







©PaperWeekly 原创 · 作者 | 陈锰钊
单位 | 香港大学,上海人工智能实验室
研究方向 | 大模型压缩与加速
本文介绍一种新型量化量化方式,EfficientQAT。大语言模型的 4-bit 量化相对来说已经较为成熟,掉点少。
近期,众多工作聚焦于推进 2-bit 量化。考虑到均匀(INT)量化的显著性能损失,近期领域内主要关注 vector 量化,例如用于 2-bit 精确量化的 AQLM [1] 和 QUIP# [2]。但他们 [1,2] 或是引入额外不可忽略的计算开销,或是数据格式难以实现实际加速,给部署带来了诸多挑战。在 EfficentQAT 中,我们致力于突破 INT 量化的局限性。
如下图 1 所示,我们在保持 INT 量化容易落地部署的特性下,成功地使 INT 量化达到与 vector 量化相当的性能。特别是,EfficientQAT 可以在 41 小时内在单个 A100-80GB GPU 上完成对 2-bit Llama-2-70B 模型的量化感知训练。与全精度模型相比,精度仅下降了不到 3%(69.48 vs. 72.41)。
值得注意的是,该 INT2 量化的 70B 模型比 Llama-2-13B 模型获得了 1.67 的精度增益(69.48 vs. 67.81),同时需要更少的内存(19.2GB vs. 24.2GB)。
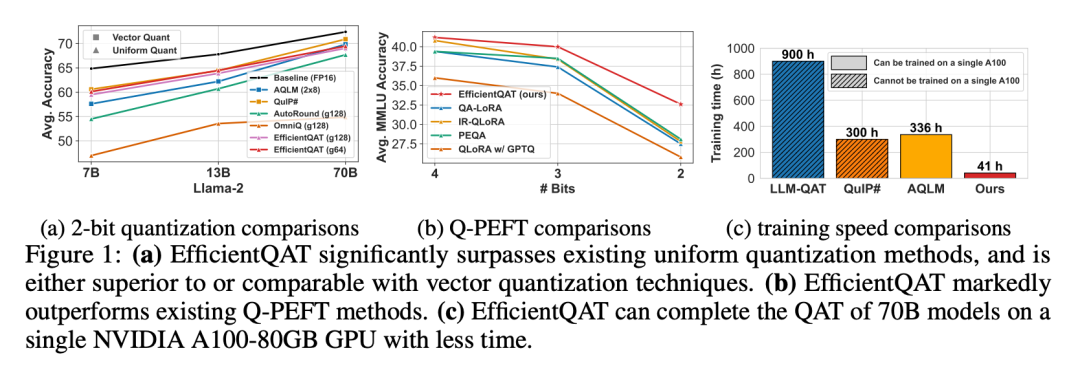
▲ 图1. 方法性能总览
相关资源如下:

论文标题:
EfficientQAT: Efficient Quantization-Aware Training for Large Language Models
文章链接:
https://arxiv.org/abs/2407.11062
代码链接:
https://github.com/OpenGVLab/EfficientQAT
同时,我们也在 huggingface 上提供了量化后的模型,以及将量化模型 repack 成更多不同的格式,例如 GPTQ 格式以及 BitBLAS 格式:
