







©PaperWeekly 原创 · 作者 | 杨志雄
单位 | 国防科技大学博士生
研究方向 | 智能图像处理

导言
近年来,基于深度学习的方法在盲单图像超分辨率(SISR)任务中取得了巨大成功。然而,现有方法通常需要手工设计的先验和基于有监督学习的先验。基于模型方法通常存在着不适定性和盲 SISR 问题的非凸性,在优化过程中通常会陷局部模式。基于学习方法在实际应用中仍然受到对训练样本的高度数据依赖和模型训练的专用时间消耗的限制。
在本文中,我们提出了一种基于元学习和马尔可夫链蒙特卡罗核估计的 SISR 方法采用轻量级网络作为核生成器,并通过从随机高斯分布的 MCMC 模拟中学习进行优化。该过程为合理的模糊核提供了近似值,并在 SISR 优化过程中引入了网络级朗之万动力学,这有助于防止核估计出现不良局部最优解。
同时,提出了一种基于元学习的交替优化程序来分别优化核生成器和图像恢复器。与传统的交替最小化策略相比,基于元学习的框架被用于学习自适应优化策略,该策略贪婪性较低,可实现更好的收敛性能。
所提方法首次在无监督推理中实现了基于学习的即插即用盲 SISR 解决方案。在合成和真实数据集上与最新技术相比,大量实验证明了所提出方法的卓越性能和泛化能力。
本文所提算法(MLMC)以及相关的对比方法 baseline 的代码都是开源的。该算法不仅对盲图像超分问题求解有效,对其他逆问题(例如其他图像恢复任务、雷达成像、医学影像等)有一定的通用性,我们自己也做了一些初步尝试。配好 pytorch 环境后即可轻松实现运行,有问题欢迎随时找我讨论交流。

