








©PaperWeekly 原创 · 作者 | TMLR Group
单位 | 香港浸会大学
在快速发展的机器学习领域,深度神经网络彻底改变了我们从数据中进行学习的方式,并在各个领域取得了显著的进步。然而,随着这些模型对私人数据的依赖,隐私泄露的风险日益突出。
最近,一种新的隐私攻击方式——模型反演攻击(Model Inversion Attack, MIA)引起了广泛关注。MIA 利用训练好的模型来提取其训练数据中的敏感信息,揭露了神经网络中的隐私风险;MIA 已在多个领域证明了有效性,包括图像、文本和图数据领域。
尽管 MIA 的研究影响显著,但目前仍然缺少系统性的研究,使得这一关键领域的诸多进展没有得到清晰的归纳和梳理。为此,在我们最新的综述研究中,我们详细地探讨了 MIA 这一研究问题,由问题定义出发,我们总结了不同数据领域的具体攻击方法及应用实例,整理了应对性防御策略,及常用的数据集和评估方法。
在本综述中,我们不仅对当前研究成果进行梳理,还提出了未来发展方向的深度思考,旨在为相关研究者提供清晰的综述分析,并以此激发更多未来研究的探索和创新。

论文标题:
Model Inversion Attacks: A Survey of Approaches and Countermeasures
论文地址:
https://arxiv.org/abs/2411.10023
Survey Repo:
https://github.com/AndrewZhou924/Awesome-model-inversion-attack

基本概要
MIA 的基本设定如图 1 所示。在 MIA 中,攻击者通常会使用经过训练的模型来提取该模型的训练信息。具体而言,MIA 会使用已知输入反复查询模型,并观察其输出以了解模型的行为方式。
通过多次执行此操作,攻击者可以收集到用于构建模型的训练数据的详细信息并从模型的输出中抽取敏感数据信息。典型的高风险应用有人脸识别与医学诊断,在这之中 MIA 能够抽取并恢复敏感的个人私有信息,对用户或患者的隐私造成巨大的威胁。
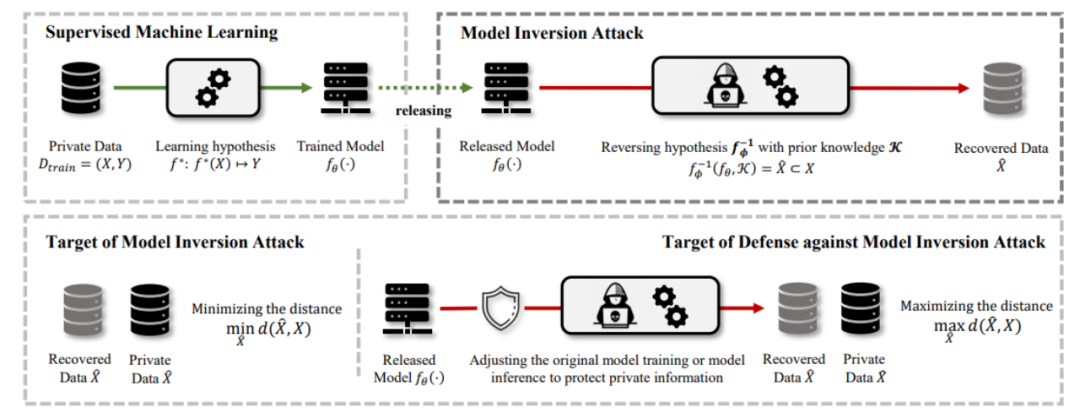 ▲ 图1. Model Inversion Attack的问题设定和基本框架
▲ 图1. Model Inversion Attack的问题设定和基本框架
尽管具体的攻击和防御方法取得了一定的发展,但考虑到 MIA 中对于恢复数据的核心关键问题,数据领域,目前还缺乏对这类隐私攻击与保护方法的系统分类研究,缺乏对某些方法有效或是失败原因的解释及优缺点分类。
为此,我们在这项工作中首次全面地调研了 MIA,对其在图像,文本,和图数据领域的攻击与防御方法进行了细致的讨论,具体的文章结构如图 2。
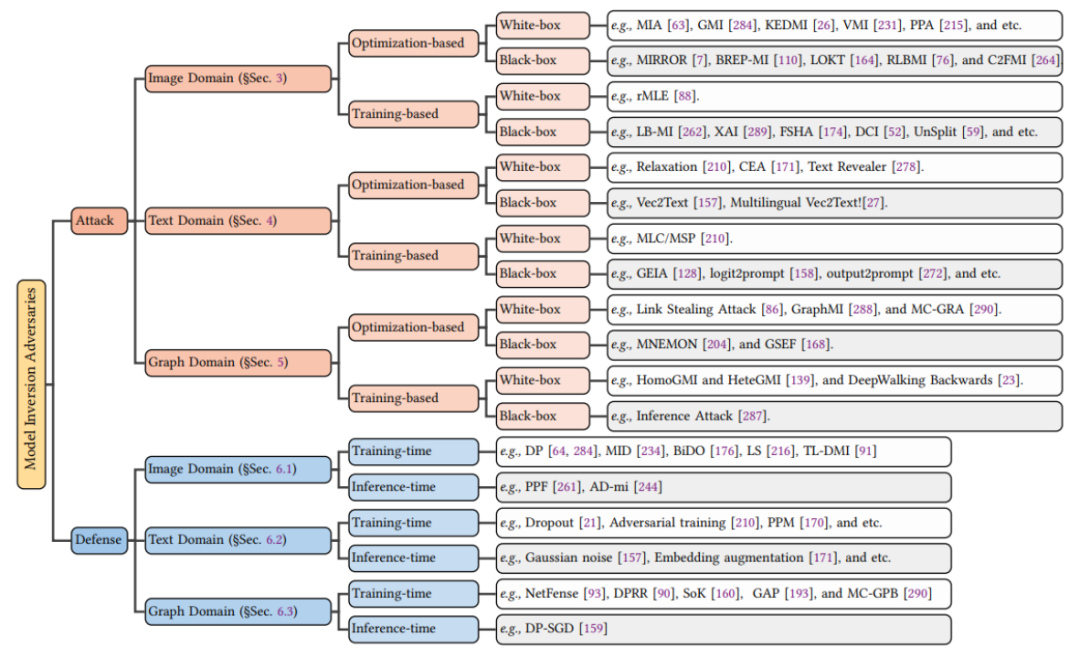 ▲ 图2. Model Inversion Attack综述的文章结构
▲ 图2. Model Inversion Attack综述的文章结构
除了给定 MIA 正式的定义,我们也讨论了与之相关的一些其他隐私攻击设定,并以图 3 为例,阐明了 MIA 与其他隐私
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









