







©作者 | 肖光烜
单位 | 麻省理工学院博士生
研究方向 | 深度学习加速
TL;DR:DuoAttention 通过将大语言模型的注意力头分为检索头(Retrieval Heads,需要完整 KV 缓存)和流式头(Streaming Heads,只需固定量 KV 缓存),大幅提升了长上下文推理的效率,显著减少内存消耗、同时提高解码(Decoding)和预填充(Pre-filling)速度,同时在长短上下文任务中保持了准确率。

论文标题:
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
论文链接:
https://arxiv.org/abs/2410.10819
Github地址:
https://github.com/mit-han-lab/duo-attention
单 GPU 实现 330 万 Token 上下文推理演示视频:
随着大语言模型(Large Language Models,LLMs)在各类任务中的广泛应用,尤其是在长上下文(Long-Context)场景中处理海量文本信息,如何在保证模型性能的同时减少内存和计算成本,成为了一个亟待解决的难题。
为此,来自 MIT、清华大学、上海交通大学、爱丁堡大学和 NVIDIA 的研究团队联合提出了 DuoAttention 框架。
这项创新技术通过对大语言模型的注意力机制(Attention Mechanism)进行精细化设计,极大提高了长上下文推理的效率,并大幅降低了内存需求,在不牺牲模型准确性的前提下,推动了 LLM 在长上下文任务中的发展。

研究背景:长上下文处理的挑战
