







 随着大型语言模型(LLM)在人类语言处理中的成功,研究者开始将其应用到分子领域,尤其是药物发现。通过深度生成模型,如RNN、Transformer和自监督学习,模型能够学习并生成复杂分子,优化药物设计。预训练模型如Chemformer和MolGPT等在分子生成和性质预测中展现出优越性能,推动了药物研发的效率和质量。这些进展展示了LLM在理解和预测分子语言方面的潜力,有望带来革命性的变化。
随着大型语言模型(LLM)在人类语言处理中的成功,研究者开始将其应用到分子领域,尤其是药物发现。通过深度生成模型,如RNN、Transformer和自监督学习,模型能够学习并生成复杂分子,优化药物设计。预训练模型如Chemformer和MolGPT等在分子生成和性质预测中展现出优越性能,推动了药物研发的效率和质量。这些进展展示了LLM在理解和预测分子语言方面的潜力,有望带来革命性的变化。

随着 ChatGPT 的快速崛起,大型语言模型(LLM)已经在人类语言建模领域展示出了其非凡的能力。无论是证明数学公式、编写代码,还是以不同的风格创作诗歌,LLM 都能胜任。然而,尽管 LLM 在人类语言的掌握上已达到了精通的程度,但在面对分子语言系统时,它仍显得较为稚嫩。
分子语言由数百万个组成成分经过数十亿年的相互作用和演化形成,其复杂性极高,对于人类来说仍然是一个挑战。最近的研究开始尝试将大型语言模型的强大能力扩展到分子领域,试图理解和预测复杂的分子语言,以提高药物发现的速度和质量,从而为该领域带来革命性的变革。
本文梳理了多篇分子语言模型的相关研究,希望能带来更多对 LLM 在药物小分子领域应用发展的深入理解和启发。
01
/ /
论文标题:
Language models can learn complex molecular distributions
论文地址:
https://www.nature.com/articles/s41467-022-30839-x
为了有效地探索庞大的分子空间,深度生成模型,特别是语言模型,已逐渐成为应对此一挑战的最有潜力的手段之一。这些模型能够理解训练分子语言的语法,并获得生成有效且相似的分子的能力,这对于各种下游应用,如设计功能性化合物,具有至关重要的意义。
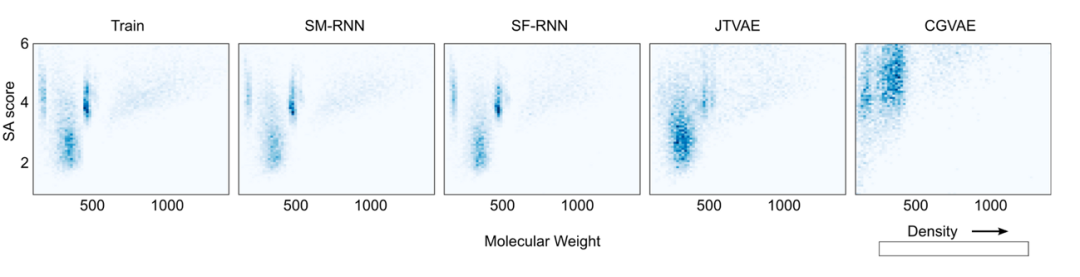
▲ 图1:RNN 模型能更精准地学习训练分布的更多特征,而 CGVAE 和 JTVAE 几乎无法掌握主要分布特征。
在这篇文章中,作者研究了简单语言模型学习分子更复杂分布的能力。为此,作者通过编译更大,更复杂的分子分布来引入几个具有挑战性的生成建模任务,并评估语言模型对每个任务的能力。语言模型可以准确地生成:ZINC15 中得分最高的被惩罚 LogP 分子的分布,PubChem 中最大分子的多模态分子分布。这一发现证明,语言模型具有学习复杂分子分布的强大能力,并且其性能优于图模型。
