







©作者 | 杜伟
来源 | 机器之心
谈到大语言模型(LLM)的策略,一般来说有两种,一种是即时的 System 1(快速反应),另一种是 System 2(慢速思考)。
其中 System 2 推理倾向于深思熟虑的思维,生成中间思维允许模型(或人类)进行推理和规划,以便成功完成任务或响应指令。在 System 2 推理中,需要付出努力的心理活动,尤其是在 System 1(更自动化思维)可能出错的情况下。
因此,System 1 被定义为 Transformer 的应用,可以根据输入直接生成响应,而无需生成中间 token。Sytem 2 被定义为生成中间 token 的任何方法,包括执行搜索或多次提示然后最终生成响应的方法。
业界已经提出了一系列相关的 System 2 技术,包括思维链、思维树、思维图、分支解决合并、System 2 Attention、Rephrase and Respond (RaR) 等。得益于这种明确的推理,许多方法都显示出更准确的结果, 但这样做通常会带来更高的推理成本和响应延迟。因此,许多此类方法未在生产系统中使用,而大多使用了 System 1。
对于人类来说, 学习将技能从深思熟虑(System 2)转移到自动(System 1)的过程在心理学中被称为自动性,以及程序记忆的使用。例如,第一次开车上班时,人们通常会花费有意识的努力来计划和做出到达目的地的决定。而在驾驶员重复这条路线后,驾驶过程就会「编译」到潜意识中。同样,网球等运动可以成为「第二天性」。
在本文中,来自 Meta FAIR 的研究者探索了一种类似的 AI 模型方法。该方法在给定一组未标记示例的情况下以无监督的方式执行编译,被称为 System 2 蒸馏。对于每个示例,他们应用给定的 System 2 方法,然后以无监督的方式测量预测的质量。
例如对于具有唯一答案的任务,研究者应用自洽性(self-consistency)并多次进行采样。对于 System 2 足够一致的示例,他们假设应该蒸馏此结果,并将其添加到蒸馏池中。然后对 System 1 进行微调,以匹配 System 2 方法对收集的示例池的预测,但不生成中间步骤。下图 1 说明了将 System 2 蒸馏到 System 1 的整体过程。
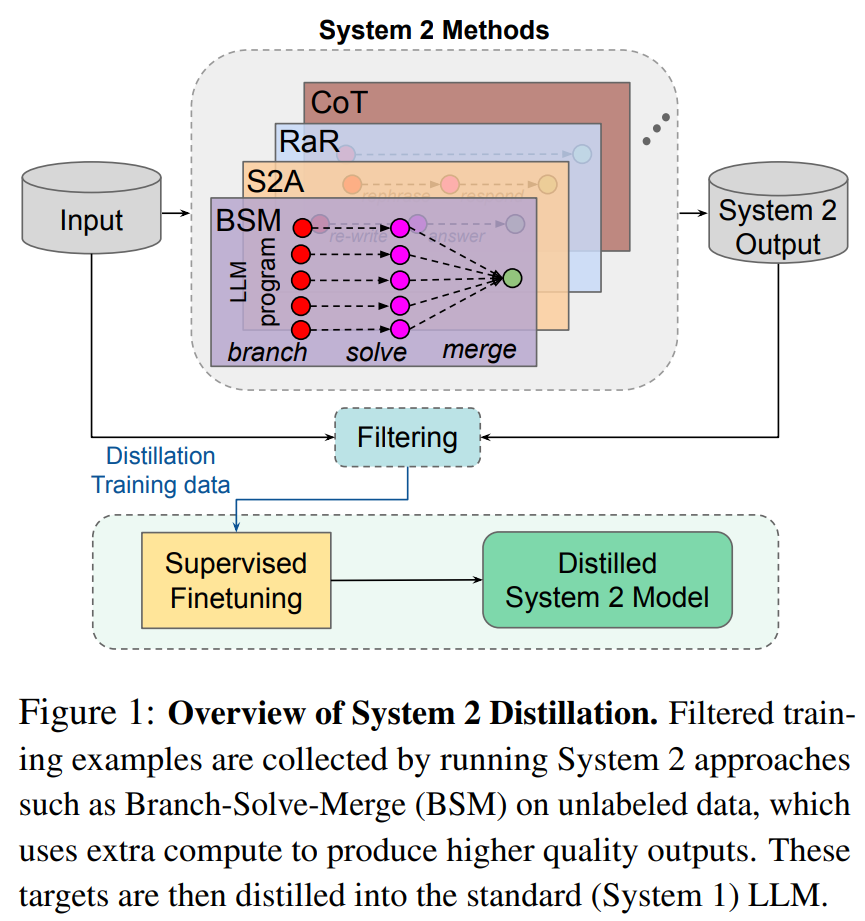
研究者对 4 种不同的 System 2 LLM 方法和 5 种不同的任务进行了实验。结果发现,本文方法可以在各种设置中将 System 2 推理蒸馏回 System 1 中,有时甚至比 System 2 教师的结果更好。此外,这些预测现在只需花费计算成本的一小部分即可产生。
