







 深兰科技北京AI研发中心的DeepBlueAI团队在CCKS 2020实体链指任务中获得亚军。本文分享了他们在中文短文本实体链指任务中的技术方案,包括实体消歧和NIL实体类型判断,采用BERT等预训练模型,以及对抗训练和模型融合等优化策略。
深兰科技北京AI研发中心的DeepBlueAI团队在CCKS 2020实体链指任务中获得亚军。本文分享了他们在中文短文本实体链指任务中的技术方案,包括实体消歧和NIL实体类型判断,采用BERT等预训练模型,以及对抗训练和模型融合等优化策略。

©PaperWeekly 原创 · 作者|罗志鹏
学校|深兰北京AI研发中心
研究方向|物体检测
全国知识图谱与语义计算大会(CCKS 2020)11 月 12 日至 15 日在江西南昌举行,CCKS(China Conference on Knowledge Graph and Semantic Computing)由中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议。CCKS 已经成为国内知识图谱、语义技术、语言理解和知识计算等领域的核心会议。
CCKS 2020 举办的各项挑战赛公布了最终结果,来自深兰科技北京 AI 研发中心的 DeepBlueAI 团队斩获了 3 项冠军和 1 项亚军,并获得了一项技术创新奖。我们可以通过这篇文章了解下 DeepBlueAI 团队在『CCKS 2020:面向中文短文本的实体链指任务』赛题中的解决方案。

赛题介绍
面向中文短文本的实体链指,简称 EL(Entity Linking),即对于给定的一个中文短文本(如搜索 Query、微博、对话内容、文章/视频/图片的标题等),EL 将其中的实体与给定知识库中对应的实体进行关联。
此次任务的输入输出定义如下:
输入:中文短文本以及该短文本中的实体集合。
输出:输出文本此中文短文本的实体链指结果。每个结果包含:实体 mention、在中文短文本中的位置偏移、其在给定知识库中的 id,如果为 NIL 情况,需要再给出实体的上位概念类型。
团队成绩
评价方式采用 F-1 分值,在最终榜单上我们 f1 达到了 0.89538 与第一名仅相差0.00002。
B 榜成绩:

A 榜成绩:

比赛难点
针对中文短文本的实体链指存在很大的挑战,主要原因如下:
口语化严重,导致实体歧义消解困难;
短文本上下文语境不丰富,须对上下文语境进行精准理解;
相比英文,中文由于语言自身的特点,在短文本的链指问题上更有挑战。

引言
实体链接是一项识别文本中的实体指称(指文本被识别到的命名实体)并将其映射到知识库中对应实体上的任务 [1]。
对于一个给定的实体链接任务,首先需要使用命名实体识别方法和工具识别文本中的实体,然后对每个实体指称利用候选实体生成技术生成对应候选实体集,最后利用文本信息和知识库的信息消除候选实体的歧义得到相匹配实体,如果最没有相匹配实体则将该实体指称标记为 NIL(代表没有对应实体)。
一般来讲,实体链接包括三个主要环节:命名实体识别、候选实体生成、候选实体消歧。
CCKS 2020 任务,对比 2019 年任务 [2] 去掉了实体识别,专注于中文短文本场景下的多歧义实体消歧技术,增加对新实体(NIL 实体)的上位概念类型判断,所以 CCKS 2020 任务可以分成两个子任务,分别为多歧义实体消歧和 NIL 实体类型判断。
针对实体消歧任务我们采用了基于 BERT [3] 的二分类方法,对每一个候选实体进行预测,然后对预测的概率进行排序,由于数据集中包含 NIL 实体,我们将 NIL 实体也作为候选实体参与模型训练和概率排序,进而完成消歧任务。
对于 NIL 实体类型判断任务提出了基于问答的 NIL 实体类型判断模型,模型通过构建问句并依据已知实体信息构建上下文,有效的引入短文本中已知实体的知识库信息,额外信息的引入能够显著提升了模型的性能。

