






©PaperWeekly 原创 · 作者 | 李磊
单位 | 北京大学硕士生
研究方向 | 自然语言处理
随着如 BERT、RoBERTa 等预训练模型在一众自然语言处理任务上取得了出色的表现,如何在取得较好性能的前提下,缩小模型的大小,加快模型的推理速度,成为了学术界和工业界的一个热门的研究方向。这篇文章将会介绍基于动态提前退出( Dynamic Early Exiting) 的预训练模型推理加速方面的系列工作。

动态提前退出
Dynamic Early Exiting(动态提前退出)的核心是根据样本的难度来匹配相应的计算量,这一思想在之前的不少文献中都已有体现,例如在 RNN 中根据样本难度决定所需的时间步(ACT),CV 领域的 Shallow-Deep Network/ 动态深度网络等。将这一思想应用到如 BERT 的预训练的模型上,我们可以把模型的 Layer 视作是一个固定的时间步/深度,则 BERT(base)实际上对每个样本都同等地执行了 12 层的前向计算。
然而,样本之间是普遍存在难度差异的,对于一些比较简单的样本,或许前几层的 BERT Layer 表示就足以支撑模型进行正确的预测,则后续的计算都可以认为是冗余的,从而可以省去以提升推理的速度。
基于这个思想,一个最为直接想法跃然纸上,我们可以在每个层之后增加一个线性分类器,然后每执行一层模型,就拿着得到的表示去过分类器得到输出结果,并且根据这个输出结果来判断是否可以直接退出,或者继续执行下去,直到模型的最后一层,整个框架的示意图如下:
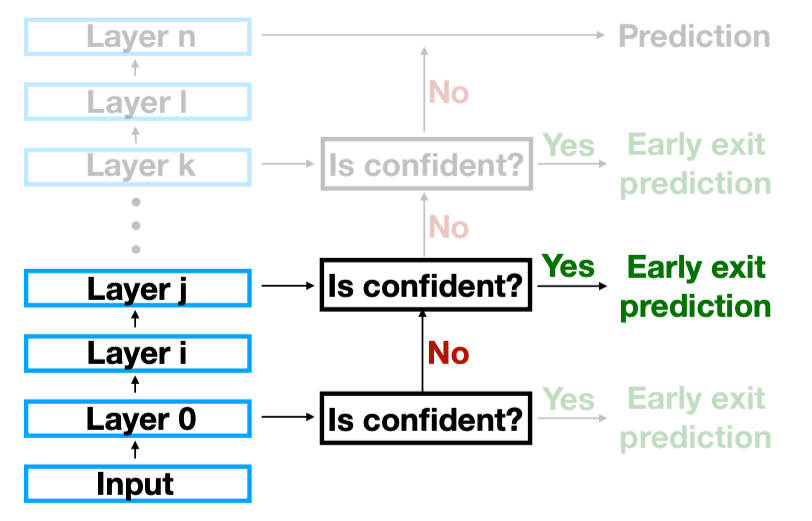
框架有了,那么如何进行是否要退出模型的决策呢?发表在 ACL 2020 上的 DeeBERT [3] 采用了一个非常启发式的指标,即模型预测概率分布的熵,若其熵小于某个特定的阈值,说明模型对于当前的预测足够自信,则可以 退出,否则则需要继续执行下一层,整体的算法如下:

