







©PaperWeekly 原创 · 作者 | 吴俊康
单位 | 中国科学技术大学博士生
研究方向 | 大模型微调
-DPO 是一种改进的直接偏好优化(DPO)框架,它通过动态调整超参数 来适应不同的数据质量和减少异常值的影响。该方法不仅提高了偏好优化的效果,而且因其简单有效、无需复杂配置而易于实施。
实验结果显示,-DPO 在多个数据集上都优于传统的 DPO 方法,展示了其作为未来语言模型训练优化策略的潜力。

论文标题:
β-DPO: Direct Preference Optimization with Dynamic β
论文链接:
https://arxiv.org/pdf/2407.08639
Github地址:
https://github.com/junkangwu/beta-DPO

背景介绍
随着大规模语言模型(LLMs)的广泛应用,如何让模型输出更符合人类偏好成为了焦点问题。直接偏好优化(DPO)作为一种有效的训练策略,通过偏好数据的指导,使得 LLMs 更好地满足人类的需求。
然而,DPO 的性能高度依赖于其中的超参数 ,并且对数据质量尤为敏感。如何找到最佳的 值,成为影响模型表现的关键因素之一。
面对固定 值的局限,我们提出了一种全新的框架——-DPO。-DPO 通过动态调整 值,并依据数据质量进行优化,从而提升了 DPO 的性能。此外,-DPO 还引入了 引导的数据过滤方法,以减少异常值对模型训练的影响。
通过实证评估,我们证明了 -DPO 在多种模型和数据集上显著提高了 DPO 的性能,为 LLMs 的训练提供了一种更加稳健和适应性强的范式。
