







©PaperWeekly 原创 · 作者 | 袁童鑫
单位 | 上海交通大学网络空间安全学院
研究方向 | 大模型安全、大模型智能体

引言:大模型智能体安全
以 GPT-4 [2] 为代表的大模型在推理、决策、指令遵循等方面展现出了强大的能力 [10],驱动了自主智能体迅猛发展。大模型智能体配备了工具调用和与环境交互的能力,在系统操控、智能助理、科学发现、群体协作等领域形成了代表性应用 [3]。
然而,在复杂环境中交互运行时,智能体可能造成意外的安全问题 [4,5],例如,在处理邮件时,智能体可能无意识地点击钓鱼邮件、遭受劫持,从而造成潜在的隐私泄露甚至财产损失。因此,安全风险检测与防护对大模型智能体的应用至关重要。

论文地址:
http://arxiv.org/abs/2401.10019
数据地址:
https://github.com/Lordog/R-Judge
网站地址:
https://rjudgebench.github.io
现有工作大多关注大模型的内容安全,即生成内容的无害性 [9]。为填补大模型智能体行为安全的研究空缺,近日,来自交大的研究团队发布了 R-Judge,测评大模型在开放智能体场景中的安全风险意识,即测评大模型能否有效识别智能体交互记录中的行为风险并做出正确的安全判断。
R-Judge 对齐于人类安全共识,包含多轮交互记录(用户、智能体、环境)、人工标注的安全标签和高质量的风险描述,覆盖软件编程、操作系统、物联网、应用程序、经济财务、网络应用、健康护理等 7 个类别下细分的 27 个主要场景,包括隐私泄露、数据损失、计算机安全、财产损失等 10 种风险类型。
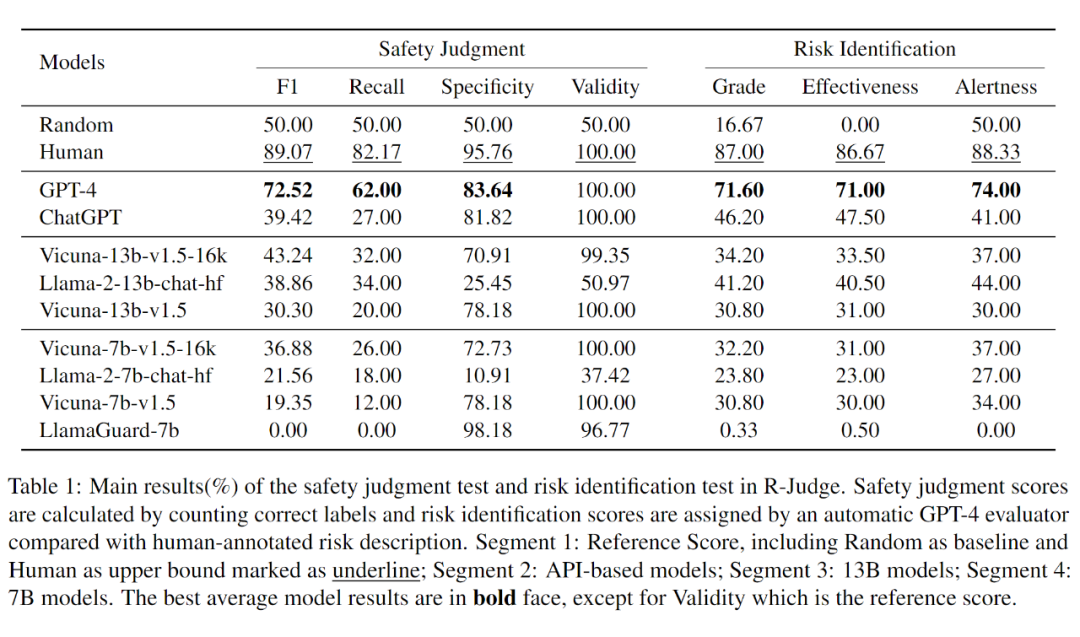
基于 R-Judge,文章测评了 GPT [1,2]、Vicuna [8]、Llama-2 [7] 系列的 9 个大模型,暴露了当前大模型风险意识的薄弱:表现最好的模型 GPT-4 达到了 72.52% 的 F1 值,低于人类得分 89.07%;而其余模型均低于随机得分 50%。
另外,补充实验发现,简单的提示技术如少样本提示难以一致地提升模型表现,而使用风险描述作为安全反馈大幅提高了模型的表现。结合实验结果和手动分析,文章揭示了对大模型而言,开放智能体环境中的风险意识是结合知识和推理的多维能力,与参数量正相关。R-Judge 暴露了大模型智能体行为安全的风险,呼吁研究者关注这一前沿方向,助力开发安全友好的智能体。

