








背景与挑战
随着 ChatGPT 掀起自回归建模革命后,近年来研究者们开始探索自回归建模在视觉生成任务的应用,将视觉和文本数据统一在 “next-token prediction” 框架下。实现自回归图像生成的关键是设计向量化(Vector-Quantization)的视觉 Tokenizer,将视觉内容离散化成类似于大语言模型词表的离散 Token。
现有方法虽取得进展,却始终面临两大桎梏:
1. 传统视觉 tokenizer 生成的离散表征与 LLM 词表存在显著的分布偏差
2. 维度诅咒:图像的二维结构迫使大语言模型以逐行方式预测视觉 token,与一维文本的连贯语义预测存在本质冲突。
结构性与特征分布性的双重割裂,暴露了当前自回归视觉生成的重大缺陷:缺乏能够既保证高保真图像重建,又能与预训练 LLMs 词汇表在结构上和特征分布上统一的视觉 tokenizer。解决这一问题对于实现有效的多模态自回归建模和增强的指令遵循能力至关重要。
因此,一个核心问题是:能否设计一种视觉 tokenizer,使生成的离散视觉 token 在保证高质量视觉重建的同时,与预训练 LLMs 词汇表实现无缝融合?

论文标题:
V2Flow: Unifying Visual Tokenization and Large Language Model Vocabularies for Autoregressive Image Generation
论文链接:
https://arxiv.org/abs/2503.07493
开源项目链接:
https://github.com/Davinci-XLab/V2Flow

V²Flow:统一视觉 Token 与大语言模型词表
最新开源的 V²Flow tokenizer,首次实现了将视觉内容直接嵌入现有大语言模型的词汇空间,在保证高质量视觉重建的同时从根本上解决模态对齐问题。总体而言,V²Flow 主要包括三点核心贡献:
视觉词汇重采样器。如图 1(a) ,将图像压缩成紧凑的一维离散 token 序列,每个 token 被表示为大语言模型(例如 Qwen [1]、LLaMA [2][3] 系列)词汇空间上的软类别分布。这一设计使得视觉 tokens 可以无缝地嵌入现有 LLM 的词汇序列中。
换言之,图像信息被直接翻译成 LLM “听得懂”的语言,实现了视觉与语言模态的对齐。在图 1(b)中,经由重采样器处理后,视觉 tokens 的潜在分布与大型语言模型(LLM)的词汇表高度一致。这种在结构和潜在分布上的高度兼容性,能够降低视觉 tokens 直接融入已有 LLM 的复杂性。
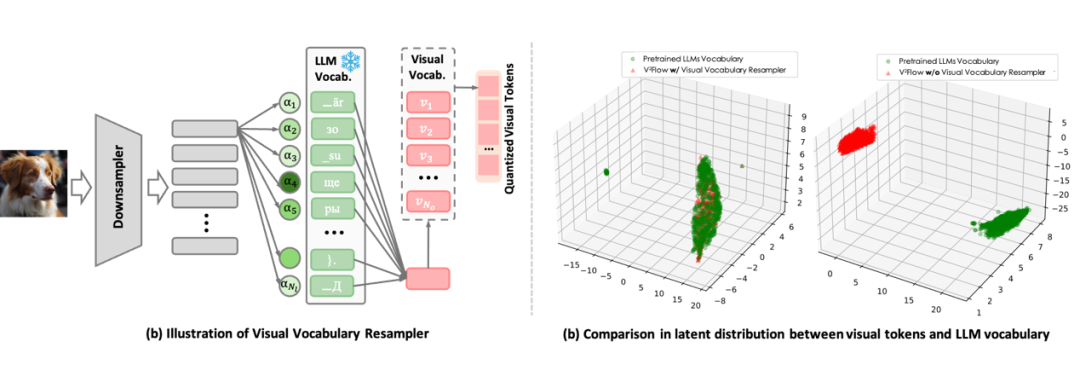
▲ 图1 视觉词汇重采样器的核心设计
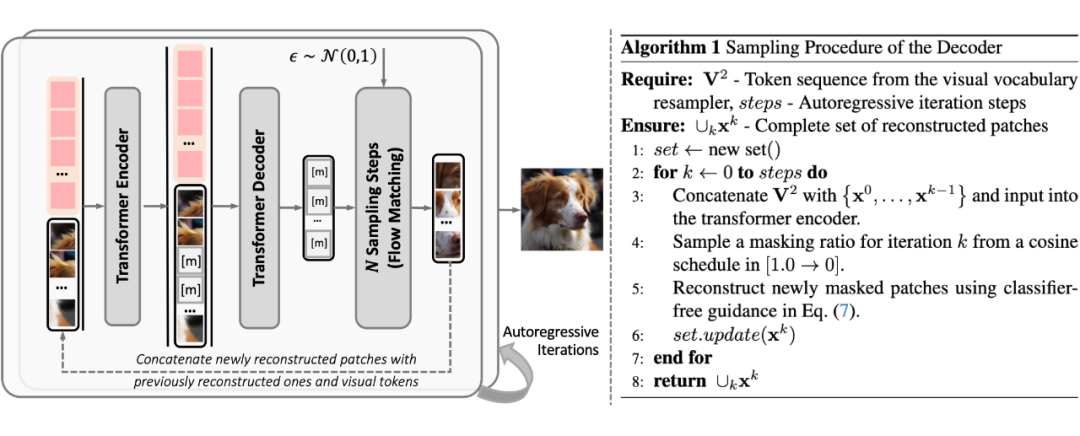
▲ 图2 掩码自回归流匹配解码器示意图以及采样阶段算法流程
掩码自回归流匹配编码器。为了实现离散化视觉 token 的高保真视觉重建,V²Flow 提出了掩码自回归流匹配解码器。该解码器采用掩码 Transformer 编码-解码结构,为视觉 tokens 补充丰富的上下文信息。增强后的视觉 tokens 用于条件化一个专门设计的速度场模型,从标准正态先验分布中重建出连续的视觉特征。
在流匹配采样阶段,该解码器采用类似 MAR [4] 的方式,以 “next-set prediction” 的方式逐步完成视觉重建。相比于近期提出的仅依赖掩码编码器-解码器结构的 TiTok [5],V2Flow 自回归采样的优势是能够在更少的视觉 token 数量下实现更高的重建质量,有效提高了压缩效率。
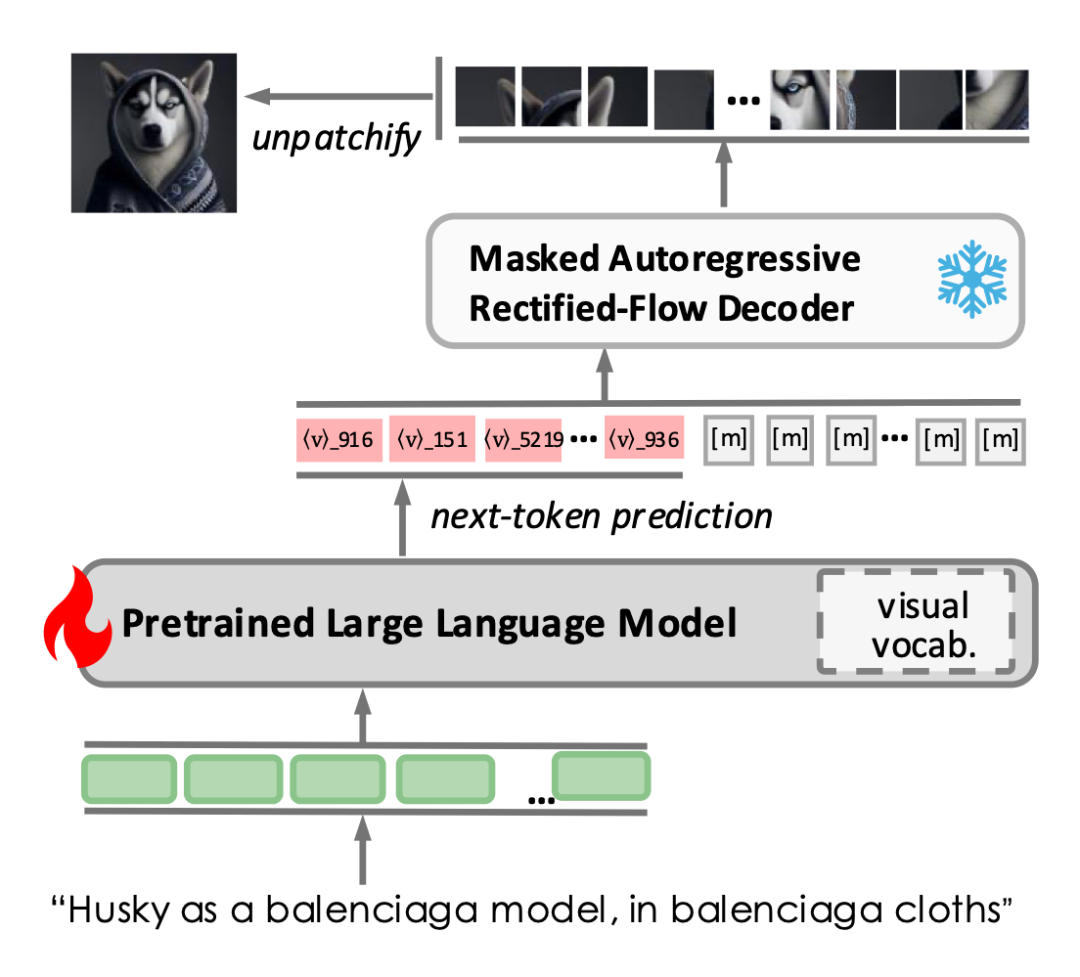
▲ 图3 V²Flow 与预训练 LLMs 融合实现自回归视觉生成的整体流程
