







©PaperWeekly 原创 · 作者 | 衣景龙
单位 | 腾讯
研究方向 | 自然语言处理

业务背景
▲ 图1. 精品区
▲ 图2. 短视频综合区
腾讯视频搜索结果产品展示形态如上图所示,列表页结果主要包括长视频(精品)模块和短视频(综合区)模块,用户发起一次检索后,会经过如下流程,
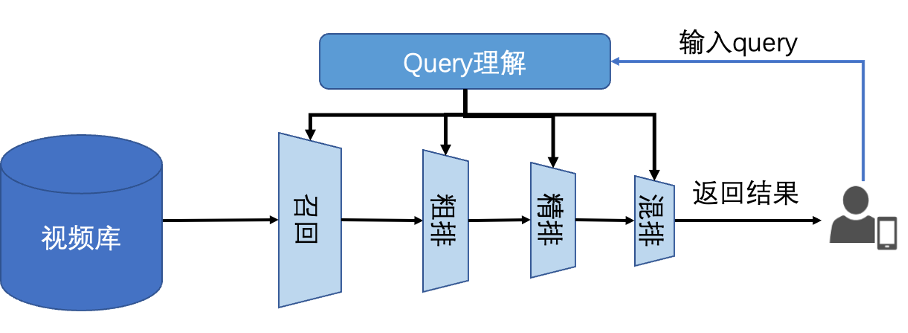
首先会经过 query 理解模块进行 query 处理,包括文本分词、实体识别、图谱识别等,然后召回模块会根据文本信息等从视频库中召回上万视频,经由粗排、精排、混排等阶段,最终获得数十个视频排序结果呈现给用户。相关性是衡量视频搜索结果的重要参考依据,直接影响到用户体验,所以在粗排、精排、混排阶段都用到了相关性模型的提供的相关性信息,本方案主要用于其中的粗排模块。
对于精品召回结果,粗排阶段会直接截断粗排相关性得分较低的视频;对于短视频召回结果,粗排阶段则先按照粗排相关性得分对视频进行分档,档内再依据粗排 ctr 等模型进行排序。
因此,粗排相关性模型对视频能否进入精排阶段,以及最终如何排序有着重要的影响。

What's 双塔?
当前业界的相关性计算模型(其他的点击率、时长等也一样)百花齐放,百家争鸣,但总结其架构特点无非就是两种:单塔与双塔。
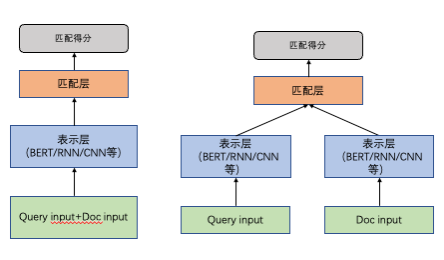
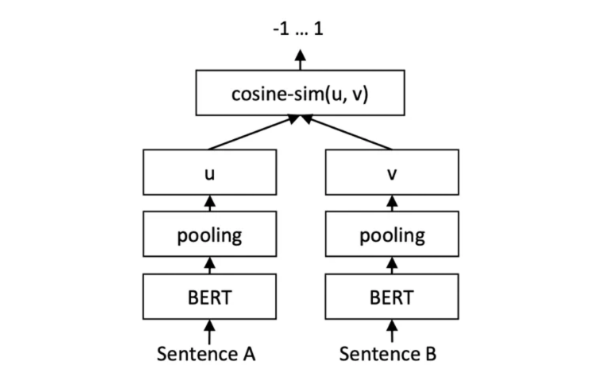
如图,相比于单塔模型将 Query 与 Doc 输入 concat 起来一并送入语言模型进行打分,双塔模型最大的特点就是 “Query 和 Doc 是独立的两个编码网络”,左侧是 Query 塔,右侧是 Doc 塔。这两个塔的参数共享/不同享,他们分别输出 Query Embedding 和 Doc Embedding。然后计算这 2 个 Embedding 的相似度,典型的工作如:Sbert [1]。
计算相识度的方式也有多种方案,如用简单的点积操作、Cosine 相似度计算,或者是用比较复杂的 MLP 结构。

Why 双塔?