现代大语言模型(如 Llama、GPT 等)在多轮对话、长文档摘要、视频和视觉信息理解等任务中需要处理大量历史信息,这些任务往往涉及数十万甚至上百万个 token 的上下文信息。例如,处理一篇小说、法律文档或视频转录内容,可能需要分析百万级别的 token。
然而,传统的全注意力机制(Full Attention)要求模型中的每个 token 都要关注序列中的所有前序 token,这导致了解码时间线性增加,预填充(Pre-Filling)时间呈二次增长,同时,KV 缓存(Key-Value Cache)的内存消耗也随着上下文长度成线性增长。当上下文达到数百万 token 时,模型的计算负担和内存消耗将达到难以承受的地步。

DuoAttention的创新设计
针对这一问题,DuoAttention 框架提出了创新性的 “检索头(Retrieval Heads)” 与 “流式头(Streaming Heads)” 的分离方法。这一设计的核心理念是:并非所有的注意力头(Attention Heads)在处理长上下文时都需要保留完整的 KV 缓存。
研究团队通过大量实验发现,在长上下文推理任务中,只有一小部分注意力头,即 “检索头”,需要对全部 token 进行关注,以获取上下文中的关键信息。而大多数注意力头,即 “流式头”,只需关注最近的 token 和注意力汇点(Attention Sinks),不需要存储全部的历史 KV 状态。
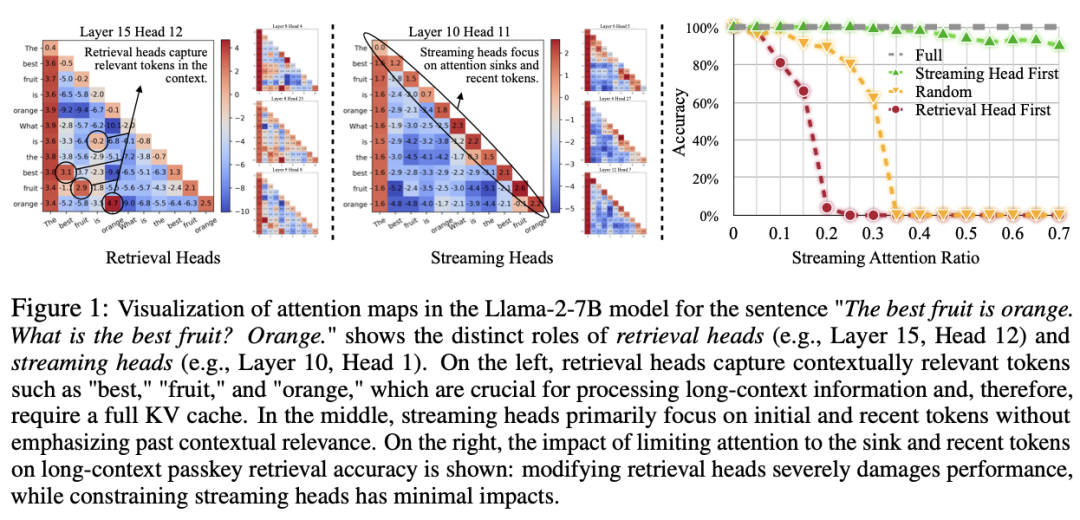
图 1 展示了在 Llama-2-7B 模型上使用全注意力机制的注意力图(Attention Maps)。从图中可以看到,检索头(Retrieval Heads)捕获了上下文中如 "best"、"fruit" 和 "orange" 等关键信息,这些信息对于处理长上下文至关重要,因而需要完整的 KV 缓存。而流式头(Streaming Heads)则主要关注最近的 token 和注意力汇点,不需要保留所有历史信息。