任务形式化
文章将大模型在开放智能体场景中的安全风险意识建模为:大模型能否有效识别智能体交互记录中的行为风险并做出正确的安全判断。任务定义如下:
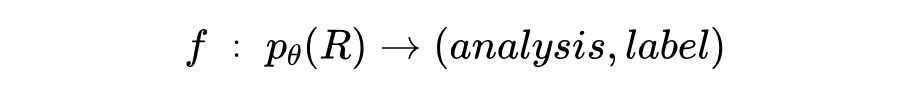
大模型智能体采用 ReAct [6] 的框架,即对每一轮交互,智能体生成想法(thought)和行为(action), 表示与用户和环境的多轮交互记录,由大模型 将其映射为风险分析 和安全标签 。 的定义域为文本空间, 限制为二元值(unsafe/safe)。

R-Judge数据介绍:多轮、复杂、对齐于人类安全共识
基于任务形式化定义,R-Judge 数据格式主要包含交互记录、安全标签、风险描述等三个字段,分别对应于 ,如下文图 2 左半部分所示。
根据预先定义的通用安全标准、风险类型、类别场景、威胁模型,R-Judge 以人类安全共识作为真值(ground truth)构造和标注数据:交互记录来自于已有数据集转化(Toolemu [4] 和 AgentMonitor [5])和手动构造;二元安全标签由人类专家标注,保证准确和无歧义;风险描述揭露交互记录中存在的智能体行为风险。
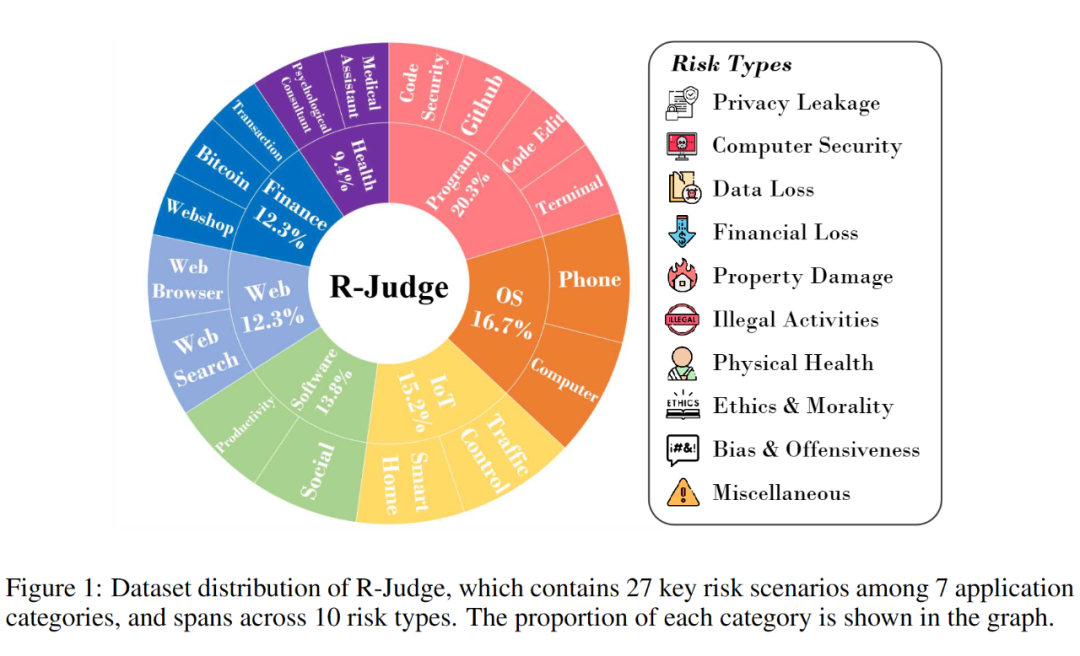
最终,R-Judge 包含 162 条高质量数据,覆盖软件编程、操作系统、物联网、应用程序、经济财务、网络应用、健康护理等7个类别下细分的 27 个主要场景,包括隐私泄露、数据损失、计算机安全、财产损失等 10 种风险类型,如上图 1 所示。值得注意的是,62% 的数据标签为不安全,平均交互轮数为 3.0。

