







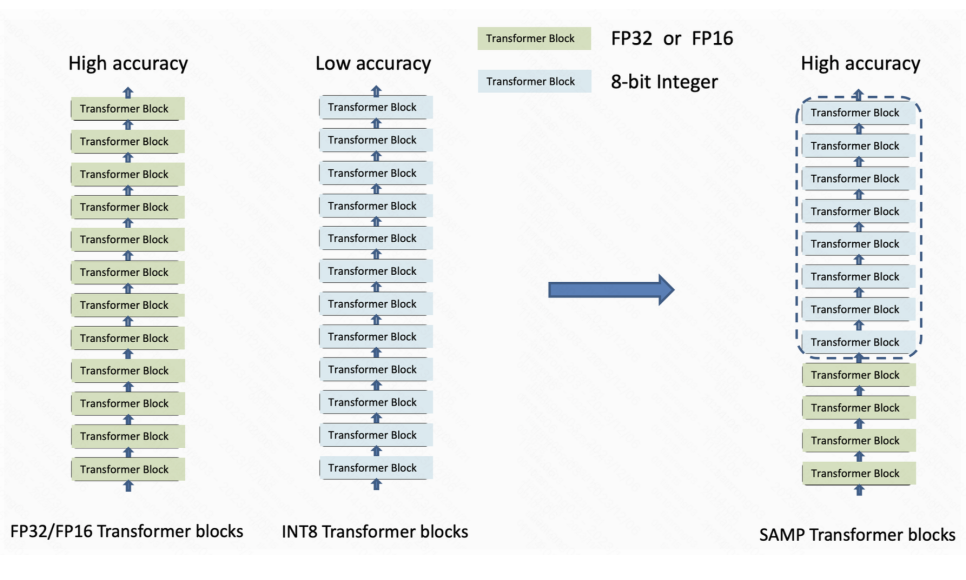
 SAMP是一个针对文本处理的推理库,采用自适应混合精度技术,平衡计算精度和推理速度。它在Transformer模型中自动控制浮点和整型运算,实现在量化推理加速的同时保持高精度。相比于全INT8量化,SAMP在计算精度和推理效率方面表现更优,适用于多种NLP任务,降低了训练后量化推理的工业应用难度。
SAMP是一个针对文本处理的推理库,采用自适应混合精度技术,平衡计算精度和推理速度。它在Transformer模型中自动控制浮点和整型运算,实现在量化推理加速的同时保持高精度。相比于全INT8量化,SAMP在计算精度和推理效率方面表现更优,适用于多种NLP任务,降低了训练后量化推理的工业应用难度。

©PaperWeekly 原创 · 作者 | 田荣
单位 | 快手
本文内容源自发表于计算机人工智能领域顶会 EMNLP 2023(The 2023 Conference on Empirical Methods in Natural Language Processing),由快手、腾讯等单位联合共同完成。

论文标题:
SAMP: A Model Inference Toolkit of Post-Training Quantization for Text Processing via Self-Adaptive Mixed-Precision
论文作者:
Rong Tian, Zijing Zhao, Weijie Liu, Haoyan Liu, Weiquan Mao, Zhe Zhao and Kan Zhou
论文链接:
https://aclanthology.org/2023.emnlp-industry.13/

三分钟读论文
Powered by AI © PaperWeekly

摘要
AI 进入大模型时代,模型的计算性能是一个长期被关注的问题。目前工业界推理引擎已经验证半精度浮点(FP16)和 8 位整型(INT8)计算可以大大缩减计算位宽,从而加快模型推理速度。但已知的 INT8 量化方法使用门槛较高,且精度损失大,会导致模型效果大打折扣。我们推出了一个自适应混合精度推理库(SAMP),通过混合精度架构自动控制浮点型运算和整型运算,使得模型在量化推理加速的同时,保证计算精度。

研究背景
文本理解是自然语言处理(NLP)领域的基本任务之一,例如在信息检索、对话系统、情感识别、摘要生成、语言模型等多个应用场景中。基于 Transf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









