







©作者 | 杨润一、朱贞欣等
来源 | 机器之心
本论文作者包括帝国理工学院硕士生杨润一、北航二年级硕士生朱贞欣、北京理工大学二年级硕士生姜洲、北京理工大学四年级本科生叶柏均、中国科学院大学本科大三学生张逸飞、中国电信人工智能研究院多媒体认知学习实验室(EVOL Lab)负责人赵健、清华大学智能产业研究院(AIR)助理教授赵昊等。
最近,3D Gaussian Splatting (3DGS) 作为一种新颖的 3D 表示方式,因其快速的渲染速度和高渲染质量而受到关注。然而,这种方法也伴随着高内存消耗,例如,一个训练好的高斯场可能会使用超过三百万个高斯基元和超过 700 MB 的内存。
近日,帝国理工学院、北航、北京理工大学、中国科学院大学、中国电信人工智能研究院多媒体认知学习实验室(EVOL Lab)、清华大学智能产业研究院(AIR)等机构的研究者联合发表了一篇论文《SUNDAE: Spectrally Pruned Gaussian Fields with Neural Compensation》,我们认为这种高内存占用是由于没有考虑基元之间的关系。在论文中,我们提出了一种名为 SUNDAE 的内存高效的高斯场,采用频谱修剪和神经补偿。

论文地址:
https://arxiv.org/abs/2405.00676
项目主页:
https://runyiyang.github.io/projects/SUNDAE/
一方面,我们基于高斯基元的空间信息构建了一个图,用于模拟它们之间的关系,并设计了一个基于图信号处理的降采样模块来剪枝,同时保留所需信号。另一方面,为了补偿剪枝造成的质量下降,我们利用了一个轻量级神经网络来混合渲染特征,有效地补偿了质量下降,同时在其权重中捕获基元之间的关系。