论文标题:
Blind Super-Resolution Via Meta-Learning and Markov Chain Monte Carlo Simulation
文章地址:
https://ieeexplore.ieee.org/abstract/document/10533864
项目地址:
https://github.com/XYLGroup/MLMC

问题陈述
盲图像超分问题中的图像退化的数学表达式可以被写为:
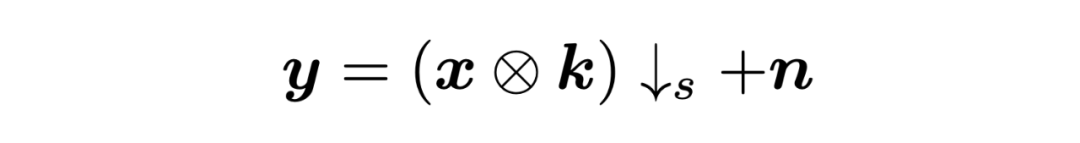
其中 为低分辨图像, 为高分辨图像, 为模糊核, 为缩放倍数, 为加性噪声。盲图像超分问题可以被写为如下最大后验(MAP)的形式:
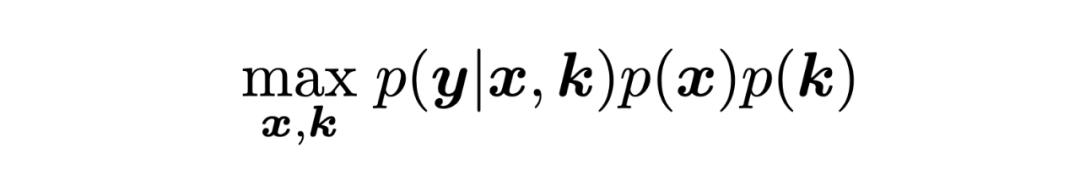
其中 为数据项, 和 为先验项。上述MAP问题也可以写出显式优化问题的形式:
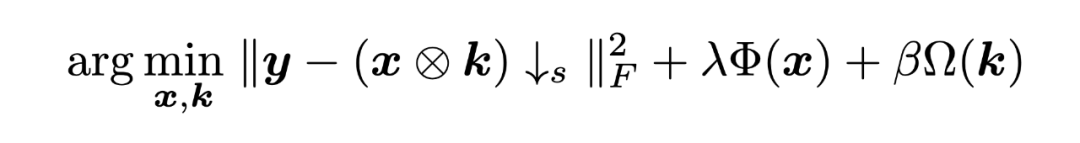
其中 和 表示先验项。
通常我们采用基于投影交替最小化(PAM)解决此类双变量优化问题。在本文中,我们设计了学习辅助优化建模,通过神经网络来辅助最优化问题的模型构建或优化求解过程,不改变原问题的基本数学映射关系和物理建模基础。
