






 HPM是一种新的自监督掩码图像建模方法,通过困难样本挖掘策略,让模型自动选择挑战性区域进行预测,提高预训练任务的难度,从而增强模型的表示能力。该方法已被CVPR2023接收,并开源代码。实验显示,无论选择何种重建目标,HPM都能通过增加代理任务的难度来提升性能。
HPM是一种新的自监督掩码图像建模方法,通过困难样本挖掘策略,让模型自动选择挑战性区域进行预测,提高预训练任务的难度,从而增强模型的表示能力。该方法已被CVPR2023接收,并开源代码。实验显示,无论选择何种重建目标,HPM都能通过增加代理任务的难度来提升性能。

©作者 | 王淏辰
今天介绍我们在自监督掩码学习(Masked Image Modeling)领域的一篇原创工作 HPM (Hard Patches Mining for Masked Image Modeling)。
各种自监督掩码学习方法的性能强烈依赖于人工定义的掩码策略,而我们提出一种新的困难样本挖掘策略,让模型自主地掩码困难样本,提升代理任务的难度,从而获得强大的表征提取能力。目前 HPM 已被 CVPR 2023 接收,相关代码已开源,有任何问题欢迎在 GitHub 提出。

论文标题:
Hard Patches Mining for Masked Image Modeling
录用信息:
CVPR 2023, https://arxiv.org/abs/2304.05919
代码开源:
https://github.com/Haochen-Wang409/HPM

Introduction
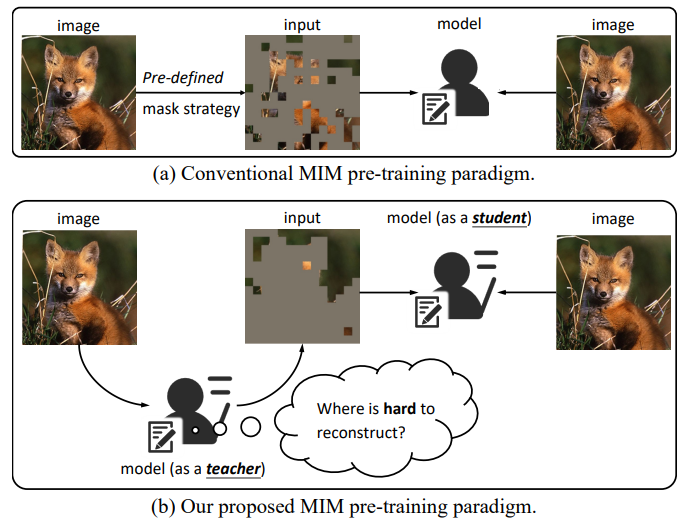
▲ Figure 1. Comparison between conventional MIM pre-training paradigm and our proposed HPM.
在典型的 MIM 方法中,模型通常专注于预测 masked patches 的某一形式的 target (例如 BEiT[1]的离散 token,MAE[2] 的 pixel RGB)。而由于 CV 信号的稠密性,MIM 方法通常需要预先定义的掩盖策略,以构造具有挑战性的自监督代理任务。否则,一个简单的插值就能完成对于 masked patches 的重建。总的来说,整个 MIM 的过程可以被认为是训练一个学生(模型),解决给定的问题(重建 masked patches),如上图 (a) 所示。
然而,我们认为,模型不应该只专注于解决给定的问题,还应该站在老师的立场上,具备自己出具挑战性问题的能力。通过创造具有挑战性的问题并解决这些问题,模型可以同时站在学生和老师的立场上,对图像内容有一个更全面的理解,从而通过产生一个高难度的代理任务来引导自己提取更加可扩展的表征。为此,我们提出了Hard Patches Mining(HPM),一个全新的MIM预训练框架,如上图 (b) 所示。
具体来说,给定一个输入图像,我们不是在人工设计的标准下生成一个 binary mask,而是首先让模型作为一个老师,自主产生掩码;然后像传统方法一样,让模型作为一个学生,让它重建 masked patches。
接下来,该问题就转化为了如何评判某一个 patch 是否为困难样本。我们自然地想到:「如果某一 patch 难以重建,即重建 loss 较大,则它为困难样本」。

