







近年来,大语言模型(LLMs)展现了在文档问答、长对话、复杂指令遵循等场景下的强大能力。然而,随着上下文长度的增长,一个关键的瓶颈日益凸显——KV Cache(键值缓存)带来的巨大 GPU 显存开销。
为了缓解这一问题,现有方法通常基于注意力稀疏性假设,在推理过程中丢弃(discard)它们认为不重要的 KV Cache。但这带来了一个新的困境:注意力分数是基 当前 隐藏状态计算的,无法完全预示 Token 在 未来 推理步骤中的重要性。
尤其在多步推理(如 CoT)或多轮对话场景下,早期被判定为不重要的 Token 可能在后续步骤中变得至关重要。丢弃 Token 可能导致关键信息的永久丢失,影响模型性能。
为此,本文提出了 OmniKV,一种无需丢弃 Token、无需训练的 LLM 高效推理方法。OmniKV 巧妙地利用了层间注意力的相似性,实现了动态的上下文选择,在不损失性能的前提下,在 Lightllm(https://github.com/ModelTC/lightllm)上实现了 1.7x 相比于 vLLM 的吞吐量提升。

论文标题:
OmniKV: Dynamic Context Selection for Efficient Long-Context LLMs
论文链接:
https://openreview.net/forum?id=ulCAPXYXfa
代码链接:
https://github.com/antgroup/OmniKV.git

核心洞察:层间注意力相似性(Inter-Layer Attention Similarity)
OmniKV 的核心创新基于一个关键洞察:在单个生成步骤内,被模型高度关注的(即注意力得分高的)Token 集合,在不同的 Transformer 层之间表现出高度的相似性。换句话说,重要的上下文信息在多个 transformer 层之间存在共识。
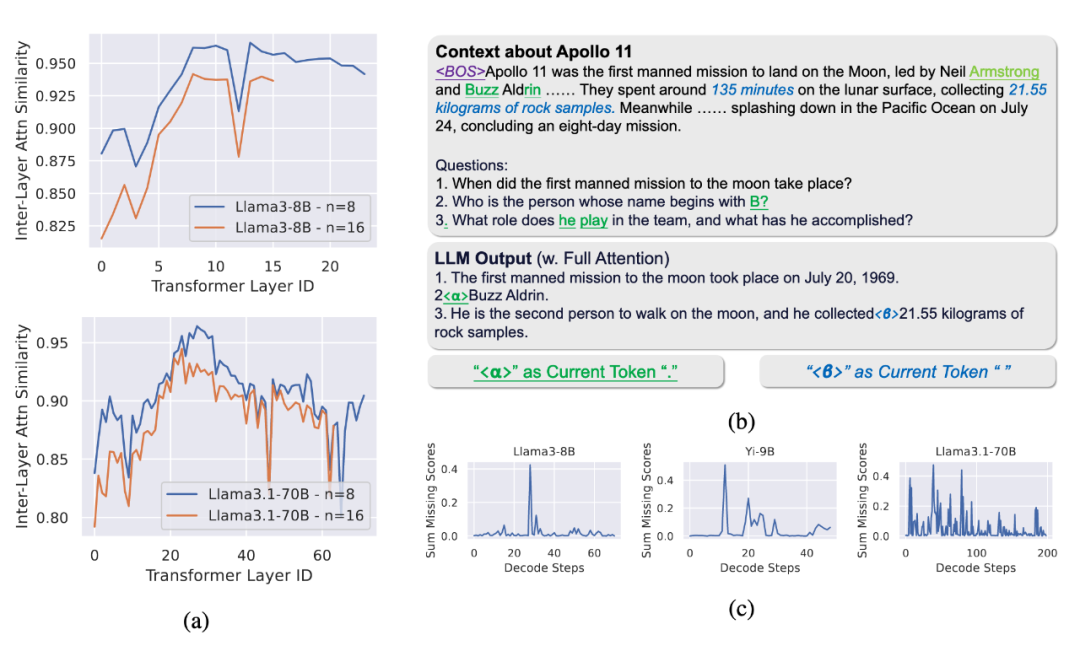
▲ 图1a:层间注意力相似性。即使相隔多个层,重要 Token 的分布也高度相似。
OmniKV 正是利用了这一特性。它仅选择少数几个层(称为 “Filter 层”)来计算完整的注意力分数并识别重要的 Token 子集,而其他大多数层则直接复用(共享)来自最近 Filter 层识别出的 Token 索引。在计算注意力时,仅加载并计算这个稀疏子集 KV Cache,从而大幅减少计算量和数据传输量。

