







通过大语言模型来生成科学创意,是目前科技界的热门话题。如果大语言模型能够自动生成可行可靠的科学创意,那将极大推动人类科技的进步。但科学研究的高时效性和逻辑性要求我们不能简单地依赖大语言模型生成的创意,因为它们可能过时或逻辑不通。
目前,主流的方法是通过检索增强生成(RAG)技术 [1],检索最新的相关文献,将它们的文章信息作为外部知识拼接给大语言模型。
然而,这种方法可能导致大语言模型陷入混乱,因为检索到的内容五花八门,方向各异,很难让大语言模型把握住正确的研究方向,就像我们人类平时阅读文献,大部分的文献可能并不会对你的研究产生帮助,反而会影响我们的思考,我们更倾向于整理出一条清晰的研究脉络并顺着继续研究,从而得到新颖的创意。
那么,能否通过一种合理的文献组织方式来让大语言模型像人类一样进行思考并提出科学创意呢?
浙江大学和阿里巴巴达摩院的研究者们提出了一项名为创意链(Chain of Ideas,CoI)的创新研究。他们将文献组织成链的形式,引导模型像人类一样进行研究思考。基于 CoI,研究者们构建了一个智能体——CoI Agent。这个智能体能够通过输入一个文章主题或一篇论文,自动生成科学创意并设计对应实验。
为了评估生成科学创意的质量,研究人员提出了一种新的评估体系——创意竞技场(Idea Arena)。这个体系通过让各个生成创意在一个竞技场里进行两两竞争比较,根据胜负关系计算 ELO 分数。
实验结果显示,CoI Agent 生成的科学创意与对应实验,无论是人工评估还是大语言模型评估,都远远超过了其他方法,并接近真实人类论文的水平。这揭示了大语言模型在科学研究中的巨大发展潜力,为未来的研究探究了新的可能。
