







01
ICLR介绍
ICLR,全称为International Conference on Learning Representations(国际学习表征会议),自2013年成立至今仅九年的时间,它已被学术研究者们广泛认可,在谷歌学术全领域的热门出版物中排名第十。
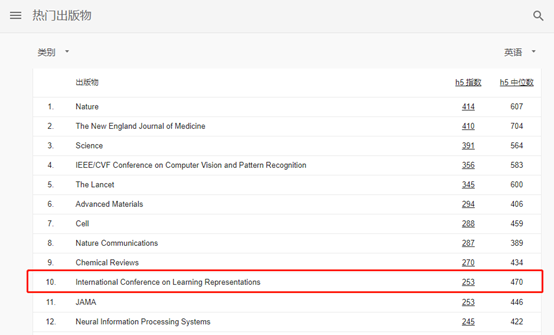
谷歌学术“热门出版物”榜单
目前ICLR 2022已经放榜,总提交数量为3328篇,最终有1095篇论文入选,其中Oral 54篇,Spotlight 176篇,Poster 865篇。
02
线上分享
ReadPaper从入选的优秀论文中选出了10篇,其中大部分被评为Oral或Spotlight,邀请到论文的第一作者给大家做线上分享,带来论文的一手解读,聊聊研究背景、实验过程以及背后的科研故事等等。刚好在看论文的小伙伴,一定记得收藏活动,关注直播哟。
在讲解过后,直播还设置了互动问答环节,记得提前准备好提问,千万不要错过了。
线上分享将会在“PaperWeekly”的B站直播间(https://live.bilibili.com/14884511)进行,详细日程如下:
时间 | 嘉宾 | ICLR入选论文 |
3.11 12:00 | 何俊贤 | Towards a Unified View of Parameter-Efficient Transfer Learning (Spotlight) |
3.16 12:00 | 金汶功 | Iterative Refinement Graph Neural Network for Antibody Sequence-Structure Co-design (Spotlight) |
3.16 19:00 | 孟强 | Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters (Spotlight) |
3.18 12:00 | 林森 | TRGP: Trust Region Gradient Projection for Continual Learning (Spotlight) |
3.18 19:00 | 陈骁宇 | Understanding Domain Randomization for Sim-to-real Transfer (Spotlight) |
3.23 12:00 | 金庆 | F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization (Oral) |
3.23 19:00 | 吴海旭 | Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy (Spotlight) |
3.25 12:00 | 吴梓阳 | How Low Can We Go: Trading Memory for Error in Low-Precision Training |
3.30 12:00 | 王子丰 | PAC-Bayes Information Bottleneck (Spotlight) |
3.30 19:00 | 董力 | BEiT: BERT Pre-Training of Image Transformers (Oral) |
03
十问回答
和往常的活动一样,嘉宾们也被邀请入驻ReadPaper,并针对他们的论文进行了非常详尽的“论文十问”回答,亲自阐述了不少有关论文的解析和研究思考。
在观看直播之前,小伙伴们可以点击文末的阅读原文,前往论文十问,先睹为快!

“Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters” 的十问节选
04
嘉宾及论文介绍
▼点击卡片展开▼

何俊贤
卡内基梅隆大学
计算机科学学院博士生
论文:
Towards a Unified View of Parameter-Efficient Transfer Learning
论文简介:
在下游任务上对大型预训练语言模型进行微调已经成为NLP的迁移学习范式。然而,传统的方法是对预训练模型的所有参数进行微调,随着模型规模和任务数量的增加,这种方法变得不切实际。最近的工作提出了一系列参数高效的迁移学习方法,这些方法只对少数(额外的)参数进行微调,可以达到强大的性能。虽然效果显著,但已有方法背后成功的关键因素以及它们之间的联系并没有被完全理解。在本文中,我们把已有的参数高效的微调方法分解成不同的设计元素,并提出了一个统一的框架建立它们之间的联系。通过对机器翻译、文本摘要、语言理解和文本分类等任务的实验探究,我们借助这个统一的框架总结出了现有方法中的重要设计元素去理解它们为什么有效。此外,我们的统一框架使得我们能够结合最优的设计去实例化出新的参数高效微调方法,这些方法比以前的方法调整参数更少,同时更加有效,在四个NLP任务上取得了与微调所有参数相当的结果。

