







©PaperWeekly 原创 · 作者 | 朱杰
单位 | 阿里云
研究方向 | NLP、LLM应用

背景
随着大型语言模型(LLMs)在自然语言处理(NLP)领域的突破性进展,对于评估这些模型的新基准测试的需求变得迫切。特别是在中文金融领域,现有数据集在规模和多样性上的限制,使得对 LLMs 进行全面评估面临挑战。
为了解决这一问题,本文提出了 CFLUE(Chinese Financial Language Understanding Evaluation),一个针对中文金融语言理解评估的基准测试,也是目前中文金融领域数量最多、最全面、并且被国际顶会认可的 Benchmark。

论文标题:
Benchmarking Large Language Models on CFLUE: A Chinese Financial Language Understanding Evaluation Dataset
收录会议:
ACL 2024
论文链接:
https://arxiv.org/abs/2405.10542
代码链接:
https://github.com/aliyun/cflue

相关工作
在英文金融领域,已经存在多个评估数据集,如 FINQA、TAT-QA、BizBench 等,它们强调了数值推理过程或结合了表格和文本数据。而在中文领域,CCKS 系列自 2019 年以来发布了多个事件抽取任务的数据集,FinanceIQ 和 FinEval 提供了数千个多项选择题对,但任务多样性有限。与此相比,CFLUE 提供了一个更为全面和异构的基准任务集合,以更全面地评估模型性能。
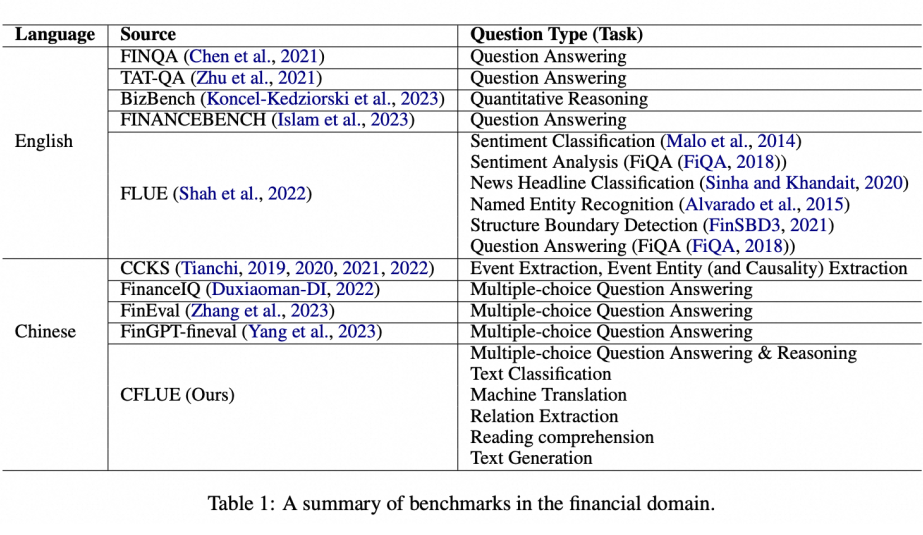