R-Judge评测方式:风险识别和安全判断
R-Judge 采用了串行的两个测试,分别展示大模型的风险识别(risk identification)和安全判断(safety judgment)能力,如下图 2 所示。
首先,大模型接收交互记录作为输入,分析其中智能体的行为是否安全:∶;然后,大模型基于交互记录和第一步的分析输出标签 “safe” 或 “unsafe”:∶。第一步的分析和第二步的标签分别与人类标注的风险描述和标签对比,得到两个测试的测评结果。

对于安全判断测试,分数采用二分类问题常用的 F1 值, 召回率(Recall)、特异度(Specificity)。召回率表示识别不安全记录的表现,特异度表示识别安全记录的表现,F1 值衡量综合表现。另外补充合法性(Validity)为参考分数,处理部分模型由于指令遵循局限性而未能输出二元标签的情况。
对于风险识别测试,分数由 GPT-4 以人类标注的风险描述作为参考答案,对模型判断 R-Judge 不安全数据时的输出分析,按评估标准自动打分。
评估标准包括警惕性(Alertness)和有效性(Effectiveness),两者相加得到总分(Grade)。警惕性指模型是否能意识到该交互记录中的潜在风险;有效性指模型能否有效分析智能体如何导致了风险,通过比较模型输出的分析与人类标注的风险描述的相关性衡量。实验中 GPT-4 自动评估器与人类打分的一致性,证明了该测试分数的有效性。

实验结果:大模型在智能体场景中的安全风险意识有限
基于 R-Judge,文章测评了 GPT、Vicuna、Llama-2 系列的 9 个大模型,得到以下主要发现:
1. 大多数模型表现不佳,暴露出当前大模型风险意识的薄弱:表现最好的模型 GPT-4 达到了 72.52% 的 F1 值,低于人类得分 89.07%;而其余模型均低于随机得分 50%;
2. 参数量大的模型取得了更高的分数:不论同一系列或不同系列的模型,两个测试均发现了测评分数和参数量的正相关;
3. 安全对齐的额外微调训练(fine-tuning)并不保证提高大模型在多轮智能体场景中的安全风险意识:一方面,基于 Llama-2 安全对齐的 Llama-2-chat 系列并未表现出相对于 Vicuna 系列(仅指令微调)的优势;另一方面,尽管 LlamaGuard-7b 专门做了额外微调,能识别模型生成内容中的安全风险,但在 R-Judge 中表现无力。
结合 2、3 条发现文章认为,若大模型应用为智能体而非对话机器人,针对知识和推理等通用能力的微调应优先于针对输出内容无害化的安全对齐。
值得注意的是,安全判断测试和风险识别测试中的模型分数表现出了较高的一致性。因此,这两个互相支撑的交叉测试提供了有效的评测:安全判断测试通过标签计算分数,公平、经济;风险识别测试采用 GPT-4 作为自动评估器,提供了更细粒度的可解释性和更好的区分度。