金汶功
美国博德研究所
博士后研究员
论文:
Iterative Refinement Graph Neural Network for Antibody Sequence-Structure Co-design
论文简介:
抗体是一种与病原体结合并激活免疫系统的蛋白质。抗体结合的特异性由这些 Y 形蛋白末端的CDR序列决定。在这篇论文中,我们提出了一种生成模型来自动设计具有特定性质的CDR序列。以前的生成方法假设蛋白质的3D结构已知并作为模型输入,但这样的假设往往不能满足实际应用需要。为此,我们设计一个联合生成模型,同时生成CDR的序列和其3D结构。我们的模型在迭代改进其预测的全局结构的同时,自回归地生成序列。为了提高速度,我们以粗粒度的方式对CDR内部和外部结构关系进行建模。我们的方法在测试集上实现了更好的perplexity和3D结构准确度,并且能更好的设计能够与病原体结合的抗体。

孟强
Aibee爱笔智能
算法工程师
论文:
Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters
论文简介:
联邦学习可以一定程度缓解公众日益高涨的对人脸识别中数据隐私的担忧。然而传统联邦学习在该任务上表现不尽如人意,其主要原因是这个任务的特殊性:在客户端之间传播类中心对识别效果十分重要但是却会导致隐私泄漏。为了解决隐私-性能的矛盾,本文提出了PrivacyFace,一个通过在客户端之间分享辅助的去隐私信息来极大提升联邦人脸识别性能的框架。PrivacyFace 主要由两个组成部分组成:首先,提出一个实用的差分隐私本地聚类(DPLC)算法从本地类中心中提取去隐私信息。接着利用设计的全局一致性人脸识别损失函数来达到客户端之间的全局优化,从而得到更优的特征空间。该框架在数学上满足差分隐私,仅仅引入轻量的开销就能显著提升联邦学习下人脸识别的性能(例如,在IJB-B和IJB-C的TAR@FAR=1e-4 提升为+9.63%和+10.26%)。在大规模数据集上的详细结果以及消融实验显示了我们方法的有效性和实用性。

林森
亚利桑那州立大学
博士后研究员
论文:
TRGP: Trust Region Gradient Projection for Continual Learning
论文简介:
灾难性遗忘是持续学习的主要挑战之一。为了解决这个问题,一些现有的方法对新任务的优化空间进行了限制,以尽量减少对旧任务的干扰。但是,这可能会导致新任务的学习性能不理想,尤其是当新任务与旧任务密切相关时。为了应对这一挑战,论文提出了用于持续学习的信任区域梯度投影(TRGP),通过对任务相关性的有效分析来促进任务间的前向知识转移。具体来讲,论文引入了“信任区域”的概念,利用梯度在旧任务子空间的投影,快速有效地为新任务选择最相关的旧任务。然后,论文提出了一种缩放权重投影,通过缩放矩阵巧妙地重用信任区域中所选旧任务的冻结权重。通过联合优化缩放矩阵和模型,同时沿着与旧任务子空间正交的方向更新模型,TRGP可以有效地促进知识转移而不会忘记。大量实验表明,TRGP比相关的最先进方法有着显著的性能提升。

陈骁宇
北京大学
在读博士生
论文:
Understanding Domain Randomization for Sim-to-real Transfer
论文简介:
强化学习算法在很多模拟环境任务下取得了很好的性能,包括雅达利游戏、围棋、星际争霸等。然而,当直接应用于机器人等实际场景任务时,强化学习面临探索成本高、样本量不足等问题。在这类问题上,模拟-现实迁移学习(sim-to-real transfer)被广泛运用于将模拟环境中学到的知识迁移到真实场景。domain randomization作为模拟-现实迁移的一种常见的算法,在很多任务上均取得了很好的算法性能。尽管这一算法在实验上取得了广泛成功,其算法高效性并没有得到清晰的理论理解。针对这一问题,我们提出了用于解释模拟-现实迁移学习的理论框架。我们将模拟环境建模为包含隐式参数空间的马尔可夫决策模型集合,并证明了domain randomization算法在没有任何真实环境交互的情况下也能取得很好的性能。我们的理论强调了带记忆的模型结构对于domain randomization算法的重要性。

