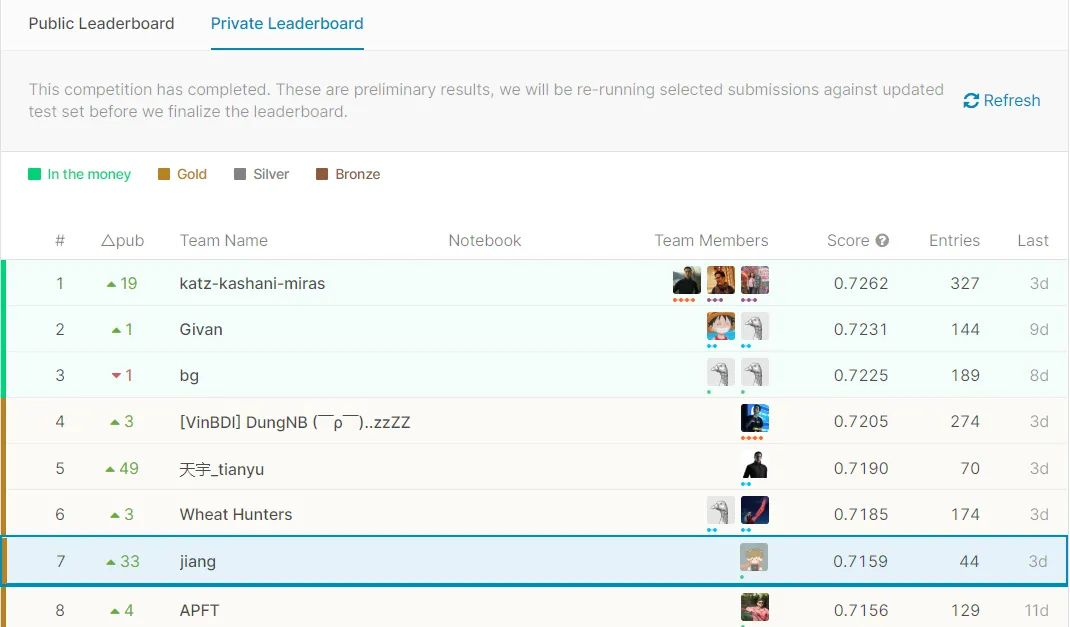
刚刚和小伙伴参加完 kaggle 的 Global Wheat Detection 比赛获得了 Private Leaderboard 第七的名次,首先,在这次比赛中我们发现在 Public Leaderboard 所得到成绩和 Private Leaderboard 所得到的成绩有很大的差异,其次,我们还发现了一些除魔改模型之外对涨点有效的方法。这是我们成绩排名截图。下面就具体看看这两种方法。

Data argument
在训练神经网络时,我们常常会遇到的一个只有小几百数据,然而,神经网络模型都需要至少成千上万的图片数据。因此,为了获得更多的数据,我们只要对现有的数据集进行微小的改变。
比如翻转(flips)、平移(translations)、旋转(rotations)等等。而我们要介绍的是 MixMatch,可以看做是半监督学习下的 mixup 扩增。

论文标题:MixMatch: A Holistic Approach to Semi-Supervised Learning
论文链接:https://arxiv.org/pdf/1905.02249.pdf
代码链接:https://github.com/google-research/mixmatch
对于许多半监督学习方法,往往都是增加了一个损失项,这个损失项是在未标记的数据上计算的,以促进模型更好地泛化到训练集之外的数据中。一般地,这个损失项可分为三类:
熵最小化——它鼓励模型对未标记的数据输出有信心的预测;
一致性正则化——当模型的输入受到扰动时,它鼓励模型产生相同的输出分布;
泛型正则化——这有助于模型很好地泛化,避免对训练数据的过度拟合。
MixMatch 整合了前面提到的一些 ideas 。对于给定一个已经标签的 batch X 和同样大小未标签的 batch U,先生成一批经过 Mixup 处理的增强标签数据 X' 和一批伪标签的 U',然后分别计算带标签数据和未标签数据的损失项。具体地流程如下:
将有标签数据 X 和无标签数据U混合在一起形成一个混合数据 W,然后有标签数据 X 和 W 中的前 X 个进行 mixup 后,得到的数据作为有标签数据 X' ,同样,无标签数据和 W 中的后 U个进行 mixup 后,得到的数据作为无标签数据 U'。
损失函数:对于有标签的数据,使用交叉熵;“guess”标签的数据使用 MSE;然后将两者加权组合。如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