实体消歧任务
实体消歧主要是对于给定的实体指称,利用候选实体生成技术得到相应的候选实体集,然后在利用实体消歧模型找到真正对 应的那个实体。如图 1 所示,利用短文本中的实体指称,可以通过候选实体生成的方式得到候选实体集合,然后利用候选实体的描述信息进行实体消歧的得到与实体指称相对应的实体,如果找不到,则用 NIL 表示。
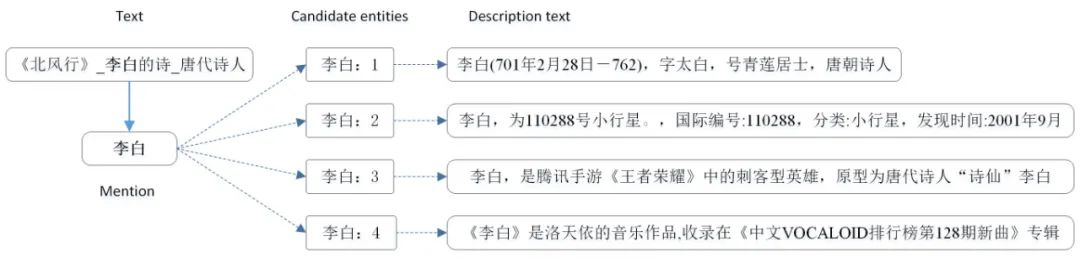
▲ 图1 实体消歧数据样例
实体描述文本
知识库中实体的信息为结构化信息,如下所示:
{"alias": ["承志"],
"subject_id": "10005",
"data": [
{"predicate": "摘要", "object": "爱新觉罗·承志是辅国公西朗阿之子。"},
{"predicate": "义项描述", "object": "爱新觉罗·承志"},
{"predicate": "标签", "object": "人物、话题人物、历史"}],
"type": "Person", "subject": "爱新觉罗·承志"
}为了方便处理,我们将“predicate”与“object”相连得到描述文本。
候选实体生成
候选实体生成最常用的方法是基于字典的方法 [4,5],这种方法需要根据给定的知识库构建名称字典,字典的键就是实体的名字,而值则是这个名字所对应的所有的具有相同名字的实体。
对于每个实体指称去检索字典的键,如果字典的键符合要求,则将该键对应的值中所有的实体都加入到候选实体集中,其中判断字典的键是否符合要求通常的做法是采用精确匹配的方式,只有当实体指称和字典键彼此完全匹配的情况下才加入到候选实体集。
基本流程为先通过知识库中的实体名字以及实体别称构建实体字典,然后采用精确匹配的方式匹配得到候选实体。
实体消歧
现在比较流行的消歧模型常用的方案是提取实体所在短文本的上下文特征,以及候选实体描述文本的特征,在将这两类特征经过全连接网络,最后进行二分类 [6,7]。
这类方法对于长文本很有效,但是对于短文本的消歧效果不是很好,主要是因为短文本内容较短,上下文太少,难以提取有效的上下文特征,而候选实体的描述文本过长,这种情况造成传统的实体消歧模型效果并不理想。考虑到短文本的特性,我们采用了基于 BERT 和实体特征的消歧模型。
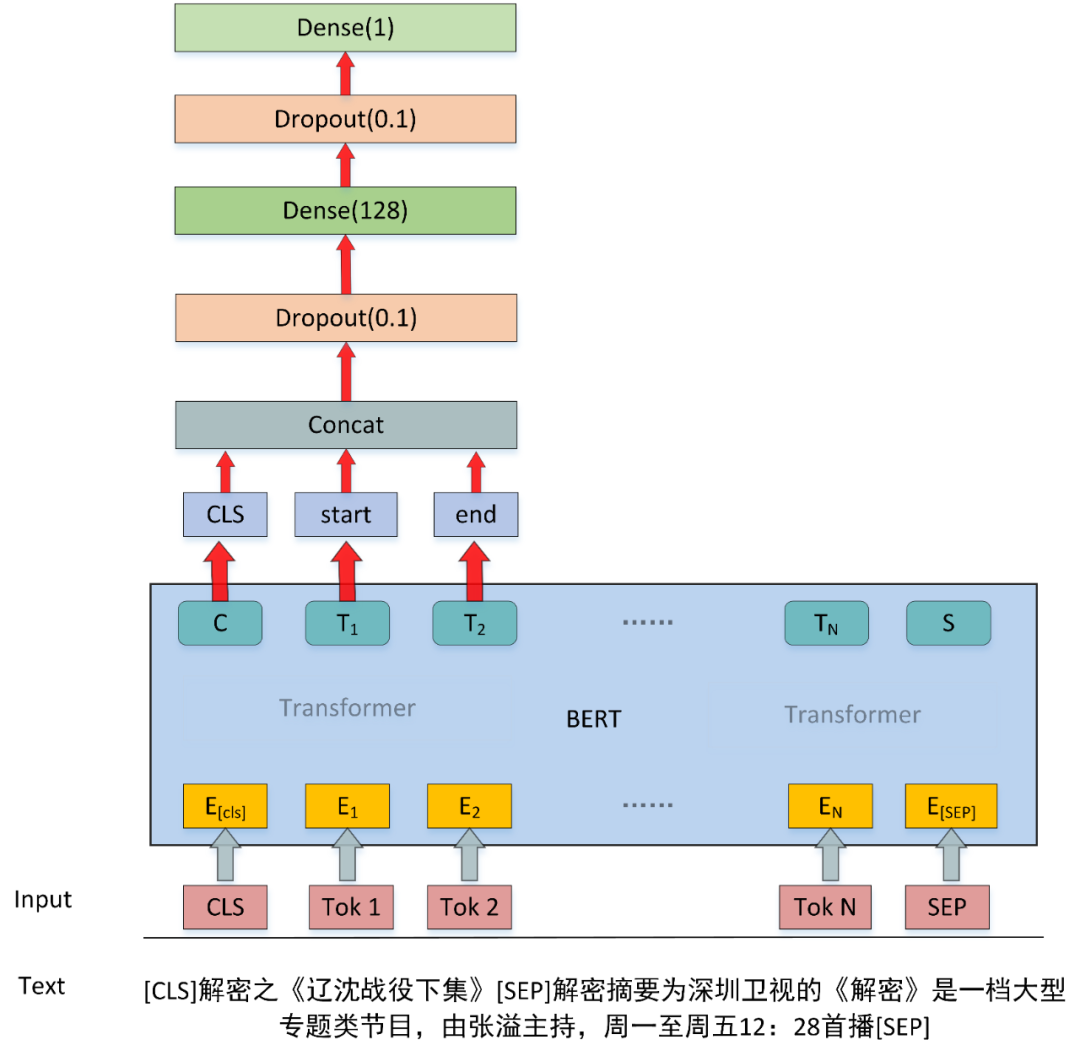
▲ 图2 实体消歧模型图
模型图如图 2 所示,模型采用的思想主要是为利用 BERT 模型 [CLS] 符号的输出向量,以及实体指称所在开始位置的向量和结束位置的向量,经过全连接层,然后经过 sigmoid 进行二分类。
其中 [CLS] 符号的输出向量可以用来判断短文本和候选实体的描述文本是否处在同一语义场景,实体位置的向量可以代表实体的上下文特征。模型的输入为短文本以及候选实体的描述文本,形式为:[CLS] 短文本 [SEP] 候选实体描述文本 [SEP]。
优化点:
动态负采样:不同于以往在训练前选取固定的负样本,模型采用动态负采样技术,在模型训练中每个 batch 选取不同的负样本参与训练,通过这种方式能够极大的提高模型的泛化能力。
NIL 排序:由于增加了 NIL 实体,对NIL 实体也作为候选实体参与训练和排序。
模型融合:采用了百度 ERNIE-1.0 [8] 和 Roberta-wwm [9] 模型两个预训练模型,并采用交叉验证的方式对最后的结果进行平均融合。