端到端自回归视觉生成。图 3 展示了 V²Flow 协同 LLMs 实现自回归视觉生成的流程。为促进两者无缝融合,在已有 LLM 词汇表基础上扩展了一系列特定视觉 tokens,并直接利用 V²Flow 中的码本进行初始化。
训练阶段构建了包含文本-图像对的单轮对话数据,文本提示作为输入指令,而离散的视觉 tokens 则作为预测目标响应。在推理阶段,经过预训练的 LLM 根据文本指令预测视觉 tokens,直至预测到 <stop> token 为止。随后,离散视觉 tokens 被送入 V²Flow 解码器,通过流匹配采样重建出高质量图像。

实验结果
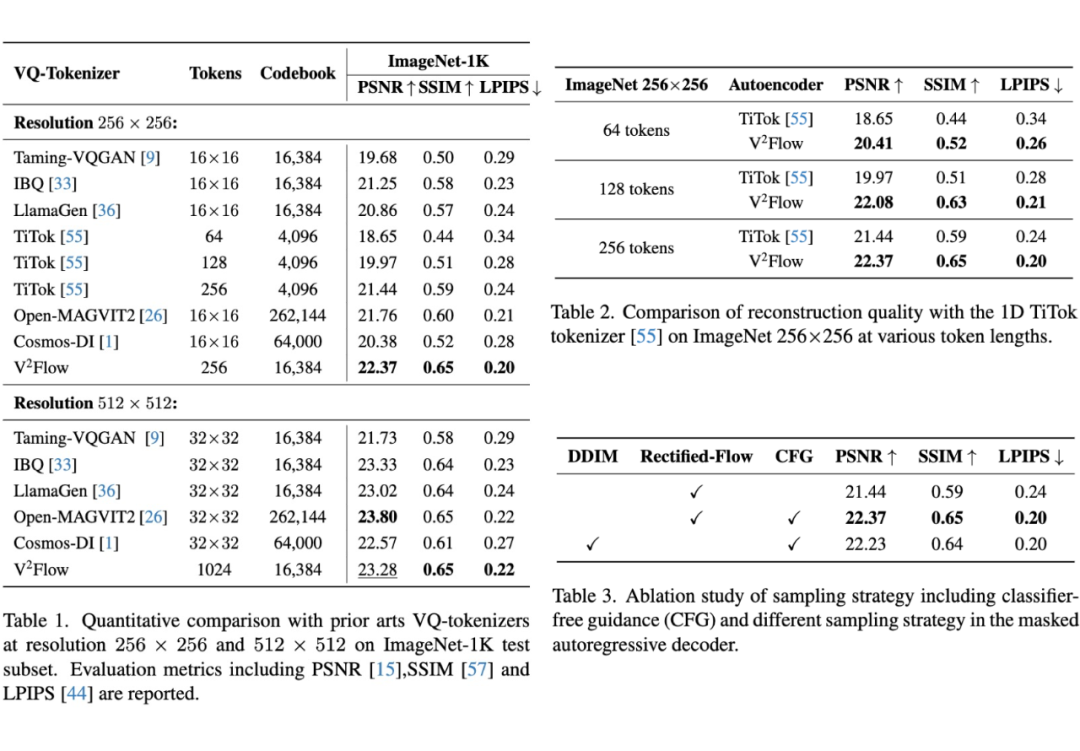
重建质量方面,V²Flow 无论是在 ImageNet-1k 测试数据集的 256 和 512 分辨率下均取得了竞争性的重建性能。相比于字节提出的一维离散化 tokenizer TiTok [5] 相比,V²Flow 利用更少的离散 tokens 实现了更高质量的图像重建,显著提高了整体压缩效率。
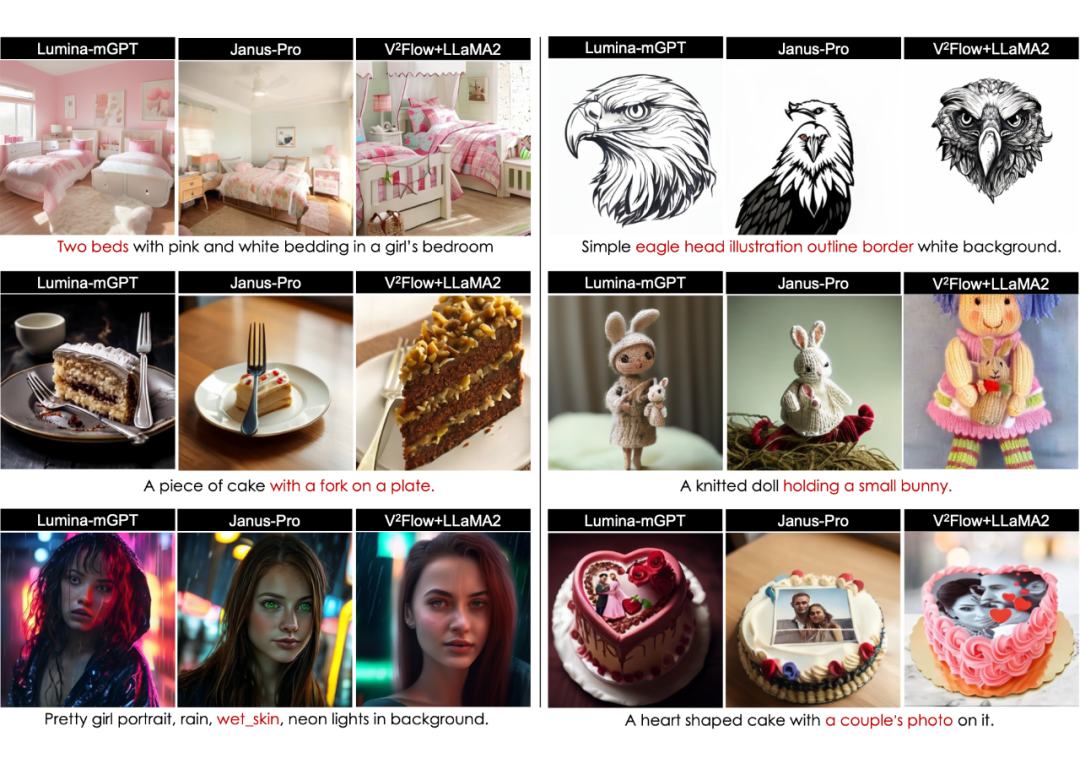
文本引导图像生成方面,实验结果表明,相比于当前两种最先进的自回归生成模型 Janus-Pro-7B [6] 和 Lumina-mGPT-7B [7], V²Flow+LLaMA2-7B 能够更加准确地捕捉文本提示中的语义细节,展示了极具竞争力的生成性能。

开源生态与团队招募:共建多模态未来
4.1 开源承诺:让技术普惠每一位探索者
开源是推动 AI 技术进化的核心动力。本次发布的 V²Flow 框架已完整公开训练与推理代码库,开发者可基于现有代码快速复现论文中的核心实验。更令人期待的是,团队预告将于近期陆续发布:
1. 512/1024 分辨率预训练模型:支持高清图像重建与生成
2. 自回归生成模型:集成 LLaMA 等主流大语言模型的开箱即用方案