02
/ /
论文标题:
Chemformer: a pre-trained transformer for computational chemistry
论文地址:
https://iopscience.iop.org/article/10.1088/2632-2153/ac3ffb/pdf
项目链接:
https://github.com/MolecularAI/Chemformer
本研究旨在解决计算化学领域中的资源挑战,通过使用自监督预训练和迁移学习的方法,为各种任务提供一个快速应用的模型。研究者提出了一种基于 SMILES,即“化学语言”的预训练模型——Chemformer。通过自监督预训练,模型可以在下游任务上提高收敛速度和性能。Chemformer 模型基于 BART 语言模型,采用了 Transformer 的 Encoder-Decoder 架构堆栈,可以很好地应用于 Seq2seq 任务,如反应预测和分子优化。同时,BART 模型也可以很容易地应用于判别性任务,如性质预测,只需使用其 Encoder 部分即可。
Chemformer 的训练过程分为两个阶段:自监督预训练和针对下游任务的微调。在自监督预训练阶段,使用大量未标记的 SMILES 数据集,通过三种不同的自监督预训练任务和模型架构进行训练。在针对下游任务的微调阶段,将预训练的 Chemformer 模型应用到特定的下游任务中,并进行微调。在微调过程中,使用了多任务学习的方法,可以同时优化多个任务,提高了化学信息学研究的效率。
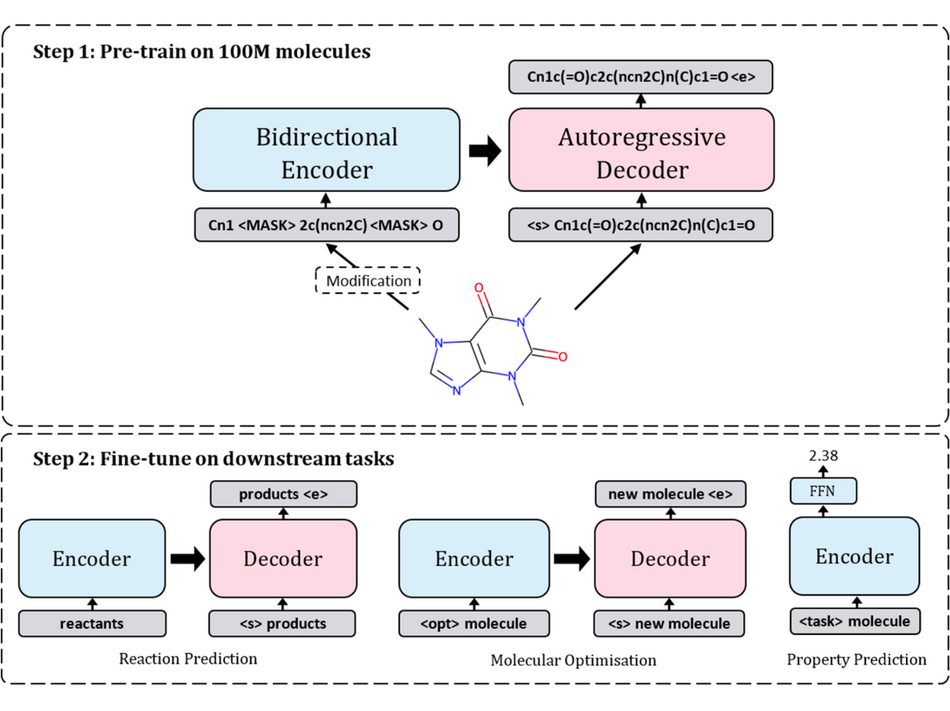
▲ 图2:Chemformer 的模型架构
Chemformer 在化学反应预测、分子优化和性质预测任务上的实验结果表明:Chemformer 模型可以轻松地应用于各种下游任务;自监督预训练可以提高 Chemformer 模型在下游任务上的收敛速度,同时可以显著提高这些任务的结果;当训练时间有限时,迁移学习和新的数据增强策略的组合能够在所有下游 Seq2seq 任务(化学反应预测、分子优化)中产生最先进的结果。
03
/ /
论文标题:
MolGPT: Molecular Generation Using a Transformer-Decoder Model
论文地址:
https://pubs.acs.org/doi/pdf/10.1021/acs.jcim.1c00600
项目链接:
https://github.com/devalab/molgpt
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









