







©PaperWeekly 原创 · 作者 | 孙浩
单位 | 剑桥大学博士生
研究方向 | 强化学习、IRLxLLM

▲ version 2024.10.15
论文预览版本:
http://sites.google.com/view/rewardmodels
上周给论文加上了一个之前没来得及写的 theorem,现在基本完成了一个自己比较满意的版本,贴出来之前还会有一些流程要走,所以先在这里先写一篇文章。如果对论文原文有兴趣的话欢迎发邮件到 hs789@cam.ac.uk 联系我们。
本文会讨论以下内容:
1. Bradley-Terry Model 为什么可以被拿来做 Reward Modeling,其背后的依据,假设,逻辑是什么?
2. 做 Reward Modeling 这件事,真正重要的是什么?除了 Bradley-Terry Model,我们还有哪些选择?
3. 理解 Bradley-Terry 和 Reward Modeling 过后,再回过头看目前的实践,有哪些部分或许可以改进?

Part I: Rethinking the Bradley-Terry models in Alignment
1.1 从两种 BT model 讲起
在之前的文章中我梳理了 BT model 的起源。从上个世纪 50 年代开始,BT model 以及它的各种改进就被用于棋类和各种体育赛事的水平评估和胜率预测上。关于它最通俗直接的表述是,当一个能力为 的队伍 A 遇上了一个能力为 的队伍 B,那么这场比赛 A 赢得 B 的概率是 。
具体实践中,由于不同比赛的赛制,规则,随机性都不同,所以如果想用分数准确预测各个队伍的胜率,是需要用被标准化过的分数的,这里分数会被比赛中的随机性标准化——举例子来说,足球比赛的随机性很大,所以即使是弱队踢强队,也有赢的可能。
同样的还有牌类游戏的随机非完全信息博弈,在这些游戏中,能赢不一定代表水平高。相比之下,象棋,围棋这些完全信息的博弈,里面的随机性就小很多(更多是选手临场发挥的随机性,而没有比赛本身的随机状态转移)。
BT model 最直接的应用是,给定不同队伍的比赛历史信息,能不能给每个队伍打分,评估他们的实力水平,进而在未来的比赛中实现对这些队伍胜率的准确预测。我们把这种应用称为 parameter estimation ——每个队伍的分数是需要估计的 parameter。
在这种场景下,理论上来讲即使完全没有随机性,我们也需要大概 这么多次比较才能把这些队伍的顺序给排出来,考虑到随机性的存在,在之前的理论工作中,最好的结果是 Han et al. [1] 给出的至少要进行 这么多次比较之后才能有比较准确的估计。
我们这里举两个 LLM 里应用了 BT model 的例子:
首先是 LLM Chatbot Arena,也就是所谓的 LLM 天梯,在这个设定下,不同的 LLM 是运动员,每一局比赛中两个运动员参赛,由使用者评判出不同 LLM 给出 response 的好坏,从而判定这一句比赛的胜负。
在 LMSYS 的 arena 中,截至目前一共有超过 2,000,000+ 场比赛,来对 150+ 个 LLM 进行比较,平均而言,任意两个 LLM 都比较了 26,000+ 次。这里 N=150,26000 >>N(logN)^3 = ~1500。所以我们看到 LMSYS 能对每个 LLM 的评分给出 95% 置信区间。
另一方面,在通过 preference-based annotation 对 LLM 进行 alignment/RLHF 的时候,BT model 被拿来将 pairwise-preference annotation 转化为分数。
这里每一个 prompt-response pair 都是一个运动员(这里其实有一个小小的跳跃,最直接的想法是,同一个 prompt 的两个 response 是两个运动员,有很多对这样的运动员)。
当我们有 N 个 prompt 的时候,会有 2N 个 response,annotator 对这 2N 个 response 进行标记相当于产生了 N 场比赛的结果。这里问题就来了,N 场比赛,想给 2N 个运动员打分,N << 2N (log 2N)^3,这事靠谱吗?
事实上,这并不是 LLM Alignment 面对的问题,在体育赛事中,两个队伍或许没有进行过很多的比赛,但是如果双方交手,我们可以通过一些特征来进行比赛结果的预测,(e.g., 队员的平均身高,年龄,大赛经历,身价,平均海参进食量)。
这里的重点不再是 parameter(ability)estimation,而是 outcome prediction。这件事在 BT model 的历史上被大量研究过,文献中称为 Bradley-Terry regression。延续这一思路,我们的文章在 LLM alignment 这个特殊场景下,给出了使用 Siamese MLP 结构实现 BT regression 的收敛性证明。
1.2 Bradley-Terry背后的假设
当我们谈论 Preference 是一场比赛,并且尝试用 Bradley-Terry model 去刻画比赛结果的时候,我们假设了什么?
一年前我写的回答部分地回答了这个问题:不同的 response 是 player,preference 就是比赛的结果。但是一年前我没想清楚的部分是,这里比赛的随机性来自于哪里?
一种自洽的解释是当时提到的,如果我们认为每个运动员的“发挥”是他实力周围的一个 gaussian 分布,再假设这种 gaussian 对于不同运动员之间有相同的 variance,那么运动员的分数就可以被这个 variance 标准化。
我们进而可以得到一个 erf 版本(而不是 tanh)的(伪)BT model。为了得到 BT model,我们需要假设每个运动员的发挥是他实力周围的一个 gumbel,location = 实力。
即使如此,有一个细节依然需要想清楚,那就是这里的 variance / 比赛的随机性是哪来的——在之前的 seminal paper 中,这部分内容都被按下不表,我们这里给出一个完整的解释:
BT model 假设了不同的标注员有关于不同 response 确定性的 bias,这些 bias 是 Gumbel 分布(所以他们的差是 logistic 分布)。类似的,我们还可以假设这些 bias 符合 Gaussian 分布,那么差就也是 gaussian——这样我们就会得到 erf 的那个版本。
除此之外,我们还可以给出另一种角度的解释(受到一些认知心理学文献关于 cognitive bottleneck 讨论的启发)标注的正确与否(和真实的 reward 值排序相比正确与否),取决于两个 reward 之差的绝对值大小。
直观来讲,如果 response1 和 response2 的真实分数分别是 r1 和 r2,如果 r1 和 r2 非常接近,那么关于这两个 response 之间的 preference 进行的标记就有更大概率被标错,或者它就和随机标注更加接近。
同时,不同标注员有不同的区分这些优劣的能力,理想情况下,一个完美标注员可以区分任意小的真实 reward 差值,那么这个标注员总可以以 100% 的正确率按照 reward 的大小进行 preference 标注。
另一个极端是,如果标注员特别差,那么即使 reward 之间的差值很大,他也没法正确区分优劣,那么这个标注员标出的数据就是随机的(0.5)。
在最普适的版本中,我们用一个值域为 [0.5,1] 的函数 作为刻画标注质量的函数,下面的 Equation 15 中,如果 ,我们就事实上回到了 BT model —— equation 15 是囊括了 BT model 在内的一个对 annotation 更广义的刻画。