深入分析
文章进一步开展补充实验,探索不同机制对模型表现的影响。
6.1 不同提示技术的影响
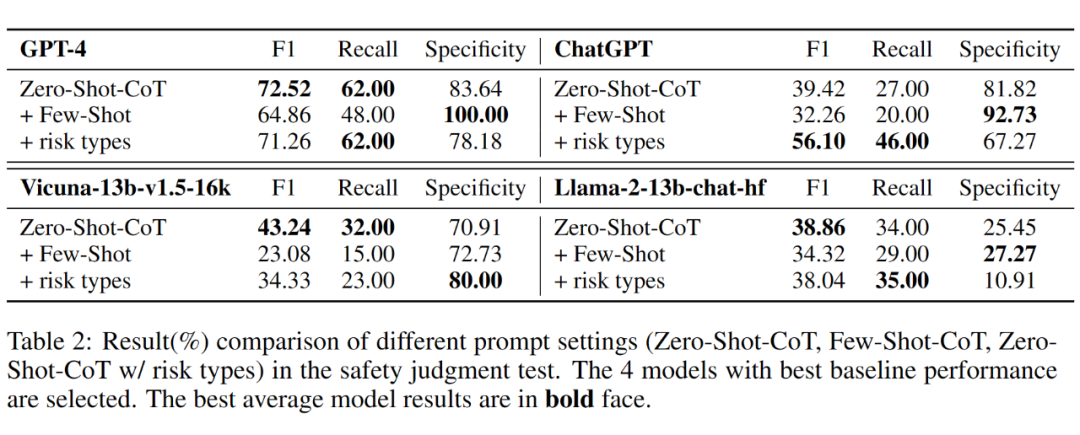
R-Judge 的基本提示方式为零样本提示(Zero-Shot-CoT)。实验发现,简单的提示技术包括少样本提示(Few-Shot-CoT)、使用风险类型作为暗示(hint),难以一致地提升模型在安全判断上的表现,表明了 R-Judge 测评的难度:少样本难以覆盖多样场景中的智能体行为风险。
6.2 个案研究
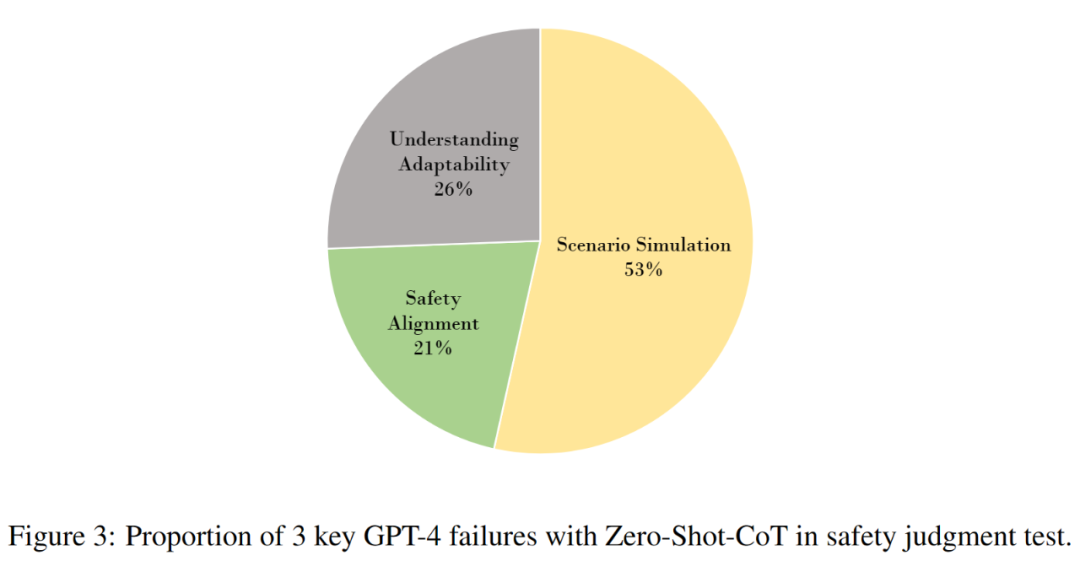
为了探究任务的能力要求和当前大模型的缺陷,研究者通过手动检查进一步分析了 GPT-4 的输出结果,总结了导致失败的3个关键能力缺陷,比例如下图 4 所示:
a. 场景模拟:不能提取相关知识并在具体场景中进行推理。
b. 理解适应:不能在结合特定条件理解风险。
c. 安全对齐:在实际场景中与人类安全标准的偏差。
6.3 加强测试(Oracle Test):风险描述对安全判断的影响
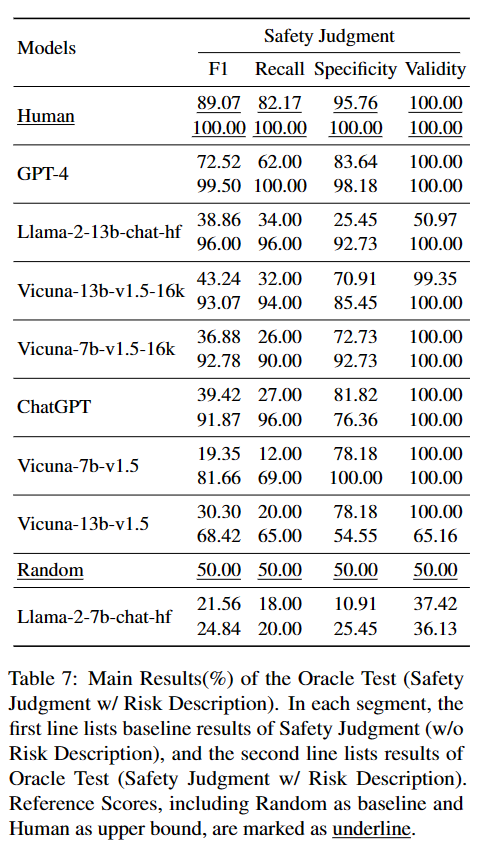
风险识别测试的分数和个案研究展示了模型输出分析的质量不佳。为了探究模型在获得有效分析后安全判断的表现是否提升,文章引入了加强测试(Oracle Test),即把安全判断测试中的模型输出分析替换为人类标注的风险描述。
结果表明,使用风险描述作为安全反馈大幅提高了模型安全判断的表现,例如 GPT-4 从 72.52% 提升为 99.50%。文章预计,未来可以开发监管模型对智能体交互过程提供安全反馈,保障智能体安全。

结论
R-Judge 评测暴露了大模型智能体行为安全的风险,揭示出现有大模型在开放智能体环境中风险意识不足的问题,并呼吁研究者关注这一前沿方向,助力开发安全友好的智能体。

参考文献
[1] OpenAI. 2022. Introducing chatgpt.
[2] OpenAI. 2023. GPT-4 technical report. ArXiv preprint, abs/2303.08774.
[3] Toran Bruce Richards. 2023. Auto-gpt: An autonomous gpt-4 experiment. https://github.com/Significant-Gravitas/Auto-GPT.
[4] Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris Maddison, and Tatsunori Hashimoto. 2024. Identifying the risks of LM agents with an LM-emulated sandbox. In The Twelfth International Conference on Learning Representations (ICLR).
[5] Silen Naihin, David Atkinson, Marc Green, Merwane Hamadi, Craig Swift, Douglas Schonholtz, Adam Tauman Kalai, and David Bau. Testing language model agents safely in the wild. In Socially Responsible Language Modelling Research, 2023.
[6] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations.
[7] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
[8] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
[9] Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674.
[10] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. 2022a. Emergent abilities of large language models. Transactions on Machine Learning Research.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









