







©PaperWeekly 原创 · 作者 | 程杰
单位 | 中科院自动化所、阿里通义实验室
研究方向 | 强化学习

论文标题:
Scaling Offline Model-Based RL via Jointly-Optimized World-Action Model Pretraining
论文链接:
https://arxiv.org/abs/2410.00564
代码链接(含模型权重):
https://github.com/CJReinforce/JOWA
项目主页:
https://cjreinforce.github.io/JOWA_agents/
TL;DR:
Scaling:通过离线基于模型、基于时序差分的强化学习预训练,所提算法JOWA的性能能够随着模型大小的增加而平稳提升。
SOTA:最大的预训练智能体能够在 15 款 Atari 游戏上达到 84.7% 人类水平和 119.5% 的 DQN 水平。
Few-shots 微调:只需约 4 条 expert-level 游戏轨迹,它就可以快速迁移到新游戏环境中。
更多示例见 github 仓库 /demos 和项目主页。

引言
离线强化学习的一个长远目标就是构建高性能的通才智能体。但是目前强化学习中构建通用智能体的方式主要使用(条件)行为克隆方法,无论是在机器人(具身智能)还是游戏领域,得益于其简单、稳定、以及在 CV、NLP 领域被广泛验证的缩放性的优势。
但是这种预训练方式通常需要大量的专家轨迹,并且难以泛化到不同环境下的新任务上。而基于时序差分的算法虽然能够突破数据质量的限制,有潜力在低质量数据中获得最优策略,但是很多工作发现其难以训练大参数量的模型,常导致训练不稳定、性能下降等现象。
受到 SORA、Genie 等世界模型展现出的卓越的泛化性的启发,本文提出联合优化的世界-动作(jointly-optimized world-action, JOWA)模型来学习通用的表征和决策能力,以期解锁 RL 的 scaling 性质和实现数据高效的跨环境微调。
JOWA 有两点关键的设计:监督损失与时序差分损失的联合优化,以及可并行的、可证明有效性的规划算法。
通过 6B token 的 Atari 游戏数据集预训练,我们观察到基于时序差分的 RL 算法性能与模型大小之间展现出 scaling 现象。实验中最大的预训练智能体 JOWA-150M 在预训练的游戏上达到了 84.7% 人类水平和 119.5%DQN 水平,平均超越了 SOTA 的大规模离线强化学习基线 37.7%。
同时,JOWA 表现出了良好的跨环境的泛化性能。通过在未见游戏上使用 5k 交互数据(约 4 条轨迹)进行微调,JOWA 即可达到 64.7% DQN 水平,平均超越基线 34.7%。由于长训练时间,我们开放了所有的训练、评估、微调代码和系列模型权重。

