








MLLMs “幻觉” 困境:“记忆” 不可靠
当前,多模态大语言模型(MLLMs) 能处理视觉、听觉和文本等多种数据,在计算机视觉和自然语言处理等领域大显身手。然而,“幻觉” 问题却成了 MLLMs 的 “阿喀琉斯之踵”,在医疗、自动驾驶等对安全要求极高的领域,模型一旦作出错误虚假的判断,后果不堪设想。
为解决这个问题,研究者们提出了不少方案。最直观经典的策略是:
1. 检索增强生成(RAG),通过从外部数据库检索相关信息以辅助更可信的文本生成,来减少幻觉,但这一方案会带来极大计算成本和存储负担;
2. 另外,后训练微调也能有效提升文本生成的一致性,却需要大量训练数据和计算开销;
3. 注意力干预策略如 OPERA,虽然不用额外数据训练,但通常涉及回顾分配操作,导致较高的推理延迟和较大的内存占用;
4. 基于对比解码(CD)的方法相对比较简单高效,例如 VCD 通过调整 logits 分布来减少幻觉,却会在解码过程引入噪声,导致降低模型幻觉率的同时也破坏了其原有的通用能力,此外还会增加数倍的推理开销。
这些方法都有各自的局限,那有没有更好的幻觉缓解办法呢?

MemVR 登场:源于人类认知的 “看两次” 妙法

论文标题:
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models
论文链接:
https://arxiv.org/abs/2410.03577
代码地址:
https://github.com/1zhou-Wang/MemVR
研究团队:
港科大(广州)、港科大、蚂蚁集团、华科大
为了更清晰地分析 MemVR 的优势,团队通过下面表格总结了与近期代表性方法的比较。
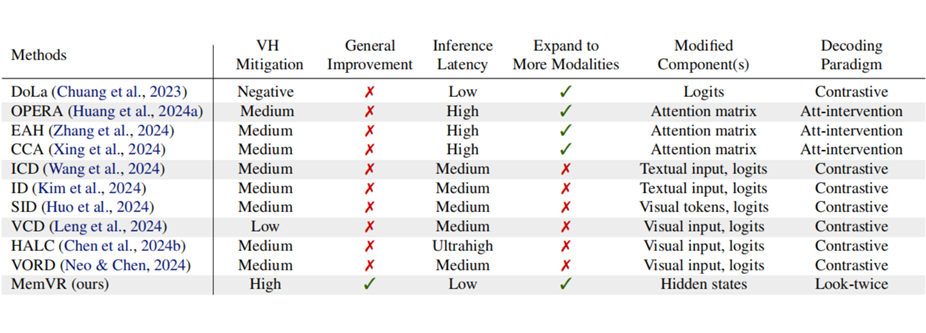
▲ 表1. 现有 SOTA 方法与提出的 MemVR 的全面剖析
