







 论文介绍了MESED,一个大规模多模态实体集扩展数据集,用于评估多模态实体集扩展(MESE)任务。MESED包含14489个实体和434675个图像-句子对,具有细粒度语义类别。此外,提出了多模态模型MultiExpan,通过预训练任务如掩码实体预测、对比学习、聚类学习和动量蒸馏学习来学习多模态实体表示。实验表明,MultiExpan在ESE任务上优于单模态和基于视觉的模型。
论文介绍了MESED,一个大规模多模态实体集扩展数据集,用于评估多模态实体集扩展(MESE)任务。MESED包含14489个实体和434675个图像-句子对,具有细粒度语义类别。此外,提出了多模态模型MultiExpan,通过预训练任务如掩码实体预测、对比学习、聚类学习和动量蒸馏学习来学习多模态实体表示。实验表明,MultiExpan在ESE任务上优于单模态和基于视觉的模型。


论文题目:
MESED: A Multi-modal Entity Set Expansion Dataset with Fine-grained Semantic Classes and Hard Negative Entities
论文链接:
https://arxiv.org/abs/2307.14878
代码链接:
https://github.com/THUKElab/MESED
论文录用:
AAAI 2024 Main Technical Track

动机
实体集扩展(ESE)是一种信息检索任务,旨在通过使用给定的候选实体词汇表和语料库,从中发现属于同一语义类的新实体。这个任务的目标是通过利用已知的一组种子实体,从语料库中检索并扩展出属于相同语义类别的其他实体。这有助于建立更全面、更丰富的实体集,提供更深入的语义理解和关联性,使得 NLP 和 IR 等下游任务受益。
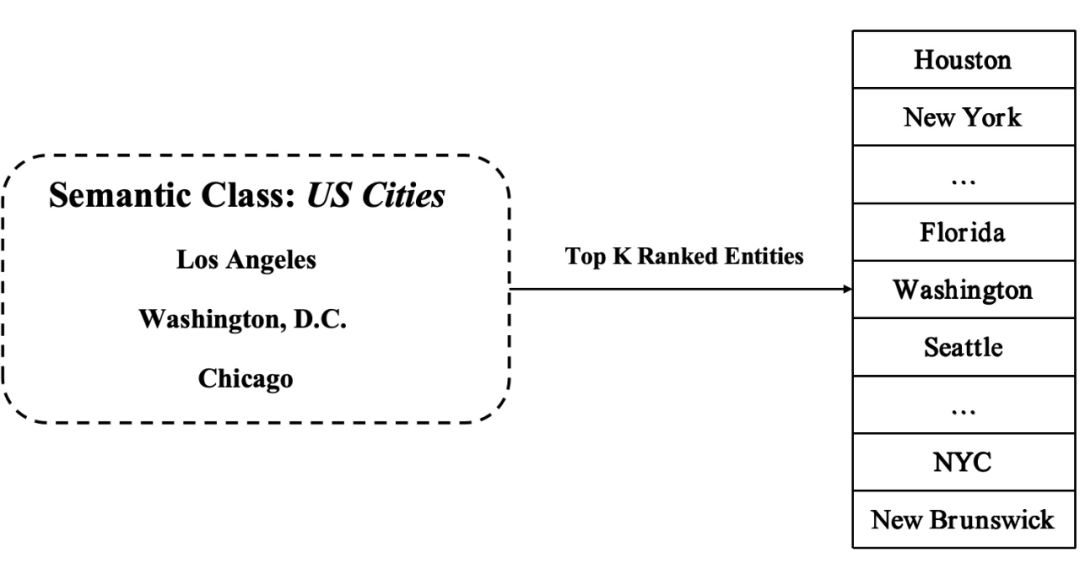
以扩展语义类 US Cities 为例,给定一组种子实体 {Washington D.C., Chicago, Los Angeles},ESE 尝试检索具有目标语义类的其他实体,如 New York, Houston。任务的目的是让扩展出的 Top K 个实体尽可能准确的属于 US Cities。