双塔模型相比于单塔模型,最明显的优势在于我们可以在离线的时候获取到 doc embedding,这样便可以提前存入到数据库中。所以使用双塔模型时不需要像单塔模型那样实时计算 embedding,而是只需要从数据库中检索对应的 Embedding,在线上与 query embedding 进行互操作就可以了,所以大大提高了运算效率,实际应用中非常容易落地,成为“召回”+“粗排”的绝对主力模型。但同时,双塔模型的优点也变成了制约自身的缺点:
缺点一:模型使用的特征缺少交叉组合类特征
一般在做搜索推荐模型的时候,会有些特征工程方面的工作,比如设计一些 Query 侧特征和 Doc 侧特征的组合特征,一般而言,这种来自 Query 和 Doc 两侧的组合特征是非常有效的判断信号。但是,如果我们采用双塔结构,这种人工筛选的,来自两侧的特征组合就不能用了,因为它既不能放在 Query 侧,也不能放在 Doc 侧,这是特征工程方面带来的效果损失。
缺点二:Query 和 Doc 发生特征交叉的时机太晚,可能会丢失一些细节特征
如果是精排阶段的 DNN 模型,来自 Query 侧和 Doc 侧的特征,在很早的阶段,比如第一层 MLP 隐层,两者之间就可以做细粒度的特征交互。但是,对于双塔模型,两侧特征只有在 Query Embedding 和 Doc Embedding 发生内积的时候,两者才发生交互,而此时的 Query Embedding 和 Doc Embedding,已经是两侧特征经过多次非线性变换,糅合出的一个表征用户或者 Doc 的整体 Embedding 了,细粒度的特征此时估计已经面目模糊了,换句话说,两侧特征交互的时机太晚了。
我们知道,Query 侧和 Doc 侧特征之间的交互,是非常有效的判断信号。而很多领域的实验已经证明,双塔这种过晚的两侧特征交互,相对在网络结构浅层就进行特征交互,会带来效果的损失。
接下来我们会在下文中提到针对上述的缺点我们是如何在腾讯视频粗排相关性模型中进行改造或者缓解的。

前情提要
下一篇文章我们将详细介绍腾讯视频相关性模型的训练数据和多阶段精调方法,所以在本篇中本文不再展开。简而言之,我们的模型训练阶段是预训练+一次精调+二次精调,与此对应的训练数据是我们的腾讯视频 doc 数据和经过 deepwalk、clicksim、ctr 判断等方式挖掘出来的 query/doc 匹配数据,及人工标注数据。在训练目标上,我们采取了多任务学习的方式,用于提升模型的语义理解能力,进而提升语义匹配任务的效果,我们目前的模型架构是基于 SimCSE [2] 训练方式的 sbert 双塔架构。
接下来我们将介绍我们如何改造双塔模型来克服前文中提到的几个缺点,主要方式如下:
1. 训练大模型增强语义判别能力,然后蒸馏到线上小模型,用以弥补双塔语义判别能力不足的问题。
2. 向精排模型看齐,用以弥补不能使用交叉特征的“遗憾”。
3. 改进自己的交互层,“穷人的孩子早当家”,用以把当前的编码信息用好。
4. 增加多塔,拓宽信息流通渠道,用以弥补信息流通损失。

以己为师——大模型蒸馏
5.1 Teacher模型
在线上为了平衡计算效率和模型准确率,我们采用了 4 层的 BERT 作为编码器,但是经验表明 4 层 BERT 的表征能力一般来讲是不如 12 层 BERT 的。故我们采用了 12 层 BERT base 模型在数据集上进行训练,然后用该 BERT 模型的训练结果来指导我们线上 BERT 模型(4 层)的训练,在训练 teacher 模型的时候,我们对学习率进行了调整,以防止模型过拟合,导致句子向量在向量空间中坍塌。