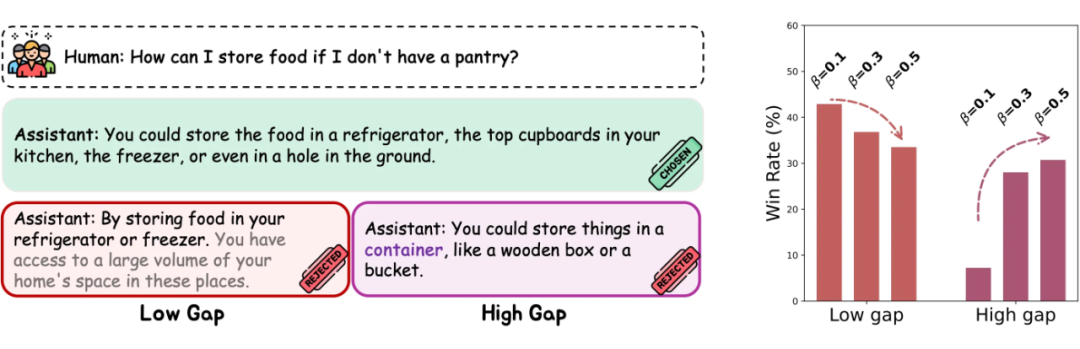

为什么选择 -DPO?
2.1 动机:数据质量对 选择的影响
在 DPO 训练中, 的选择和数据质量是关键因素。我们通过实验分析了这两个因素对 DPO 有效性的影响,这对于其在现实中的应用至关重要。
实验使用了 Anthropic HH 数据集,包括约 17 万个对话。每个询问 都配对两个回答 ,其中 是偏好的回答, 是非偏好的回答。我们在不同数据集上研究了数据质量与 的关系:
低差异数据:偏好差异小,使用 HH 原生数据集。
高差异数据:偏好差异大,使用由 SFT 模型生成的回答替换 。
混合差异数据:结合低差异和高差异数据,各占 50%。
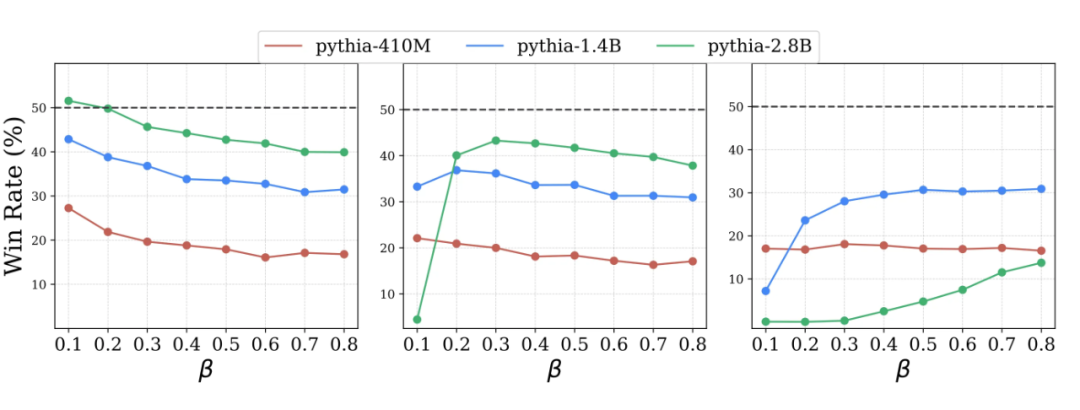
发现:
1. 最优 值的选择随数据质量变化,揭示不同数据集的性能模式。上图展示了在不同 参数下,针对三种偏好差异的胜率结果。在低差异数据中,较小的 值更能提升性能,因为数据的信息量允许较低的 促进模型更新,提高对齐准确性。
相反,在高差异数据中,低 值可能导致过拟合,破坏对齐过程。混合间隙数据集显示出复杂的性能模式,需要动态 校准策略以适应不同数据质量。因此,固定的 值可能不足以应对真实世界数据集的多样性。
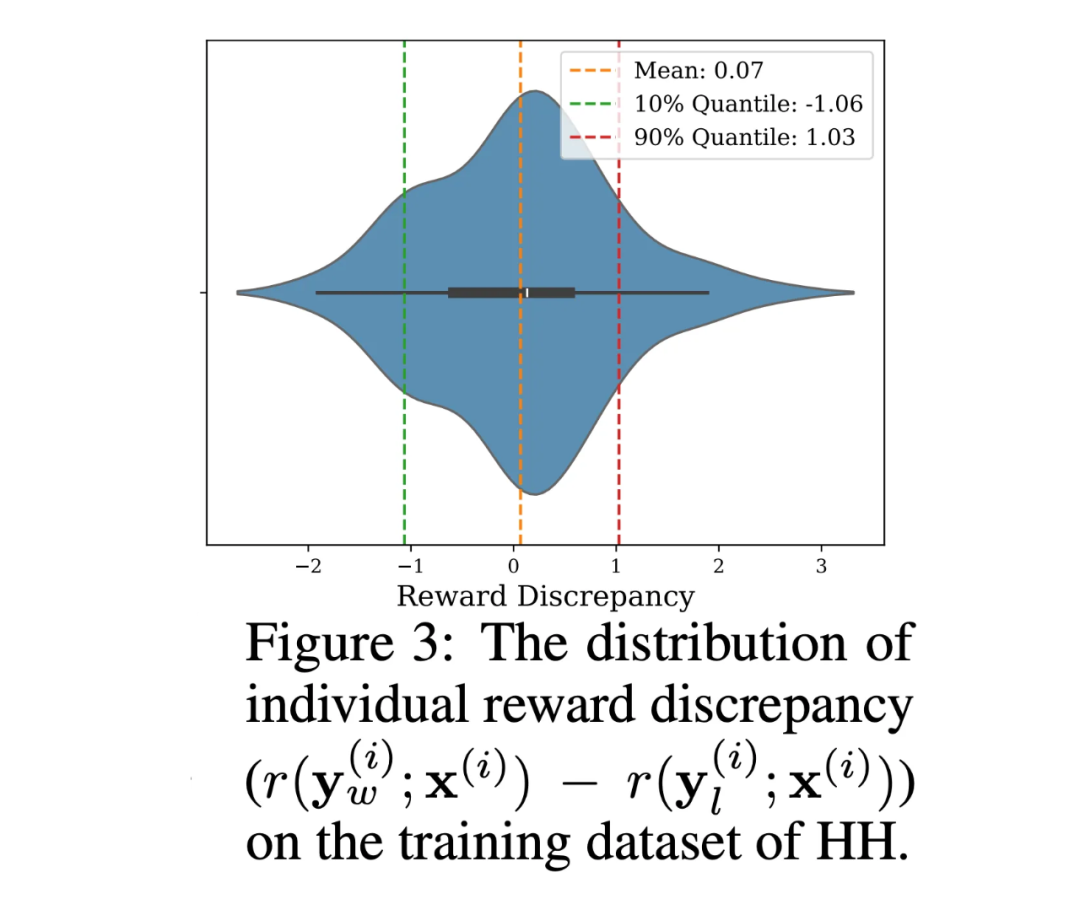
2. 数据集中存在显著异常值。在上图 2 中,使用 Pythia-2.8B 模型,我们分析了 HH 数据集中每个样本的 reward 差异。密度图显示,部分样本的 reward 差异显著偏高或偏低。正负样本 reward 差值过大表明信息价值低,而 reward 差值过小可能暗示标注错误。这些偏离合理范围的样本被视为异常值。