然而,传统的 ESE 方法基于单模态,通常信息有限且表征稀疏。单模态 ESE 方法面临着一些挑战,主要表现在以下几个方面:
具有细粒度语义差异的负实体:与目标类属于同一粗粒度语义类的实体。在扩展语义类 US Cities 时,必然需要考虑到与目标类别具有相同父语义类(US Location)的实体,例如位于美国的 Florida 和 Texas。由于这些实体在文本上下文中具有相似语义,传统的单模态 ESE 方法往往难以在细节上进行区分。
同义实体:实体的多种别名。ESE 模型可以很容易地理解常见别名,但无法理解上下文相关的别名,如缩写和昵称,因为确定它们的含义需要明确的文本提示。例如,SEA 仅在某些上下文中表示 Seattle,这可能导致检索的遗漏。
一词多义实体:一词多义实体可能存在歧义,因为引用多个实体的文本提及共享相同的 token。由于预训练语言模型通过单词共现学习语义,因此包含相同 token 的实体本质上更接近。例如,从 Washington, D.C. 到 Washington State 的相似度大于到 Austin 等许多其他城市的距离,从而导致错误的结果。
长尾实体:出现频率较低且相对不常见的实体,如晦涩的地名。这些实体由于出现次数有限,其在文本中的描述通常较为零散,且文本上下文匮乏,很难获取关于这些实体的详尽信息。由于文本描述的稀缺性,表示长尾实体往往过于稀疏,使得在检索时可能会错过相关的内容。
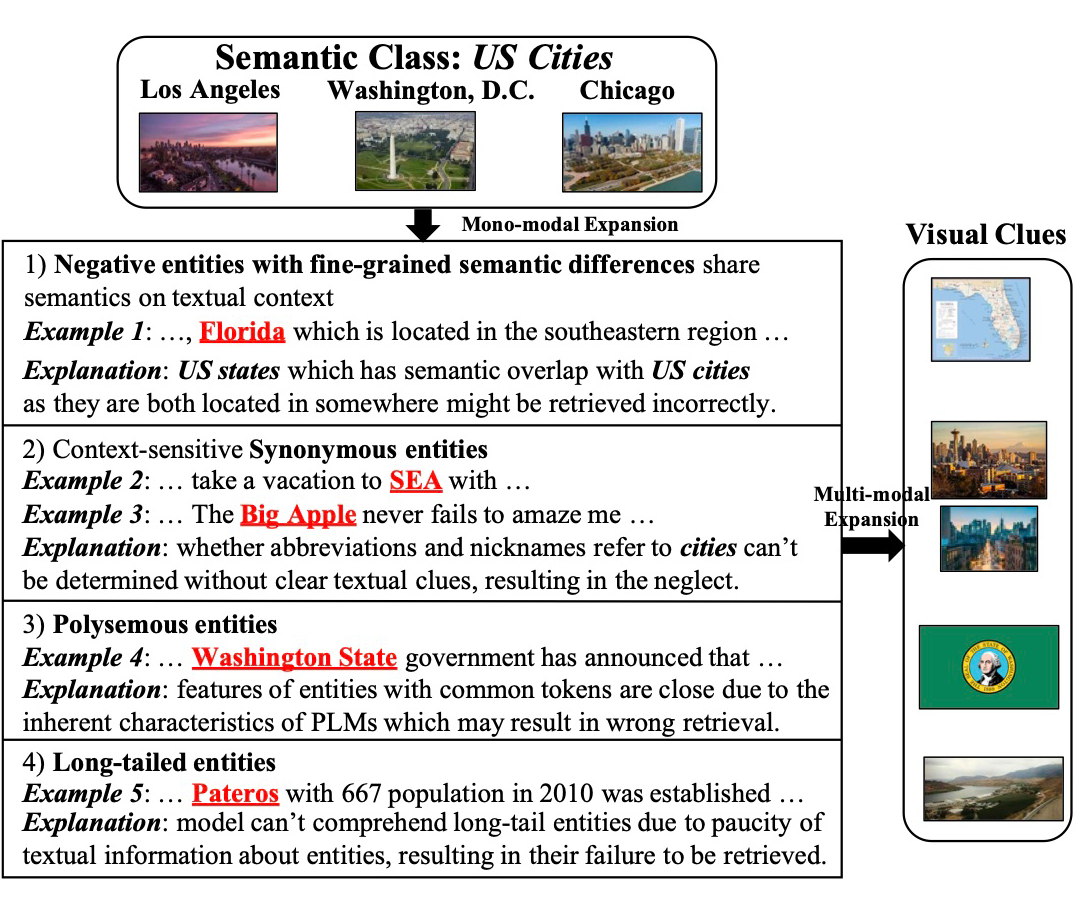
上述情况促使多模态实体集扩展(MESE)任务的出现。MESE 整合来自多种模式的信息来表示实体并将它们扩展到目标语义类,利用多个信息源来克服单模态方法的局限性。
遗憾的是,尽管存在多种多模态数据类型,但目前还没有基于细粒度语义类结构的多模态数据集可用于评估 MESE 的效果。为弥补这一差距,本文构建一个名为 MESED 的大规模人工标注的 MESE 数据集,其中包含来自维基百科的 14489 个实体和 434675 个图像-句子对。
此外,本文提出多模态基线模型 MultiExpan 并探索多种自我监督的预训练目标,用于多模态实体的表示学习。大量实验验证了 MultiExpan 与单模态/多模态模型相比的有效性。
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