目前项目论文、代码、Demo 均已经上线,引起了研究者较大的关注以及好评 [2]。CoI 的 Demo 现在每天生成几百个研究 Ideas,可能未来会有基于 CoI 生成 Idea 的论文发表,让我们拭目以待。




论文标题:
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
论文链接:
https://arxiv.org/abs/2410.13185
Github链接:
https://github.com/DAMO-NLP-SG/CoI-Agent
Demo链接:
https://huggingface.co/spaces/DAMO-NLP-SG/CoI_Agent

序言
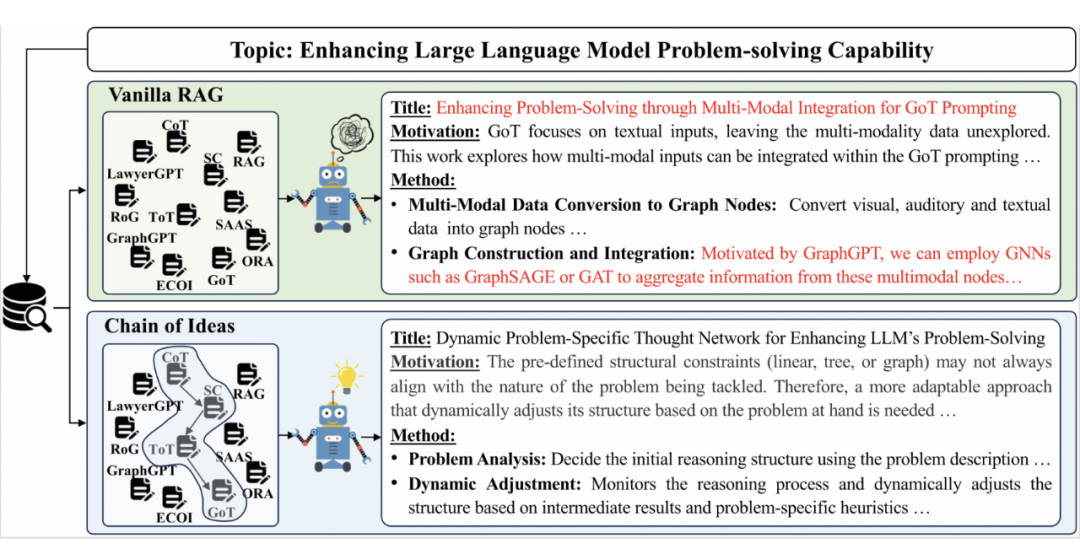
▲ 图1. CoI与传统方法的区别
如图 1 所示,传统的方法,通常是围绕一个研究主题,检索大量相关文献,并将这些文献的知识作为提示词(Prompt)输入到大型语言模型中。
然而,这种方法存在一个显著的问题:尽管这些文献都围绕着同一主题,但它们的内容往往杂乱无章,就像是在分叉路口给模型指了多个方向,导致模型难以判断哪条路是正确的,也不清楚如何深入研究。这不仅容易让研究浅尝辄止,还可能使模型陷入混乱,停滞不前。
为了克服这一挑战,研究者们提出了一种新的知识注入方式——创意链(CoI)。CoI 的核心思想是更有效地组织外部知识,使大型语言模型能够模仿人类的思考方式。通过这种方式,模型不仅能够理解文献的表面信息,还能深入挖掘其背后的逻辑和联系,从而更准确地指导研究的方向。