我们通过大量的结果展示了 SUNDAE 的性能。例如,在 Mip-NeRF360 数据集上,SUNDAE 可以在使用 104 MB 内存的情况下达到 26.80 PSNR 和 145 FPS,而标准的 3D Gaussian Splatting 算法在使用 523 MB 内存的情况下达到 25.60 PSNR 和 160 FPS。
与此同时,自从开源后,SUNDAE 受到国际上广泛的关注,受到了知名 NeRF 社区 MrNeRF,AI research 社区维护者 Ahsen Khaliq、以及多位相关领域研究人员转发关注。


带神经补偿的频谱剪枝高斯场
1.1 基于频谱图的剪枝策略
3DGS 使用一组高斯基元来表示场景,由于这些基元在三维空间中的分布不规则,我们提出了基于图的方法来捕获基元之间的关系,而不是使用网格这样的常规结构。
具体来说,我们采用图信号处理理论来推导一个最优的采样策略,该策略能够基于图信号保留特定频谱的信息。通过控制频谱带宽,我们可以灵活地控制剪枝比例,建模高斯基元之间的关系。如图 1 (c),我们可以控制剪枝 90% 的高斯基元而不降低渲染质量。

▲ 图1. (a) 3DGS 7k 迭代次数的结果;(b) 3DGS 30k 迭代次数的结果,使用了更多的高斯基元来表示三维场景,因此质量更高、速度更慢、存储空间更大;(c) 剪枝了 90% 的高斯基元,在存储空间上大幅减小,但是达到了相似的渲染效果。
我们使用高斯基元的中心来作为图上的信号输入,将高斯基元之间的距离作为图的边,图的邻接矩阵可以表示为
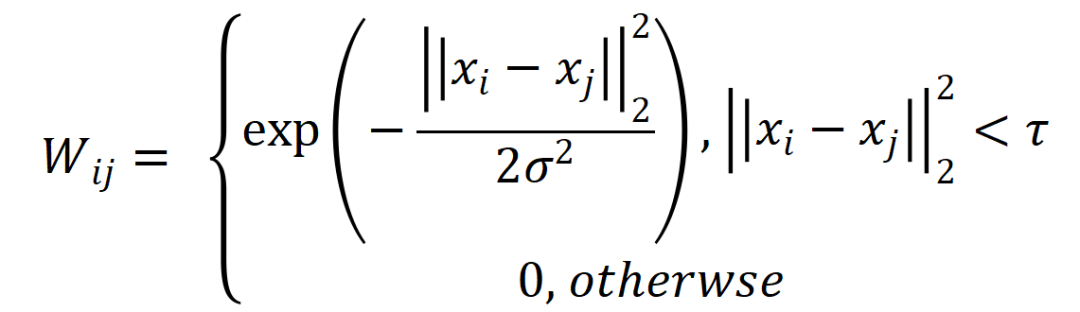