JOWA模型架构

JOWA 使用 VQ-VAE 将图像状态离散化。除了 token 嵌入和位置编码外,JOWA 还为每个游戏单独设置了任务编码。最终通过不同的预测头完成世界建模和动作价值预测两个任务。VQ-VAE 的训练使用了加权的 L1 重构损失、commitment 损失、LPIPS 感知损失。
世界建模依靠状态预测头 、奖励预测头 和终止预测头 来学习环境的动态转移函数、奖励函数等。为了统一损失函数类型为交叉熵损失,将环境奖励使用符号函数离散化为 3 种离散取值 {-1, 0, 1}。因此,世界建模的损失函数可以写为:
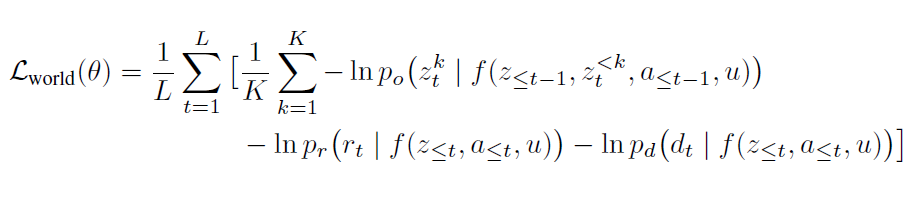
其中 f 表示 transformer 函数,u 是任务 ID,用来索引任务编码。
动作价值的学习依靠价值函数头 来完成,我们使用保守的分布式时序差分损失来训练:
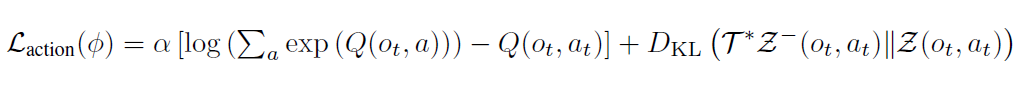
其中第一项是 CQL 的保守正则化项,通过惩罚 OOD 动作的价值来避免域外价值的过度优化。第二项使用 C51 的分布式时序差分替代了均方误差的时序差分损失,这在近期其他工作以及本文的消融实验中都证明了,分布式时序差分损失是实现 RL 缩放性的重要因素。
最终,我们通过两个损失函数的加权和来优化 JOWA 模型。由于两个任务共享了 transformer 骨干,因此 transformer 吸收了两个损失函数反传的梯度,形成了联合优化。
虽然前人工作观察到时序差分损失会导致大模型参数情况下的训练不稳定,但是对于 JOWA 而言,世界建模损失可视作一个正则项,来稳定价值函数的学习过程。并且将两种损失函数都统一成交叉熵损失,也能够更好地通过线性加权的方式控制不同任务对应的梯度大小,实现任务平衡的训练。
除了正则化的作用,预训练后的世界模型可以为智能体提供规划能力,并且通过规划或数据合成的方法实现样本高效的迁移。

规划算法
预训练的世界模型可以让智能体在决策时进行未来规划,从而弥补不准确的 Q 值估计造成的次优策略。首先,我们把在世界模型想象出的马尔可夫过程里找寻最优策略的问题建模成树搜索问题。此处省略假设以及推导过程,最终指引搜索的目标函数可表示为:
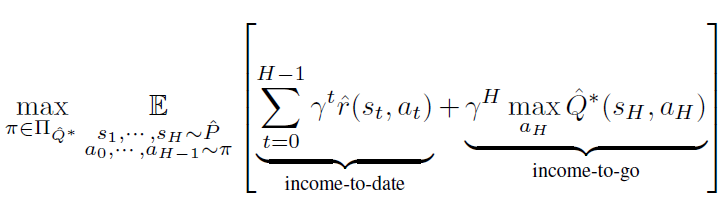
其中, 分别表示 JOWA 预训练后的奖励预测头、状态预测头和最优动作价值头。 表示受 限制的策略空间,其中的策略只能将状态映射到 top-K 值的动作集合中。
这个目标函数表示,我们可以在想象的马尔可夫过程中使用受限策略游走 H 步,最后收益最大的叶子节点与根节点之间的路径即为最优策略。本文证明了基于搜索的最优价值估计的误差上界如下定理所示,并基于此导出了在满足何种条件下,基于搜索的最优价值函数要比直接时序差分学习的最优价值更准确:

简单而言,当世界模型的预测误差(奖励预测误差与状态预测误差的加权和)比基于时序差分的价值估计误差更小时,基于搜索的价值估计会更准确。
我们使用 beam search 来实现该规划算法,在每个时间步只保留有最大收益的 K 个状态。当波束宽度 K=2 且规划视野 H=2 时,规划算法可以图示为:
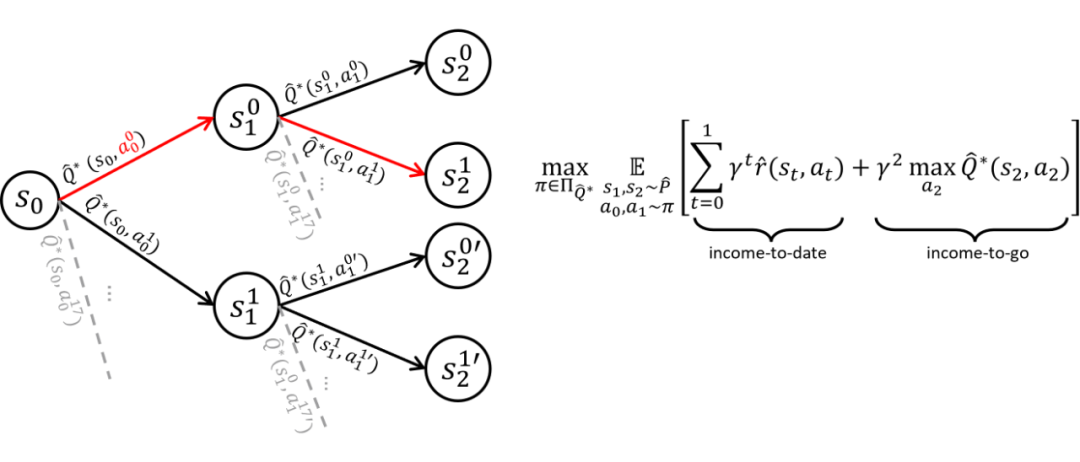