具体方法
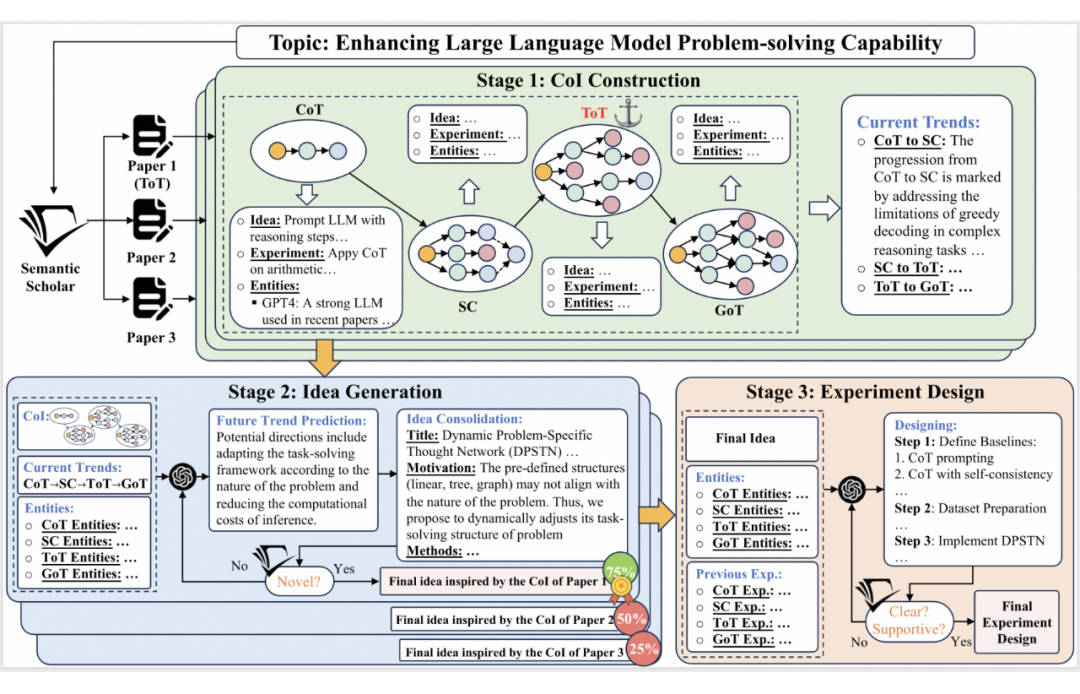
▲ 图2. CoI 的主要原理
具体过程如图 2 所示,从特定研究主题出发,我们检索 n 篇相关文献,将它们分别作为 n 条创意链的锚点。接着,我们向前追溯引用这些文献的文章,精选出与主题最相关、与原论文直接关联的文献,作为链的下一个节点。这个过程不断重复,直到无法找到更多相关文献。
同样,我们也向后追溯被该文章引用的文献,直到文献链达到合理长度。通过这种方式,我们构建了一条条论文链,每一条都是对特定研究主题的深入剖析。利用大型语言模型,我们从这些链中提取关键思想,形成了 CoI。
研究者们认为,CoI 反映了人类研究过程中的清晰脉络,它帮助语言模型分析论文间的递进关系,预测未来的研究方向,并最终提出创新的创意。这个过程自然而直观,就像告诉模型前三个数字是 1,2,3,然后预测第四个数字一样。
这种方法极大地降低了大型语言模型在处理复杂文献时的困难。通过比较 n 条链生成的 n 个创意,我们选择胜率最高的作为最终创意,以减少低质量链的影响。
研究者们进一步指导大型语言模型,根据提出的创意和过去的实验,设计新的实验。由于创意基于 CoI 生成,理想情况下,它们是过去方法的延伸,可以复用旧的实验设计,包括基线和测试指标,有效避免了模型在设计实验时的幻觉问题。
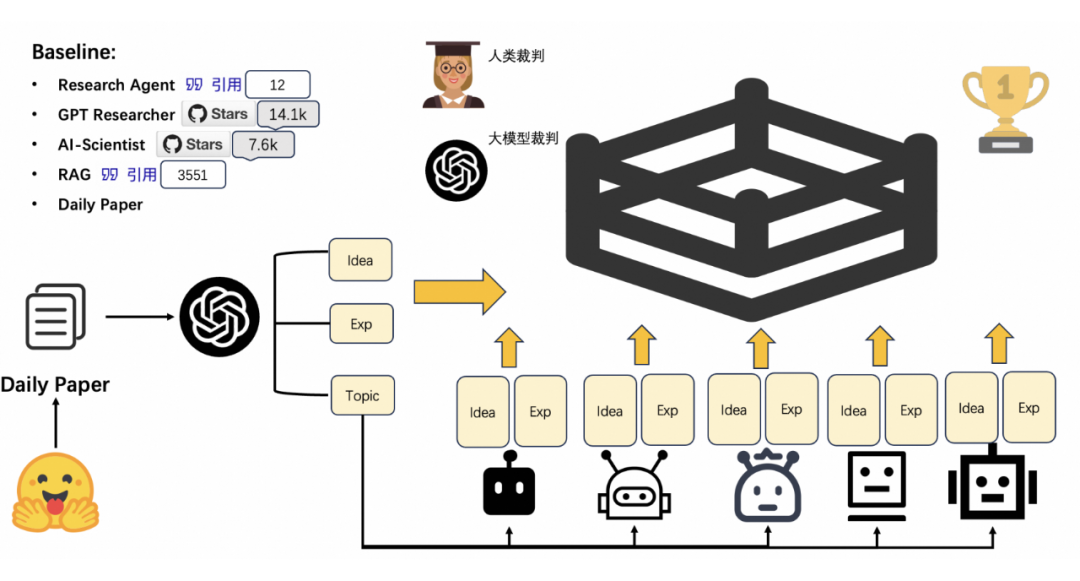
▲ 图3. Idea Arena
为了验证创新创意的质量,研究人员开发了一种新颖的科学创意评估工具——Idea Arena,具体如图 3 所示。