其中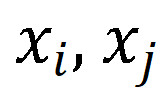 是高斯基元的中心点,
是高斯基元的中心点,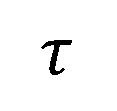 是一个阈值超参数,
是一个阈值超参数,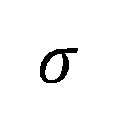 是距离矩阵的方差。也就是说,如果两个高斯基元之间的距离比一个阈值小,那么我们将其之间建立一条图的边。建立好图的邻接矩阵之后,我们可以根据 Haar-like 滤波器对图上的信号进行处理,得到特定频段的图信号。最终根据想要的频段信号进行剪枝,本文中我们使用了带阻滤波器,保留表示物体细节的高频信号和背景点的低频信号。
是距离矩阵的方差。也就是说,如果两个高斯基元之间的距离比一个阈值小,那么我们将其之间建立一条图的边。建立好图的邻接矩阵之后,我们可以根据 Haar-like 滤波器对图上的信号进行处理,得到特定频段的图信号。最终根据想要的频段信号进行剪枝,本文中我们使用了带阻滤波器,保留表示物体细节的高频信号和背景点的低频信号。
1.2 神经补偿机制
经过频谱剪枝后,渲染质量因为删去了过多的高斯基元不可避免会下降,为了解决这个问题,我们采用了一个神经网络来补偿这一质量损失,如图 2 所示。
我们从 Gaussian Splatting 转换到了 Feature Splatting,引入一个轻量级卷积神经网络来输出高斯基元映射到图像上的 RGB 值,从而融合不同基元的信息。这使得补偿网络的权重在二维图像空间中间接地来捕获基元之间的关系。
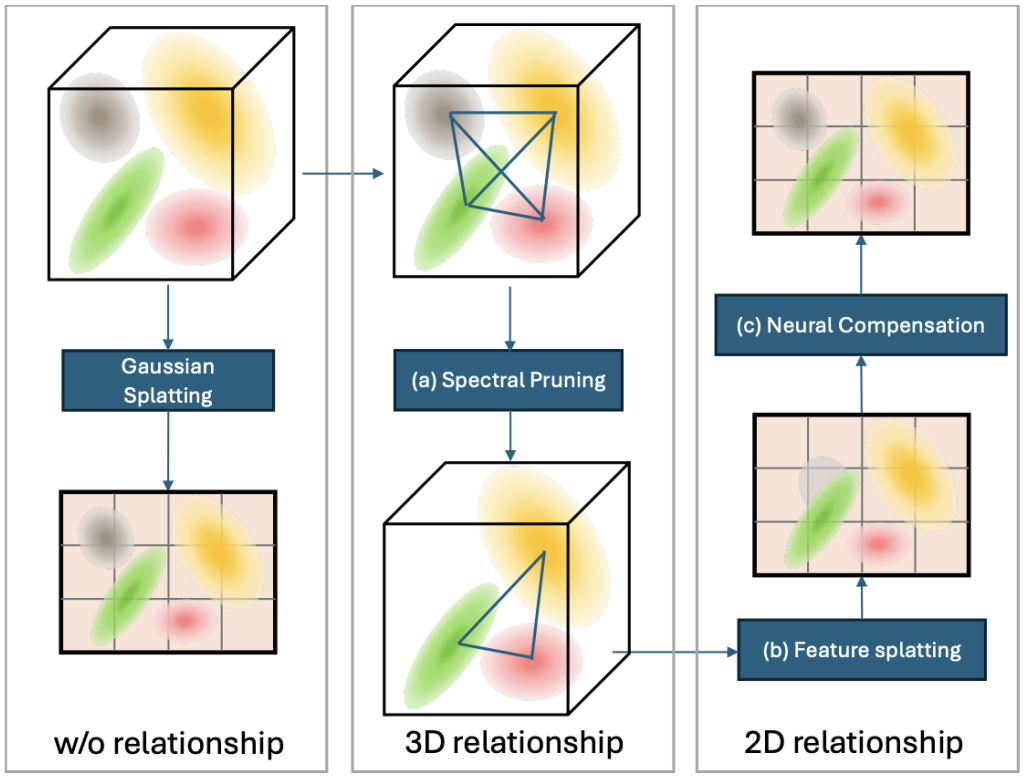