同时,我们采取了 child tuning [3] 的方式来增加模型的泛化能力。简单的来说就是把 dropout 加入到梯度的反向传播中,在每一步的更新迭代中对反向梯度进行伯努利采样,相当于对网络参数更新时随机地将一部分梯度丢弃。还有一种方式是任务相关的采样,针对不同的下游任务自适应地进行调整,选择出与下游任务最相关最重要的参数来充当 Child Network。
具体的,是通过计算梯度变化的累计值,引入 Fisher Information Matrix(FIM) 来估计每个参数对于下游任务的重要性程度,之后选择分数最高的那部分参数作为 Child-Network,在后续的迭代过程中,只对这一部分参数进行更新。我们尝试了两种方式最后选取了第一种,使 AUC+0.4。
除此之外,受陈丹琪新作《Should You Mask 15% in Masked Language Modeling?》[4] 的启发,我们也针对预训练阶段的 BERT 尝试不同的 MASK 比例,经过实验,选定了合适的 mask rate,最终使 AUC+0.5,Teacher 模型的 Auc 当前为 86.18。
5.2 Student模型
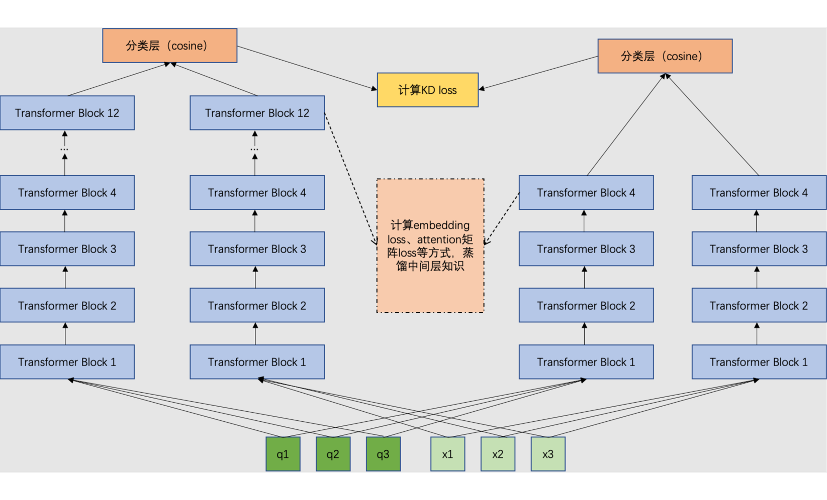
点击数据的组织类型为 pairwise 样本。如上图所示,我们在当前的任务上,多加了一个损失(knowledge distill loss),用 teacher bert 的正负样本得分来指导 student bert(要上线的)正负样本得分,使 acu+1.99。
因为用于精调的数据来自于搜索点击日志,因此无法保证正负样本的准确率。因此在上一个版本中我们采用更为准确的人工标注数据,构建训练集,对模型进行二次精调,取得了不错的效果。但人工标注数据比较少,直接采用上述的蒸馏策略,只学习 teacher 模型对样本对的打分,会导致 student 模型学到知识不够,进而导致性能提升不够明显。
所以我们修改了我们的蒸馏策略,student 模型不仅仅要学习 teacher 模型对正负样本对的打分,而且要学习一个 batch 内,每一个 query 与其他所有 doc 的相似度得分,这样可以让student模型学到teacher所携带的更多的知识。最终 auc+1.42%→83.82%。

以人为师——精排模型蒸馏
前文提到过,双塔模型缺乏交叉特征,而我们的精排相关性模型是单塔模型,是加入了许多的交叉特征的,所以用精排相关性模型来指导粗排相关性模型,一定程度上可以弥补粗排模型缺乏交叉特征的不足,从而提升模型的语义能力,与此同时,还涉及到一个一致性的问题。
我们的整个搜索排序系统类似于一个漏斗状系统,包括召回、粗排、精排以及混排四个阶段,每个阶段都像是一个漏斗,从海量的视频集合中过滤出用户最有可能感兴趣的视频送给下一阶段,所以如果我们的粗排相关性与精排相关性的一致性较差,那么最终可能会导致模型做“无用功”(送到上层的精排后都被精排打压了),甚至出现粗排优化越好,精排结果越差的“负优化”现象。因此我们需要重视对粗排与精排“一致性”的评估。