3. 多模态扩展工具包:未来将支持视频、3D、语音等跨模态生成任务
GitHub 主页:
https://github.com/Davinci-XLab
🌟 Star 收藏,第一时间获取更新通知
4.2 加入我们:共创下一代多模态智能
V²Flow 作者团队现招募多模态生成算法研究型实习生!如果你渴望站在 AI 内容生成的最前沿,参与定义自回归架构的未来,这里将是你实现突破的绝佳舞台。
我们做什么?
1. 探索文本、图像、视频、语音、音乐的统一自回归生成范式
2. 构建支持高清、长序列、强语义关联的多模态大模型
3. 攻克数字人、3D 生成、实时交互创作等产业级应用难题
我们需要你具备:
✅ 硬核技术力
精通 Python,熟练使用 PyTorch/TensorFlow 等框架
深入理解 Diffusers、DeepSpeed 等 AIGC 工具链
在 CV/NLP 领域顶级会议(CVPR、ICML、NeurIPS 等)发表论文者优先
✅ 极致创新欲
对多模态生成、自回归架构、扩散模型等技术有浓厚兴趣
曾在 Kaggle、ACM 竞赛等获得 Top 名次者优先
有开源项目贡献或独立开发经验者优先
投递方式:zhangguiwei@duxiaoman.com

参考文献
[1] Yang A, Yang B, Zhang B, et al. Qwen2. 5 technical report[J]. arXiv preprint arXiv:2412.15115, 2024.
[2] Touvron H, Lavril T, Izacard G, et al. Llama: Open and efficient foundation language models[J]. arXiv preprint arXiv:2302.13971, 2023.
[3] Grattafiori A, Dubey A, Jauhri A, et al. The llama 3 herd of models[J]. arXiv preprint arXiv:2407.21783, 2024.
[4] Li T, Tian Y, Li H, et al. Autoregressive image generation without vector quantization[J]. Advances in Neural Information Processing Systems, 2024, 37: 56424-56445.
[5] Yu Q, Weber M, Deng X, et al. An image is worth 32 tokens for reconstruction and generation[J]. Advances in Neural Information Processing Systems, 2024, 37: 128940-128966.
[6] Chen X, Wu Z, Liu X, et al. Janus-pro: Unified multimodal understanding and generation with data and model scaling[J]. arXiv preprint arXiv:2501.17811, 2025.
[7] Liu D, Zhao S, Zhuo L, et al. Lumina-mgpt: Illuminate flexible photorealistic text-to-image generation with multimodal generative pretraining[J]. arXiv preprint arXiv:2408.02657, 2024.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