▲ 图2. 左边显示的原版 3DGS,由于没有捕捉到基元之间的关系,因此需要大量的存储空间;中间展示了我们的频谱剪枝策略,建模高斯基元之间的关系;右侧显示神经补偿利用 2D 特征来改善渲染效果。
具体来说,我们不是像 3DGS 那样直接渲染 RGB 图像,而是通过用于 3D 高斯的可微分光栅化器获得一个特征图,该光栅化器将 3D 高斯基元的特征投影到二维特征图上。
然后,我们利用一个轻量级神经网络来建模基元之间的关系并补偿频谱剪枝后的质量下降。这个网络由一个具有 skip-connection 的四层全卷积 U-Net 组成,它聚合来自不同基元的信息。使用平均池化进行下采样,并使用双线性插值进行图像上采样。该网络以光栅化的特征图为输入,输出 RGB 图像。
SUNDAE 的总体框架如下图 3 所示。
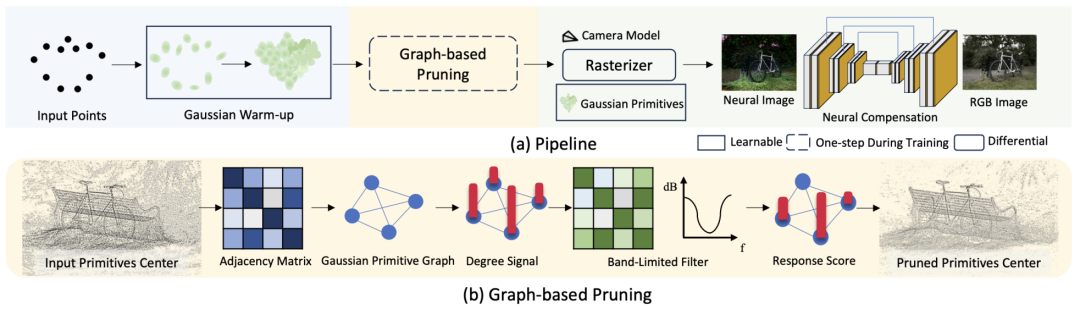
▲ 图3. (a) Pipeline: 对一个预训练的 3D 高斯场,采用基于图的剪枝策略对高斯基元进行降采样,并使用卷积神经网络来补偿剪枝造成的损失。(b) 基于图的剪枝:基于高斯基元之间空间关系的图被用于剪枝。通过使用带阻滤波器,这一过程便于从高频组件中提取细节信息,同时捕捉低频部分的一般特征,从而实现整个场景的全面而高效的表示。
1.3 连续剪枝策略
此外,我们还提出了一个连续剪枝的策略来降低峰值存储,与训练后剪枝不同,后者从一个完全密集的高斯场中剪除基元,连续剪枝涉及在整个训练过程中的预定义间隔定期移除特定数量或比例的基元。这种方法旨在在训练 3D 高斯场时持续控制基元的最大数量,从而降低训练期间的峰值内存需求,并允许在 GPU 内存较低的 GPU 设备上进行训练。