对此,我们在离线相关性人工评测数据上进行分析,发现若以精排相关性打分为序,统计粗排相关性打分在此序下的正序对占总序对比重,大约只有 70.50%。分析原因主要有二:
1. 特征集合的差异:粗排相关性模型因为双塔结构的限制,只用了 query/doc 单侧特征,仅有文本侧特征,包括 doc title、doc father_column_title、doc tags 等,而精排相关性模型则在使用了这些特征之外又用到了文本长度、query/doc ner/kg 个数统计等单侧特征以及 query/doc ner/kg 覆盖个数统计,click sim 等交叉特征。
2. 模型结构的差异:粗排相关性模型是双塔 BERT 加一个浅层交互网络,这就限制了模型所使用的往往只有 query/doc 单侧特征,且交互相对较浅,而精排相关性模型使用的是单塔 BERT 网络,query 与 doc 从最开始就得到交互,且在上层通过 DNN 网络融入了其余的单侧特征和交叉特征。
综合以上分析,为了尽量弥补粗排模型和精排模型的 Gap,缩小粗排模型和精排模型预估结果的差异性,同时弥补粗排模型缺乏交叉特征的不足,我们采用知识蒸馏的方式对粗排相关性模型进行了一系列的升级和优化。
我们将精排相关性模型作为 teacher 模型,粗排相关性模型作为 student 模型;将精排学到的知识 transfer 到粗排中,拉近粗精排之间的距离,用以提高一致性;另外,实践过程中我们发现在模型训练的后期,我们可以逐步增大蒸馏 loss的影响,从而使得粗排模型的预估值更好的向精排模型靠近,同时模型对 query/doc 相关性的判别能力几乎没有损失。
经过大量实践,我们的模型一致性优化训练示意图如下,student loss 是粗排相关性模型自带的对比学习 loss、mask language loss、query ner loss 等,在训练后期模型已经获得了大量相关性语义知识以后,我们取消了 student loss,只保留 distill loss,从而扩大了精排模型对粗排模型的影响,最终我们实现在点击数据上 auc+1.28%->85.41%,在人工标注数据上 auc+0.74%->86.15%,正序对占比 +5.37%->75.87%,在线实验人均短视频时长累计提升 2.27%。

打铁还需自身硬——模型加入后交互层
虽然双塔缺乏交叉特征、信息流动有所损失,但即使如此,正所谓“穷人的孩子早当家”,若我们能把当前的编码信息用好,也会显著提升现有模型的语义匹配能力。
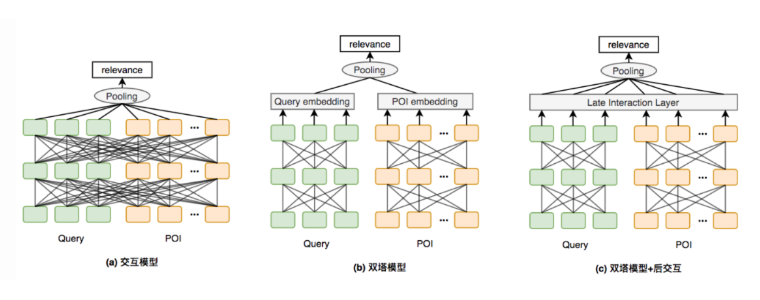
此前提到,在语义匹配领域,双塔模型与单塔模型各有各的优缺点,单塔的模型优势在于 query 与 doc 能在模型中进行交互,从而提高了模型判别能力,但是缺点在于语义向量需要实时计算,所以效率比较低,从而产生了双塔模型,双塔模型由于 query 和 doc 缺乏交互,所以语义匹配的准确率往往会有所下降,但是由于语义向量可以提前计算并进行缓存,所以大大提高了运算效率。
近期,许多学者和从业者开始尝试将两者的优势结合起来,主要思想之一就是在双塔模型之后,加入后交互层,从而让 query 与doc 有一定的交互,这是随着算力越来越充足,人们对计算效率和模型准确率进行一个再平衡的必然趋势。类似工作有 ColBERT [5]、Poly-encoders [6] 等。
那么如何增加后交互层呢,我们探索出了如下两点改进:
1. 多头(multi-head)的思想,释放信息量,缓解“一词多义”问题。
2. 改进现在的仅仅只是点乘的匹配层,增加匹配层匹配能力,经过多轮的优化迭代,我们现在的算力已经支持我们进行该探索。
7.1 多头(multi-head)思想
由于腾讯视频搜索中的 query 都比较短,且往往存在一词多义的问题,例如:开端、猎狐等,我们无法得知其代表一部剧及其短视频还是某部剧的部分 title,异或是直接是另一部剧。
只由一个向量来表征其含义,往往不足,有可能同一个 query 在不同的 query-doc 对中,被不断的拉扯到不同的距离上,基于此,我们提出了一个改进,借鉴了 transformer 中 multi-head 的思想,当 query 经过 bert 提取出语义向量之后,我们通过不同的全连接层(head)将其映射到不同的向量空间中,使不同的 head 捕捉 query 不同的语义,从而缓解其一词多义的问题,例如:小猪佩奇可以是动画片,也可以是玩具视频。
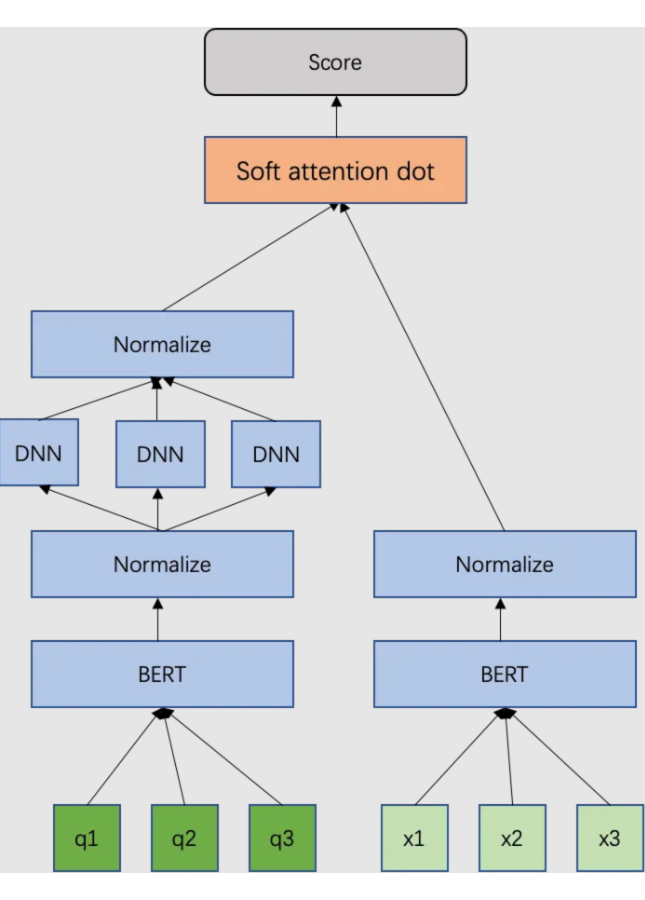
Soft attention dot 表示一个简单的 attention 机制,将点成积结合起来,公式如下:
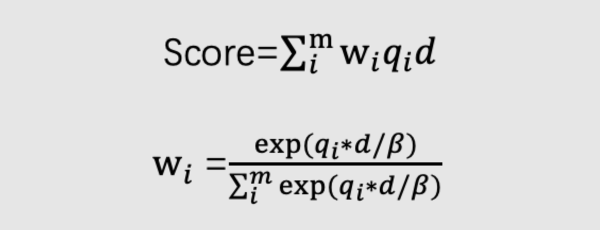
d 为 doc 向量,qi 为第 i 个 head 产生的 query 向量,β 为温度系数。
同上所述,既然 query 存在一词多义的问题,那么 doc 可能也同样会存在,所以我们将对 query 的多头操作复制到 doc 上,此时我们会获得一个 nq*nd 的匹配矩阵(nq 为query 的 head 数目,nd 为 doc 的 head 数目),我们利用上述的 soft attention dot 机制来获取最终打分,最后使 auc+1->84.82。
7.1.1 多头机制探究
前文提到过,我们提出多头机制的主要原因是我们希望每个头,只关注最终输出序列中一个子空间,互相独立,由于不同头之间参数不共享,所以允许模型在不同的表示子空间里学习到相关的信息,期待通过这种方式通过将 query/doc 表征映射到不同的向量空间中,使不同的 head 捕捉 query 不同的语义,对此,我们研究了多头的彼此之间的正交性用于验证我们的猜想。
我们在相关性数据上采样出 6w 余 query 与 doc,inference 其不同头的 embedding,然后计算每个 query 自己的 3 个头之间的 cos 相似度,最后计算点乘矩阵均值,得出如下矩阵:
array([[ 1.00000012, -0.00871744, -0.2434016 ],
[-0.00871744, 0.9999997 , 0.21546192],
[-0.2434016 , 0.21546192, 0.99999982]])
其中array[i][j]代表第i个头与第j个头的cos相似度,可以看到不同的头之间是接近正交的。
同时,doc的相似度矩阵如下,也可以得到一样的结论:
array([[ 0.99999999, -0.04584159, -0.18707253],
[-0.04584159, 1. , 0.29358823],
[-0.18707253, 0.29358823, 0.99999999]])
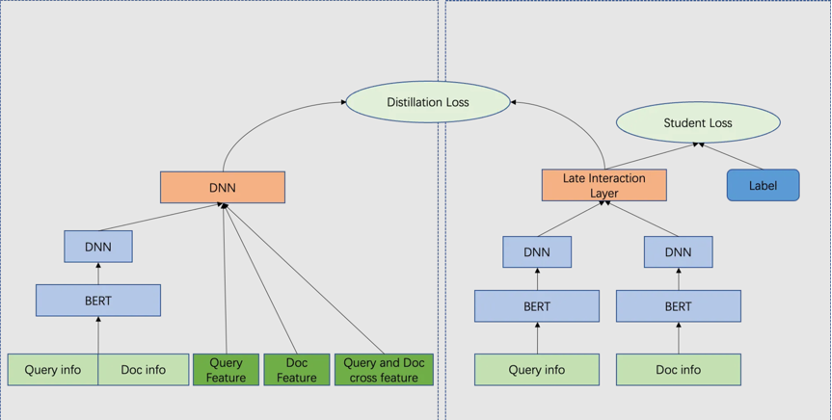