最后则就是中间的这些分类器应该如何训练,DeeBERT 采用的是两阶段的方案,第一个阶段就是简单的 Fine-tuning,训练模型每一层的表示以及最后一层的分类器;第二阶段则固定住中间层的参数以及最后分类器,利用 CE loss 训练中间层的分类器,从而优化中间分类器的分类结果。
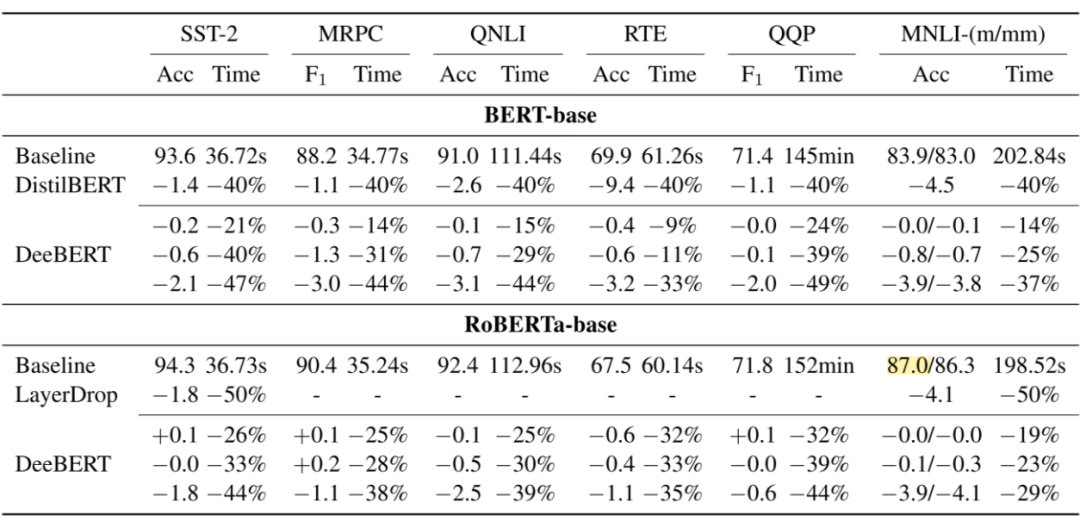
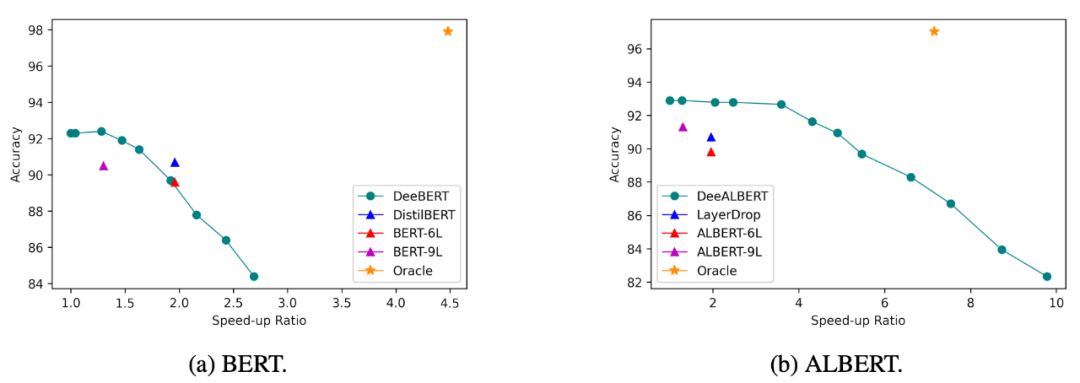
模型的评估则是通过设定不同的阈值,比较不同加速比之下的测试集上的平均性能。作者在 GLUE 的分类数据集上进行了实验,发现相比于 DistilBERT 这类静态模型压缩的方法,能够取得更好的推理加速的效果:
无独有偶,同样是 ACL 2020,还有两篇也是基于动态退出的想法进行 BERT 推理加速的文章,这里对其简要介绍如下:
FastBERT [5] :和 DeeBERT 不同之处在于其中间层的分类器用了更加复杂的基于 attention 的分类器,并且在训练中间分类器的时候增加了额外的 self-attention 目标,使得中间层的输出和最后一层分类器的输出保持一致。文章在一种文本分类数据集能够在 ~10x 加速比的情况下保持原始模型的性能。
RightTool [4] :文章利用中间分类器的预测结果的 confidence,即预测类别的概率值作为退出的指标,并且对其进行了 post-hoc carlibration,以避免 over-confident 的问题。文章和之前的 Paper 不同的地方在于,其对于样本复杂度进行了分析,发现样本长度和难度的相关性很低,而模型的预测的置信度和难度的相关性也不高,相关系数大约在 0.3 附近,这也提示我们说虽然目前基于启发式的退出策略已经取得了不错的成绩,但还有着提升的空间。