OmniKV 方法
OmniKV 的推理过程分为 Prefill 和 Decode 两个阶段:
Prefill 阶段:对输入的 Prompt 进行编码,生成完整的 KV Cache。此时,OmniKV 将大部分非 Filter 层的 KV Cache 卸载(offload)到 CPU 内存,仅保留少量 Filter 层的 KV Cache 在 GPU 上。
Decode 阶段(生成阶段):
Filter 层:计算完整注意力,并使用 Context Selector 动态选择当前步骤最重要的 Top-K 个 Token 索引。
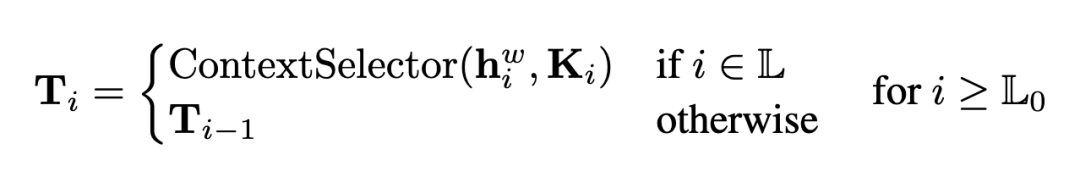
非 Filter 层:直接从 CPU 加载(load)由前一个 Filter 层选择出的 Token 索引对应的 KV Cache 子集,并在该子集上执行稀疏注意力计算。
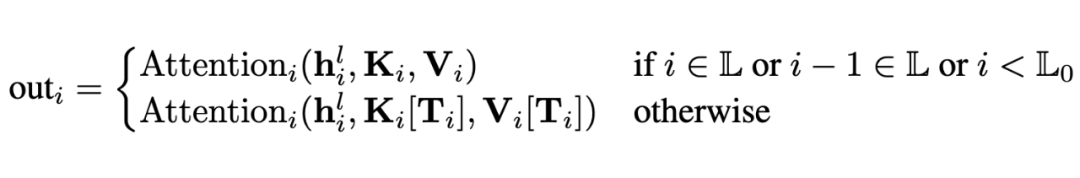
Packed Load:由于相邻的多个非 Filter 层共享相同的 Token 索引,它们的 KV Cache 可以被打包(packed)并一次性从 CPU 加载到 GPU,进一步减少 PCIe 带宽压力。
异步传输:数据加载与计算可以异步进行,掩盖部分数据传输延迟。
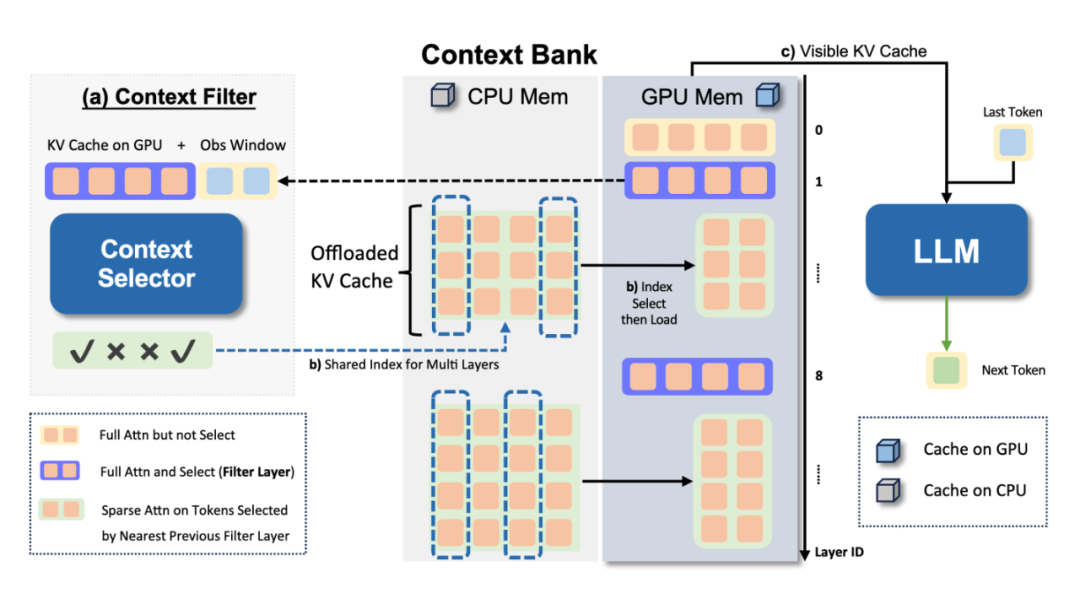
▲ 图2:OmniKV Decode 阶段框架图。通过 Filter 层动态选择,非 Filter 层仅加载和计算稀疏子集。