研究团队从人类如何消除幻觉的认知过程出发,旨在通过模拟人对于记忆不确定性进行二次检查的策略来增强 MLLMs 的可靠性。
具体来说,当我们看到一张图片后,大脑通常会形成一个初步的记忆痕迹,但随着时间推移,人们的注意力会被转移到其他方面(类似 Attention Sinks),关于图片细节的记忆可能会变得模糊。
为了加深记忆,人们会选择再看一次图片,来帮助大脑重新激活与这张图片相关的神经元,从而增强视觉记忆的真实性,避免不确定的幻觉。

受此启发,研究者提出了 Memory-space Visual Retracing(MemVR),也就是 “看两次” 机制。它的实现过程也很巧妙,相当于把视觉 Token 当作补充性证据,在模型推理到遇到遗忘困扰的中间触发层(相当于人们绞尽脑汁思索阶段)后,通过前馈网络(FFN)让其重新“检索”所需视觉知识(即实现所谓看两次)。
这就好比给模型一个 “记忆提醒”,让它在回答前再确认一下不确定的视觉知识,有效增强与事实的一致性。
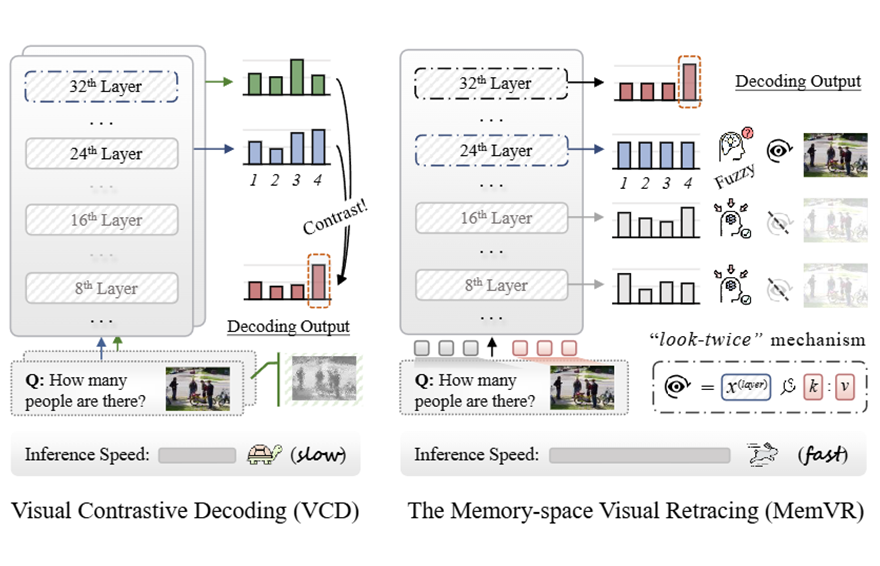
▲ 图1. 基于 CD 的幻觉缓解范式与提出的高效 MemVR 的比较
在技术实现上,MemVR 对 FFN 进行了巧妙重构。普通 FFN 像一个 “知识存储器”,用输入作为查询去匹配关键值来获取对应的信息。
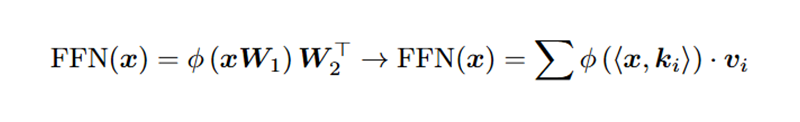
而 MemVR 的视觉回溯(VR)则把视觉 Token 当作 “补充性证据”,在模型推理到不确定性极高的层(这被认为是模型在发出“求救”信号)后,将视觉 token 再注入文本解码器的中间层,从而校准可能偏离真实目标的预测,减少与物体、属性、关系等相关文本生成的不确定性。
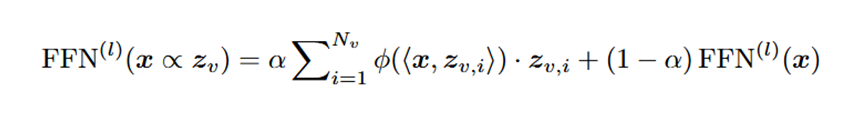