EfficientQAT量化后的模型:
https://huggingface.co/collections/ChenMnZ/efficientqat-6685279958b83aeb6bcfc679
转化为GPTQ格式:
https://huggingface.co/collections/ChenMnZ/efficientqatgptq-format-669e050e0060107f091edc95
转化为BitBLAS格式:
https://huggingface.co/collections/ChenMnZ/efficientqat-bitblas-format-669e0559fe9496b3c6fca59c
注意,由于原本的 AutoGPTQ 对 asymmetric quantization 存在一个数据溢出的 bug(详见 Lin Zhang:分析 AutoGPTQ 中存在的一个 Bug),所以我们选择的是 AutoGPTQ 的官方 bug 修订版 GPTQModel 进行 repack。

背景
为了更好得理解量化操作是如何加速大语言模型(Large Language Models, LLMs)的,我们首先介绍模型推理过程中的计算瓶颈。
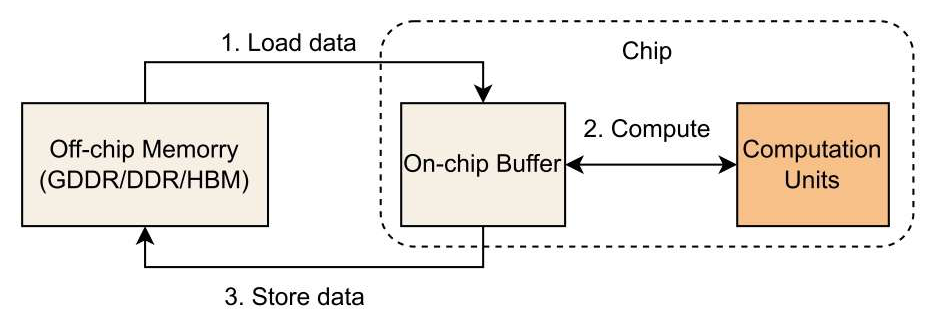
▲ 图1 一个操作(如矩阵乘法等)在硬件上的执行过程 [3]。
如图 1 所示,一个操作的计算时间可以分为两大块的和,分别是数据处理时间以及计算执行时间。为了更好的理解计算瓶颈是在数据搬运还是在计算执行上,我们引入一个经典的 roofline 性能分析模型。
如图 2 所示,x 轴是计算密度,即每秒计算次数和每秒数据搬运次数的比值;y 轴即每秒可以完成的计算次数(Operation Per Seconds, OPS)。从图 2 我们可以看出,当计算密度低时,操作就是内存密集型 (memory-bound),通过减少数据搬运开销,增大计算密度,可以显著增加 OPS,实现推理加速的目的。