▲ Figure 2. For each tuple, we show the (a) input image, (b) patch-wise reconstruction loss averaged over 10 different masks, (c) predicted loss, and (d) masked images generated by the predicted loss.
如上图所示,我们发现一张图片中 discriminative 的区域(前景)往往是难以重建的。因此,只要让模型「预测每个 patch 的重建损失」,进而 mask 掉那些高重建损失的 patch,就得到了更加具有挑战性的代理任务。
因此,我们引入了一个辅助的 loss predictor,用以预测每个 patch 的重建损失。

Method
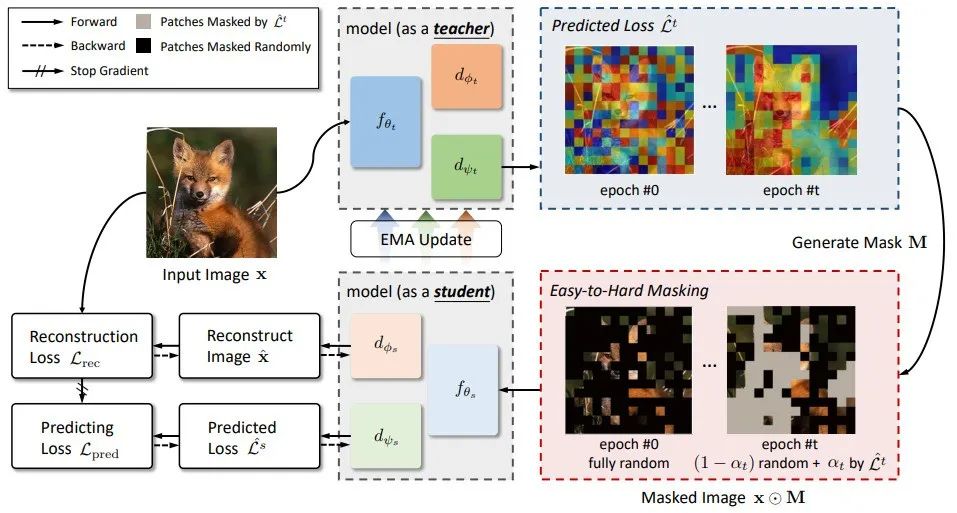
▲ Figure 3. Illustration of our proposed HPM.
HPM 包含一个学生模型和一个老师模型,它们共享网络结构,包含 encoder ,图像重建 decoder ,损失预测 decoder 。老师模型的参数是由学生模型指数平滑更新而来的。
每次迭代,一张图片首先打成 patch,并经过老师模型,得到每个 patch 预测的重建损失。进而,基于该预测,产生当前的 binary mask ,用于 MIM 任务。损失函数包含两项:
,
其中 表示重建损失,是标准的 MIM 损失;而 表示的是重建损失预测损失。

图像重建
其中 表示产生的 binary mask, 表示 element-wise dot product,因此 表示的是 visible patches。 表示的是某种产生 target 的 transformation,例如 MAE 中就是一个恒等映射,而 BEiT 中则是将图像转化为离散的 token。, 表示某种度量,如 MAE 中用的 距离,SimMIM[3]中用的 smooth 距离。

