







©作者 | 方佳瑞
单位 | 腾讯
研究方向 | 机器学习系统
随着 Gemini 1M context length 和 Sora 出世,如何训练超长上下文的大模型引起了大家广泛关注。
本文对比两种目前炙手可热长文本训练方法 DeepSpeed Ulysess [1] 和 Ring-Attention [2]。2023 年末,二者几乎同时出现,但是设计方法大相径庭,可谓一时瑜亮。
DeepSpeed Ulysess:切分 Q、K、V 序列维度,核心卖点保持通信复杂度低,和 GPU 数无关,和序列长度呈线性关系。
Ring-Attention:切分 Q、K、V 序列维度,核心卖点是通信和计算重叠。
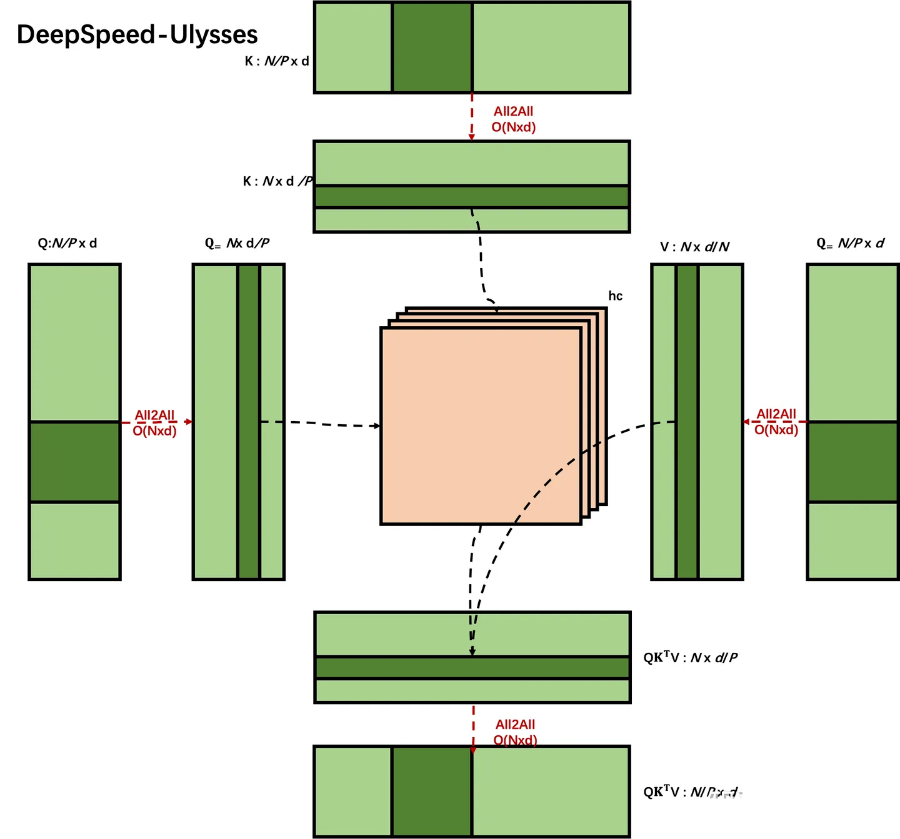
下面,我用 FlashAttention Style 的示意图来对比二者区别。图中 N 表示序列长度,d 表示 hidden_size=(hc * hs),hc = head_cnt,hs=head_size,P 表示 GPU 数目(图中 P=4)。红色虚线表示通信,黑色虚线表示计算。

DS-Ulysses
DS-Ulysses 对 Q、K、V 沿着 N 维度切分成 P 份,三个分布式矩阵通过 All2All 变成沿 d 维度切分了。参见我之前的文章 [3],All2All 等价于一个分布式转置操作。之后就是正常的 softmax(QK^T)V 计算,可以用 FlashAttention 加速,得到结果再通过 All2All 转置回来。
因为 All2All 最有通信量是 O(n),n 是 message size,所以 DS-Ulysses 通信量位 O(Nxd),和 P 没关系。所以可以扩展到很多 GPU 上。Ulysses 可以和 ZeRO 正交使用,ZeRO 可以进一步切分 Q、K、V,减少显存消耗。
Ulysses 也有明显缺点,就是转置后切分维度 d/P,我们希望 d/P=hc/P * head_size,即对 head_cnt 所在维度切分,这样 Attention 的计算都在一张卡上完成,从而可以使用 FlashAttention 等单卡优化。但是如果遇到 GQA 或者 MQA 情况,K、V 的 head_cnt 很小,导致 GPU 数目 P 也不能变得很大。