经验表明,较低峰值内存的优势以较弱的最终内存占用控制为代价。例如,如果我们每 2000 次迭代剪掉 20% 的基元,3D 高斯场的最终收敛状态可能会偏离预期的 20% 减少。
此外,这种变化可能在不同场景中有所不同,增加了剪枝效果的可预测性和一致性的复杂性。因此,我们将连续剪枝策略视为必要时的替代方案。

实验结果
2.1 定量结果
我们将 SUNDAE 与最先进的 3DGS 和 NeRF 算法进行对比,相比于 3DGS 来说,我们的模型只占用了 10% 的内存就可以达到相似的效果,并且使用 30% 或 50% 的内存便能超过原版 3DGS。并且在 FPS 上远远超过了 NeRF 相关的其他算法。
这是由于我们的模型能较好的捕捉高斯基元之间的关系,使用更少的高斯基元来高效地表征三维场景。

2.2 定性结果
定性结果中可以看到看到,我们们将 SUNDAE 在 1% 和 10% 采样率的定性结果与 3DGS 和 InstantNGP 进行比较。
定性结果显示,SUNDAE 能够在只使用 10% 甚至 1% 的内存消耗下,达到类似的新视角合成质量。图成功地构建了基元之间的关系,而神经补偿头部有效地维持了渲染质量。并且从图 5 的第四行和最后一行可以看到,频谱剪枝能够移除靠近摄像机的漂浮物。

2.3 消融实验
2.3.1 带阻滤波器
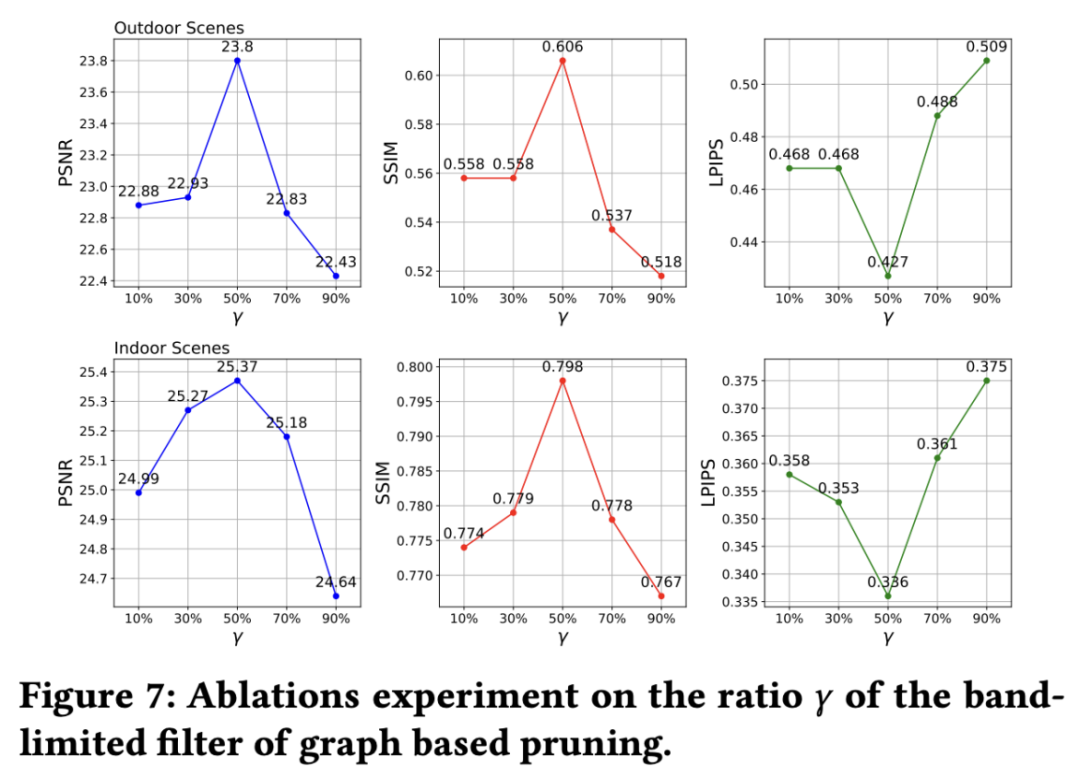
带阻滤波器的比率由一个参数表示。具体来说,在基于图的剪枝过程中,我们采样了若干基元,包括一定比例 () 的高通和剩余的 (1-) 低通。