改进
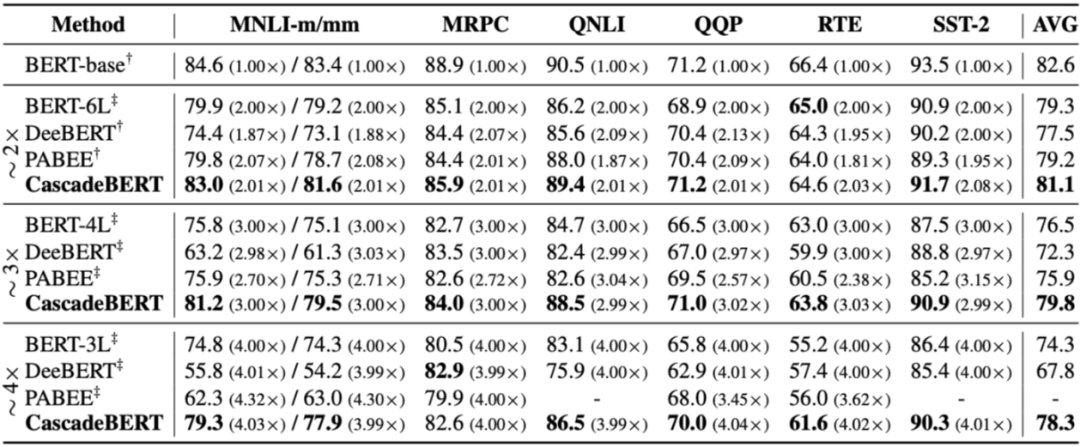
后续有不少工作尝试对 Dynamic Early Exiting 的框架进行探究和改进,CascadeBERT [6] 总结了 Dynamic Early Exiting 在高加速比下,即大部分样本都在浅层退出时,会遇到的两个瓶颈问题:(1)退出决策不鲁棒,即样本难度和中间分类器的分类置信度并不匹配;(2)浅层表示具备的信息不够充分。
对于前者,作者设计了一个用于衡量退出决策和样本难度顺序是否匹配的指标 Difficulty Inversion Score(难度逆序分数),越高说明中间层分类器给出的退出决策和样本难度越一致,文章发现 DeeBERT 的中间分类器在其自己 选择退出的样本上进行了分析,发现其依旧无法给出较好的退出决策:
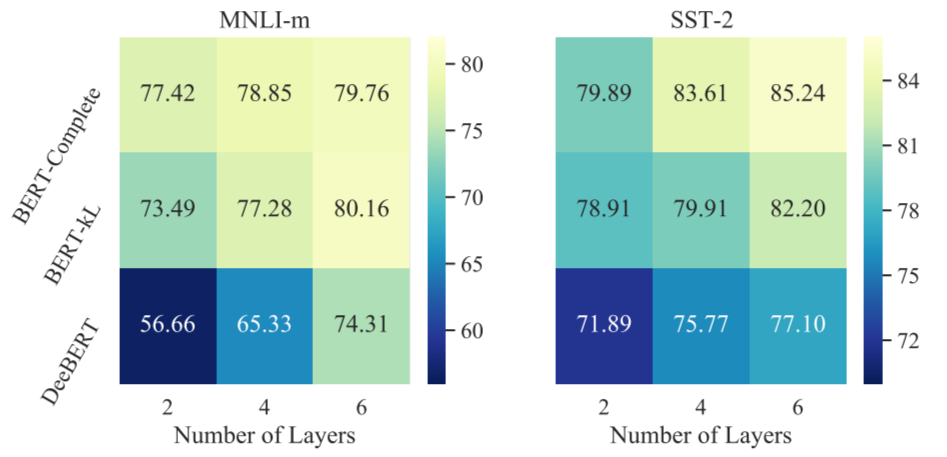
对于后者,作者比较了使用相同层的表示,并且在 DeeBERT 选择退出的样本上进行了性能分析:
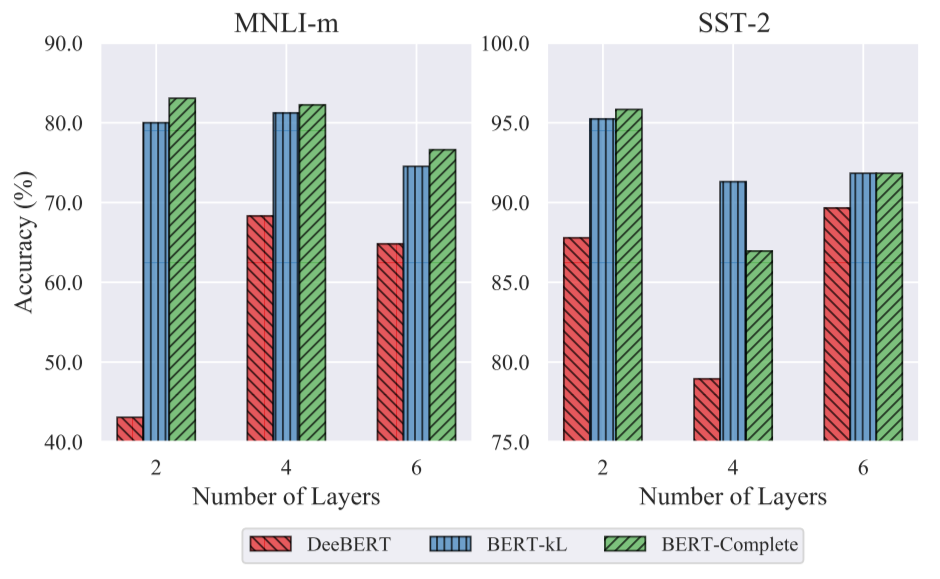
发现即使是相较于直接 fine-tune BERT 前几层得到的 BERT-kl,DeeBERT 的性能在只用少数浅层的样本的时候也难以做出相对准确的预测。基于此,CascadeBERT 提出了一种级联不同大小预训练模型的方案,并且在训练过程中加入样本难度相关的正则项,从而使得在较高加速比的情况下也能够保持较好的性能。
同期也有不少工作在这两方面对 Dynamic Early Exiting 进行改进:
2.1 更好的退出决策
PABEE [7] 尝试结合中间不同层的退出决策的一致性进行更加鲁邦的退出决策,其核心是当连续某几层的中间分类器都给出一致的预测结果后,认为这一个样本的预测结果以及足够自信,因而可以提前退出:
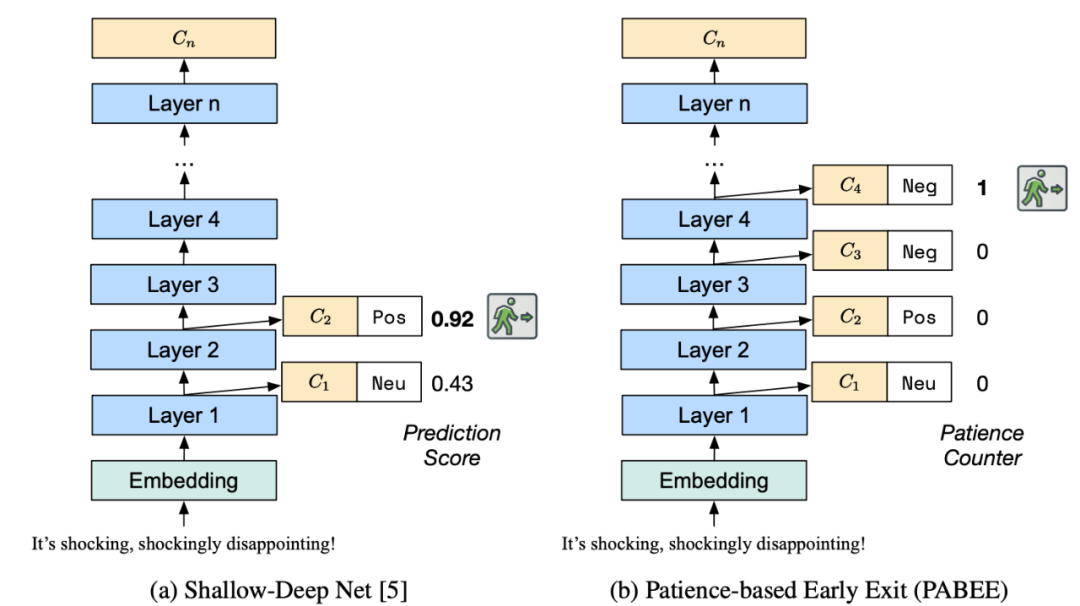
这样的方案简单并且有效,相对于 DeeBERT 都取得了比较明显提升,但因为在设定退出条件的时候需要设置的一致预测层数只能是整数,大大地限制了其加速比的取值范围。类似地,ELBERT [8] 在连续多层分类器给出某个类别上单调递增的概率之后触发退出。
Early Exiting with Ensemble [9] 指出目前的动态退出框架距离性能的上限仍然存在巨大的空间,假设存在 oracle 模型能够在最早的完成正确预测的一层退出,这一情况即下的加速比即是理论的一个上限,而目前不同的方法还存在很大的改进空间,下图的右上角是理论的上界,而大部分的方法都落在了图中的左下部位:
作者基于 Ensemble 理论,推导出一个目标函数,使得不同层的 classifier 在正确的类别上预测一致,而错误类别上的分布尽量拉大,进而增加了中间分类器预测的 Diversity,使得后续基于 Ensemble Voting 的退出决策更加准确。在多个数据集上的实验结果也证明了这一点:

类似地,LeeBERT [10] 使中间的分类器进行 Mutual Distillation,并且对不同层的分类器的 loss 赋以不同的可学习的权重,以提升退出决策的质量。
2.2 更好的中间表示
前面提到,CascadeBERT 指出 BERT 浅层的样本表示可能不足以支撑分类器进行正确的分类决策,因其,其作者提出将中间层退出改为在不同大小的预训练模型(例如,一个 2 层的 BERT 和一个 12 层的 BERT)之中进行级联退出,因为 2 层的 BERT 也是从头预训练得到,因而其样本表示具备比较完整的语义信息,从而能得到一个比较好的效果:
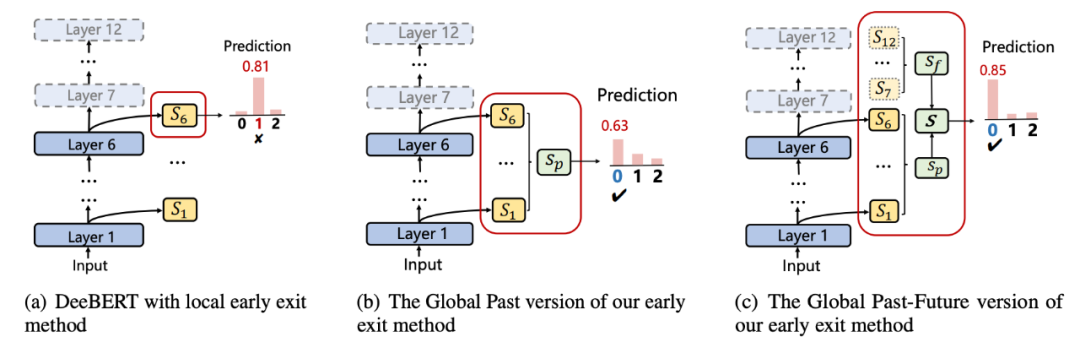