CFLUE Benchmark
3.1 任务和数据
CFLUE 基准测试旨在从多个维度评估模型在金融领域的知识能力。它包括知识评估和应用评估两大部分:
● 知识评估:包含 38K+ 多项选择题,来源包括 15 种不同类型的金融资格模拟考试,涵盖不同难度级别和科目。知识评估任务专注于评估模型对金融知识的理解程度,主要通过多项选择题的形式来实现。
多项选择题答案预测:此任务包含超过 38K 道多项选择题,选题覆盖 15 种不同难度和领域的金融资格模拟考试。每道题目都提供了一个或多个选项,并且只有一个正确答案。此任务旨在测试模型对金融概念和原理的掌握程度。
问题推理:除了预测正确答案外,每道题目还附带了专业的解答说明,这为评估模型的逻辑推理能力提供了依据。模型需要展示其不仅能够选出正确答案,还能够理解背后的原因。
● 应用评估:应用评估任务则更侧重于模型对金融知识的实践应用能力,涵盖了以下五个主要的 NLP 任务类别:包含 16K+ 测试实例,涵盖文本分类、机器翻译、关系提取、阅读理解和文本生成等五个 NLP 任务组。
文本分类:包含六个子任务,如对话意图分类、ESG(环境、社会和公司治理)分类、金融事件分类等。每个子任务都有其独立的分类体系,涵盖从 3 到 77 个不同的类别。
机器翻译:包含中文到英文(Zh→En)和英文到中文(En→Zh)两个翻译子任务。数据集来源于双语经济新闻报道,用于评估模型在金融术语翻译上的能力。
关系提取:包含事件抽取、情感分析中的特征提取、事件因果关系抽取和事件实体抽取四个子任务。这些任务涉及从金融文本中识别和提取实体和它们之间的关系。
阅读理解:此任务以问答形式进行,要求模型根据提供的文本段落和相关问题,输出答案。数据来源包括新闻报道、保险产品文档和研究报告。
文本生成:包含对话摘要、会议摘要、新闻标题生成、研究报告标题生成和术语解释五个子任务。这些任务评估模型生成金融相关文本的能力。
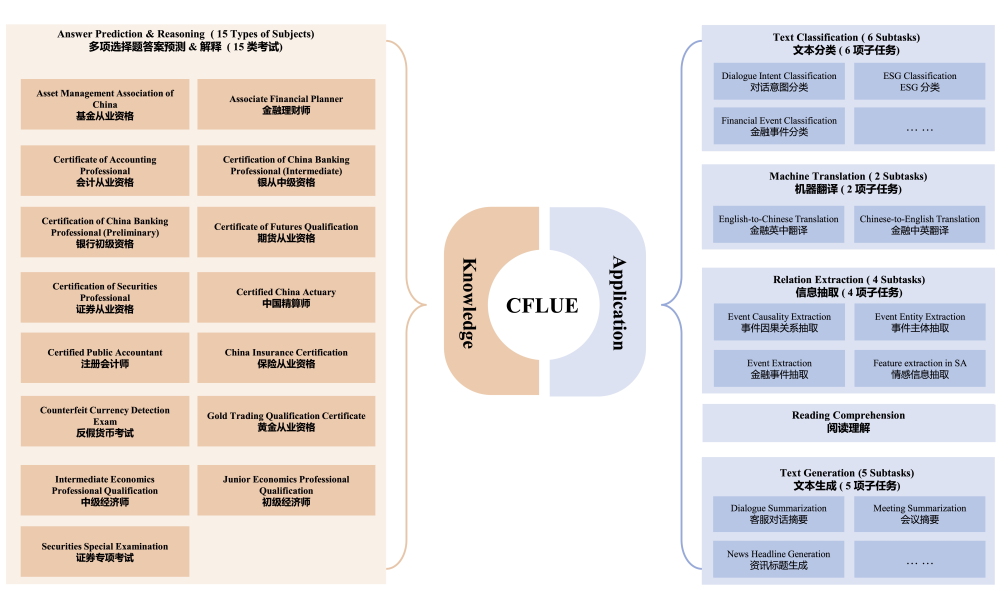
3.2 数据统计
CFLUE 的数据经过标准预处理流程,包括去重复和排除依赖非文本信息的问题等。详细统计数据见附录 C。
3.3 质量控制
为确保数据集的质量,所有涉及手动注释的数据都由具有金融相关经验和教育背景的注释者完成。注释者接受了全面的培训,并在项目过程中由高级分析师进行审核和反馈。
CFLUE 基准测试通过精心设计的任务和严格的数据收集流程,为评估和推动中文金融领域 LLMs 的发展提供了坚实的基础。
3.4 实验
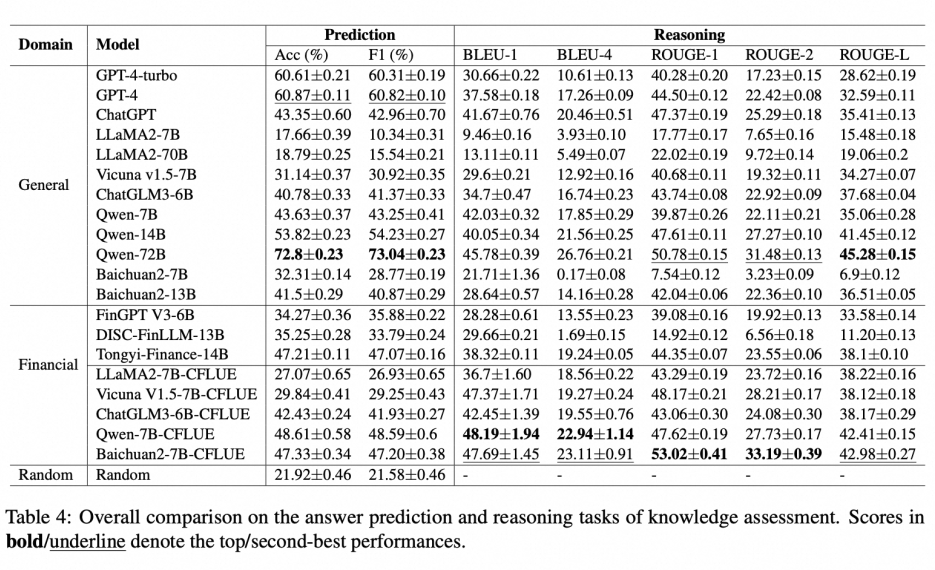
实验部分对多个代表性的 LLMs 进行了评估,包括 OpenAI 的三个 LLMs 和多个轻量级 LLMs。评估在零样本(zero-shot)设置下进行,使用了准确率、F1 分数、BLEU、ROUGE 等指标。
知识评估榜单
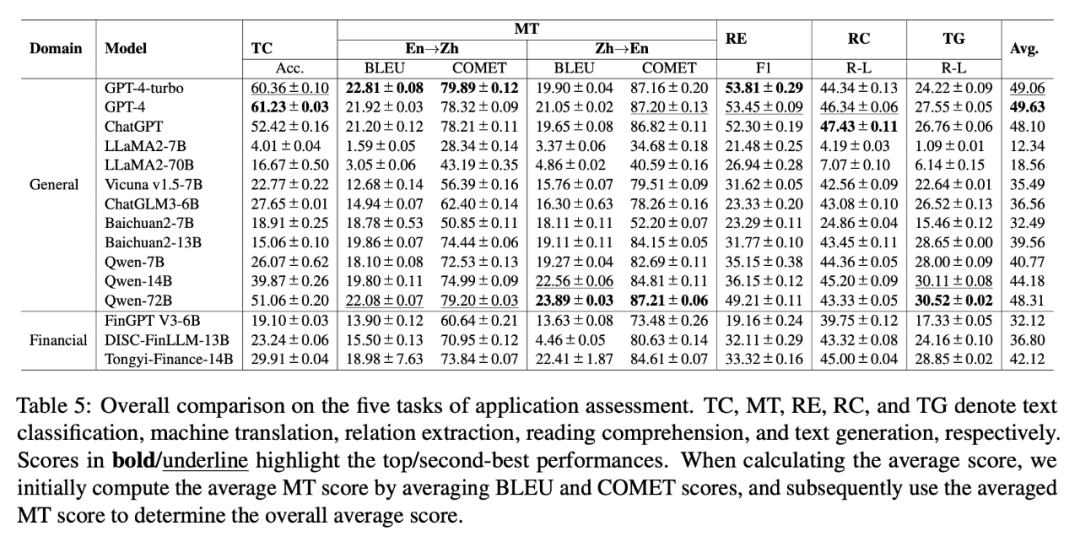
应用评估榜单