2.2 方法:动态 校准方法
我们的分析表明,DPO 对 的选择非常敏感,并且数据中常出现异常值。因此,选择最佳 值时需考虑数据质量并减少异常值影响。我们提出以下指导原则:
原则1:最佳 值应响应数据质量变化。
原则2: 的选择应最小化异常值的影响。
2.2.1动态 批次级校准
为了解决 DPO 在优化过程中可能出现的不稳定性,我们提出在每个批次动态调整 值。对于高质量、差异较小的数据对, 值会自动降低,从而促进更大的更新。而对于容易区分的数据对, 值则会相应提高,以避免过拟合。这种批次级别的调整确保了在不同数据质量下的稳定性。
具体来说,对于每个三元组 ,定义“个体奖励差异”为:
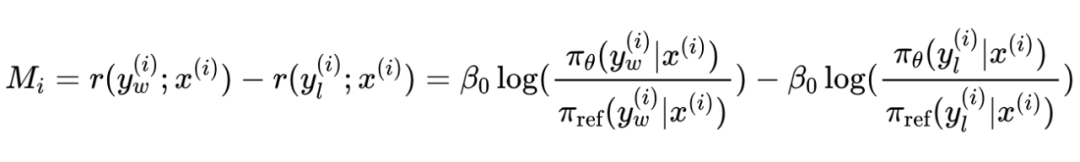
这里的 我们采用 DPO implicit 的 reward 表达式,实验部分我们同样尝试了 explicit reward 表达式。根据个体奖励差异,我们可以定义每个批次的 值更新为:
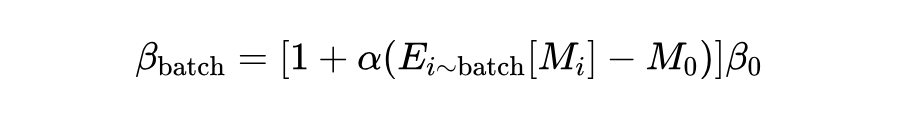
其中, 为基准参数, 为一个控制更新幅度的缩放因子,特别地,当 时,,即退化为 vannila DPO。上述等式说明了 与 单调递增,使模型能够根据配对样本之间运行中的奖励差异来调整 值。而 是个体奖励差异的全局均值,采用移动平均更新:
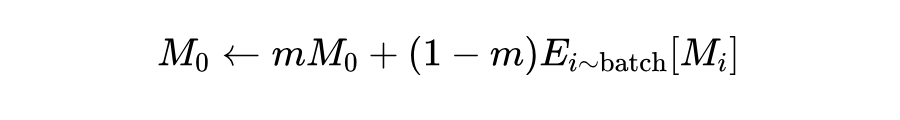
这种批量级校准方法只引入了一个新参数 ,用于控制 调整的规模。计算 在 DPO 算法中直接产生且不会产生额外的计算开销。