Global Past-Future [11] 则尝试利用 imitation learning,一方面利用所有浅层的样本表示,另外一方面尝试预测出更深层的样本表示来作为辅助信息,进而提升分类的效果:

应用
动态提前退出不仅仅可以应用在简单的分类任务上,不少研究也尝试将其拓展到更加不同的任务上。
BERxiT [12] 利用一个额外学习 learn-to-exit 模块,根据当前的样本表示给出一个是否要退出的决策,这一就可以将这一思想应用到回归任务上。
Early Exiting for Sequence Labeling [13] 更近一步地拓展到了序列标注任务上,其根据序列标注任务的特点,设计了两种退出的机制:Sentence-level Early Exit (SENTEE)以及基于局部 token 的不确定性设计的 Token-level Early Exit(TOKEE):
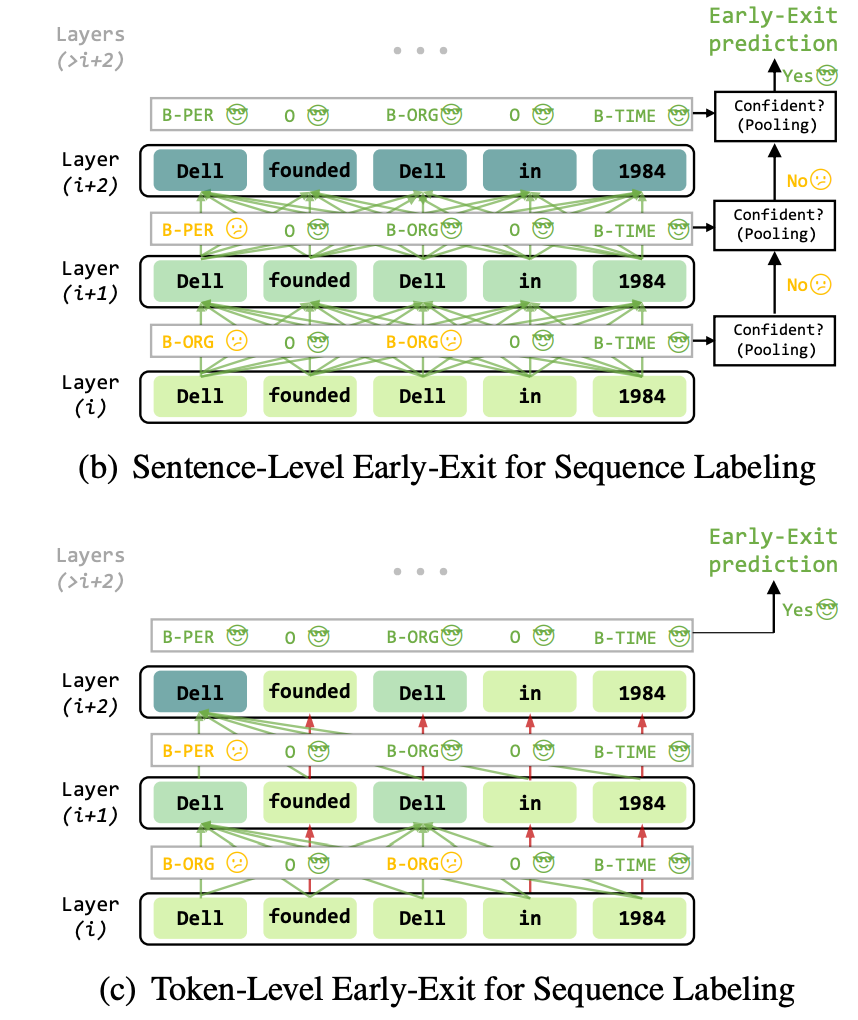
句子级别的退出机制和 DeeBERT 类似,就不再赘述。Token 级别的退出,则是基于上下文窗口 中所有 Token 的预测不确定度的最大值,若是其超过了某个设定的阈值,则后续的计算过程中,这一 token 的表示将不再被重复计算,而是直接传递到下一层,进而能够将 A ttention计算量从 到 , 和 分别是序列长度和没有退出的 token 的数量, 是隐层的维度。
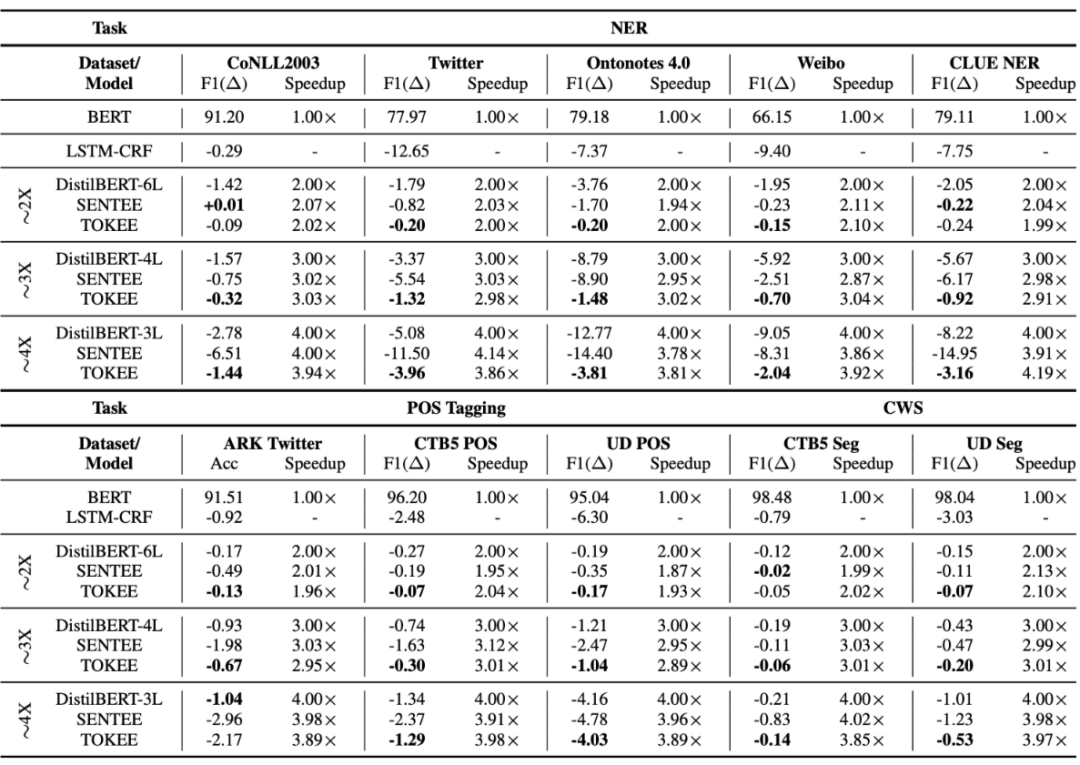
SENTEE 和 TOKEE 能够在一众序列标注任务上取得比较高的加速比的同时保持较好的效果:

小结
我们在这篇文章中简要介绍了用于预训练模型推理加速的动态提前退出思想,并且对目前主要的工作和相关改进进行了梳理。此外,这一框架也被拓展到例如序列标注等的多种任务上,展现出了一定的潜力,也期待未来有更多相关工作来探索更好更快的预训练模型。
