







 本文汇总了CVPR 2023中关于掩码图像建模的最新研究,涉及深度模型的不同层学习、预训练与微调的迁移差异、生成模型与表示学习的融合、知识蒸馏策略以及视频和点云领域的应用。通过这些研究,揭示了在计算机视觉中预训练模型的改进方法和新应用场景。
本文汇总了CVPR 2023中关于掩码图像建模的最新研究,涉及深度模型的不同层学习、预训练与微调的迁移差异、生成模型与表示学习的融合、知识蒸馏策略以及视频和点云领域的应用。通过这些研究,揭示了在计算机视觉中预训练模型的改进方法和新应用场景。

©PaperWeekly 原创 · 作者 | GlobalTrack

CV领域一般改进

论文标题:
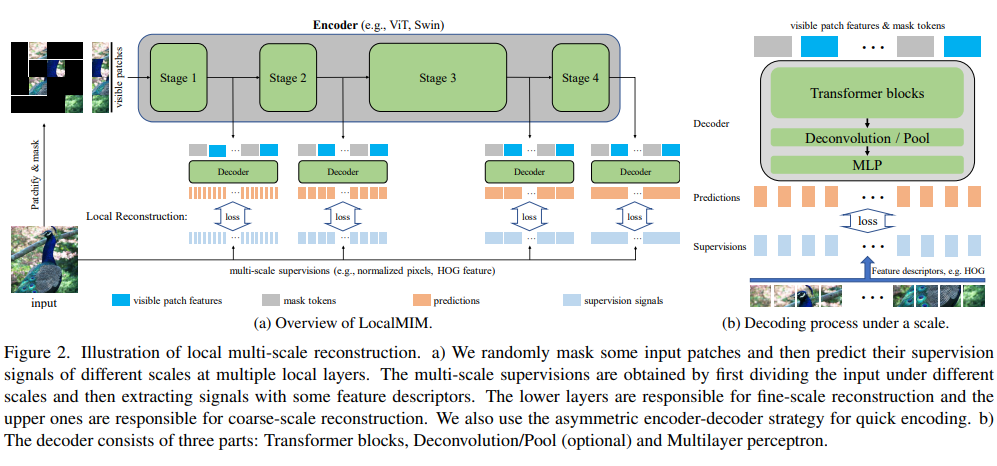
Masked Image Modeling with Local Multi-Scale Reconstruction
论文链接:
https://arxiv.org/abs/2303.05251
代码链接:
https://github.com/Haoqing-Wang/LocalMIM
本文指出深度模型上层和下层架构重要性是不同的。微调阶段上层可以快速适应下游任务而下层变化较为缓慢。考虑将重建任务同时应用于上层和下层架构,以明确指导。具体地,在预训练阶段,上层和下层分别学习细尺度和粗尺度监督信号。

论文标题:
Integrally Pre-Trained Transformer Pyramid Networks
论文链接:
https://arxiv.org/abs/2211.12735
代码链接:
https://github.com/sunsmarterjie/iTPN
本文指出 MIM 任务预训练的一个关键问题是上有预训练任务和下游微调任务间的迁移差异。下游任务需要分层视觉特征,而基于 MIM 自监督学习的模型一般缺少此类特征。本文给出一种同时训练 backbone 和颈部模块的算法。本文也需要给各阶段颈部模块添加重建损失。这里指导特征图选择为教师模型对应阶段的特征图输出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