无损性能,可能更适合 CoT 或多轮对话场景的加速
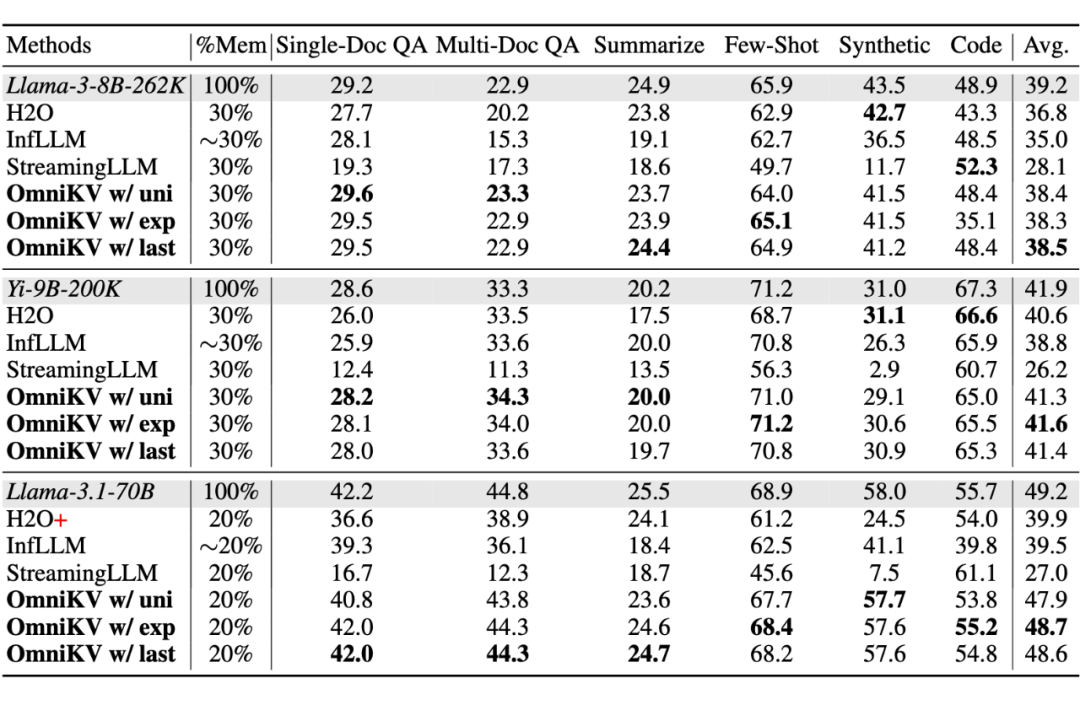
▲ 图3:Longbench 的性能表现,在长文本 benchamrk 下,OmniKV 单步推理拥有几乎无损的性能。
丢弃 Token 的方法可能会丢失对后续推理至关重要的信息。图 1b 和 1c 的分析表明,在多步推理(如 CoT)中,不同生成步骤所依赖的关键 Token 是动态变化的。
OmniKV 的 Token-Dropping-Free 设计天然地避免了这个问题。因为它保留了所有历史信息,模型可以在任何需要的时候,通过动态选择机制重新关注到之前可能被忽略的 Token。
实验(图4)表明,在 2WikiMQA、HotpotQA 和论文提出的 2StageRetr 等多步推理任务中,OmniKV 在各种显存预算下都显著优于 H2O 等丢弃 Token 的方法,展现了其在复杂推理场景下的鲁棒性和优越性。
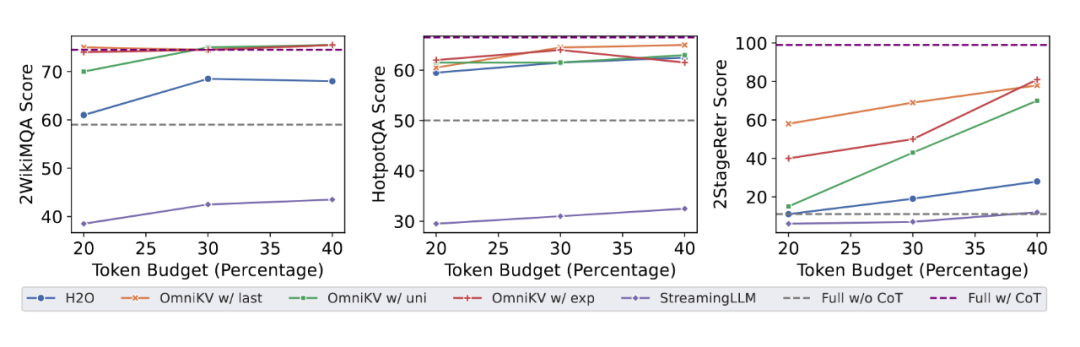
▲ 图4:多步推理任务性能对比。OmniKV(红色/绿色/橙色线)在各种预算下均显著优于基线方法。