过去研究者们常常使用大语言模型生成一个 Likert 量表来评估创意的质量 [3,4]。然而,由于科学创意是一个开放性的问题,这导致了在自动评分过程中不存在一个明确的、普遍认可的黄金标准作为参考。这使得模型的评价标准无法和人类的评价标准对齐 [5]。
为了避免这一问题,研究人员采用了一种类似竞技场的评测方法。他们让不同方法针对多个主题生成创意,并在对应主题下进行两两对决。最后通过胜负关系来计算 ELO 分数。
这种竞技场评测方式将创意的评价从直接评分转换为两两比较,降低了大语言模型评测时对黄金标准的依赖,从而能得出更精准的评价结果 [6]。为了比较机器生成的创意和真实人类产生的创意,研究人员还将现实世界中的学术论文纳入了竞技场进行比较。

实验结果
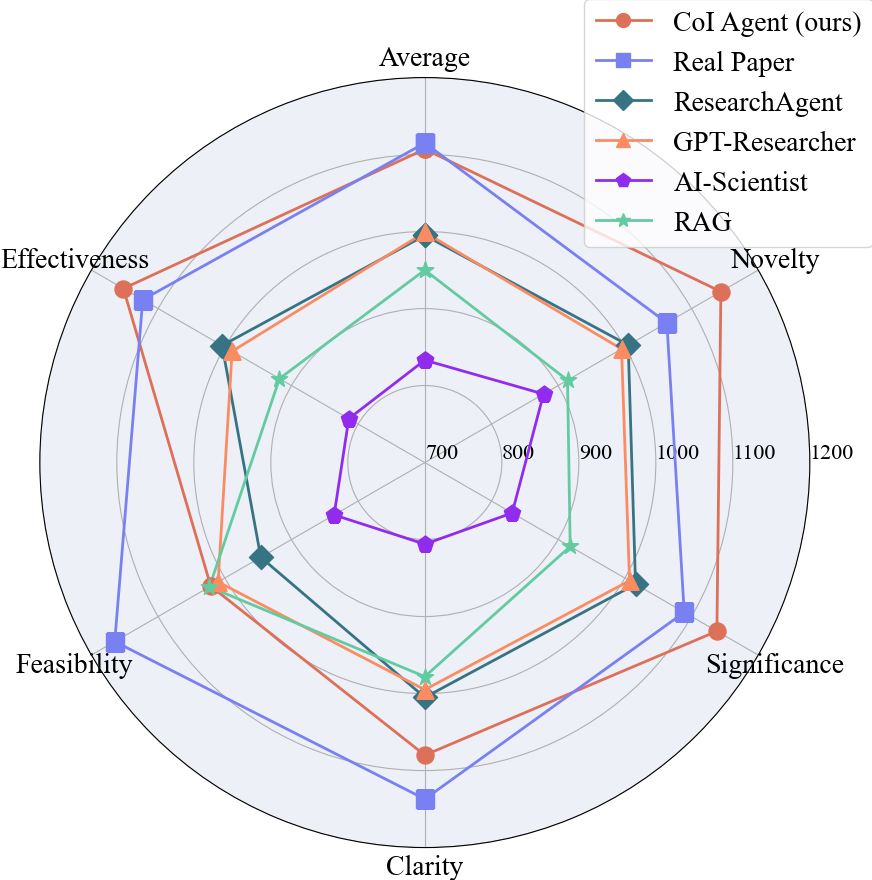
图4.大语言模型评估结果
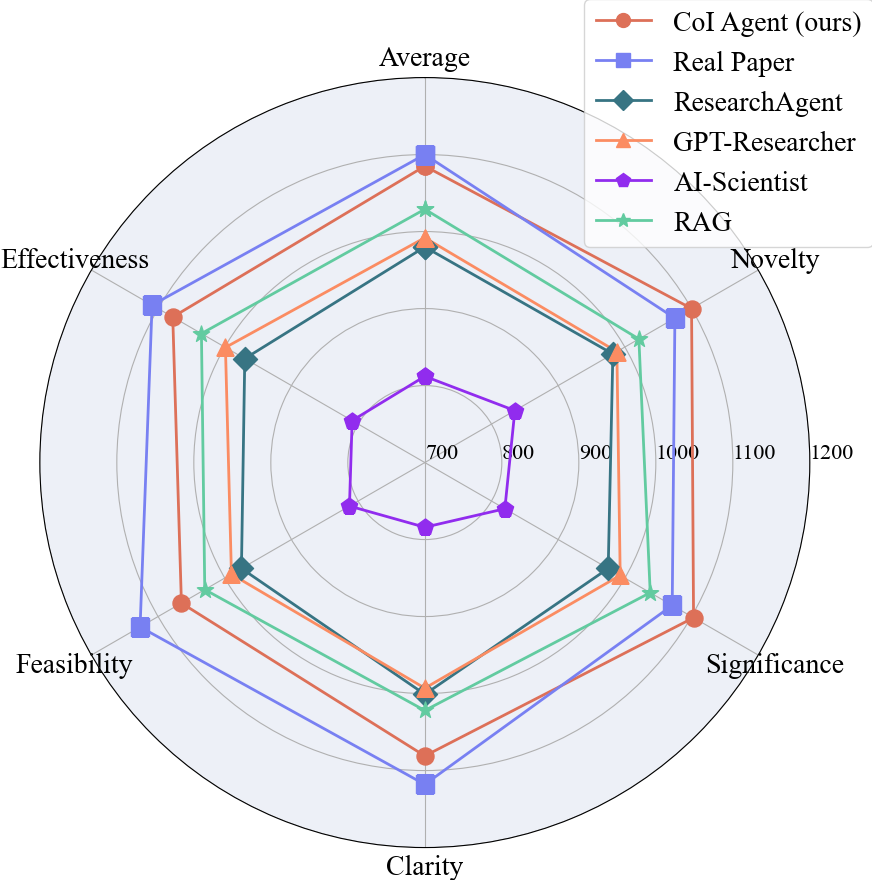
图5.人工评估结果
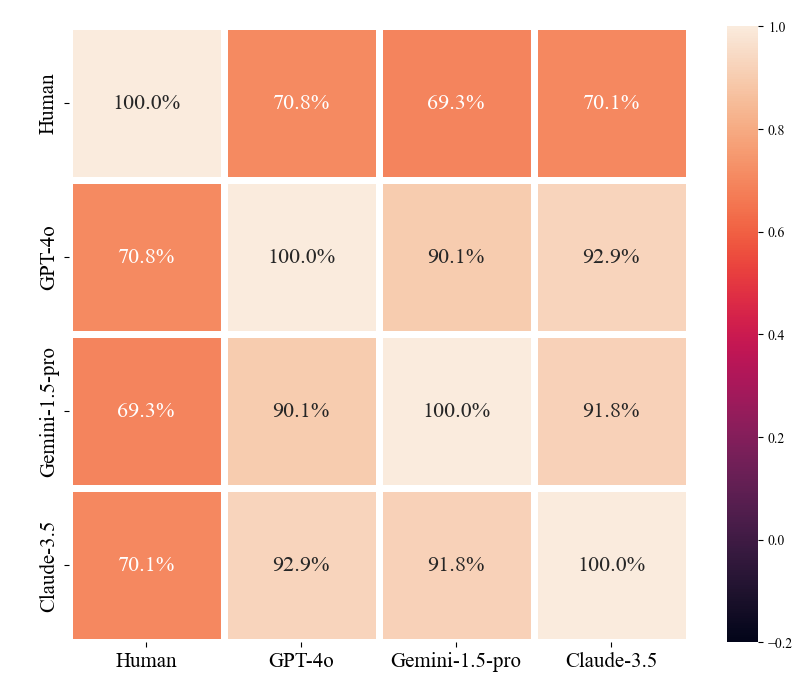
▲ 图6.一致性分析
3.1 创意层面结果
首先,研究者们在一致性方面进行了测试,使用了 Claude-3.5、Gemini-1.5-pro 和 GPT-4o 三种大语言模型,具体如图 6 所示。他们发现,当这些模型作为裁判时,它们的一致性超过了 90%。
这表明,大语言模型在判断科学创意时具有极高的一致性。而与人类的判断进行比较时,大语言模型与人类的评价一致率也达到了约 70%。这进一步验证了大语言模型作为裁判时的公正性和一致性。