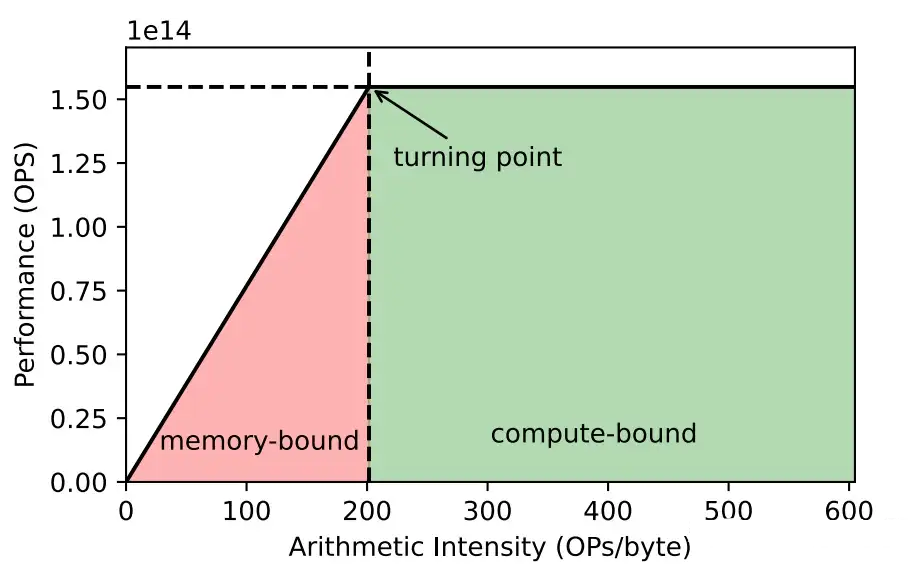
▲ 图2 Roofline 模型。以 NVIDIA A6000 上的 FP16 计算为例 [3]。
值得注意的是,LLMs 的推理可以分为两个阶段,Prefilling 阶段和 Decoding 阶段。我们主要关注占据大部分时间的 Decoding 阶段,此时 LLMs 执行的是逐 token 的自回归推理。
计算每个 token 所需要的计算量低,但是却需要搬运整个模型的权重,导致计算密度低,即模型属于 memory-bound。因此,一种直接的加速手段,也即本文的研究对象,就是 weight-only quantization:通过降低 weight 的 bit 数,以同时实现推理时的显存减少和推理速度提升。

方法
如前文所述,INT2 量化会带来显著的性能损失。一种可能的解决方案是 Quantization-Aware Training(QAT):
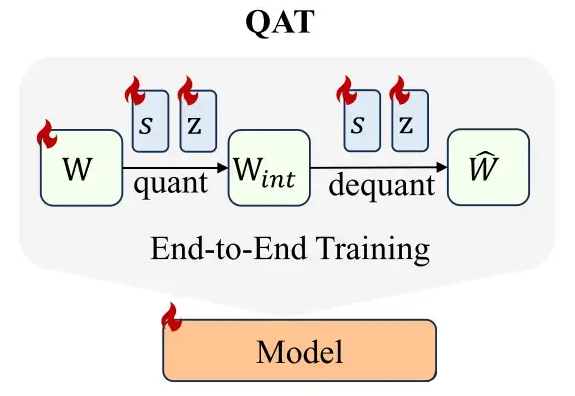
▲ 图3 QAT示例图
如图 3 所示,QAT 需要同时端到端的训练整个网络的所有权重以及量化参数,导致内存开销大,以及对数据质量的要求高。
近期的工作 BitNet b1.58 [4] 证明了 3 值 QAT 也能达到和 FP 模型类似的精度。但是,由于 QAT 的巨大训练开销,导致 BitNet b1.58 也仅在 3B 模型以及 100B 训练 tokens 上进行了验证。总的来说,QAT 是提升量化模型的有效手段,但巨大的训练开销阻碍了其应用。
为了解决 QAT 的高训练开销问题,我们提出平替版,EfficientQAT:
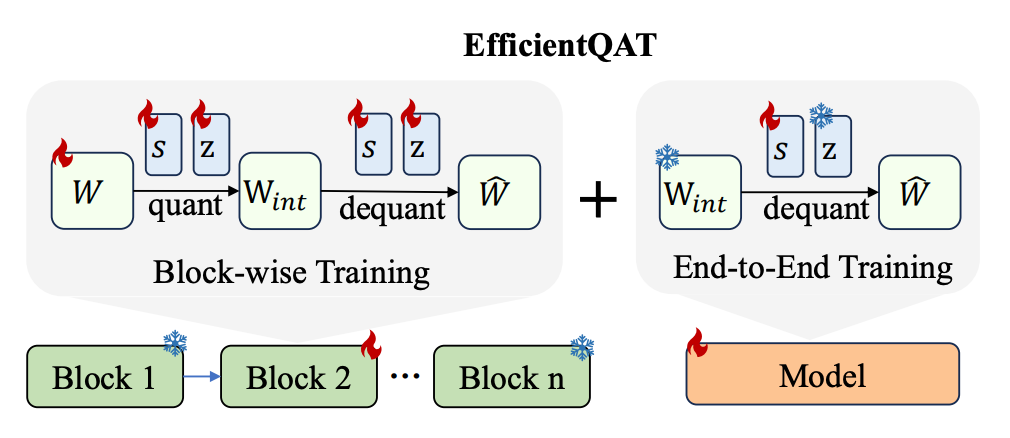
▲ 图4 EfficientQAT 示例图
如图 4 所示,EfficientQAT 的主要思路有两点:
将整体的 End-to-End Training 解耦成同时包含 Block-wise Training 和 End-to-End Training 的两阶段训练方式。