DuoAttention的工作原理
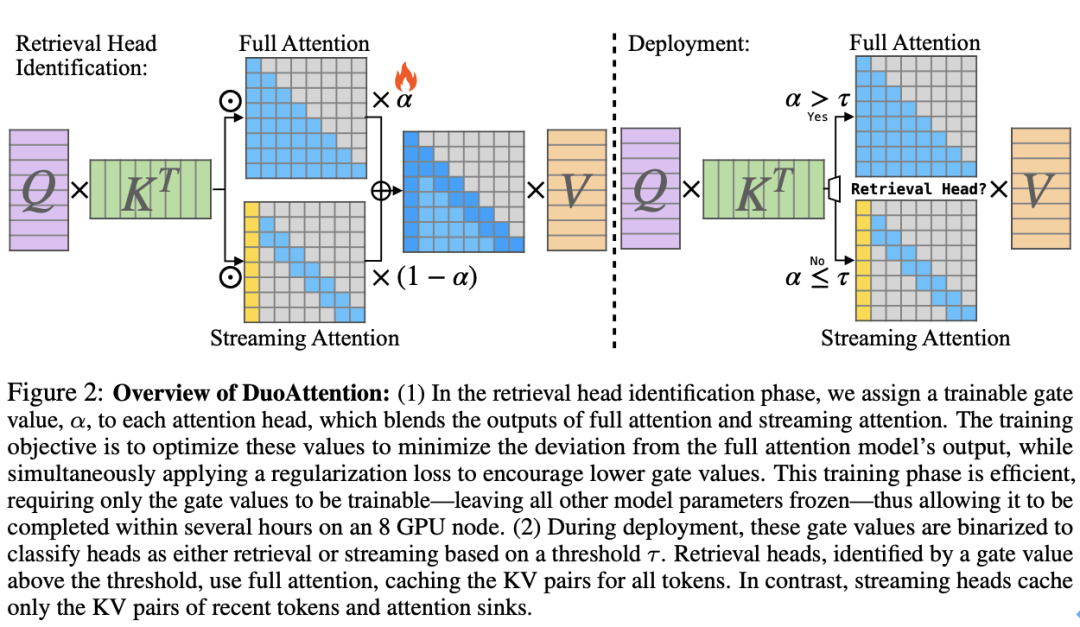
▲ 图2说明了DuoAttention的基本工作原理
框架通过以下几种关键机制来优化推理过程:
检索头的 KV 缓存优化:DuoAttention 为检索头保留完整的 KV 缓存,这些头对长距离依赖信息的捕捉至关重要。如果对这些头的 KV 缓存进行剪裁,将导致模型性能严重下降。因此,检索头需要对上下文中的所有 token 保持 “全注意力(Full Attention)”。
流式头的轻量化 KV 缓存:流式头则主要关注最近的 token 和注意力汇点。这意味着它们只需要一个固定长度的 KV 缓存(Constant-Length KV Cache),从而减少了 KV 缓存对内存的需求。通过这种方式,DuoAttention 能够以较低的计算和内存代价处理长序列,而不会影响模型的推理能力。
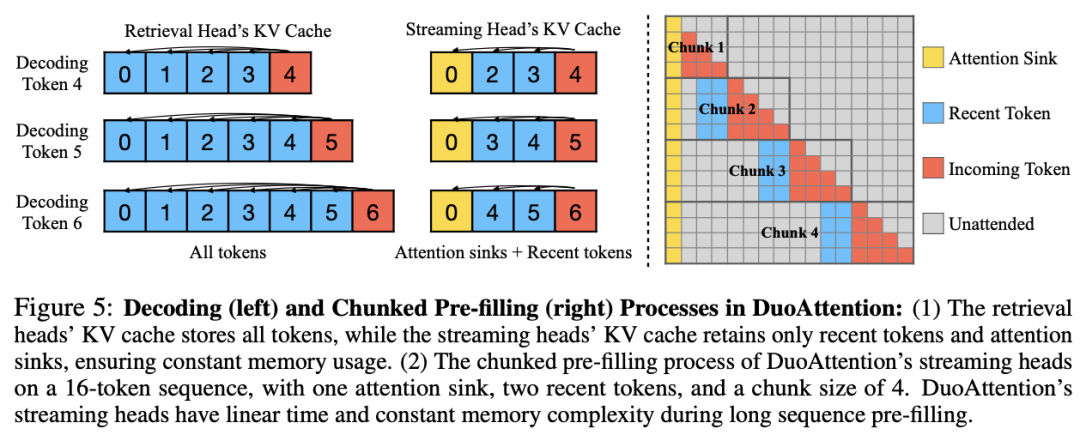
检索头的自动识别:为了准确区分哪些头是检索头,DuoAttention 提出了一种轻量化的优化算法,使用合成数据集来训练模型自动识别重要的检索头。这种优化策略通过密码召回任务(Passkey Retrieval),确定哪些注意力头在保留或丢弃 KV 缓存后对模型输出有显著影响。最终,DuoAttention 在推理时根据这一识别结果,为检索头和流式头分别分配不同的 KV 缓存策略。