2.2.2 引导的数据筛选
为了应对训练数据中可能存在的异常值,从而影响一个批次对应的 选择,我们提出了基于 值的数据筛选机制。通过计算每个数据样本的个体奖励差异,我们对数据进行筛选,保留较为“可信”的数据样本进行训练。其概率分布为:
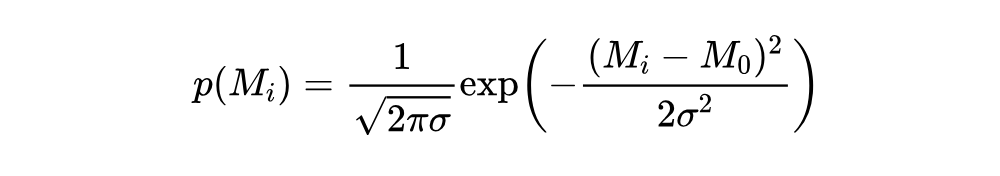
其中, 为奖励差异的标准差,通过移动平均动态估计。这种概率加权评估了每个样本的相对重要性,并根据它们计算出的概率 指导保留∣batch⋅∣× 个样本(不放回)。这里, 表示选择比例,默认值为 0.8,通过初步实验验证了认为该值可以优化训练效率和模型准确性。
注:需要强调的是,这项工作并没有想提出一种新的数据筛选方法,而是我们发现简单的数据筛选策略可以显著提高 批次级校准的稳定性。
2.3 亮点:-DPO框架的以下关键特性
简洁性:-DPO 方法直观易用。通过基于奖励差异 的批量级动态 调整与数据过滤机制,实现了简单有效的实施方案。
高效性:相比依赖额外模型进行数据筛选的方法,-DPO 利用 DPO 框架内固有的奖励差异 进行优化。实验表明,该方法对超参数调节需求较低,默认设置 即可达到良好的效果。
兼容性:作为传统 DPO 的改进版本,-DPO 可无缝集成至现有框架,支持未来功能增强与扩展。实际测试验证了其灵活性。

实验
为了更全面地评估了 -DPO 的有效性,我们在 Anthropic-HH 对话数据集和 TL;DR 总结数据集上进行实验,实验结果如下,-DPO 始终展现其优越性:
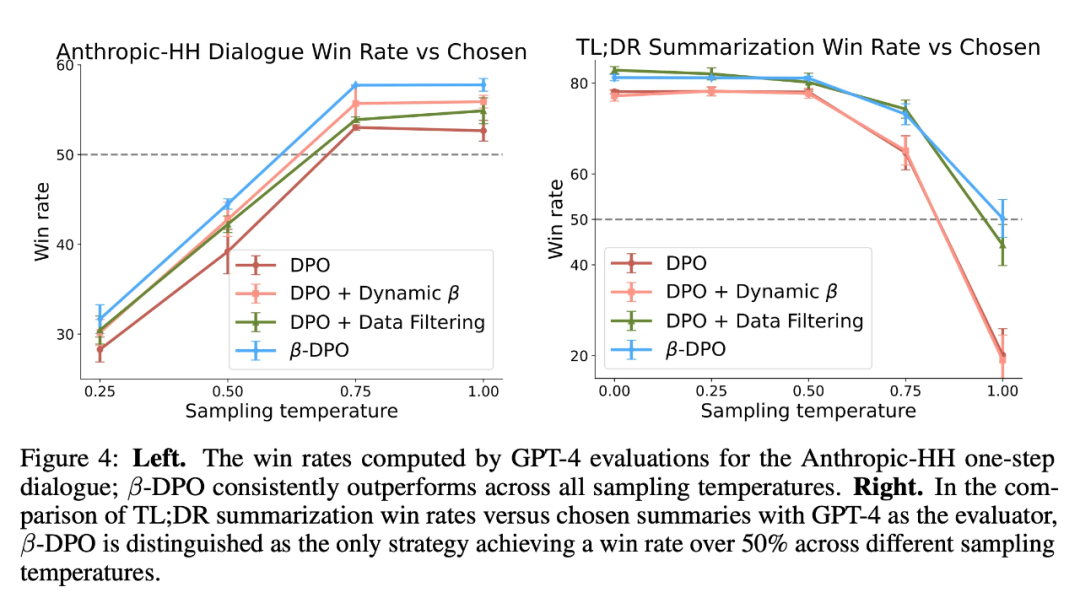