最后,综合人类专家和大型语言模型的评估结果,研究者们发现 CoI Agent 在多个维度上都比其他方法有显著提升,其表现已经接近真实人类论文的水平。特别是在新颖性和重要性这两个方面,CoI Agent 甚至已经稳定超越了现实世界中的论文。
尽管在可行性方面还有所欠缺,这主要是因为真实论文必须经过实验验证才能发表,而生成的创意尚未经过这样的检验。因此,其可行性相对较低是可以理解的。然而,这样的进步仍然展示了大型语言模型的潜力,它们确实有能力构思出真正新颖的创意。
3.2 实验设计层面结果
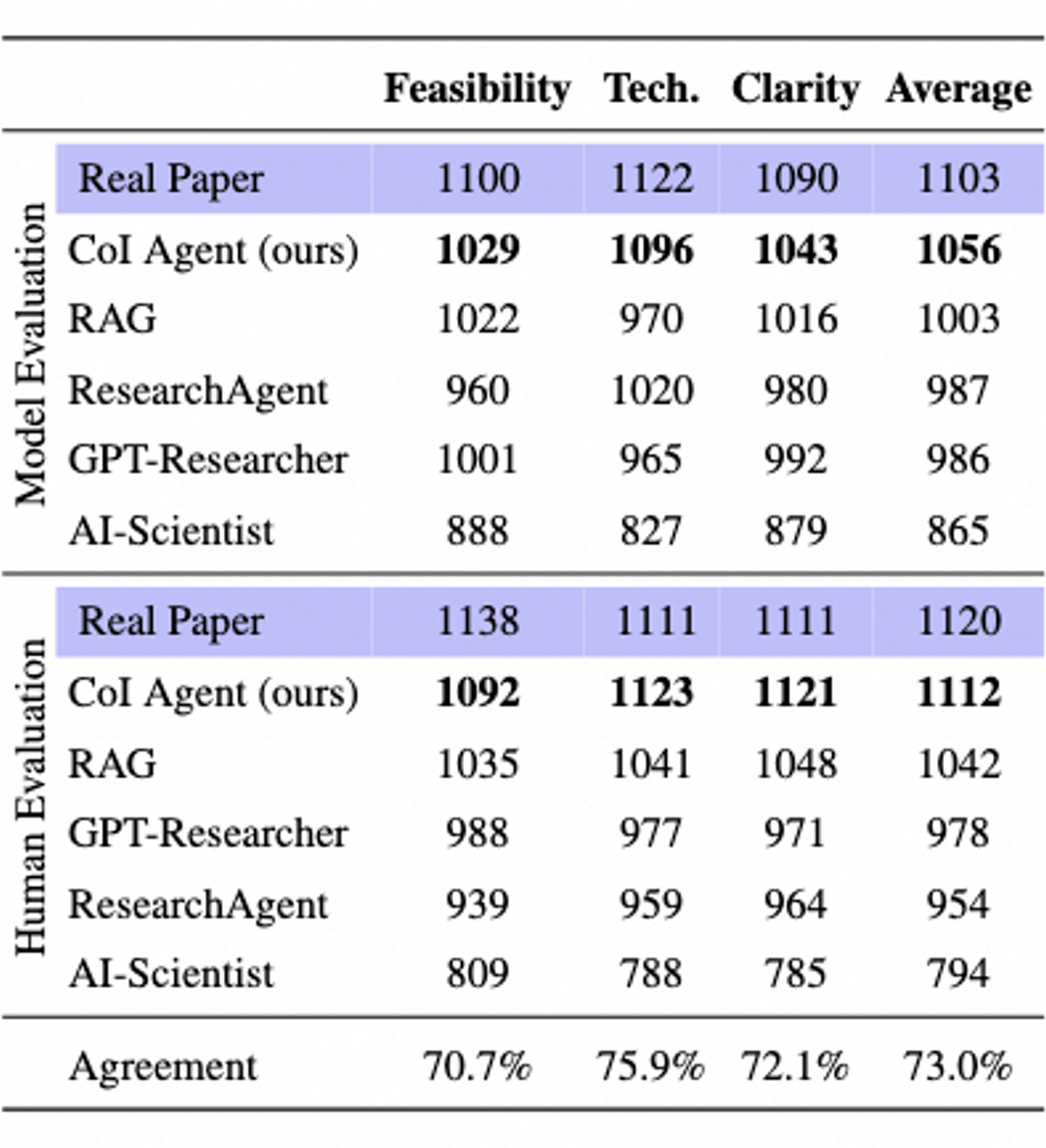
▲ 图7.实验设计评估结果
在实验层面,CoI Agent 同样表现出色,与其他方法相比遥遥领先,并且在专家的评估中接近了真实人类论文的水平。这验证了 CoI Agent 的生成质量,并证明了这种创意链构造方式的合理性。
3.3 消融实验结果
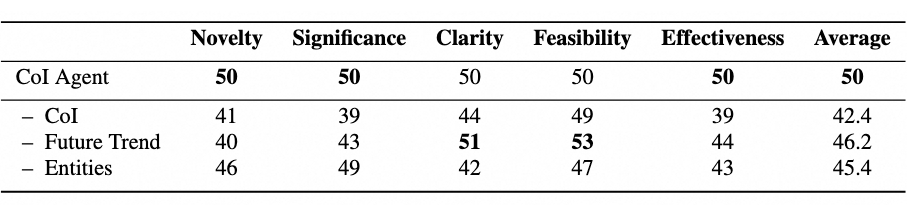
▲ 图8. 消融实验结果
研究人员还对实验方法中的各个组件进行了消融实验。结果如图 8 显示,每个组件对生成质量都有影响,尤其是 CoI。当研究人员简单地将 CoI 替换为 RAG,而保持其他部分不变时,生成的创意在新颖性、重要性和有效性这三个指标上都出现了明显的下降,这说明了 CoI 这种文献组织方式的有效性。
去除未来趋势预测会降低新颖性,因为大型语言模型缺乏对潜在前瞻性创意的洞察。最后,省略实体信息会降低清晰度和有效性,因为这样生成的创意会更加抽象,缺乏特定概念的支持。这突出了实体信息在提升创意的清晰性和实际相关性方面的价值。
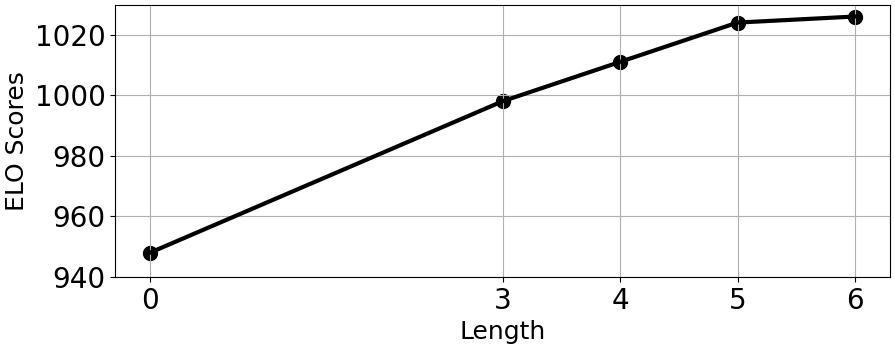