Part II: Rethinking Reward Modeling Objective——RM 的最终目标是进行优化
2.1 Order Consistency的概念
前面我们讲了 BT model 背后的假设,以及用 BT model 将 preference data 转换成 score 时候的逻辑——由于我们是在embedding space上进行的 regression,而 embedding space 中不同的 prompt-response pair 之间的排序关系可以在一定程度上 generalize 到其他的 prmopt-response pairs,因此我们不需要像 classical BT model 那样用大量样本估计 parameter,而是可以用相对少量的 annotation 对新的 prompt-response pair 做 prediction。
这里我们可以再次对比 reward modeling 和传统体育赛事用 BT regression 时候的差别,在体育赛事中,我们会关心每一场比赛的胜率(至少买彩票的同学们会关心),这种情况下,知道每个队伍精确的分数预测就变得很重要。
但是在 reward modeling 的使用场景下,我们其实并不关心不同的 prompt-response pair 哪个胜出的概率是多少,我们更关心的是二者的序关系,在使用 reward model 的时候(例如 inference-time optimization 的过程中),我们会拿到一个 prompt 的多个 response,我们不需要准确预测这些 response 相比其他 response 胜出的精确概率,而是只要找到那个最好的 response 即可。
一个有趣的 callback 是最近恰好在读《算法之美》这本书,书里第二章就提到现在的体育赛事很多时候只有冠军是精确的冠军,而第二名并不一定是真正的第二名。
从这个角度来看,我们用 BT model 来进行 reward modeling 似乎是有点过于追求细节了。重新审视数据,我们提出了一个更加通用的 high-level 优化目标:Order-Consistency——保序性。形式上,我们给出如下定义:

给定标注数据集的时候,我们能做的所有就是复现数据集中的(不完美)标注。我们用 来表示这个 ordering model / 序模型,那么只要我们优化 优化得足够好,那么这个 就一定不会离真实的标注太远。
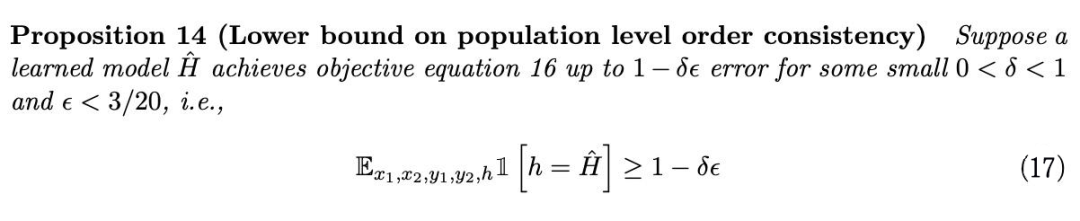
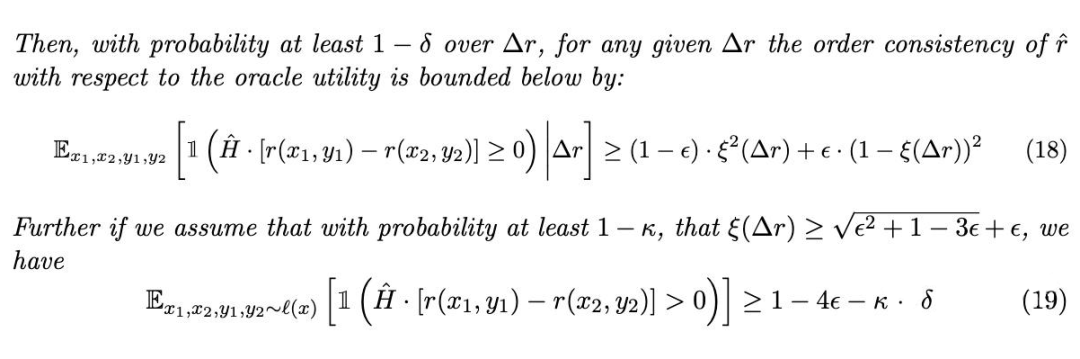
2.2 BT Model与Order Consistency
显然,BT model 是一个优化 Order Consistency 的 model,它显式地把 写成两个 reward estimation 之差的形式,这个形式本身具有反对称性——反转两个 reward estimator 的位置,序估计会反号。
2.3 Classification与Order Consistency
除此之外,我们指出,直接对被标记为正/负的样本进行二分类也是一种对 Order Consistency 的优化,它优化的是 Order Consistency 的上界:也即同时要求对 prompt-response 正样本的预测大于 0,负样本的预测小于 0,这里没有了显示的反对称性要求,我们希望 Classifier 可以从数据中学到这一性质。
理论上,BT mode 优化的是 prompt-response pair 中其中一个胜利的概率。classification model 优化的是正样本是一个“好”样本的概率,这种直接的分类其实移除了负样本的影响,是这个样本在比较中胜利的边缘概率。
文章中,我们给出了如下的结果——BT reward 和 classification reward 之间可以被一个与i无关的常数连接,classification reward 加上一个常数可以 upper-bound 住 BT reward。