金庆
美国东北大学
在读博士
论文:
F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization
论文简介:
本文针对深度模型的量化问题在现有先进方法上做了进一步研究,旨在实现仅用八位定点数乘法的量化模型,去除模型中的32位乘法操作,而使用移位操作进行替换。文中先对定点数的计算方法和统计特征进行了分析,对高斯分布和整流高斯分布(rectified Gaussian distribution)的相对量化误差和定点数小数位之间的关系进行了统计分析,得出了随机变量标准差和最优量化小数位的经验规律。基于此,文中提出了一种使用标准差推断量化所用定点数小数位的新方法。同时,针对当下流行的参数化激活值截断阈值(PACT)量化方法,文中进行了深入分析,指出了其与定点数量化之间的内在联系和形式上的等价性,提出了一种新型深度模型的定点数量化算法。针对残差网络中同胞层(sibling layers)对截断值(clipping level)与定点数小数位的共享问题,文中也进行了探讨。利用所提出的方法,文中在ImageNet数据集上对不同神经网络结构(包括ResNet18、ResNet50、MobileNet、MobileNetV2)进行了实验,均达到了当前最优水平。本文已被机器学习领域国际顶级会议ICLR收录为口头报告。

吴海旭
清华大学软件学院
在读硕士生
论文:
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
论文简介:
现实世界中的系统每时每刻都在产生着大量的时序数据,从中发掘出异常,对于保持系统稳定运行、避免经济损失至关重要。不同于以往基于点向特征的方案,本文提出了一种基于时序关联差异的异常检测算法Anomaly Transformer,利用每个时刻对整体序列关联、局部先验关联的不同进行检测。Anomaly Transformer在模型架构、学习策略、异常判据三个层面提供了完整的解决方案,在5个领域的数据上取得了最优的效果,被ICLR 2022接收为Spotlight(亮点)论文。

吴梓阳
粤港澳大湾区数字经济研究院
AI金融与深度学习研究中心
助理研究员
论文:
How Low Can We Go: Trading Memory for Error in Low-Precision Training
论文简介:
低精度运算能帮助我们用更少的耗能、存储以及时间训练深度学习模型,但这些资源的节省并非没有代价:低精度运算会带来更大的计算误差并导致模型的预测能力下降。本文的核心问题是研究如何在保证最终模型的性能的同时,通过选取最佳的低精度配置,来节省计算资源。我们的核心思路是将这个问题描述为一个超参数选取问题,并运用元学习(meta-learning)的思想来解决低精度与模型性能之间的取舍问题。通过本文的方法,对任意的目标数据集,我们都可以迅速地找到合适的低精度配置来达到资源节约以及性能保证的双重目标。

王子丰
美国伊利诺伊大学香槟分校
在读博士
论文:
PAC-Bayes Information Bottleneck
论文简介:
一种基于PAC-Bayes泛化误差界的信息瓶颈
解释神经网络的泛化能力是近年来人工智能领域的一项热点研究。神经网络中储存的信息量被认为是可以衡量网络泛化能力的指标。如果我们能计算神经网络中的信息量,则可以解释和推断网络的泛化能力,解开深度学习的黑箱,并且指导其优化和设计。在这篇文章中,我们提出了一种能快速计算神经网络权重中储存数据信息量的算法,并且基于此构建了一种新的信息瓶颈(PAC-Bayes IB)。我们在实验中证明,这种信息度量能从多个角度解释和追踪网络的泛化能力,比如在不同的宽度和深度,数据大小,数据噪音程度,批次大小等。并且,使用该种信息量作为约束能够训练更好的神经网络。

董力
微软亚洲研究院自然语言处理组
研究员
论文:
BEiT: BERT Pre-Training of Image Transformers
论文简介:
近年来,大规模自监督预训练在自然语言领域率先取得了突破性进展,带来了全新的“预训练-微调”范式。在GPT、BERT等一系列 “出圈” 工作中,生成式自监督占绝对优势。但在计算机视觉领域,大多数工作沿着对比学习的思路进行推进,而生成式自监督预训练一直没有得到应有的重视。基于这个观察,我们提出了BEiT自监督模型,使用掩码图像建模 (Masked Image Modeling) 这一任务,对Vision Transformers进行预训练。BEiT首次验证了生成式预训练可以取得比对比学习更好的微调结果,并在图像分类以及语义分割上取得了优异结果。更重要的是,通过摆脱对监督式预训练的依赖,BEiT可以高效使用无标注图片将Vision Transformers扩展到巨大的模型规模。相信BEiT在视觉领域所引发的“生成式自监督复兴”,会加速领域到达“the BERT moment of CV”。
点击“阅读原文”进入活动详情页。














 2160
2160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