重建损失预测
4.1 绝对损失
一种最直观的方法就是直接最小化真实重建 loss 和预测的重建 loss 之间的 MSE,即
其中 表示的是学生模型的 loss predictor,而这里的 已截断梯度。
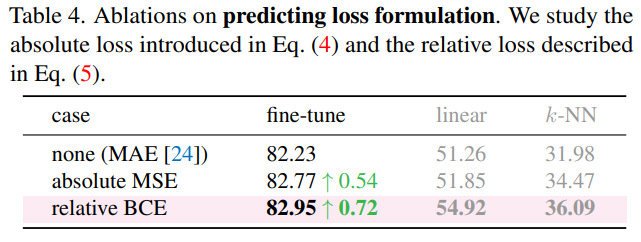
然而,回顾一下,我们的目标是确定图像中的困难样本,因此我们需要学习 patch 之间的相对关系。在这种情况下,MSE 并不是最合适的选择,因为 的 scale 会随着训练的进行而减少,因此损失预测器可能会被其 scale 和准确值所淹没,而忽略了提取 patch 间的相对大小。为此,我们提出了一种基于二元交叉熵的相对损失。
4.2 相对损失
给定一张含有 N 个 patch 的图片,其真实的重建损失为,我们的目的是预测这 N 个 patch 之间重建损失的相对大小,即 。然而, 并不可导,我们将问题转化为了「dense relation comparison」,即预测两两 patch 之间的大小关系。
其中 表示的是学生模型输出的损失预测值,而 i, j=1,2, 是 patch indexes。 是 函数,即 。 和 是两个指示函数,表示 patch i 和 patch j 的真实重建损失大小,定义如下:
其中 表示的是 patch i 和 patch j 都应当是被 masked 的。

掩码产生:easy-to-hard
一个自然的想法就是每次迭代过程中,先基于老师模型计算 ,然后 top-75% 的 patch 都 mask 掉。然而,在早期训练阶段,学到的特征表征容易被丰富的纹理所淹没,这意味着重建损失与判别性还没有建立起相应的关系。为此,我们提出了一种由易到难的掩码生成方式,提供一些合理的提示,引导模型一步一步地重建掩码的硬块。
具体来说,假设 mask ratio 为 ,则在 t 次迭代,我们 mask 掉 最大的 个 patch,剩余 个需要 mask 的 patch 则随机产生。
整个训练过程的伪代码为:



Experiments
6.1 消融实验
这一部分,我们以 ViT-B/16 为 backbone,以 ImageNet-1K 上 pre-train 200 epochs 为默认配置。
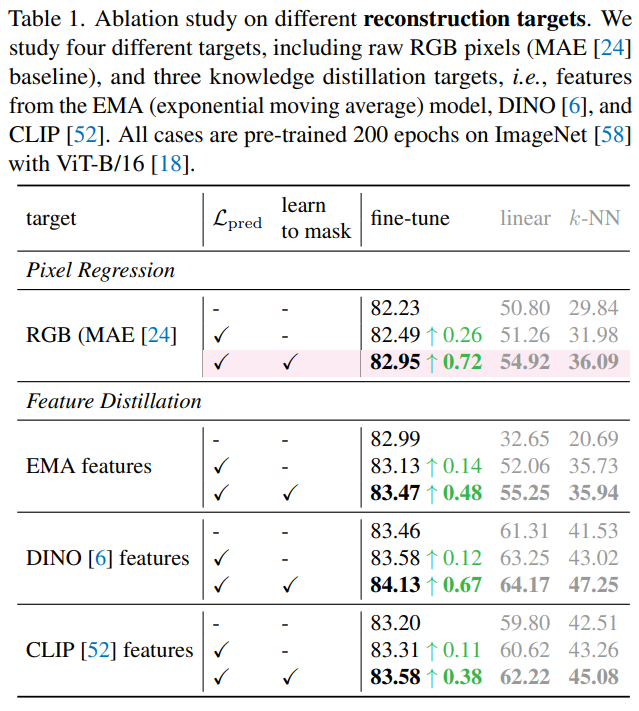
重建目标的消融。我们发现,不管以什么为重建目标,加入 作为额外的损失,并基于此进一步产生更难的代理任务均能获得性能提升。值得注意的是,仅仅引入一个额外的 objective 也能够带来 consistent 的性能提升,表明挖掘困难样本的能力本身,就能够促使习得更好的特征表示。这一点不仅在分类任务上得到体现,下游任务(检测分割)也有相应的体现。
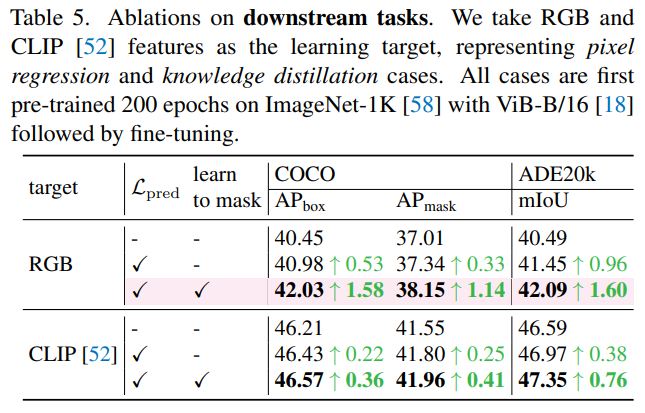
掩码策略的消融。我们发现,难度大的代理任务确实能够带来性能提升,但保留一定的随机性也是同样必要的。这些结论是非常直观的。直接掩盖那些预测损失最高的 patch 虽然带来了最难的问题,但图像 discriminative parts 几乎被掩盖了,这意味着 visible patches 几乎都是背景(见图2)。在没有任何提示的情况下,强迫模型只根据这些背景来重建前景是没有意义的。
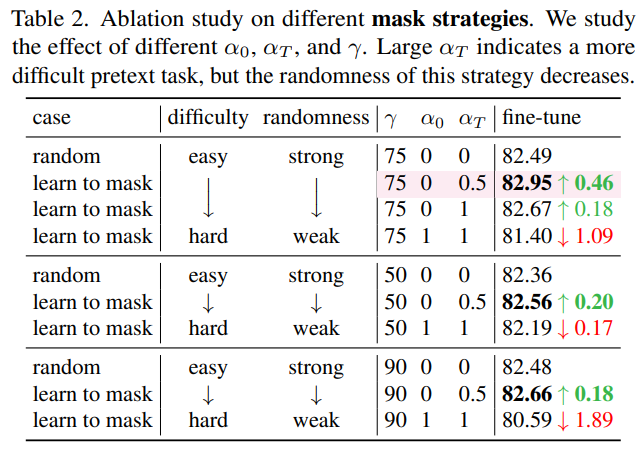
进一步地,我们探究「难」的代理任务对于 MIM 是否有帮助。其中, 表示这个任务甚至简单于 random masking,会导致性能退化。类似的,hard-to-easy 也会导致性能退化。
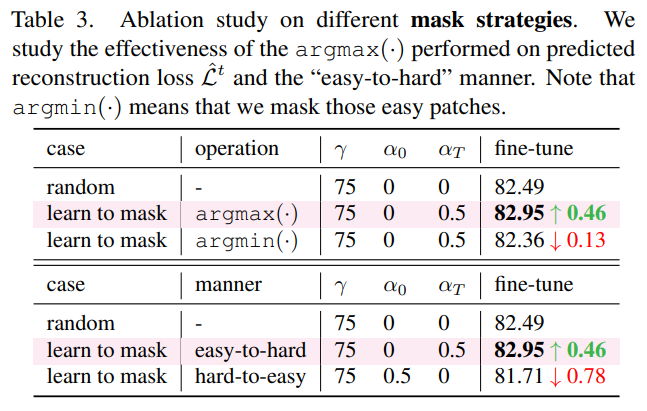
预测损失的 formulation。MSE 相较于 baseline 能够有提升,但 BCE 是一个更好的选择。
Comparison with state-of-the-art methods

下面,给出了一些预测损失的可视化。可以看出,预测损失很好的反应了物体的前景部分。



参考文献
[1] Hangbo Bao, Li Dong, and Furu Wei. Beit: Bert pre-training of image transformers. In International Conference on Learning Representations (ICLR), 2022
[2] Kaiming He,Xinlei Chen,Saining Xie,Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
[3] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
更多阅读



🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 5322
5322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