Part III: Rethinking Global Reward Approximator——应当如何标注数据
在前面的分析中,我们可以发现,所有的推导其实都不要求 prompt-response 来自于同一个 prompt。
这是因为在 BT regression 的假设下,我们的比较是在 embedding space 进行的,而 embedding space 是 prompt-response 二者联合的 embedding,直觉上来说,对 embedding space 不同数据点进行 order-consistency learning 其实就是在给不同的数据点打分,这种分数是全局通用的,而非针对某一些 prompt 特定的。
事实上,不同的 prompt-response 之间可以进行比较,这是可以做 reward modeling 的隐含先决条件——这种比较的可能性允许了我们学到可以用于预测任意 prompt-response 分数的 reward model。我们学的 reward 是 universal function approximator(此处致敬一下 multi goal RL 里的 UVFA)。
至于为什么我们需要不同 prompt-response 之间进行比较,我们可以拿体育赛事进行一个很好的类比:考虑我们有很多少年足球运动员生活在不同的城市,他们在自己的城市踢比赛,可以大概得到他们在城市内的排名,如果不进行不同城市的交叉比赛,我们很难知道这些运动员相比于全局水平来说究竟如何,或者说我们获得的给运动员打分的模型会比较局限在当地。
如果我们要预测一个没在数据集中的城市里,一名新的运动员的表现,我们更希望获得更加多样化的比赛数据,最好不仅有城市内的比赛,也有城市间的比赛。
在经典的分类问题中,选取什么样的数据进行标注有很强的关联:我们不能只选那些很明显是正样本或者负样本的数据,不然训练任务太简单,遇到稍微复杂一点的例子学到的模型效果就会变差,同样我们也不能只要那些分类边界上的例子,如果只有这些样本,又很容易过拟合——对于 reward model 来说这个问题就是 reward hacking。
在先前的工作中,RPO [3] 已经提出过考虑不同 prompt 的 response 之间进行比较。
举例来说,如果我们考虑 helpful chat bot 这个目标的时候,我们可以通过对比 LLM 给不同 prompt 的回复,来标注它回答某一些问题是不是比另一些问题更加 helpful——这里更加 helpful 当然有可能是因为这个 prompt “简单”,更容易给出有帮助的答案,但更重要的是,在这种 cross-prompt 的比较中,我们希望能够学到可以泛化的关于 “helpful response” 的描述。
另一方面,cross-prompt 的比较还能带来更高的标注质量,直观来看,这是因为随机选取两个 prompt 和它们对应的两个 prompt 进行比较,比固定 prompt,生成两个 response 进行比较会有更大的差异性,更容易比较出哪个更好,我们有以下结果:

更严格意义上的证明需要考虑标注的正确率,要证明期望上来说,标注的质量会因为随机选取 prompt 而提升,我们证明了下述结果:(这个证明我上周写了 6 页,然后合作者用 1 页写了个推广版 )。

因此,实验上我们很好奇,如果可以进行不同 prompt 之间的 annotation,是否可以更有利于 reward modeling。我们在实验中对这一点进行了详尽的探索。

Part IV: Experiments——相当好用的Tree-based Models
这部分结果会等文章 arxiv 过后再进行更新。我们主要进行了三个方面的实验:
(所有实验我们都进行了 5 次重复,所有 embedding,训练代码,模型,我们实验里生成的回复,训练和测试数据都会开源)。
复现我们的代码,每个实验在 128core 的 CPU 机器上只需要不到十分钟(我们一共进行了超过 1.2w 组实验,交叉验证了各种情况下的性能表现)
1. 我们探索了 BT Reward Model 和 Classification Reward Model 在用 embedding 作为输入的时候的性能差异。
我们发现:在我们进行的大多数实验中,Classification Reward Model 可以取的不输于 BT Reward Model 的性能,但是 Classification Reward Model 比 BT Reward Model 灵活很多,可以用任意已有的 classifier 来实现,可以用 MLP,也可以用 lightgbm / xgboost 这些 tree-based model。
2. 我们研究了不同 annotation 质量和数量下,不同 reward modeling 方法的性能变化。
我们发现:随着标注质量的降低,或者数据数量的减少,BT Reward Model 不如 Classification Reward Model。
3. 我们对比了 cross-prompt 进行标注和单一 prompt 多个 response 进行标注的数据源进行 reward modeling 的性能,并且压力测试了 cross-prompt,展示了在怎样的条件下 cross-prompt 能带来更大的性能提升。
我们发现:cross-prompt 在 response 的 diversity 较低的情况下可以带来大幅度的性能提升。而在实际的 RLHF workflow 中(现在一般默认进行 online 因为效果显著更好)我们往往只能随机生成两个 response 然后给标注员去标,这种情况下 cross-prompt annotation 可以比较显著地提升 reward modeling 的效果。