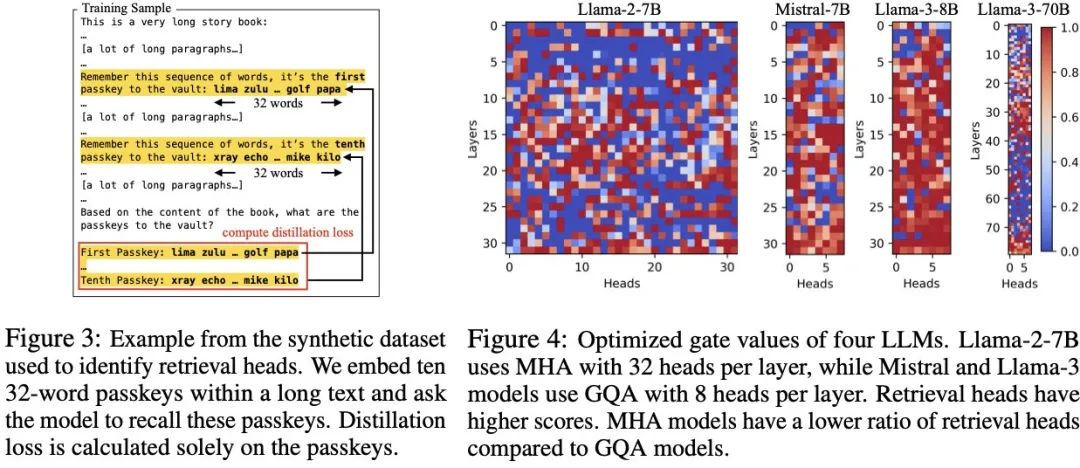
▲ 图 3 展示了 DuoAttention 使用的合成数据集中的一个样例。图 4 展示了 DuoAttention 最终确定 LLM 中各个注意力头的类别。

性能与准确率实验
为了验证 DuoAttention 框架的有效性,研究团队在多种主流 LLM 架构上进行了广泛的实验评估,包括 Llama-2、Llama-3 和 Mistral 模型。实验不仅测试了 DuoAttention 在内存与计算效率上的提升,还通过长上下文和短上下文任务对模型的准确率进行了全面测试。
1. 长上下文任务的评估:在 Needle-in-a-Haystack(NIAH)基准测试中,DuoAttention 在极深的上下文条件下表现卓越,保持了高精度,并在处理 1048K 个 token 的长上下文时,依然能够保持稳定的准确率,而其他方法由于丢失关键信息导致性能下降显著。
在 14 个 LongBench 基准测试中,DuoAttention 展现了在不同任务下的强大泛化能力,能够以较低的 KV 缓存预算,提供接近全注意力机制的准确性。在多头注意力模型(MHA)上,DuoAttention 使用 25% 的 KV 缓存预算即可在多数任务中取得与全缓存相当的效果,而在分组查询注意力模型(GQA)上,50% 的 KV 缓存预算即可维持高精度表现。
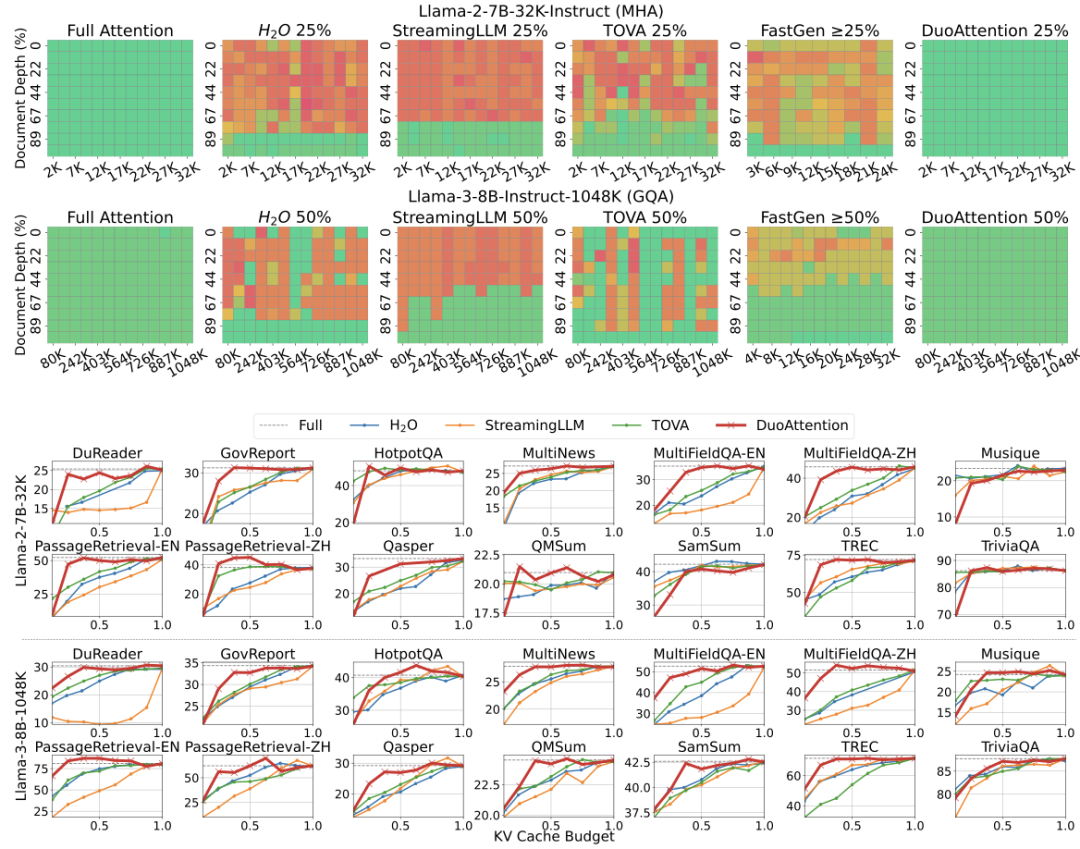
2.短上下文任务的评估:在 MMLU(多项选择题)、MBPP(编程能力)和 MT-Bench(帮助能力)等短上下文基准上,DuoAttention 也表现出色。在使用 50% 流式头的情况下,DuoAttention 的表现几乎与全注意力机制一致,保持了 LLM 在短文本任务上的原始能力。