对于上述多变量优化问题,可以引入两个神经网络分别作为核估计器 和图像重建器 将问题中对变量的优化问题转换为对网络参数的优化问题:
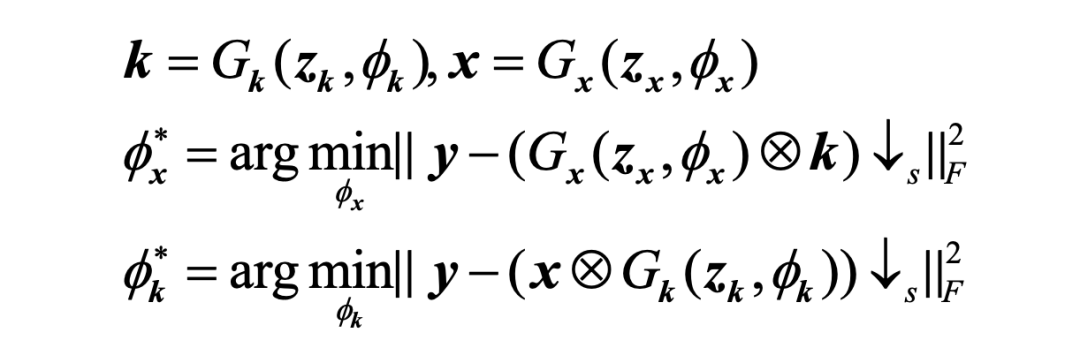

方法
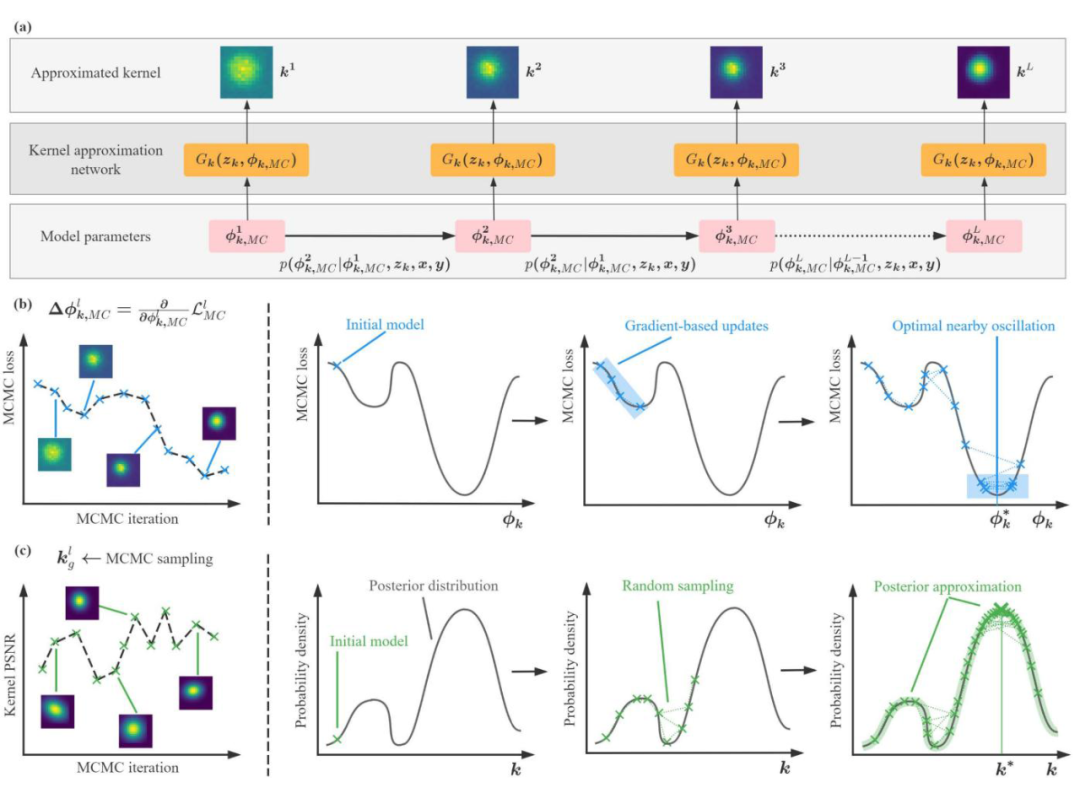
2.1 总体框架
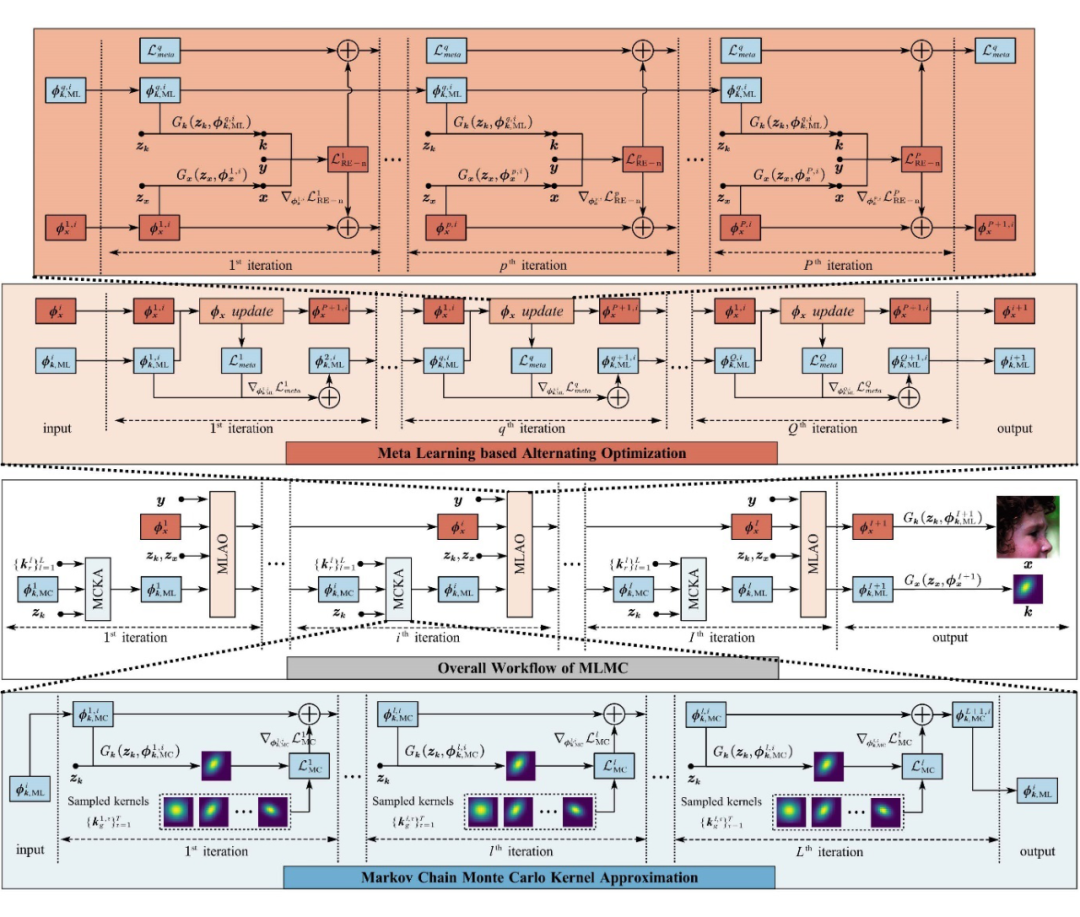
基本范式建立在 MCKA(蓝色)和 MLAO(黄色)阶段分别对核估计器的参数 和图像恢复器的参数 进行交替优化的基础上。MCKA 和 MLAO 之间的交替优化过程称为外循环。在每个外循环步骤中,分别有 MCKA 内循环和 MLAO 内循环。
在 MCKA内循环中,内核生成 的参数根据随机高斯分布上的 L 次 MCMC 模拟进行迭代更新,以赋予随机内核先验。在 MLAO 内循环中,内核之间的交替估计和 HR图像恢复经过 Q 次迭代处理,以确保在给定 LR 观测的基础上的估计精度。
2.2 马尔可夫链蒙特卡罗核估计
我们提出一种随机高斯分布的 MCMC 采样以提供核先验,并在核生成器的参数上构建马尔可夫链,这些参数在 MCMC 过程中迭代更新,以近似盲 SISR 任务的模糊核。首先,我们应用具有参数 的浅层 FCN 来生成模糊核 ,其通过将固定随机噪声 作为输入,形式如下:

表示来自随机高斯分布的模糊核, 表示 MCMC 采样的随机核
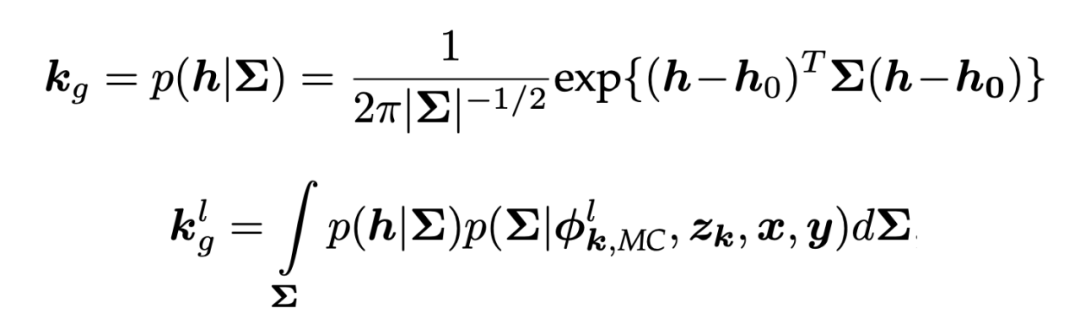
随机生成的分布涵盖不同的核大小 、中心 和类别 。其中表示当前参数状态 给定的 HR 图像 和 LR 图像 的后验。积分运算可以被整个分布上充分采样的求和所取代,近似为:
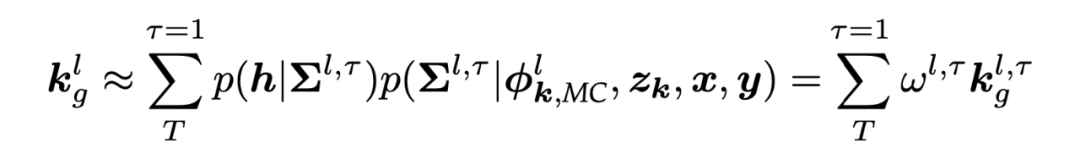
可以表示第 个采样核的权重 。在本文中, 上的马尔可夫链在一次蒙特卡洛模拟中通过核权重 对所有采样核进行重新加权,可以表示为:
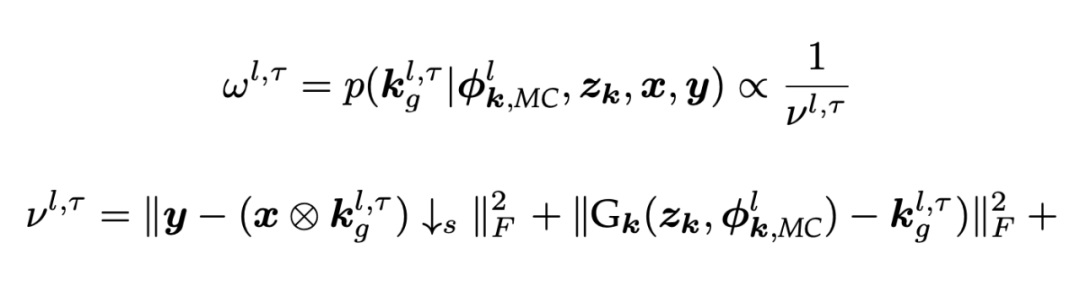
随机采样的核由 加权, 由 LR 图像重建项以及第l次迭代时采样核和近似核的 MSE 组成。因此,我们认为随机采样的核被分布在最小化 LR 图像重建误差的核附近,新的采样将优先发生在最后采样核的附近。
LR 图像重建误差促使随机采样的核实现后验分布,而 MSE 在核 PSNR 的急剧变化和获得的合理模糊核的稳定收敛之间取得平衡。
与经典 MCMC 方法不同,该方法并非使用极大的采样数 T 在 的整个范围内进行穷举采样,而是在一个 MCKA 阶段中仅随机采样少数实现。在马尔可夫链转换对采样核进行重新加权后,将获得的集成核 应用于优化参数 ,该近似优化可表示为:
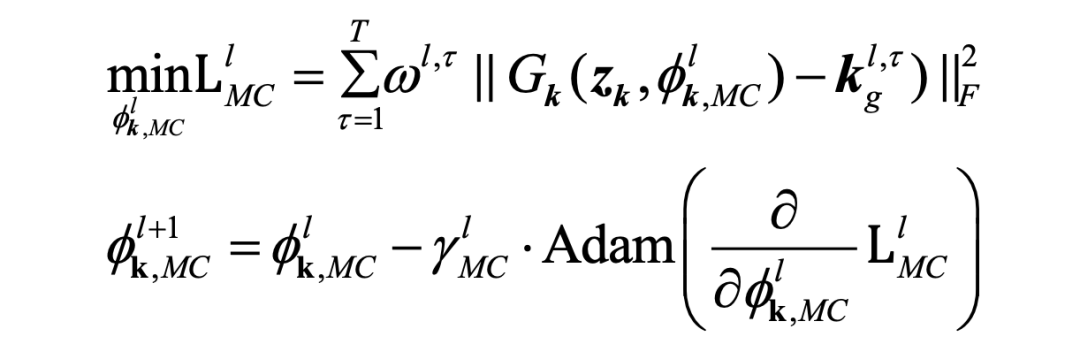