将 weight 的更新限制在 Block-wise Training 阶段。
具体而言,引入 Block-wise Training 的思路主要 follow 此前的工作 BRECQ [5] 和 OmniQuant [4], 旨在通过此细粒度的 Block-wise MSE 重建监督降低对数据量的需求。
同时,我们发现,在 Block-wise Training 阶段,简单的直接优化权重和相关量化参数即可获得最优性能。无需像此前的 PTQ 方法一样设计 rounding parameters [6,7] 或者 clipping parameters [4] 以约束解空间防过拟合。
由于此 Block-wise Training 阶段所有参数被同时训练,我们将其称为:Block-wise Training with All Parameters(Block-AP)。
进一步的,我们希望对网络进行端到端训练以实现进一步降低量化损失的能力,以及实现支持模型 adapt 到任意数据集的能力。
基于此,我们提出 End-to-End Training with Quantization Parameters(E2E-QP)。我们首先对 Block-AP 量化后的低 bit 模型进行 pack,使得其可以用更少的内存读取,降低训练内存开销。
其次,我们发现,在小数据的 End-to-End training 上,单独训练量化参数 step size(s), zero point (z) 或者两者同时训都能达到类似的性能,但是训练 z 需要将其从低 bit 的表现形式转化回 fp16,引入了额外的存储开销。基于此,在 E2E-QP 阶段,我们选择只训练量化参数 s。

实验结果
训练数据:Block-AP 阶段采用来自 RedPajama 数据集的 4096 个长度为 2048 的片段,E2E-QP 阶段采用来自 RedPajama数据集的 4096 个长度为 4096 的片段。

▲ 表1 zero-shot tasks 性能对比