推理速度大幅提升
通过 Offloading,OmniKV 能将 Llama-3-8B 在单张 A100 上支持的最大上下文长度从 128K 扩展到 450K,且依然实现了 1.7x 的加速比。
推理框架适配与吞吐提升: 我们将 OmniKV 成功适配到了业界流行的 LightLLM 推理框架。在多卡张量并行(TP=4)的设置下,与集成了 PagedAttention 的 vLLM 相比,OmniKV + LightLLM 的解码吞吐量(Throughput)在处理 512K 长序列时提升了 1.7x。
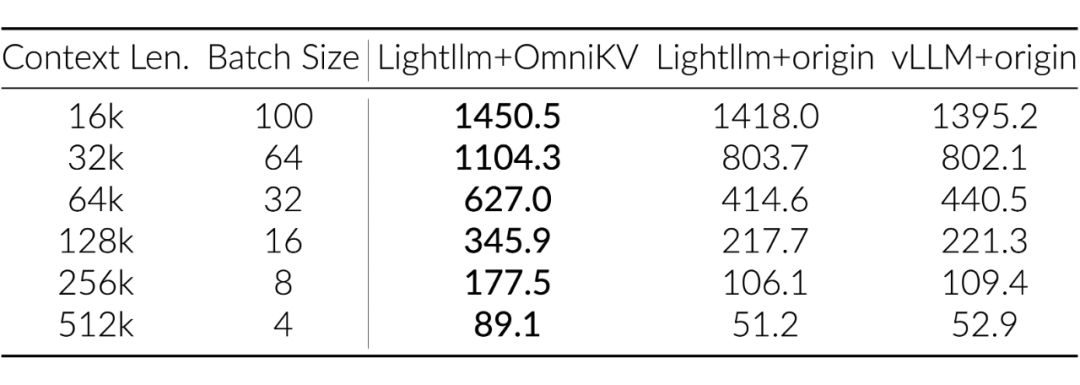
▲ 表1:推理吞吐量对比

总结
OmniKV 提出了一种创新性的动态上下文选择方法,用于高效处理长上下文 LLM 推理:
1. 核心洞察:揭示并利用了 Transformer 层间的注意力相似性。
2. 动态无损:无需丢弃任何 Token,通过动态选择实现计算稀疏,尤其适合 CoT 和多轮对话等复杂推理场景。
3. 高效实用:显著提升推理速度和吞吐量,降低显存占用,并成功适配 LightLLM 等主流推理框架。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