MCKA 过程用于解决盲 SISR 问题有两个主要贡献。一方面,MCMC 采样为模糊核估计提供了松散但合理的核先验,而不需要预训练和标记数据,实现了“即插即用”。
另一方面,MCKA 过程会定期对参数 的收敛带来随机扰动,这些参数 会针对 MLAO 阶段中的 LR 图像重建误差损失进行交替优化,可以防止参数 的优化由于内在的非凸性和不适定性而收敛到不良局部模式。
2.3 网络级朗之万动力学
为了提高基于梯度下降的变量更新优化算法的性能,我们提出了基于网络的朗之万动力学表达式:
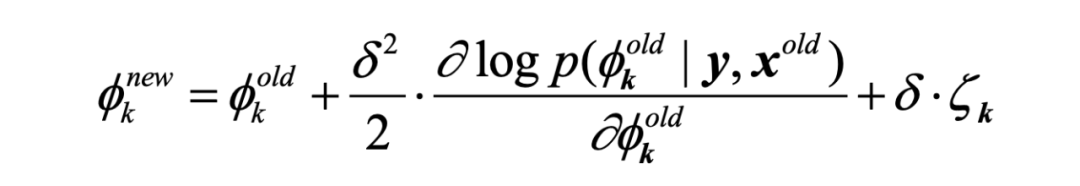
其中第二项表示数据一致性更新项,第三项表示 随机先验更新项。与经典的 Langevin 更新式的主要区别在于,我们这里利用的是随机样本而不是随机噪声。
这样适配网络参数更新,不仅保留了原本的随机扰动,防止更新陷入局部最优,同时随机采样得到的模糊核同样也能提供合理的随机数据先验,保证了模糊核估计的性能。
2.4 基于元学习的交替优化策略
传统基于 AM 的方式在核估计和图像恢复两个子问题之间通过网络交替估计 HR 图像 和模糊核 。然而每个子问题的中间解通常包含显著的噪声,并且仅使用一阶信息对每个子问题进行最小化行为从全局收敛的角度来看不一定会产生良性解。
因此,我们设计了一种基于元学习的交替优化策略,称为 MLAO 过程,用于从观察到的 LR 图像 中优化 和 。
