








多模态大模型,特别是长视频理解的多模态大模型的一个主要挑战是如何高效管理和利用图像序列和视频帧的超长上下文数据。OmChat 通过多阶段的训练,使得模型支持最长达 512K 词元,表现优于所有其他开源模型。本文对 OmChat 的关键技术,以及数据集的特点进行了总结。

论文标题:
OmChat: A Recipe to Train Multimodal Language Models with Strong Long Context and Video Understanding
论文链接:
https://arxiv.org/abs/2407.04923
代码链接:
https://github.com/om-ai-lab/OmModel

扫码查看论文

扫码查看代码

本文结构
本文首先对文章的核心方法进行总结,包括作者如何将模型的上下文长度拓展到 512k(渐进的预训练方式),以及作者在预训练与指令微调阶段如何选择高质量数据。最后对 OmChat 模型在各个 benchmark 上的结果进行分析和展示,以及对作者提出的 benchmark 进行介绍。最后对文章进行总结。

方法
主要特点
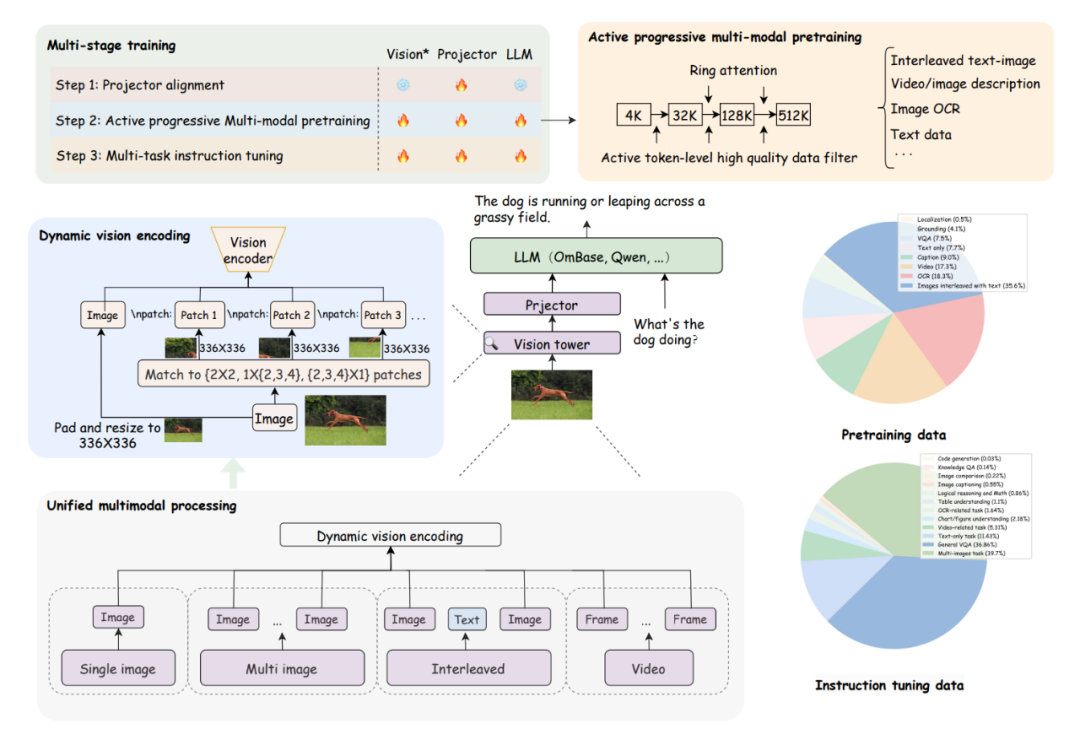
▲ OmChat的模型框架和训练策略
OmChat 与先前工作的不同之处在于以下几点:
统一多模态处理方式:OmChat 实现了处理各种类型视觉输入的统一方法。无论输入格式如何,OmChat 首先将输入分解为图像,然后将其输入到视觉模块中。这种系统的方法确保所有输入变化,无论是单张图像、多张图像、图像-文本交错组合还是视频帧,都处理为一致的输入。
动态视觉编码:OmChat 实施了类似 AnyRes 的动态视觉编码。通过引入这种动态视觉编码机制可以增强捕捉各种图像分辨率的细节和细微差别的能力。
主动渐进多模态预训练:从 4K 到 512K 实施渐进训练策略,逐步扩
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









