







 本文介绍了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,探讨了如何使用SDE来描述生成扩散模型的前向和逆向过程。文章通过SDE的理论框架,解释了扩散模型的构建,并讨论了得分匹配在模型训练中的作用。作者强调,尽管SDE概念复杂,但理解其简化形式有助于降低理解难度。
本文介绍了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,探讨了如何使用SDE来描述生成扩散模型的前向和逆向过程。文章通过SDE的理论框架,解释了扩散模型的构建,并讨论了得分匹配在模型训练中的作用。作者强调,尽管SDE概念复杂,但理解其简化形式有助于降低理解难度。

©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》[1],可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将 DDPM、SDE、ODE 等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck 方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。

随机微分
在 DDPM 中,扩散过程被划分为了固定的 步,还是用《生成扩散模型漫谈:DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了 步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。
为此,我们用下述 SDE 描述前向过程(“拆楼”):
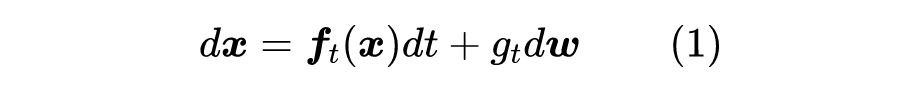
相信很多读者都对 SDE 很陌生,笔者也只是在硕士阶段刚好接触过一段时间,略懂皮毛。不过不懂不要紧,我们只需要将它看成是下述离散形式在 时的极限:
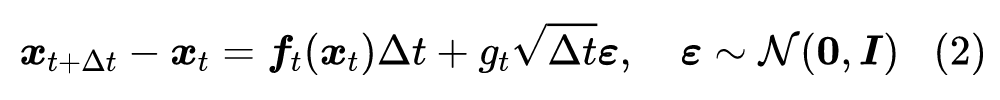
再直白一点,如果假设拆楼需要 天,那么拆楼就是 从 到 的变化过程,每一小步的变化我们可以用上述方程描述。至于时间间隔 ,我们并没有做特殊限制,只是越小的 意味着是对原始 SDE 越好的近似,如果取 ,那就对应于原来的 ,如果是 则对应于 ,等等。也就是说,在连续时间的 SDE 视角之下,不同的 是 SDE 不同的离散化程度的体现,它们会自动地导致相似的结果,我们不需要事先指定 ,而是根据实际情况下的精确度来取适当的 T 进行数值计算。
所以,引入 SDE 形式来描述扩散模型的本质好处是“将理论分析和代码实现分离开来”,我们可以借助连续性 SDE 的数学工具对它做分析,而实践的时候,则只需要用任意适当的离散化方案对 SDE 进行数值计算。
对于式(2),读者可能比较有疑惑的是为什么右端第一项是 的,而第二项是 的?也就是说为什么随机项的阶要比确定项的阶要高?这个还真不是那么容易解释,也是 SDE 比较让人迷惑的地方之一。简单来说,就是 一直服从标准正态分布,如果随机项的权重也是 ,那么由于标准正态分布的均值为 、协方差为 ,临近的随机效应会相互抵消掉,要放大到 才能在长期结果中体现出随机效应的作用。

逆向方程
用概率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