例如,他们发现成功的蒸馏适用于处理有偏见的意见或不相关信息的任务(System 2 Attention)、澄清和改进某些推理任务中的响应(RaR)以及 LLM 的细粒度评估(分支 - 解决 - 合并)。
不过,并非所有的任务都可以蒸馏到 System 1 中,尤其是需要思维链的复杂数学推理任务。这也反映在人类身上,如果没有深思熟虑的 System 2 推理,人类就无法执行某些任务。

论文标题:
Distilling System 2 into System 1
论文链接:
https://arxiv.org/pdf/2407.06023

将System 2蒸馏回System 1
设置:System 1 和 System 2 模型
给定一个输入 x,研究者考虑设置一个单一模型,在他们的例子中是一个大语言模型 (LLM),它能够实现两种响应模式:
System 1:直接生成输出 y。这类方法通过转发(forwarding)底层自回归神经网络 (Transformer) 的各层来生成输出标记来完成。
System 2。这类方法使用底层 Transformer 在生成最终响应 token 之前生成任何类型的中间输出标记 z,可能包括多次调用(提示)。
从形式上,研究者将 System 2 模型 S_II 视为一个函数,它接受 LLM p_θ 和输入 x,并且可以重复调用 LLM 以使用特定算法生成中间标记 z,然后返回输出 y:
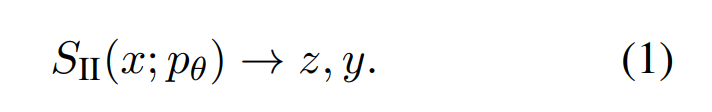
System 2 方法可能涉及多个提示、分支、迭代和搜索,同时使用 LLM 生成中间结果以供进一步处理。相比之下,System 1 模型仅考虑原始输入 x 并直接调用 LLM pθ 来生成输出 y:
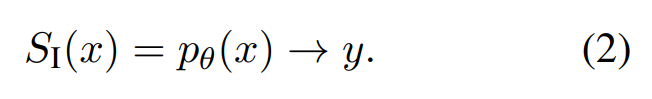
方法:System 2 蒸馏
本文方法的第一步是使用 System 2 模型对未标记的输入 X 生成响应:
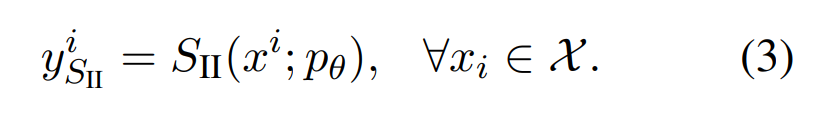
然后,这些响应 y^i_S_II 可直接用作 System 2 蒸馏目标,以微调 System 1 模型。但是,它们容易受到噪声的影响:其中一些响应可能是高质量的,而另一些可能是低质量或不正确的。对于涉及简短响应(通常具有唯一正确(但未知)的答案)的简短问答和推理任务,研究者考虑采用无监督管理步骤来尝试提高训练数据质量。他们考虑了以下两种依赖于自洽性标准的变体:
输出的自洽性:对 S_II (x^i ; p_θ) 进行总共 N 次采样,并接受多数投票响应;如果没有多数投票获胜者,则丢弃该示例。
输入扰动下的自洽性:以输出不变的方式扰动输入 x^i,例如改变提示中多项选择题的顺序,并计算每次扰动的 S_II;如果输出不一致,则丢弃该示例。
之后研究者得到了合成数据集 (X_S_II , Y_S_II),其中 X_S_II 是 X 的一个过滤子集,目标是 Y_S_II。最后一步是使用这个蒸馏出来的训练集对参数为 p_θ 的 LLM 进行监督微调。研究者通常从当前状态 p_θ 初始化此模型,然后继续使用新数据集进行训练。微调后,他们得到一个 LLM 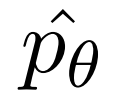 ,这是一个 System 1 模型,预计可提供与评估的 System 2 模型类似的输出和性能提升。
,这是一个 System 1 模型,预计可提供与评估的 System 2 模型类似的输出和性能提升。

实验结果
训练和评估设置
研究者使用 Llama-2-70B-chat 作为所有实验的基础模型。他们需要一个具有足够能力的基础模型,使其能够像 System 2 模型一样高效运行,同时还具有可以微调的开放权重,因此做出了此选择。
同时,研究者考虑了几种 System 2 方法,包括 System 2 Attention、 RaR、分支解决合并(Branch-Solve-Merge)和思维链, 并重点关注每种方法都显示出强大性能的任务。
对于 System 1,研究者使用指令调整后的基础模型作为标准基线进行零样本推理。他们报告每个任务的任务特定指标,以及「#Tokens」指标,后者衡量评估集上每个输入生成的平均 token 数量。System 2 方法则包括中间 token 生成以及最终输出 token 生成。
Rephrase and Respond 蒸馏
RaR 是一种 System 2 方法,它首先提示语言模型以进一步阐述的方式来复述原始问题,然后基于复述的问题生成响应,目的是提供更优的输出。
对于蒸馏数据,研究者使用输出的自洽性为 RaR 构建 System 2 蒸馏数据集。对于每个输入,他们对最后一个字母( last letter)任务进行了八次采样迭代,并同样对硬币翻转(coin flip)任务的每个阶段进行八次采样迭代,然后用多数投票来确定最终输出。
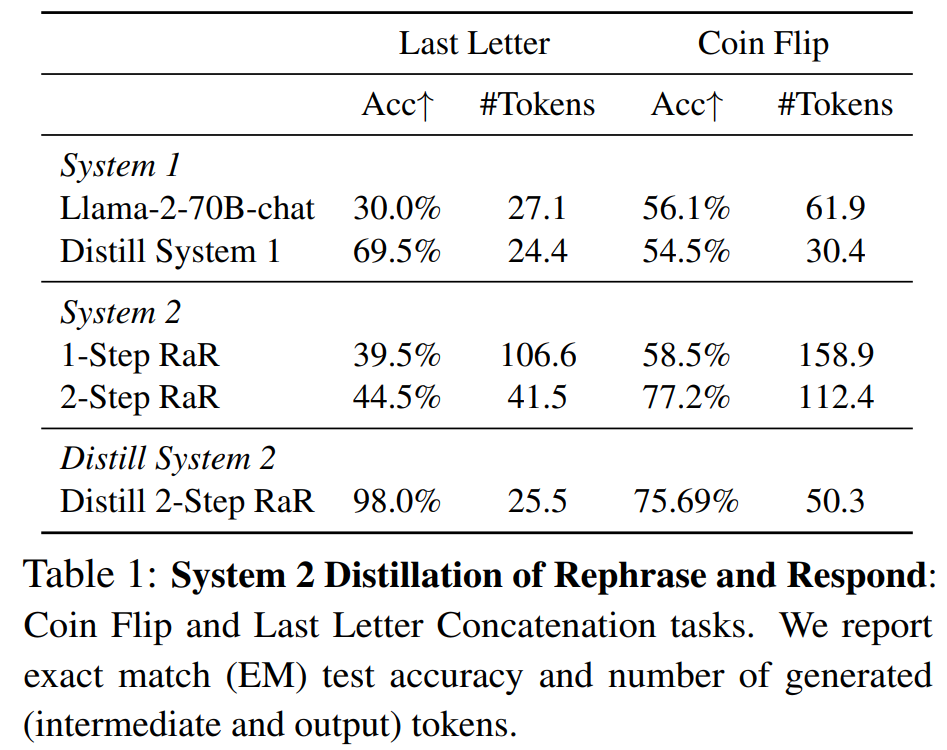
首先来看最后一个字母连接(Last letter Concatenation)任务。此任务侧重于符号推理,要求模型连接给定单词的最后一个字母。整体结果如下表 1 所示。