结果表明,这个参数对渲染质量有显著影响,50% 的比率提供了最佳的结果,而对低频或高频信号的不成比例强调会导致质量下降,因为通 50% 的比率保留了均衡的高频细节和低频背景所以效果更优。
2.3.2 补偿网络
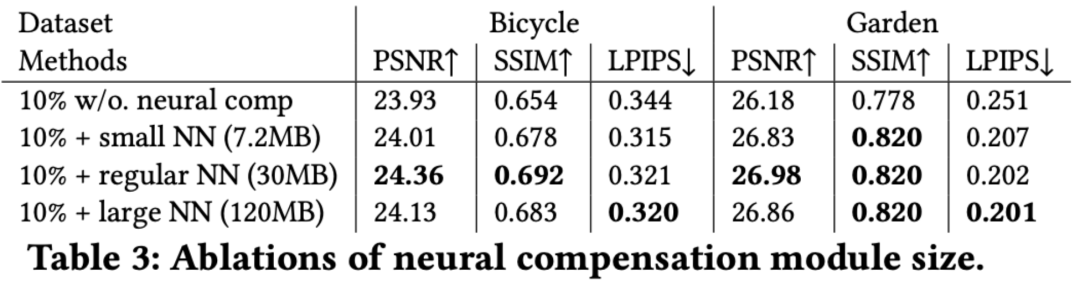
如图 6 和表 2 所示,我们定性和定量地展示了补偿网络的重要性。如表 2 所示,所有采样率下,使用神经补偿相比不使用都表现出了改善的性能。这一点通过图 6 中展示的可视化结果得到了进一步支持,展示了该模块在缓解频谱剪枝造成的性能下降方面的补偿能力。同时,也证明了基元之间的关系被很好地捕捉。
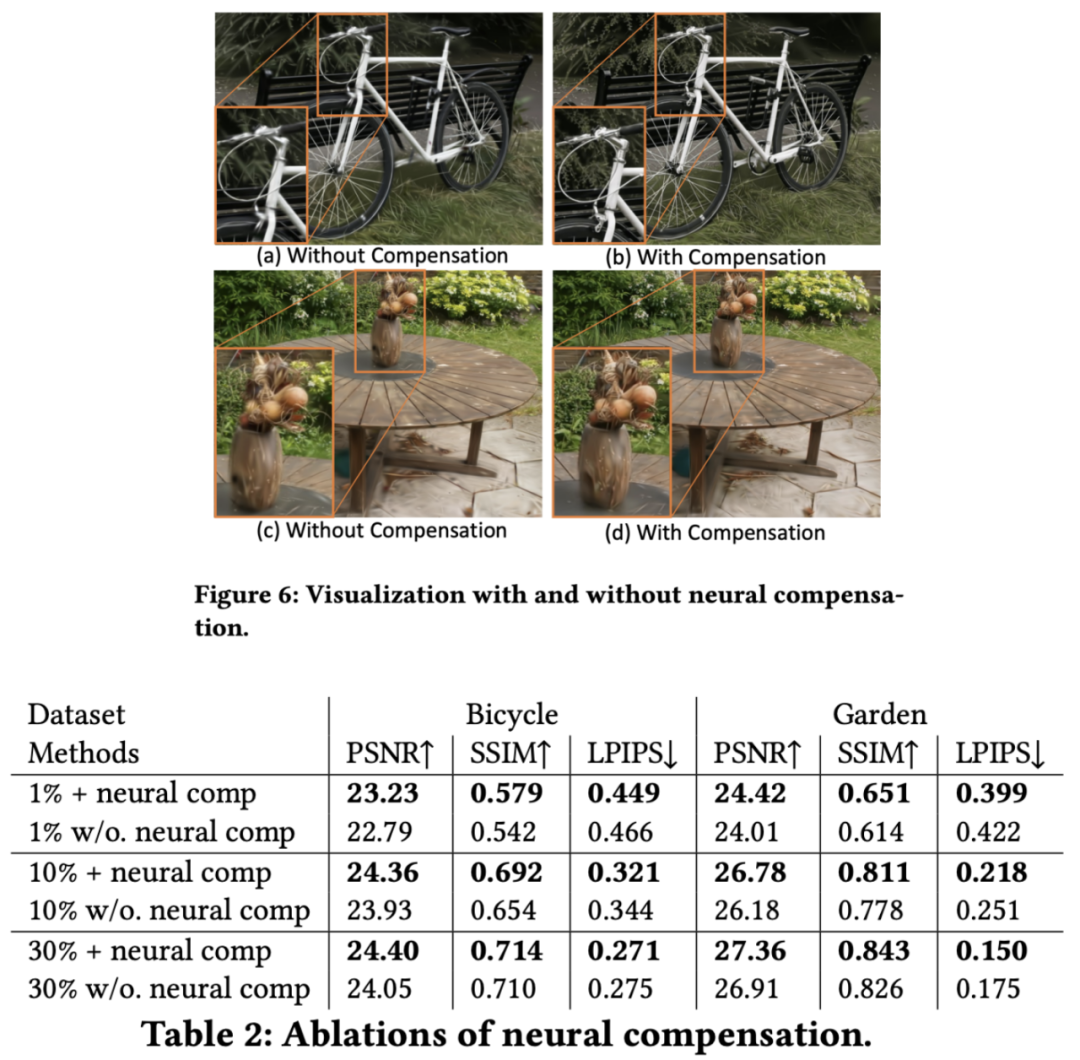
如表 3 所示,我们尝试了不同大小的补偿网络,增加网络大小并不一定能提高渲染质量,这与 ADOP 的发现一致,表明了相似的趋势。我们采用 30MB 的 4 层 UNet 作为默认设置,以最佳平衡质量和内存。
2.3.3 更多的采样点
如上表 1 所示,保留 50% 的基元在渲染质量上优于原始的 3DGS。我们还额外测试了保留 80% 和保留所有基元,以检验采样率如何影响最终结果,如表 4 所示。
结果显示,保留 80% 的基元提高了渲染质量,根据 LPIPS 显示出改进,但在 PSNR 和 SSIM 上的视觉提升很小。保留所有基元(并训练更多的周期)无法进一步提高质量,这也显示了建模基元关系的重要性。如果没有有效的关系建模,更多的基元会使模型难以收敛,且大量基元对场景表示产生负面影响。
此外,我们的目标是平衡渲染质量与存储效率;然而,将存储增加到 620MB 以保留 80% 的基元只带来了轻微的质量提升,从而降低了存储效率。

2.3.4 连续采样策略