Part V: 结尾
如果要一句话概括我们文章的重点:“Reward Modeling 中最重要的是 Order Consistency,除了 BT Model,用 classification 训练 RM 也可以达成这个目标”。
如果再加一句话:“在做 Annotation 的时候,通过 cross-prompt 的比较,可以提升整体的标注质量”。
再加一句话:“欢迎大家多尝试 embedding-based classifier RM,它效果好,稳定,可以和各种分类器兼容(比如 LGB/XGB),并且可以轻松(轻量化)ensemble 来进一步提升 RM 的效果”。
最后,这一切的前提,包括 Reward Model 存在的前提,是我们能够有一个很好的 embedding space。是 embedding space 允许了我们在极其稀疏的对比中拟合 reward model。这方面大家可以看一下 @yr15 最近在 NeurIPS'24 关于 Reward Model embedding/representation learning 的工作 [2]。
写这篇工作的过程中收获了很多,过程中重复造了很多轮子,也有过很多的顿悟时刻,更重要的是,在写这一篇工作的过程中一直处在一种探索和求解的状态里,一点点将几个月之前的疑惑解开。
用实验去启发可能的解释,找到合适的数学语言去描述观察到的现象,不断探索更合理和宽松的假设,然后在这些条件下给出证明。在信息爆炸的时代,能有机会用原教旨主义的科学研究范式完成一篇工作,本身已是一件幸事。
希望这些思路和我们的发现在大家的研究和工程中可以有帮助!也欢迎找我们交流讨论。
附录
——在过去一年里围绕 IRL x LLM(Reward Modeling)开展的工作:
[1] Prompt-OIRL:用 Offline Inverse RL 做 prompt 的 optimization,廉价,高效,五分钟训练出来的 reward model 能让math能力大幅提升。https://openreview.net/forum?id=N6o0ZtPzTg
[2] DenseReward:在 RLHF 里用 attention 给 token 分配 reward,尝试解决 RLHF 中的 credit assignment 问题。https://arxiv.org/pdf/2402.00782
[3] RATP:将 LLM 的使用放在 MDP 的框架里描述,给出的 thought process 囊括了 CoT,ToT,Graph-of-Thought 等一众可以用于提升 reasoning 能力的工作。这种基于 dense reward/progress feedback 做搜索的思想也是当前 Inference-time Optimization / Searching based generation(例如 o1 model)的技术核心。https://arxiv.org/pdf/2402.07812
[4] InverseRLignment:用 Inverse RL 的视角来理解 SFT,指出从 preference-based data 进行 alignment 的困难,并同时提出了用于 Alignment from Demonstration 的方案。https://arxiv.org/abs/2405.15624(有一篇相同主题比我们晚了半年挂出来的论文中了 NeurIPS‘24,早在三月的时候他们作者团队就要了我们的论文说可以给建议,发了论文给他们之后改口说涉秘不能聊技术建议,最后我们这篇投稿rebuttal过后全正分,所有 reviewer 满意的情况下被从头到尾沉默的 AC 用莫名其妙的理由给拒了)
[5] DataCOPE:Reward Modeling 的本质是 Off-policy evaluation(OPE),OPE 并不一定数据越多越好,重要的是质量而非数量——重要的是数据和待评估策略之间的匹配程度。Less can be more in reward modeling!https://openreview.net/pdf?id=wg5y4AK6l7
[6] 最近贴出来的一篇 workshop position paper,指出 Reward Model 是进行 inference-time optimization 的唯一选择和必由之路。(从 RL 的角度看,LLM 是 online-dynamics + offline Reward Model,所以如何得到更加精准的 reward model 是 LLM post train / efficient and effective deployment 里很核心的问题)https://openreview.net/pdf?id=qpop1gQvVQ

参考文献
[1] https://projecteuclid.org/journals/annals-of-applied-probability/volume-30/issue-5/Asymptotic-theory-of-sparse-BradleyTerry-model/10.1214/20-AAP1564.full
[2] Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
[3] Yin, Yueqin, et al. "Relative preference optimization: Enhancing llm alignment through contrasting responses across identical and diverse prompts." arXiv preprint arXiv:2402.10958 (2024).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









