







 本文详细介绍了NLP领域的最新趋势——Continuous Prompt,对比了全监督学习、预训练微调等范式,重点分析了连续提示在预训练语言模型中的应用,包括WARP、Prefix-Tuning等方法,展示了其在自然语言处理任务中的优势和潜力。
本文详细介绍了NLP领域的最新趋势——Continuous Prompt,对比了全监督学习、预训练微调等范式,重点分析了连续提示在预训练语言模型中的应用,包括WARP、Prefix-Tuning等方法,展示了其在自然语言处理任务中的优势和潜力。

©PaperWeekly 原创 · 作者 | 张一帆
学校 | 中科院自动化所博士生
研究方向 | 计算机视觉
近几年,NLP 技术发展迅猛,特别是 BERT 的出现,开启了 NLP 领域新一轮的发展。从 BERT 开始,对预训练模型进行 finetune 已经成为了整个领域的常规范式。但是从 GPT-3 开始,一种新的范式开始引起大家的关注并越来越流行:prompting。
首先我们根据综述文章 Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing [1] 对 prompt 的来源和大致思想做个介绍。
NLP 中的四种范式。
全监督学习,即仅在目标任务的输入输出样本数据集上训练特定任务模型,长期以来在许多机器学习任务中发挥着核心作用,同样的,全监督学习在 NLP 领域也非常重要。但是全监督的数据集对于学习高质量的模型来说是不充足的,早期的 NLP 模型严重依赖特征工程。随着用于 NLP 任务的神经网络出现,使得特征学习与模型训练相结合,研究者将研究重点转向了架构工程,即通过设计一个网络架构能够学习数据特征。
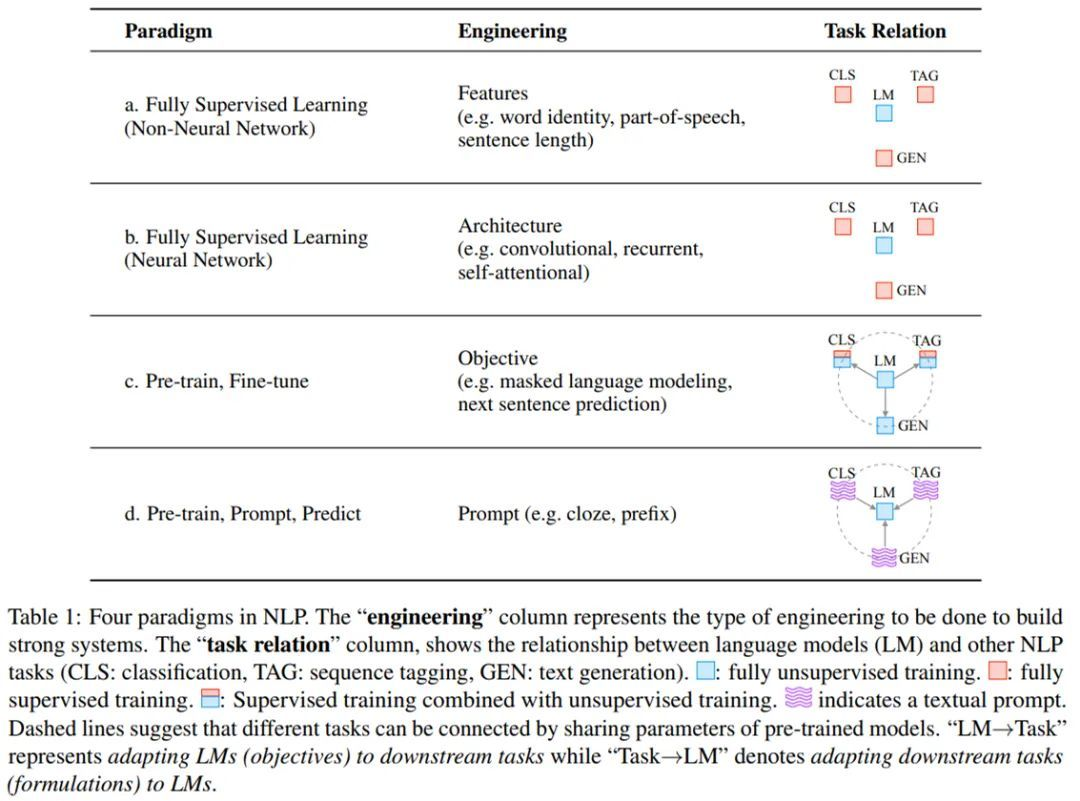
从 2017-2019 年开始,NLP 模型发生了翻天覆地的变化,这种全监督范式发挥的作用越来越小。具体而言,研究重点开始转向预训练、微调范式。在这一范式下,一个具有固定架构的模型通过预训练作为语言模型(LM),用来预测观测到的文本数据的概率。由于训练 LM 所需的原始文本数据需要足够丰富,因此,这些 LM 都是在比较大的数据集上训练完成。
之后,通过引入额外的参数,并使用特定任务的目标函数对模型进行微调,将预训练 LM 适应于不同的下游任务。在这种范式下,研究重点转向了目标工程,设计在预训练和微调阶段使用的训练目标(损失函数)。
当前我们正处于第二次巨变中,「预训练、微调」过程被称为「预训练、prompt 和预测」的过程所取代。在这种范式中,不是通过目标工程使预训练的语言模型(LM)适应下游任务,而是重新形式化(Reformulate)下游任务,使其看起来更像是在文本 prompt 的帮助下在原始 LM 训练期间解决的任务。
通过这种方式,选择适当的 prompt,该方法可以操纵模型的行为,以便预训练的 LM 本身可以用于预测所需的输出,有时甚至无需任何额外的特定任务训练。这种方法的优点是给定一组合适的 prompt,以完全无监督的方式训练的单个 LM 就能够用于解决大量任务。然而该方法也存在一个问题——这种方法引入了 prompt 挖掘工程的必要性,即需要找出最合适的 prompt 来让 LM 解决面临的任务。
目前的 Prompt Engineering 主要分为三种方法:Discrete Prompt,Continuous Prompt 以及 Hybrid Prompt。本文挑选了最新四篇 Continuous Prompt 相关的文章加以解读。
WARP: Word-level Adversarial ReProgramming
Prefix-Tuning: Optimizing Continuous Prompts for Generation
The Power of Scale for Parameter-Efficient Prompt Tuning
Multimodal Few-Shot Learning with Frozen Language Models
第一篇文章首次提出了 continuous prompt 的方法(从 adversarial programming 中得到的 insight),本文的输入需要可学习的 embedding,输出需要任务特定的输出层,也可以看作可学习的 prompt,第二篇文章中使用类似于 continuous prompt 类似的 prefix 加到 transformer 的每一层。
这个过程能否进一步简化呢?第三篇文章给出了答案,第三篇文章只对输入添加额外的 个可学习的 prompt,并得到了超越前人的结果。第四篇文章属于一篇应用,将 continuous prompt 成功的应用在了多模态领域。