Ring-Attention
Ring-Attention 就是FlashAttention(FA)的分布式版本,利用了 online softmax 这个大杀器。FlashAttention 文章一搜一大把,我也解读过 [4]。这里推荐朱小霖的 Ring-Attention 文章,里面有一个非常好开源实现,在原始 Ring 基础上做了很多改进。
https://zhuanlan.zhihu.com/p/683714620
https://github.com/zhuzilin/ring-flash-attention
Ring-Attention 采用 FA 的双循环计算模式,外层循环循环遍历 Q,内层循环遍历 K、V,使用 online softmax 增量更新最终结果,这和 FA 一模一样。当 K、V 计算穿越下图虚线部分时候,需要 P2P 通信,向相邻的 GPU 卡通信。通信和计算可以重叠起来。下图只画了一个 head 的 Attention 计算,可以并行做 head_cnt 个这样的计算。
Ring-Attention 的分块大小 (下图中的参数 c) 是可调节的。红色箭头表示的 fp16 格式 KVCache 的 P2P 通信量是 bytes。QKV 分块计算量是 FLOPS。所以只要满足计算量大于通信量,计算通信可以重叠起来,从而让通信开销消失。另外 K、V 的计算结果 intermediate tensor 只需要 c x c 大小部分,内存消耗很少。
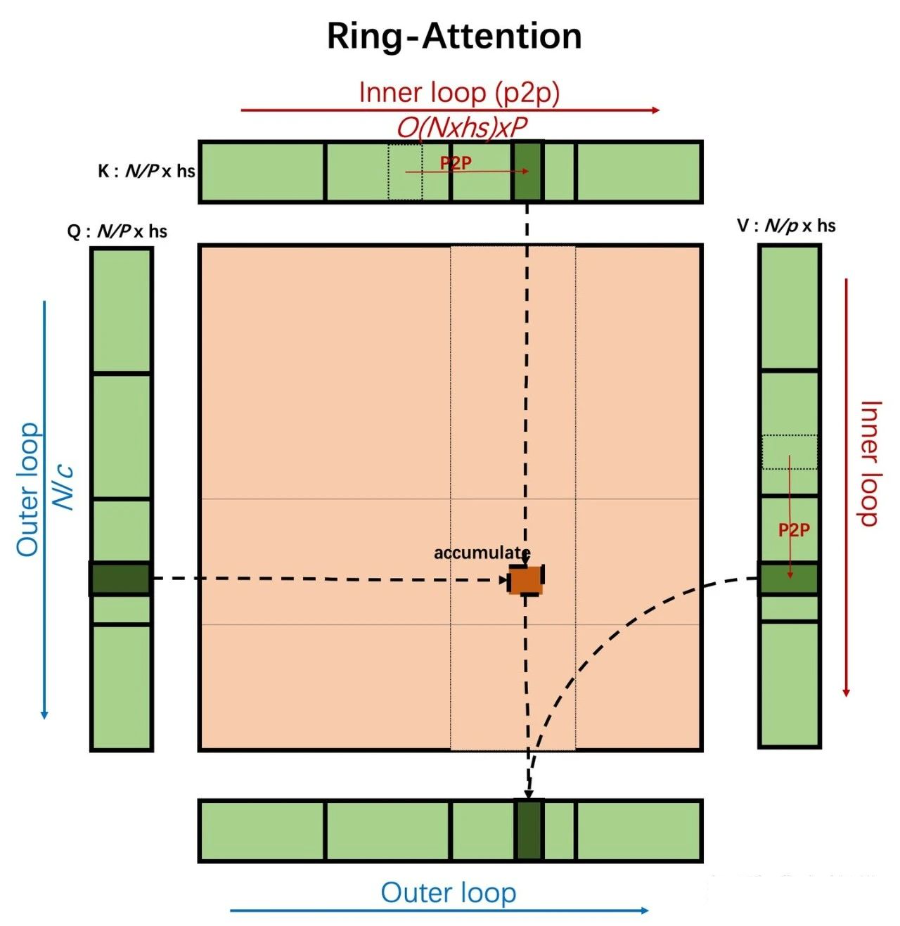
Ring-Attention 也有很多缺陷。比如 Self-Atention 计算有效部分一般是一个下三角,所以均匀切分 Q 的话,负载是不均衡的。这个问题 @朱小霖 的实现做了优化。另外处理变长序列也不容易,这在 SFT 任务中比较常见。