为了让 VR 的效果更好,研究团队还设计了动态触发机制。根据不同层的输出不确定性,动态选择中间触发层进行视觉回溯 VR。这种动态策略相比固定层 VR 策略更灵活,能适应不同场景,避免了固定层 VR 策略对特定数据集的过度依赖和繁琐的超参数调整。
理论层面上,MemVR 从信息论的角度深入分析,证明“看两次”的操作增强了隐藏状态和视觉 Token 之间的互信息,降低输出的条件熵,优化信息瓶颈框架下的目标函数。这意味着模型能更好地利用视觉信息,减少预测的不确定性,降低产生幻觉的概率,提升整体可靠性。

实验见真章:效果显著超预期
研究团队进行了大量实验来验证 MemVR 的效果,涵盖了多个幻觉评估基准测试和通用基准测试。
在幻觉基准测试中,MemVR 表现惊艳。在 POPE 基准测试里,它的平均准确率最高提升了 7.0%,在 A-OKVQA 数据集的不同设置下,F1 分数最高提升了 7.5%,远超其他对比方法。
在 CHAIR 评估中,相比普通的 LLaVA-1.5,MemVR 在相关指标上也有显著提升,比如 CHAIR_S 指标提升了 6.8%,CHAIR_I 指标提升了 15.6%。在 HallusionBench 评估里同样表现出色,在多个指标上都取得了最佳成绩。
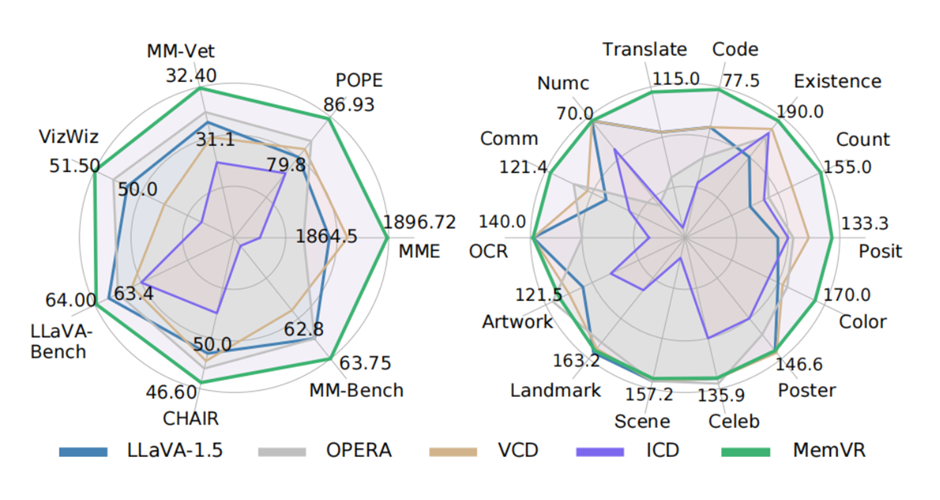
▲ 图2. 比较基准模型的雷达图
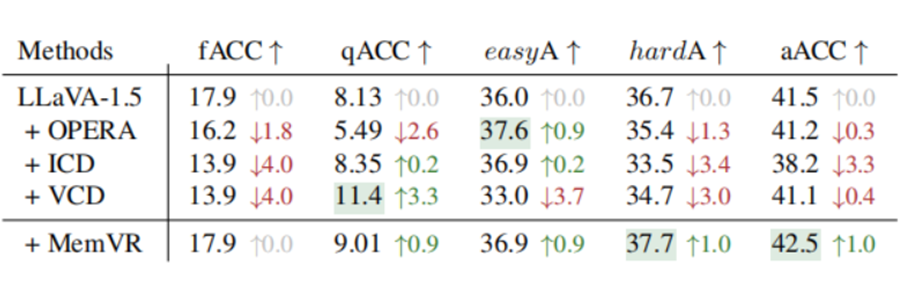
▲ 表2. 不同方法的 HallusionBench 评价结果
在通用基准测试中,MemVR 同样表现卓越。在 LLaVA-Bench 测试中,它的各项指标都优于竞争模型;在 MM-Vet 测试里,OCR 和空间感知任务的整体性能平均提升了 6.1%;在 MME 子集中,处理物体级和属性级幻觉以及常识推理的能力都有显著提高,LLaVA 和 Qwen-VL 的 MME 总分分别增加了 32 和 36。