WARP

论文标题:
WARP: Word-level Adversarial ReProgramming
收录会议:
ACL 2021
论文链接:
https://arxiv.org/abs/2101.00121
代码链接:
https://github.com/YerevaNN/warp
本文最大的贡献在于,不同于 Discrete Prompt 需要手工寻找或者学习离散的 token 作为 prompt,本文直接优化 embedding 作为 prompt,这给了我们的模型更多的自由度,并最终在下游任务中有更好的表现。
文章的思路很简单,我们需要优化的参数就是两组 embedding , 代表 prompt, 是对每一类的分类参数,有点类似于全连接层这种感觉。
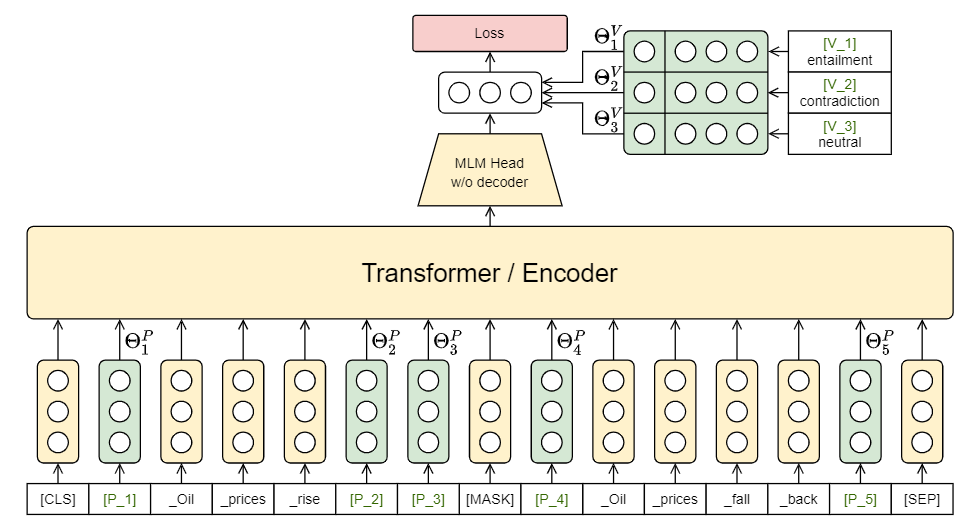
如上图所示,具体来说,我们把 prompt tokens 插入到输入序列中,再经过 encoder 和一个 MLM head,然后通过 ,那么我们分类的概率可以通过如下公式计算:
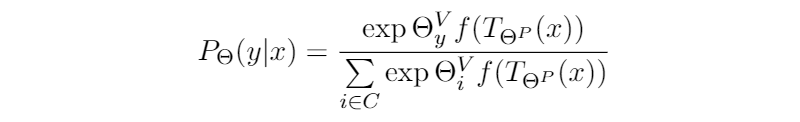
公式中的
是插入了 prompt
的序列,
是所有类别,
是预训练语言模型的的输出。
训练过程也很简单,就是在下游任务的数据集中通过梯度优化寻找使得 cross-entropy loss 最小的参数。

Experiments
实验过程中所有的 prompt tokens 都被初始化为 [MASK] 的 embedding。
在最常用的 benchmark GLUE上,WARP 取得了非常不错的效果,并且参数量少了好多个数量级。下表中的 # 表示训练的参数量。

再看一下 ablation,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