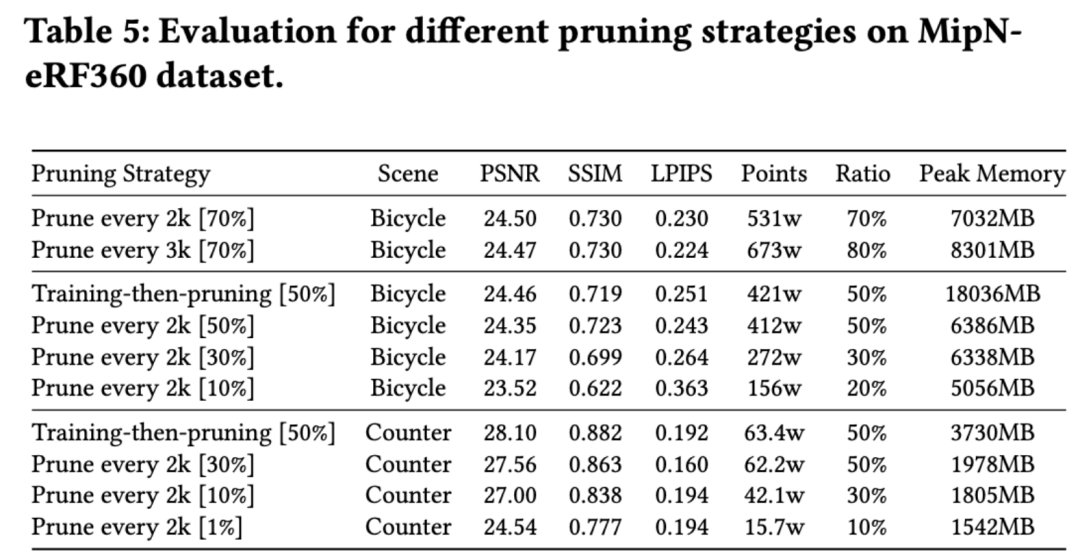
我们在 MipNeRF360 数据集中的 Bicycle 和 Counter 场景上测试了连续采样策略,设定不同的剪枝间隔迭代次数和剪枝率。如表 5 所示,Points 是训练后的基元数量,Ratio 是训练后基元数量与原始 3DGS 的大致比率。
结果显示,这种策略可以降低峰值内存,但难以控制最终内存(通过 Points 和 Ratio 反映)。因此,我们验证了我们的训练后剪枝策略,但仍然在我们的开源工具箱中提供连续剪枝策略作为一种替代方案。
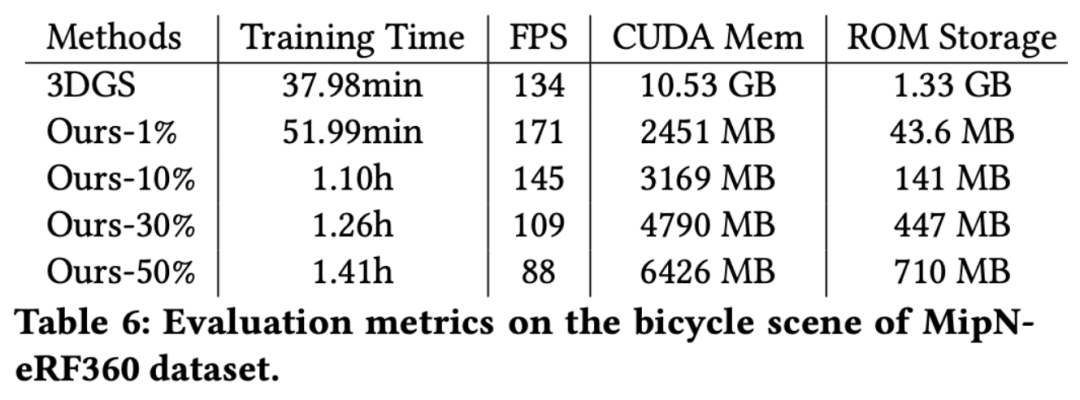
2.3.5 高效性评估
关于训练时间、CUDA 内存、渲染帧率和 ROM 存储的详细信息,请参见表 6。值得注意的是,「Ours-50%」版本在可接受的训练时间内(1.41 小时)达到了最好的渲染质量,同时实现了实时渲染,并显著降低了训练期间的 CUDA 内存使用和 ROM 存储。

结论
在这篇工作中,我们提出了一种新颖的具有神经补偿的频谱剪枝高斯场 SUNDAE,通过引入图信号处理,来建模高斯基元之间的关系,并混合不同基元的信息来补偿剪枝造成的信息损失。
我们使用高斯基元之间的空间信息构建图来建模关系,并根据频谱信息进行剪枝,去除冗杂的基元。一个轻量级神经网络被用来补偿剪枝后不可避免的渲染质量损失。
实验结果表明,SUNDAE 在保持 3DGS 的效率的同时,显著减小了内存,提升了效率并且保持了高保真的渲染质量。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