实体类型判断
对于实体类型判断任务大家通用的思路也就是 baseline 思路为,通过提取 mention 位置的向量,然后经过全连接分类,得到实体的类型。
这种方案的最大缺点就是仅仅用短文本的信息去对 NIL 实体进行类型分类,没有利用到已知实体信息的特征,为了利用上其他不是 NIL 实体的信息,我们构建了基于问答的实体类型判断模型。模型基于问答的思想,通过构建问句和上下文将已知实体的信息输入到模型中,来提升实体类别判断的性能。
{"text_id": "456",
"text": "神探加杰特,和彭妮长得一模一样,竟想要霸占泰龙的位置",
"mention_data": [
{"kb_id": "283448", "mention": "神探加杰特", "offset": "0"},
{"kb_id": "NIL_VirtualThings", "mention": "彭妮", "offset": "7"},
{"kb_id": "NIL_VirtualThings", "mention": "泰龙", "offset": "21"},
{"kb_id": "88355", "mention": "位置", "offset": "24"}]
}对于上述例子,其中实体有 “神探加杰特” 、“彭妮”,“泰龙”,“位置” 4 个实体,需要预测类型的 NIL 实体有“彭妮”,“泰龙”,对于实体 “彭妮”,“泰龙”,“彭妮” 根据命名习惯很容易判断为类型为 Person 类型, 就算根据短文本的语义分析判断“彭妮”依旧是 Person 类型,同样模型学习到的也是 Person 类型。而“彭妮”的真实类型为 VirtualThings 类型,可以看出在没有其他额外信息的情况下,很难准确预测“彭妮”的类型。
当前任务为:对于输入文本 ,其中存在 NIL 实体集合 {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