图9.创意链长度分析
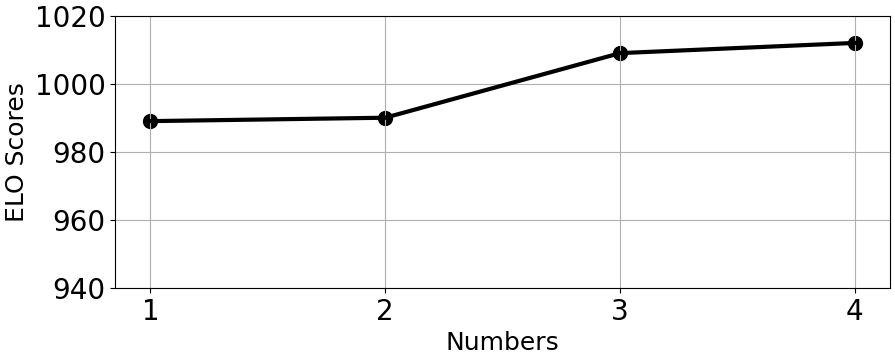
图10.创意链数量分析
为了深入探究创意链的各个变量对生成质量的影响,研究人员还对链的长度和数量进行了分析实验,实验结果如图 9,图 10 所示。
为了更好地探究链的长度的影响,研究人员将 CoI 替换为 RAG,检索 5 篇相关文献作为链长度为 0 的特殊情况(其他部分与原方法一致)。
实验结果表明,链的长度与生成创意的质量有明显的正相关关系。这说明较长的 CoI 能够提供更可靠和全面的洞察,反映当前研究领域内的发展趋势,从而使大型语言模型能够更好地把握未来的发展趋势。当长度达到 5 之后,生成的创意质量开始趋于平稳。这一饱和点表明,这个长度足以捕捉相关趋势,而额外的文献提供的帮助不再明显。
在链的数量方面,直觉上,这类似于多次采样,优中选优,因此一般来说,增加分支数量与创意质量会表现出正相关。然而,不同分支数量之间的 ELO 评分差异较小。这一现象可能归因于生成多个链主要有助于降低任何单一CoI 表现不佳的影响。幸运的是,这种低质量的 CoI 是比较少见的。

生成样例

▲ 图11. 生成样例
图 11 展示了一个由 CoI Agent 生成的创意示例。我们可以看到,CoI Agent 收集了从 2021 年到 2024 年,与应用大语言模型进行科学研究相关的 5 篇递进性论文,并将它们组成了一条发展路径。
通过分析每篇论文的研究趋势,它认为当前应该解决的问题是创意生成的多样性和新颖性。因此,引入了进化算法,并利用选择、交叉、变异和迭代这四个步骤来解决这些问题。可以看到,这个推理过程非常自然,不仅仅是简单地融合过去的文献,进行方法的拼接,而是真正提出了针对痛点的解决方案。