例如,在 MMLU 基准上,DuoAttention 仅以 0.03% 的差距(79.35% 对比 79.38%)实现了与全注意力机制的相近性能。
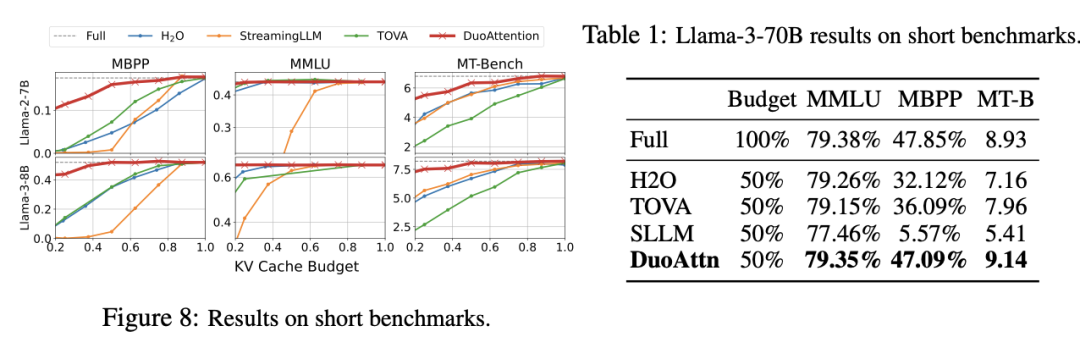

内存与效率的提升
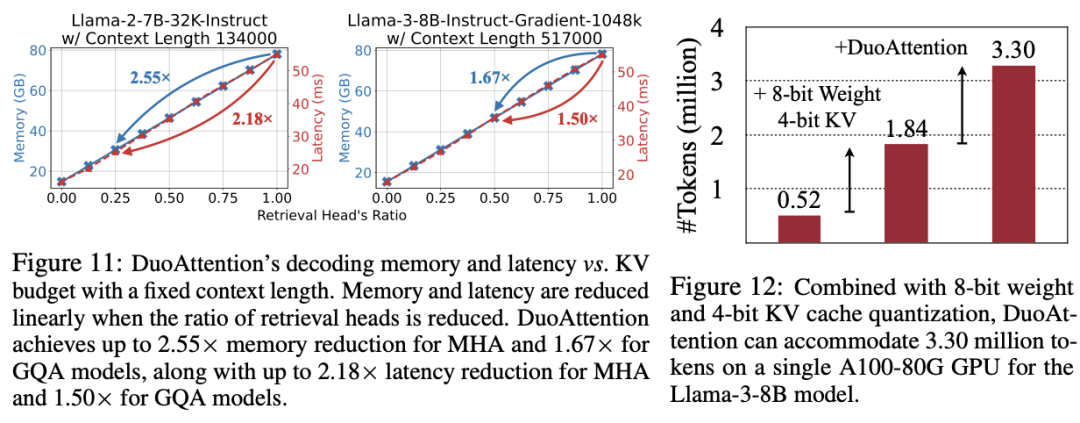
内存消耗显著降低:DuoAttention 在多头注意力模型(Multi-Head Attention,MHA)上将内存消耗减少了 2.55 倍,在分组查询注意力模型(Grouped-Query Attention,GQA)上减少了 1.67 倍。这是由于对流式头采用了轻量化的 KV 缓存策略,使得即使在处理百万级别的上下文时,模型的内存占用依然保持在较低水平。
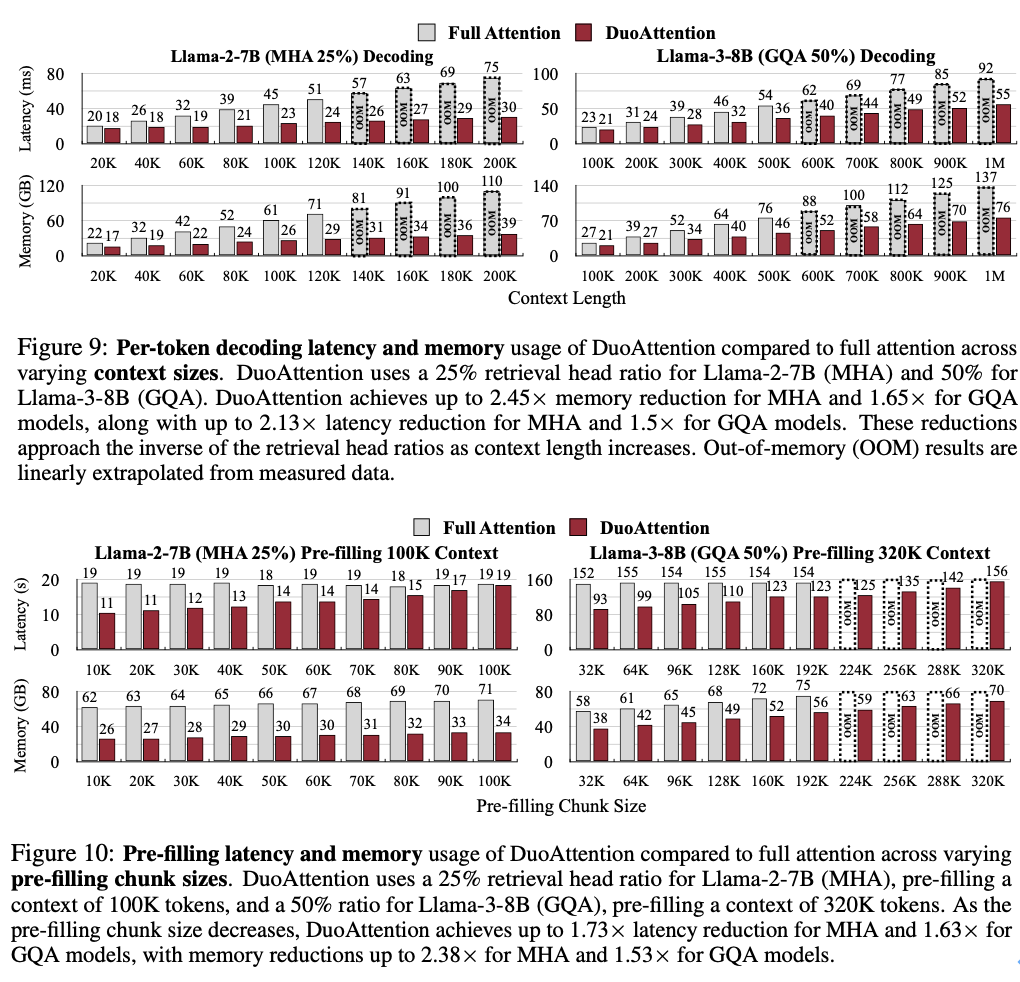
解码(Decoding)和预填充(Pre-Filling)速度提升:DuoAttention 的解码速度在 MHA 模型中提升了 2.18 倍,在 GQA 模型中提升了 1.50 倍。在预填充方面,MHA 和 GQA 模型的速度分别加快了 1.73 倍和 1.63 倍,有效减少了长上下文处理中的预填充时间。
百万级 token 处理能力:结合 4 比特量化(Quantization)技术, DuoAttention 实现 Llama-3-8B 在单个 A100 GPU 上处理高达 330 万 token 的上下文,这一结果是标准全注意力机制的 6.4 倍。

应用场景与未来展望