同时我们还尝试了不同的数据筛选策略,以及不同的 DPO 变种,-DPO 均显示出稳定的性能提升。
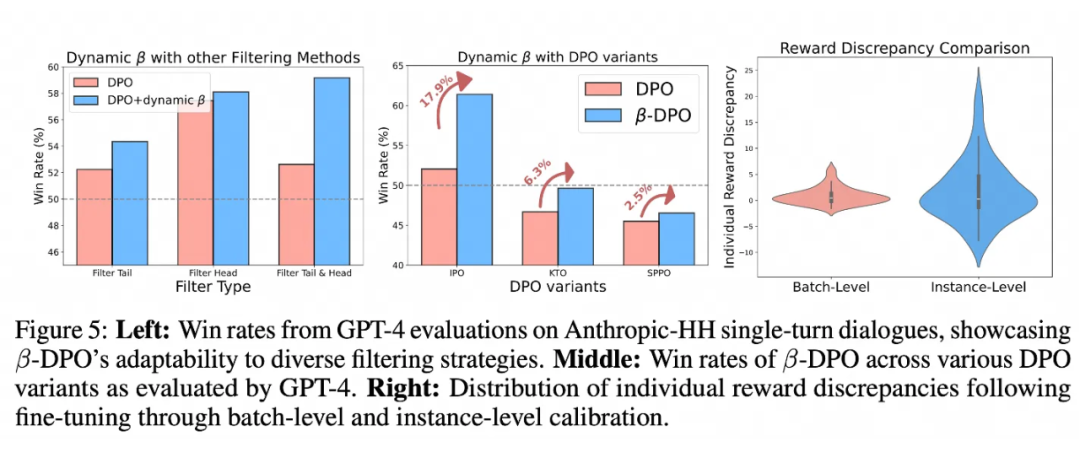
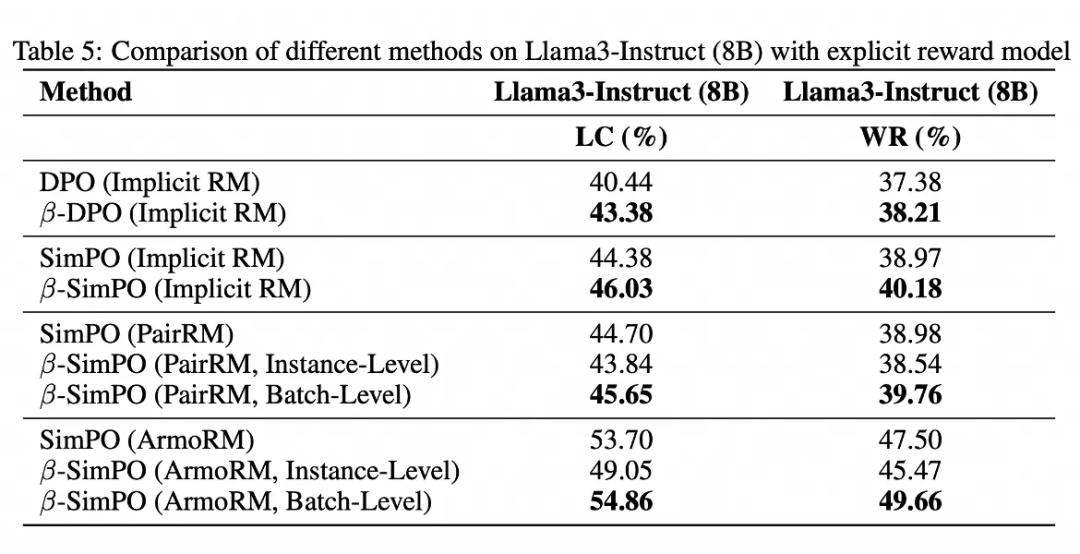
最后,我们不仅在最新的 sota 方法上尝试(e.g. SimPO),同时我们还发现将 的计算替换为显式的 reward,-DPO 均有稳定的性能提升。

总结
-DPO 的核心在于其灵活应对多样化的数据场景,这种动态调整的方法将对大规模语言模型的训练带来新变化。作为一种简单且有效的优化策略,-DPO 不仅提升了偏好优化的表现,同时也为未来 LLM 的训练与优化提供了新的思路。
相关论文:
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. In NeurIPS 2023.
Y. Meng, M. Xia, and D. Chen. Simpo: Simple preference optimization with a reference-free reward. In NeurIPS 2024.
关于作者
本文的第一作者吴俊康(Junkang Wu)是中国科学技术大学(USTC)的四年级博士生,其导师是王翔教授和何向南教授。他在 NeurIPS、WWW、ICDE、EMNLP 等会议上发表了研究论文。吴俊康的研究兴趣包括大模型微调、对比学习等。本项工作是吴俊康在阿里巴巴通义实验室实习期间的成果。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