此时,基本已经验证了我们的猜想.7.2 匹配层改进关于匹配层的改进,我们借鉴了基于匹配矩阵模型的思想,以 ESIM [7] 为例,模型直接进行句子交互,获得匹配矩阵(matching matrix),再通过神经网络计算语义匹配程度,在此处输入的 word emb 为我们的 head embedding。
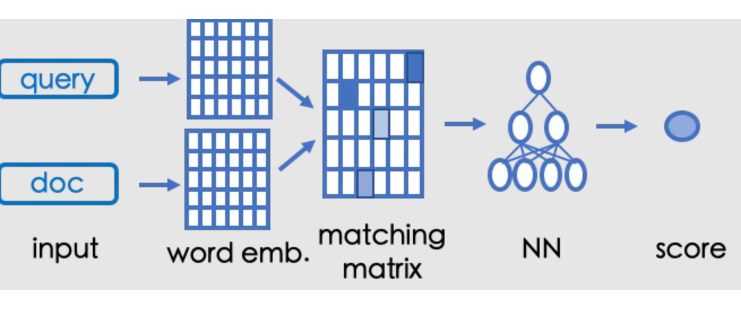
ESIM 模型交互相比于直接点乘的方式优点是交互充分,能够突出核心 term,语义匹配效果好,相比于 soft attention dot 的方式,该模型 auc 提升 0.59。缺点是计算复杂度较高,在线计算压力较大,但此时得力与粗排工程同学的持续优化,极大释放了粗排的计算压力,我们已经可以通过模型压缩的方式使该模型上线,最终模型上线后,精品点击率提升 0.3%,短视频时长提升 2.59%。
7.3 模型压缩
为了与工程的同学一起将模型顺利上线,满足在线的高并发低延时要求,我们从四个方面对模型进行了优化:包括等价替换算子(尽可能多的用矩阵乘法),以利用 mkl 加速;减少 head 数目及降维层参数等;尝试不同的 pooling 方式;以及尝试不同的增强对齐信息的方法,最终在控制 auc 不降的情况将 FLOPs 由 180358 降低到 65570,在离线侧 batch size 为 400 的情况下单次预测耗时减少 37%。

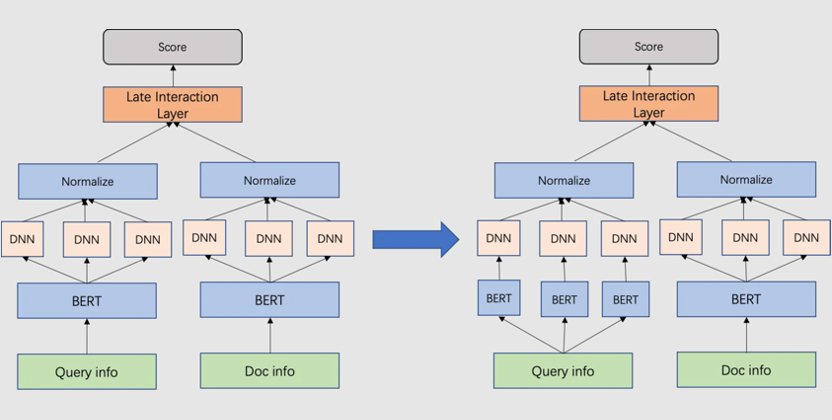
强强联合——拓宽信息流通渠道
上文提到双塔模型一大缺点就是塔两侧信息交叉得太晚,信息在塔中向上流动的过程,也是一个信息压缩的过程,不可避免地带来信息损耗,等到最终能够通过匹配层或 cosine 交叉的时候,一些细粒度的信息已经在塔中被损耗掉。
所以,双塔改建最重要的一条主线就是:如何保留更多的信息在 tower 的 final embedding 中。那么我们会自然而然的想到,我们是否可以拓宽塔的宽度或者个数,让不同粒度/方面的信息能够沿着不同的道路(塔)向上走,那不就可以大大减少信息在向上流动过程中的损耗了么?
8.1 引入多模态特征
视频搜索怎么可以只有文本特征?谈到要拓宽信息流动渠道,我们第一个便会想到在视频搜索中拓宽视频多模态特征,腾讯视频中的多模态预训练模型将在另一篇文章中进行介绍,本文在此不做赘述,可以暂时将该模型认为是一个产出携带多模态视觉信息的 embedding 的工具,在此只谈谈如何将该模型作为粗排模型的信息流通渠道并在上层融合信息。
来自 Facebook 的 21 年的论文 Que2Search [8] 为我们做出了一个很好的示范,在 Que2Search 中,引入了商品封面的多模态信息,以及 country 的信息,不同信息通过不同通道向上传递,比如 country 这样的 categorical 特征直接 embedding,而文本信息则通过 XLM。不同通道得到各自的 embedding,再融合(fusion)生成 final embedding,与对侧塔得到的 final embedding 计算 cosine similarity。
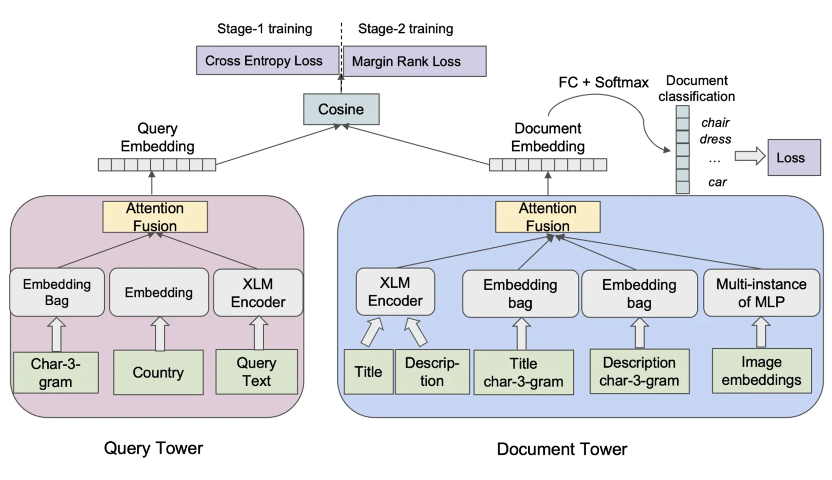