二者比较
通信量:Ulysses 完胜。
DS-Ulysses 三次 All2All 通信量 3xO(Nxd)。
Ring-Attention :N/P/c x (P-1)/PxO(Nxd)=O(N^2xd/(Pxc)),外层循环每个GPU需要N/P/c次迭代,内层循环每个GPU收发(P-1)/P x O(Nxd)数据。通信会随着序列长度增长而平方增长。所以非常依赖和计算重叠。
通信方式:Ring-Attention 更鲁棒。
DS-Ulysses 需要 All2All 通信,对底层 XCCL 实现和网络硬件拓扑要求比较。一般 All2All 跨机器涉及拥塞控制,带宽比较差。
Ring-Attention 需要 P2P 通信,对网络需求很低。
内存使用:二者近似
二者 Q、K、V 显存消耗一致,对于 QK 计算结果 intermediate tensor 也都可以和 FlashAttention 等 memory efficient attention 方法兼容。二者也都可以和 ZeRO、TP 等其他并行方式兼容,所以我认为二者内存消耗类似。
网络硬件泛化型:Ring-Attention 更好
Ulysses 没有重叠 All2All 和计算,不过这个并不是不可以做。
Ring-Attention 重叠 P2P 和计算,对分块大小 c 需要调节。
模型结构泛化性:Ring-Attention 更好
Ulysses 会受到 head 数目限制,导致无法完成切分。尤其是和 TP 结合,有序列并行 degree * 张量并行 degree <= head_cnt 的限制。
Ring-Attention 对网络结构参数不敏感。
输入长度泛化性:Ulysses 更好
Ring-Attention 处理变长输入很难处理,Ulysses 无所谓。
总体来说,Ring-Attention 侵入式修改 Attention 计算流程,实现复杂,同时对变长输入、并行分块大小选择、三角矩阵计算负载均衡等问题处理起来很麻烦。而 Ulysses 对 Attention 计算保持未动,实现简单,但是缺陷就是对 num head 参数敏感。
用奥卡姆剃刀原理,我觉得 Ulysses 后面也许会是主流方案。

混合并行
Ulysses 和 Ring 可以组成一个混合序列并行方案。同时克服并行度 <=num_head 的限制,和避免 P2P 低效带宽利用。比如,在下面 8xA100 NVLink, num_head=8 上可以相比 ring-flash-attn 有 18% 和 31% 的训练和推理性能提升。
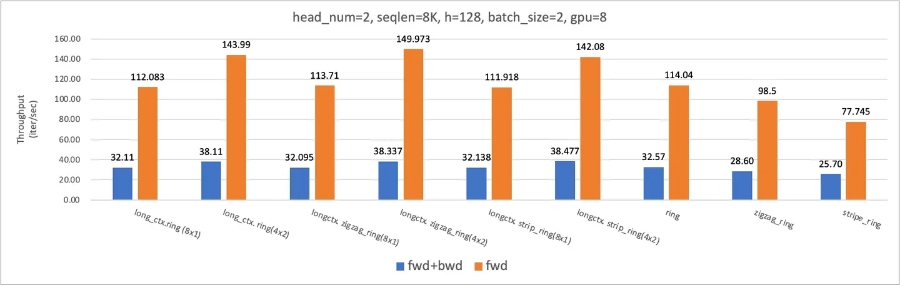
在下面 8xA100 NVLink, num_head=2 上,训练有 54% 训练性能提升,得益于利用 All2All 高带宽利用率的特性。
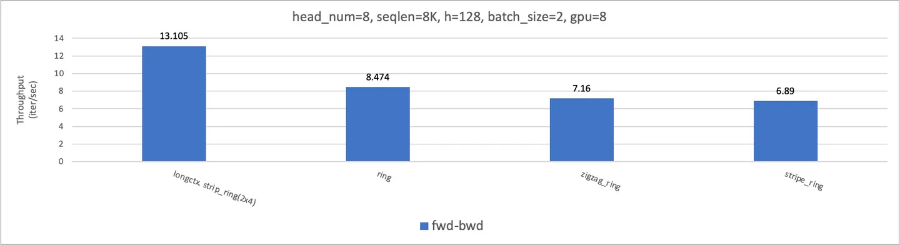
实现参见本人 repo:
https://github.com/feifeibear/long-context-attention

参考文献
[1] https://arxiv.org/abs/2309.14509
[2] https://arxiv.org/abs/2310.01889
[3] https://zhuanlan.zhihu.com/p/653968730
[4] https://zhuanlan.zhihu.com/p/664061672
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