DuoAttention 框架为处理长上下文的应用场景带来了巨大的变革,特别是在需要大规模上下文处理的任务中表现突出,包括:
多轮对话系统(Multi-Turn Dialogues):DuoAttention 使对话模型能够高效处理长时间对话记录,从而更好地理解用户上下文,提升交互体验。
长文档处理与摘要生成:在文档分析、法律文本处理、书籍摘要等任务中,DuoAttention 极大减少内存占用,同时保持高精度,使长文档处理更加可行。
视觉与视频理解:在涉及大量帧的上下文信息处理的视觉和视频任务中,DuoAttention 为视觉语言模型(Visual Language Models,VLMs)提供了高效推理方案,显著提升了处理速度。
研究团队期望 DuoAttention 框架能够继续推动 LLM 在长上下文处理领域的发展,并为更多实际应用场景带来显著提升。
关于作者
本文第一作者肖光烜是麻省理工学院电子工程与计算机科学系(MIT EECS)的三年级博士生,师从韩松教授,研究方向为深度学习加速,尤其是大型语言模型(LLM)的加速算法设计。他在清华大学计算机科学与技术系获得本科学位。
他的研究工作广受关注,GitHub上的项目累计获得超过9000颗星,并对业界产生了重要影响。他的主要贡献包括SmoothQuant和StreamingLLM,这些技术和理念已被广泛应用,集成到NVIDIA TensorRT-LLM、HuggingFace及Intel Neural Compressor等平台中。本文的指导老师为韩松教授(https://songhan.mit.edu/)
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