实验
缩放趋势:
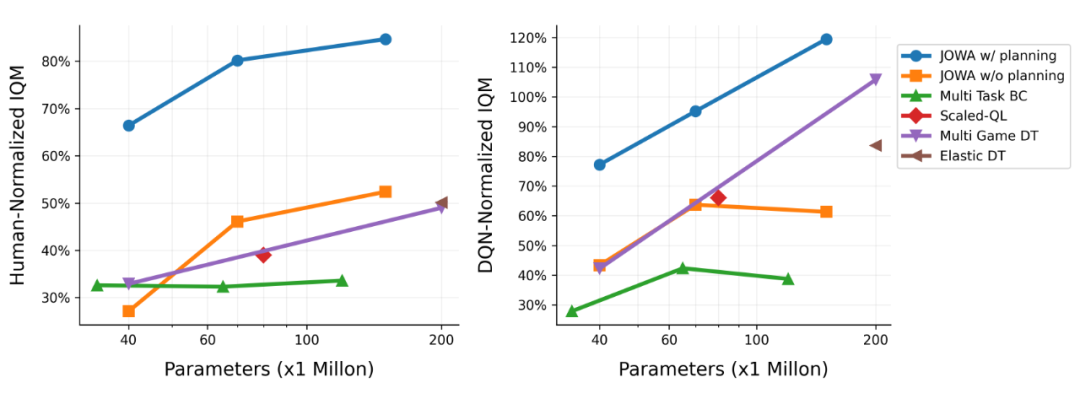
由于前人算法不完全开源,我们复现了四种基线算法:Multi-task BC、Multi-Game DT、Elastic DT 和 Scaled-QL。其中前三个基线代表了(条件)行为克隆类方法,最后一个基线和 JOWA 都代表了时序差分类算法。
上图画出了评价指标与模型参数大小之间的关系,可以观察到:
1. JOWA 可以很好地利用更大的模型参数,展现出了缩放性质;
2. 启用规划的 JOWA 算法显著超越了各基线算法,即使他们可能有更大的模型参数,或者在预训练时使用了数据增广;
3. JOWA 自身的对比发现,所提出的规划算法可以显著提升模型性能,并且修复偏离的缩放性。
Few-shot微调
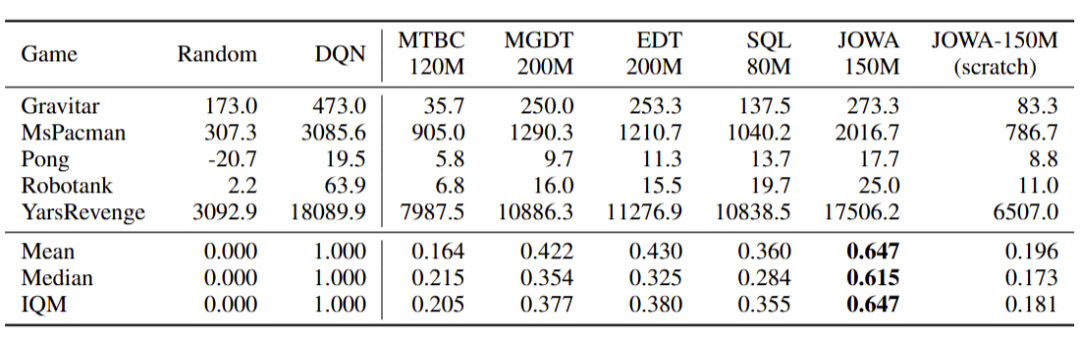
我们在 5 个预训练未使用的游戏环境中进行了少样本微调,每个新游戏只使用 5k 的专家级交互数据(在这些环境上等同于平均约 4 条轨迹)。
由于跨游戏环境意味着不同的状态转移过程、不同的奖励函数、不同的有效动作空间,因此这个任务非常具有挑战性。而预训练的 JOWA-150M 智能体表现出了最好的微调后性能,达到了 64.7% 的 DQN 水平,平均超越基线算法 34.7%。这表明联合优化后的 JOWA 智能体能够学会通用的表征和决策能力。
消融实验:
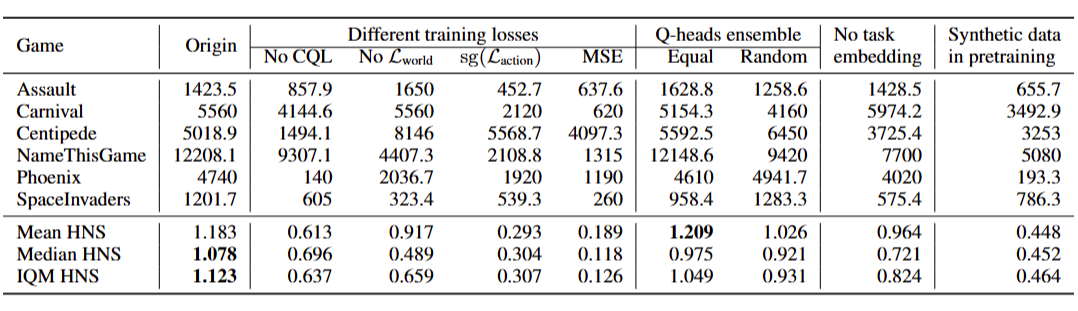
在消融实验中,我们分析了不同损失函数、价值头集成、任务编码和预训练时合成数据的作用。
对于损失函数,我们实验了:1)去掉 CQL 保守正则项;2)去掉世界建模损失,退化为训练无模型的价值函数;3)价值损失不反传给 transformer,退化为世界模型与价值函数独立训练;4)均方误差的时序差分损失。
对于价值头集成,我们探究了集成方法是使用等权重还是随机权重加权求和。消融实验的结论总结如下:
(1) 联合优化和分布式时序差分损失对 JOWA 至关重要;
(2) CQL 正则项、世界建模损失和任务编码能显著提升性能;
(3) 我们没有观察到价值头集成的显著收益,但这可能是由于集成数量不够多;
(4) 预训练时使用世界模型生成的数据会有害性能。
其中第四条结论比较有趣,因为前面实验已经证明预训练后使用世界模型进行规划可以显著提升性能,也就是可以产生更优的策略、合成更高质量的数据,但是预训练时使用合成数据却结论相反。
根据规划算法章节的定理,我们猜测:应该等预训练一定步数后,当世界模型比较准确时,再进行合成数据。但是由于在预训练中进行数据合成会拖慢训练速度 5 到 10 倍(导致约一个月的训练时间),因此我们没有再进行额外实验来验证猜想。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