重要的是,其他方法虽然能缓解部分幻觉问题,但会降低模型在通用基准测试中的性能,而 MemVR 不会有这一问题,MemVR 在减少幻觉的同时,也能保证模型在通用任务上表现出色。
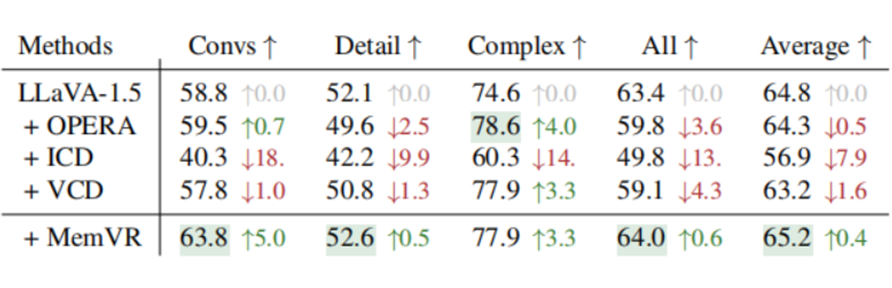
▲ 表3. 不同方法的 LLaVA-Bench(In-the-Wild)评价结果
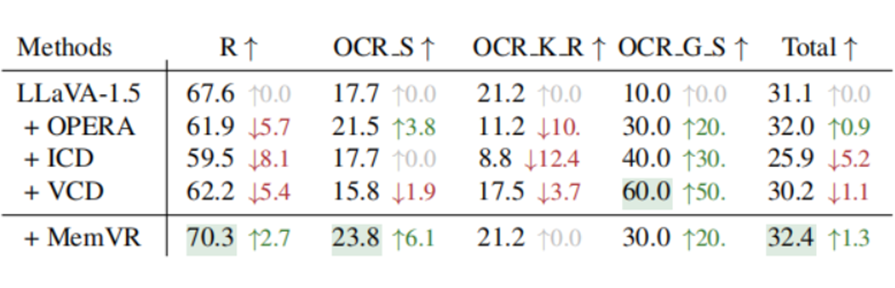
▲ 表4. 不同方法的 MM-Vet 评价结果
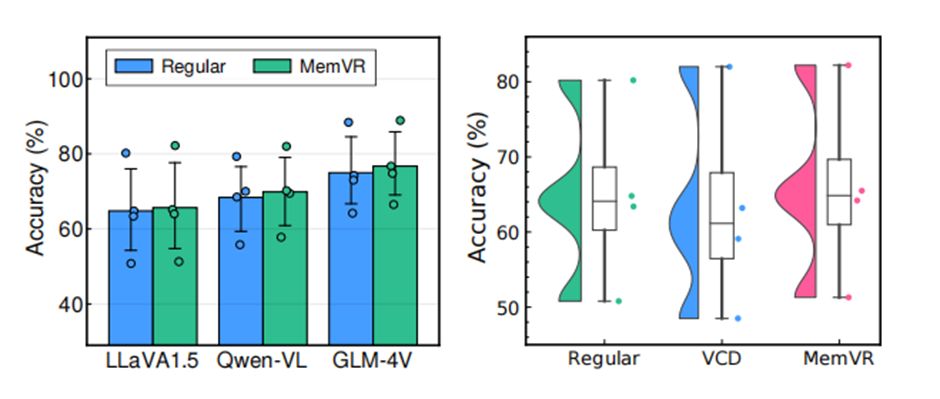
▲ 图3(左)MemVR 与 LLaVA-1.5、Qwen-VL 和 GLM-4V 在 LLaVA-Bench 上的比较。(右)MemVR与VCD 在 LLaVA-Bench 上的比较
在效率上,相比于基于对比解码和注意力干预范式,前者需要多轮推理,后者因回滚操作导致指数级开销,MemVR 方法仅需一次常规推理,具有明显的效率优势。下表显示了在延迟、吞吐量、时间成本和内存方面的比较结果。
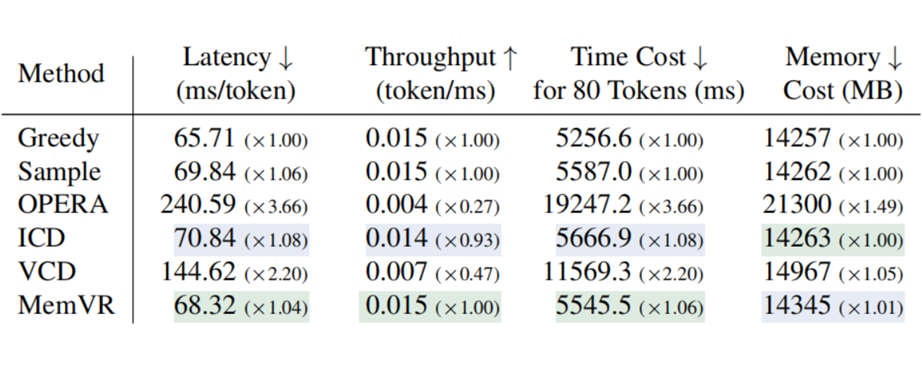
▲ 表5. SOTA 方法和 MemVR 在延迟、吞吐量、时间成本和内存使用方面的性能比较。

未来可期:持续优化,拓展应用边界
MemVR 为缓解多模态大语言模型的幻觉问题提供了创新思路和有效方法,在多个基准测试中展现出强大的性能。但它也并非完美无缺,目前即插即用的策略所能提升的性能有限,可能需要进一步研究并迁移到训练范式以获得更好的效果。
MemVR 具有广阔的拓展空间,理论上可以扩展到任意更多模态,如应用于语音、点云、IMU、fMRI 等数据类型实现“听两次”,“感知两次”等,为未来的幻觉研究探索更多可能。
不快来试一下?解锁 “看两次” 的神奇力量!
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