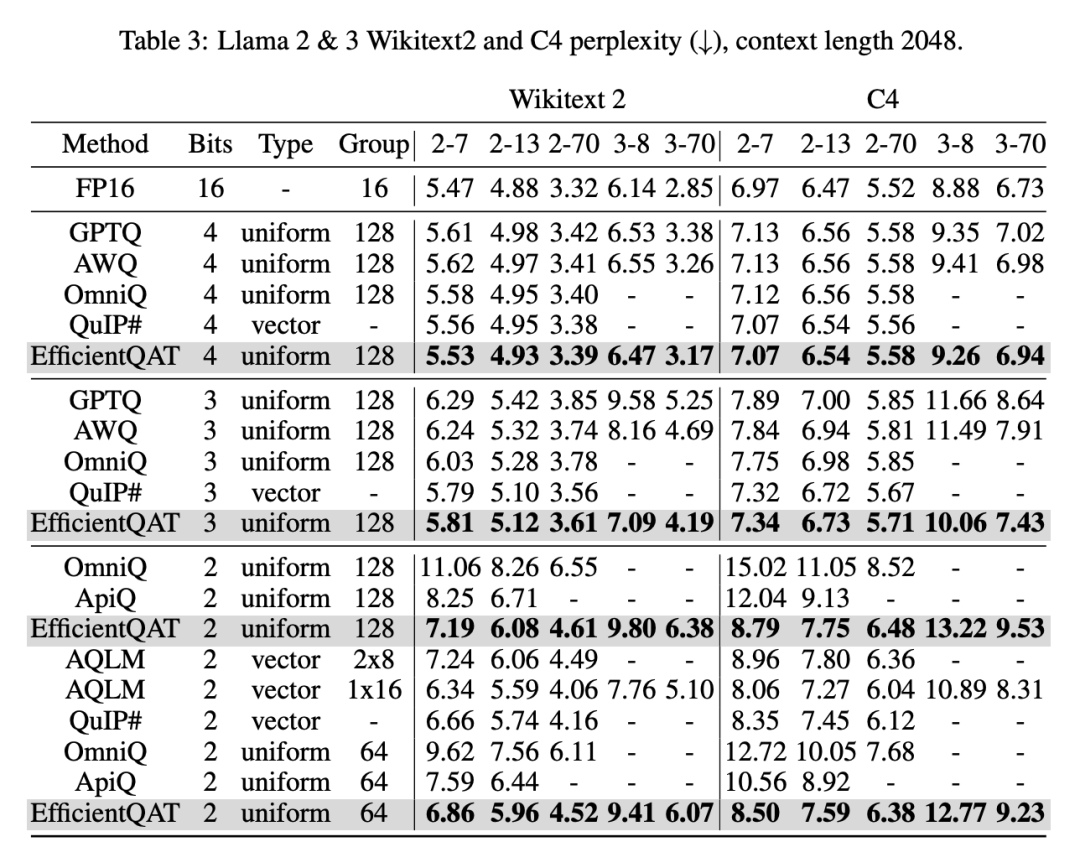
▲ 表2 Perplexity 性能对比
如表 1 和表 2 所示,EfficientQAT 在低 bit 场景相较于此前的 uniform 量化方案性能优势明显,同时产生于 vector 量化方案 comparable 的结果。需要注意的是,表中加粗并不表示最优,因为大多数情况下,性能最优方案是 vector 量化,但需要注意的是他们是以难以部署为代价,如此前的图 1 所示。同时,值得注意的是,Llama-3 的量化难度或者量化敏感性显著高于 Llama-2,和此前的文献 [3] 观察类似。
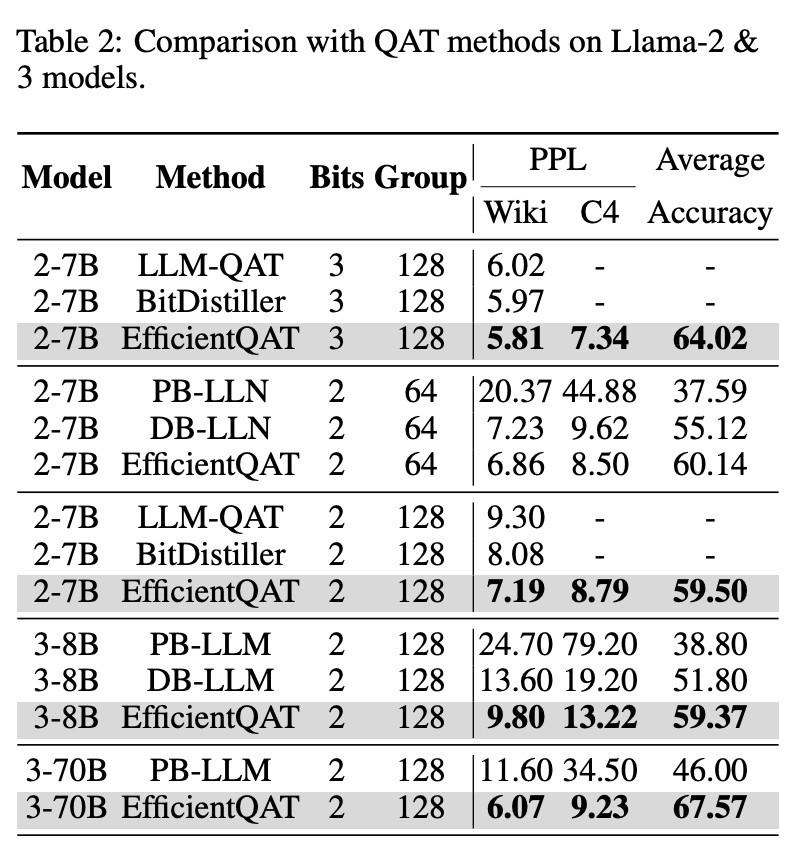
▲ 表3 和 QAT 方法的对比
表 3 给出了 EfficientQAT 和此前的一些 LLM QAT 方案的对比。
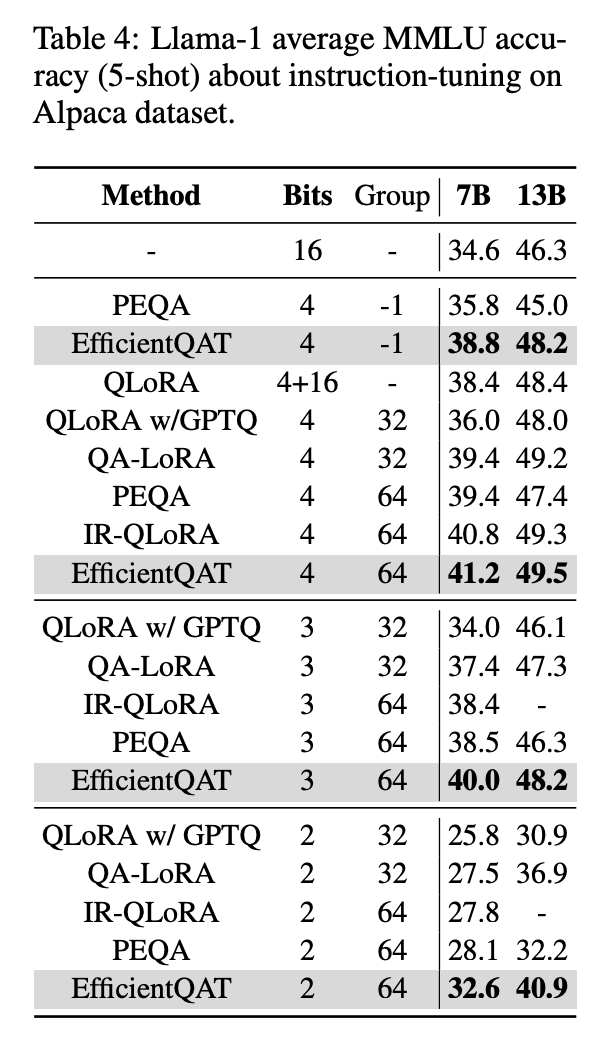
▲ 表4 和量化高效参数微调方法的对比
通过修改 E2E-QP 阶段的数据集,EfficientQAT 也可以实现和此前 Q-LoRA [9] 系列工作, 即量化版 parameter-efficient fine-tuning。但值得注意的是 EfficientQAT 不需要引入额外的 LoRA 模块,其本身训练的量化参数即可视为 Adapter。如表 4 所示,可以发现 EfficientQAT 显著优于此前的方案,我们将性能优势其归因为 Block-AP 阶段量化的初始化。
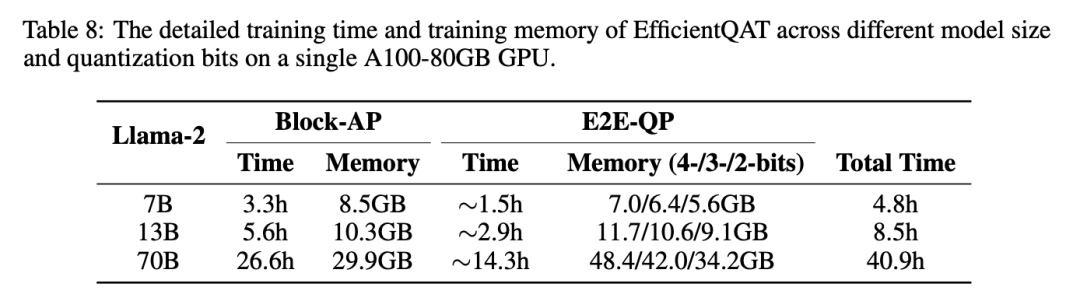
▲ 表5 训练开销
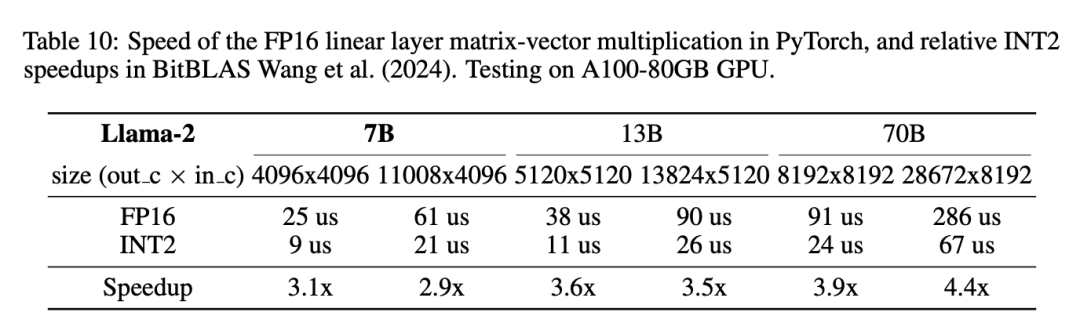
▲ 表6 推理加速
表 5 和表 6 分别呈现了 EfficientQAT 的量化开销以及推理加速。更多实验以及分析可以参见原文。

总结
在本研究中,我们引入了 EfficientQAT,它在内存使用和训练时间上均提高了量化感知训练(QAT)的效率。
经过全面测试,EfficientQAT 在多样性和性能方面超越了现有的后训练量化(PTQ)、量化感知训练(QAT)以及量化参数高效微调(Q-PEFT)方法,适用于不同模型和量化级别。此外,EfficientQAT 利用标准均匀量化,这简化了使用现有工具箱进行部署的过程。

参考文献
[1] Extreme Compression of Large Language Models via Additive Quantization
[2] QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
[3] LLM Inference Unveiled: Survey and Roofline Model Insights
[4] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
[4] OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
[5] BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction
[6] Up or down? adaptive rounding for post-training quantization.
[7] Optimize weight rounding via signed gradient descent for the quantization of llms
[8] How Good Are Low-bit Quantized LLAMA3 Models? An Empirical Study[9] QLORA: Efficient Finetuning of Quantized LLMs
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 258
258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