总结
本文介绍了 CoI Agent,这是一个旨在增强大型语言模型生成研究创意能力的框架。CoI Agent 通过将创意组织为链条结构,提供了一种有前景且简明的解决方案,有效地反映了特定研究领域内的渐进发展。它帮助大语言模型理解当前的研究进展,从而增强它们的创意能力。
然而,正如研究者们所观察到的,生成的创意虽然在创新性上能力突出,但通常在可行性方面存在不足,这与目前的最新研究一致 [7]。这是因为这些创意并没有经过实际的实验验证。如果能够让智能体自主进行实验,并根据实验结果来完善创意和实验设计,那么我们就能实现一个完整的科研循环。
这样的循环是实现自动化科研创新的关键。这也是本文研究者们希望在未来继续探索和深入研究的方向。通过这样的方法,我们不仅能够生成创新的创意,还能确保这些创意在实践中的可行性,从而推动科研的自动化和创新。

参考文献
[1] Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
[2]https://www.linkedin.com/feed/update/urn:li:activity:7252935332797583360/
[3] Baek J, Jauhar S K, Cucerzan S, et al. Researchagent: Iterative research idea generation over scientific literature with large language models[J]. arXiv preprint arXiv:2404.07738, 2024.
[4] Lu C, Lu C, Lange R T, et al. The ai scientist: Towards fully automated open-ended scientific discovery[J]. arXiv preprint arXiv:2408.06292, 2024.
[5] Zheng L, Chiang W L, Sheng Y, et al. Judging llm-as-a-judge with mt-bench and chatbot arena[J]. Advances in Neural Information Processing Systems, 2023, 36: 46595-46623.
[6]Zhao, Ruochen, et al. 'Auto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions.'arXiv preprint arXiv:2405.20267 (2024).
[7]Si, Chenglei, Diyi Yang, and Tatsunori Hashimoto. 'Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers.'arXiv preprint arXiv:2409.04109 (2024).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