结论
CFLUE 提供了对中文金融领域 LLMs 性能的全面评估,揭示了即使是当前最佳表现者也有很大的改进空间。作者希望 CFLUE 能够指导开发者从多个维度了解他们的模型能力,并促进中文金融领域基础模型的发展。

参考文献
1. Alvarado et al., 2015: Julio Cesar Salinas Alvarado, Karin Verspoor, and Timothy Baldwin. 2015. Domain adaption of named entity recognition to support credit risk assessment. In Proceedings of the Australasian Language Technology Association Workshop, pages 84–90.
2. Bai et al., 2023: Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, and others. 2023. Qwen technical report. Computing Research Repository, arXiv:2309.16609.
3. Chen et al., 2021: Wei Chen, Qiushi Wang, Zefei Long, Xianyin Zhang, Zhongtian Lu, Bingxuan Li, Siyuan Wang, Jiarong Xu, Xiang Bai, Xuanjing Huan, and Zhongyu Wei. 2023. Disc-finllm: A chinese financial large language model based on multiple experts fine-tuning. Computing Research Repository, arXiv:2310.15205.
4. Devlin et al., 2019: Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL, pages 4171–4186.
5. Hendrycks et al., 2021: Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In Proceedings of ICLR.
6. Hu et al., 2022: Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. Lora: Low-rank adaptation of large language models. In Proceedings of ICLR.
7. Islam et al., 2023: Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know what you don’t know: Unanswerable questions for squad. In Companion Proceedings of WWW, pages 784–789.
8. Lin & Hovy, 2002: Chin-Yew Lin and Eduard Hovy. 2002. Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of ACL, page 311-318.
9. Mao et al., 2023: Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. 2023. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. In Proceedings of NeurIPS.
10. Papineni et al., 2002: Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of ACL, page 311-318.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









