







 本文介绍了研究如何通过数据增强来提高大型语言模型(LLMs)在数学推理任务上的能力,特别是针对GSM8K数据集创建了AugGSM8K,并训练出MuggleMath模型,取得显著成果。然而,尽管数据增强能提升模型在特定领域的性能,但在数学推理的泛化能力方面仍存在局限,表明单一基准的数据增强不足以提升模型的整体数学推理性能。
本文介绍了研究如何通过数据增强来提高大型语言模型(LLMs)在数学推理任务上的能力,特别是针对GSM8K数据集创建了AugGSM8K,并训练出MuggleMath模型,取得显著成果。然而,尽管数据增强能提升模型在特定领域的性能,但在数学推理的泛化能力方面仍存在局限,表明单一基准的数据增强不足以提升模型的整体数学推理性能。

©PaperWeekly 原创 · 作者 | 李成鹏
单位 | 阿里达摩院
研究方向 | 大模型推理
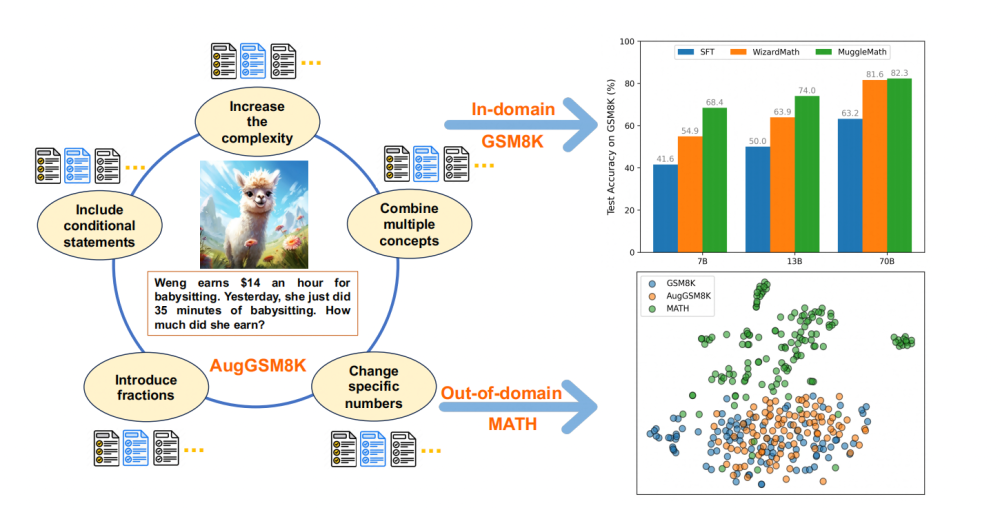
数学推理任务上被认为是闭源模型(如 ChatGPT 和 GPT4)和开源模型(如 LLaMA)最大的差距之一。而基于数学问题的问题或者答案进行数据增强后对大型语言模型(LLMs)进行微调被证实是有效的,这也极大地缩小了开源 LLMs 与闭源 LLMs 之间的差距。
例如,GSM8K RFT [1] 通过对相同的数学问题采样了多样化的推理答案,并利用拒绝采样的方式筛选出答案正确的推理路径,在 GSM8K 数据集上取得了良好的效果。而 WizardMATH [2] 和MetaMATH [3] 则通过对数据集中原有的数学问题进行改编的方式获得些新问题的方式进行数据增强,在 GSM8K 数据集和 MATH 数据集上都取得了良好的效果。
而这篇论文则是更深入地对数学推理任务中的数据增强进行了研究,旨在回答以下问题:1)怎样数据增强策略更有效?2)增强数据量与模型性能之间的关系如何?3)数据增强给模型带来的性能提升能否在其他领域的数学推理任务上泛化?
为此,文章通过使 GSM8K(主要包含初等代数问题)中的问题更复杂和多样化,并对每个新问题采样多个推理路径,创建了一个名为 AugGSM8K 的新数据集。在 AugGSM8K 的子集进行微调后,获得了一系列名为 MuggleMath 的 LLMs。MuggleMath 在 GSM8K 上取得了显著的新最佳成绩(在将 LLaMA-2-7B 提高到 68.4%;将 LLaMA-2-13B 提高到 74.0%,将 LLaMA2-70B 提升到 82.3%)。
MuggleMath 的在 GSM8K 上的性能与增强数据量之间呈现出对数线性关系。文章还发现,MuggleMath 在数学推理能力泛化到其他领域的 MATH 数据集(包含初等代数,代数,数论,计数和概率,几何,中等代数和微积分)时表现较弱。这主要归因于 AugGSM8K 和 MATH 之间问题分布的差异,这表明在单一基准上进行数据增强无法提高模型整体数学推理性能。

论文标题:
Query and Response Augmentation Cannot Help Out-of-domain Math Reasoning Generalization
论文链接:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