而在融合多塔 embedding 生成 final embedding 时,Que2Search 也提出 Simple Attention Fusion 方案,并通过实验证明,比传统的 concatenation+mlp 方案有效。Simple Attention Fusion 的方案如下图所示,'f' 是各通道融合后的 final embedding。

我们在腾讯视频搜索的粗排融合中尝试了如上方案,将多模向量经过一个 MLP 层做正则化,然后做 simple attention,此外还尝试了将该向量作为 ESIM 匹配层输入中的一个 token embedding,最后证明确实是 Simple Attention Fusion 方案更优,目前离线 auc 取的 0.2 的提升,正在线上实验。
8.2 多塔编码
对比 Facebook 2020 年经典论文《Embedding-based Retrieval in Facebook Search》[9] 和 Que2Search,可以清晰看到 facebook 经历了一个“拆一个宽塔为多个窄塔”的思路变化。
这种思想也可以被我们借鉴到我们的模型里,在引入多头机制的时候我们的方法是用一个 BERT 进行向量编码然后通过不同的 DNN 映射层映射为不同的 head,但是这种方式总归是有上限的,因为 BERT 向量编码的信息容量总是有限的,某种程度上我们只是在“纸上雕花”,挖掘现有编码下的信息量,那么如果线上允许的情况下,我们是否可以直接进一步将编码塔就拓展为更多的塔,这样扩宽了信息流动渠道,理论上限编码信息量变为原有单塔编码的多倍。
由于对 Doc 的多塔编码会使线上存储空间扩展为原来的三倍,所以我们目前只在 query 侧进行实验,目前 auc 可以持平现有模型的 auc,正序比略高于现有模型,相信随着训练的持续进行该模型一定会取得比现有模型更好的效果。

总结展望
本文回顾了双塔模型的“前生今世”,讲述了为何我们要选用双塔,同时双塔存在哪些缺点,我们在开发时应该如何尽量避免,正如前文提到的,主要缺点有二:一是缺乏交叉特征;二是到信息交互的时候,信息损失太多,但事物的发展总是辩证统一的,有缺点也不掩盖其利于线上部署,实时性高的巨大优点。
虽然有阿里 COLD [10] 等模型开始尝试告别双塔,直接利用特征筛选+单塔模型摆脱双塔的两大缺点,但对线上的改造和工程优化恐怕并非那么简单,所以我们现在还远远没有到完全可以抛弃双塔架构的时候,现在依然有很多研究双塔的文章不断涌现,例如:美团在 2021 KDD 上发表的论文对偶增强双塔 [11] 通过在 query 塔构造向量来表征所有与 query 正向交互的 doc 信息,doc 塔亦然,通过这种方式来减少信息损失,以及我们接下来也将尝试离线计算的 doc 塔做大,query 塔不变的非对称多塔的方式来减少信息损失等。
总而言之,业界对双塔的研究依然在如火如荼的进行中,希望本文能对致力于研究双塔、改进双塔、利用双塔的同学们能够有所启发,若有任何问题也欢迎直接联系我讨论交流。

参考文献
[1] Reimers N, Gurevych I. Sentence-bert: Sentence embeddings using siamese bert-networks[J]. arXiv preprint arXiv:1908.10084, 2019.
[2] Gao T, Yao X, Chen D. Simcse: Simple contrastive learning of sentence embeddings[J]. arXiv preprint arXiv:2104.08821, 2021.