更多相关的 paper 可以参考复旦大学博士生孙天祥同学整理的 Paper List:
https://github.com/txsun1997/awesome-early-exiting
我们也梳理了和预训练模型效率相关的 Paper List:
https://github.com/TobiasLee/Awesome-Efficient-PLM
包括剪枝(Pruning)、知识蒸馏(Knowledge Distillation)、量化(Quantization)等,也欢迎大家 Star。
//预训练模型专题交流群//
随着算力的提升,大数据的涌现,新一代人工智能已经迈向“炼大模型”的时代。如果你也对预训练模型感兴趣,欢迎扫描下方二维码(备注「大模型-单位/学校-研究方向」)加入群聊,听说这里还可以免费体验 1060 上车百亿大模型推理哟~

 扫描下方二维码
扫描下方二维码

参考文献
[1] Adaptive Computation Time for Recurrent Neural Networks. Preprint 2016
[2] Shallow-Deep Networks: Understanding and Mitigating Network Overthinking. ICML 2019
[3] DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference. ACL 2020.
[4] The Right Tool for the Job: Matching Model and Instance Complexities. ACL 2020.
[5] FastBERT: a Self-distilling BERT with Adaptive Inference Time. ACL 2020.
[6] CascadeBERT: Accelerating Inference of Pre-trained Language Models via Calibrated Complete Models Cascade. Findings of EMNLP 2021.
[7] BERT Loses Patience: Fast and Robust Inference with Early Exit. NeurIPS 2020.
[8] ELBERT: Fast Albert with Confidence-Window Based Early Exit. Preprint 2021.
[9] Early Exiting with Ensemble Internal Classifiers. Preprint May 2021.
[10] LeeBERT: Learned Early Exit for BERT with Cross-Level Optimization. ACL 2021.
[11] A Global Past-Future Early Exit Method for Accelerating Inference of Pre-trained Language Models. NAACL 2021.
[12] BERxiT: Early Exiting for BERT with Better Fine-Tuning and Extension to Regression. EACL 2021.
[13] Accelerating BERT Inference for Sequence Labeling via Early-Exit. ACL 2021
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