基线 System 1 模型 (Llama-2-70B-chat) 的准确率达到 30.0%,低于 System 2 的 1-Step 和 2-Step RaR 方法(分别为 39.5% 和 44.5%)。通过本文无监督技术将 2-Step RaR 方法蒸馏回 System 1 Llama-2-70B-chat 模型,则实现了 98.0% 的惊人准确率。
与零样本聊天模型相比,模型可以有效地从这些训练数据中学习如何解决任务。RaR 的蒸馏有效地继承了 System 2 和 System 1 的优势,既保留了 System 2 的准确率优势,而其推理成本与 System 1 相当。
再来看硬币翻转推理任务。这种符号推理任务经常在研究中进行测试,它涉及确定硬币的最终面(正面或反面),从已知的初始位置开始,经过一系列用自然语言描述的翻转,例如「硬币正面朝上」。
整体结果见上表 1。Llama-2-70B-chat(零样板)在此任务上的成功率为 56.1%,而 1-Step 和 2-Step RaR 的成功率分别为 58.5% 和 77.2%。因此,使用 2-Step 方法获得了巨大改进。通过本文无监督技术将 2-Step RaR 蒸馏回 System 1 Llama-2-70B-chat 可以获得 75.69% 的结果。
因此,蒸馏的 System 2 模型提供的性能与 System 2(2 Step RaR)相当,但不需要使用 2 个提示执行 LLM 程序。
System 2 Attention 蒸馏
Weston 和 Sukhbaatar (2023) 提出了 System 2 Attention (S2A),这种方法有助于减少模型的推理陷阱,例如依赖输入中的偏见信息或关注不相关的上下文。
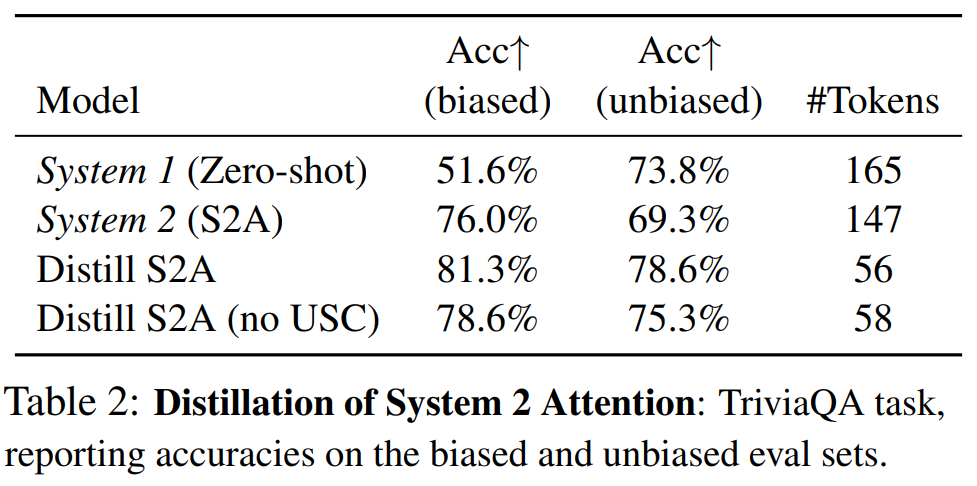
研究者验证了将 S2A 提炼到 System 1 中的可行性,特别是 SycophancyEval 问答任务,该任务包含已知会损害 LLM 性能的输入中的偏见信息。
结果如下表 2 所示,报告了 3 个随机种子的平均准确率。正如预期,基线(System1)LLM 在有偏见部分的准确率较低,容易受到有偏见输入的影响。S2A 显著提高了有偏见输入的性能。System 2 蒸馏表现出与 System 2 方法类似的强大性能。
更多实验结果请参阅原论文。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