[3] Xu R, Luo F, Zhang Z, et al. Raise a child in large language model: Towards effective and generalizable fine-tuning[J]. arXiv preprint arXiv:2109.05687, 2021.
[4] Wettig A, Gao T, Zhong Z, et al. Should You Mask 15% in Masked Language Modeling?[J]. arXiv preprint arXiv:2202.08005, 2022.
[5] Khattab O, Zaharia M. Colbert: Efficient and effective passage search via contextualized late interaction over bert[C]//Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 2020: 39-48.
[6] Humeau S, Shuster K, Lachaux M A, et al. Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring[J]. arXiv preprint arXiv:1905.01969, 2019.
[7] Chen Q, Zhu X, Ling Z, et al. Enhanced LSTM for natural language inference[J]. arXiv preprint arXiv:1609.06038, 2016.
[8] Liu Y, Rangadurai K, He Y, et al. Que2Search: fast and accurate query and document understanding for search at Facebook[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2021: 3376-3384.
[9] Huang J T, Sharma A, Sun S, et al. Embedding-based retrieval in facebook search[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2553-2561.
[10] Wang Z, Zhao L, Jiang B, et al. Cold: Towards the next generation of pre-ranking system[J]. arXiv preprint arXiv:2007.16122, 2020.
[11] Yu Y, Wang W, Feng Z, et al. A dual augmented two-tower model for online large-scale recommendation[J]. DLP-KDD, 2021.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