在第 p 次迭代中,LR 图像重建误差 可以表示为:
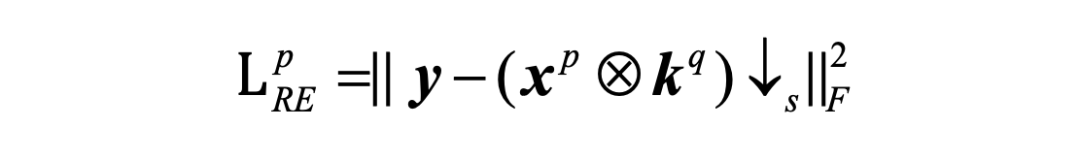
我们不是最小化 而穷举地优化每个子问题,而是将 P 次迭代中图像重建误差 累积起来作为元学习损失,来更新参数 Q 次。
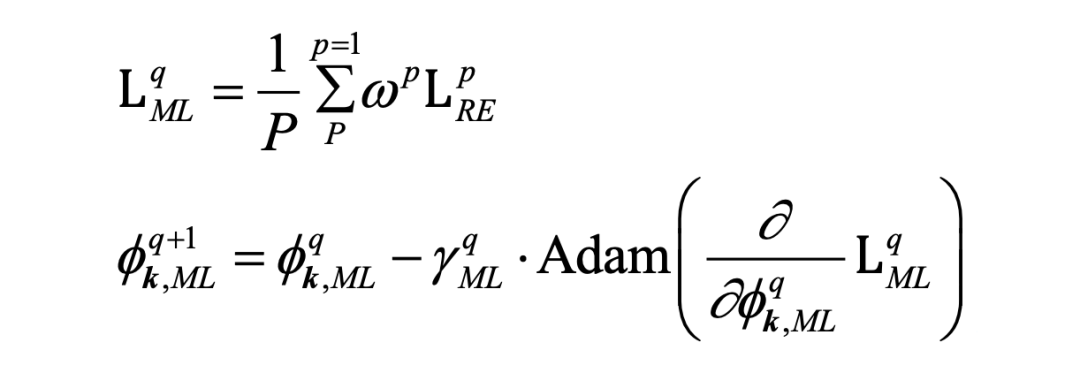
这种优化策略贪婪程度较低但适应性更强,通过全局学习优化策略在迭代过程中对部分重建误差轨迹的相互知识,穷尽地优化每个单独的子问题实现。模糊核估计的优化策略就被赋予了一种松弛,这允许在估计迭代期间在第 p 次子问题中对 有非最优解,但从 P 次迭代的角度来看,它能够收敛到更好的最优解。
在每次迭代中,图像重建器 通常易受图像噪声影响,从而导致过度拟合到不良的局部最优值。因此,我们设计了一种基于超拉普拉斯图像先验对图像重建子问题进行最优求解的方法来更新参数 ,首先为基础退化模型制定了一个独立同分加性高斯白噪声 (AWGN) 模型:
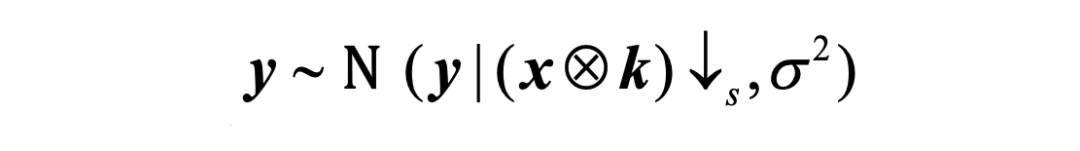
超拉普拉斯先验被用来约束估计的 HR 图像的 AWGN:
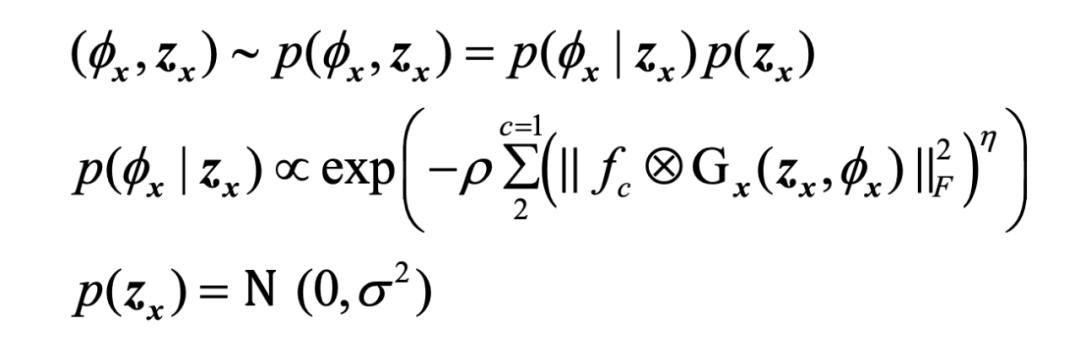
图像估计器的参数 通过损失函数进行优化:
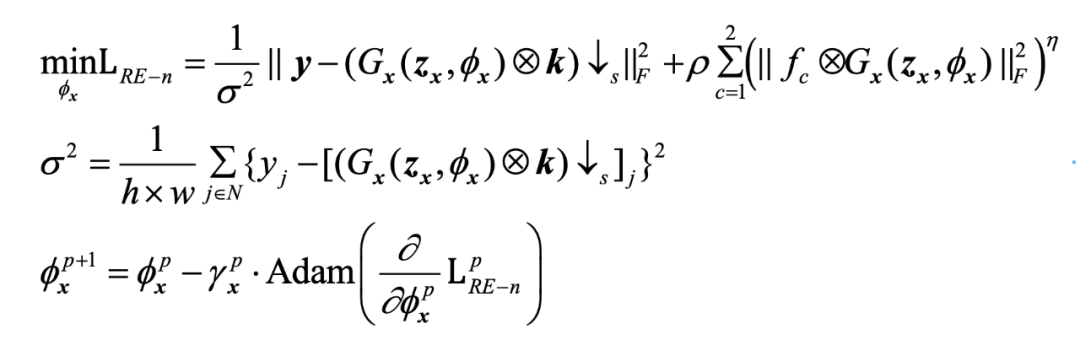

实验
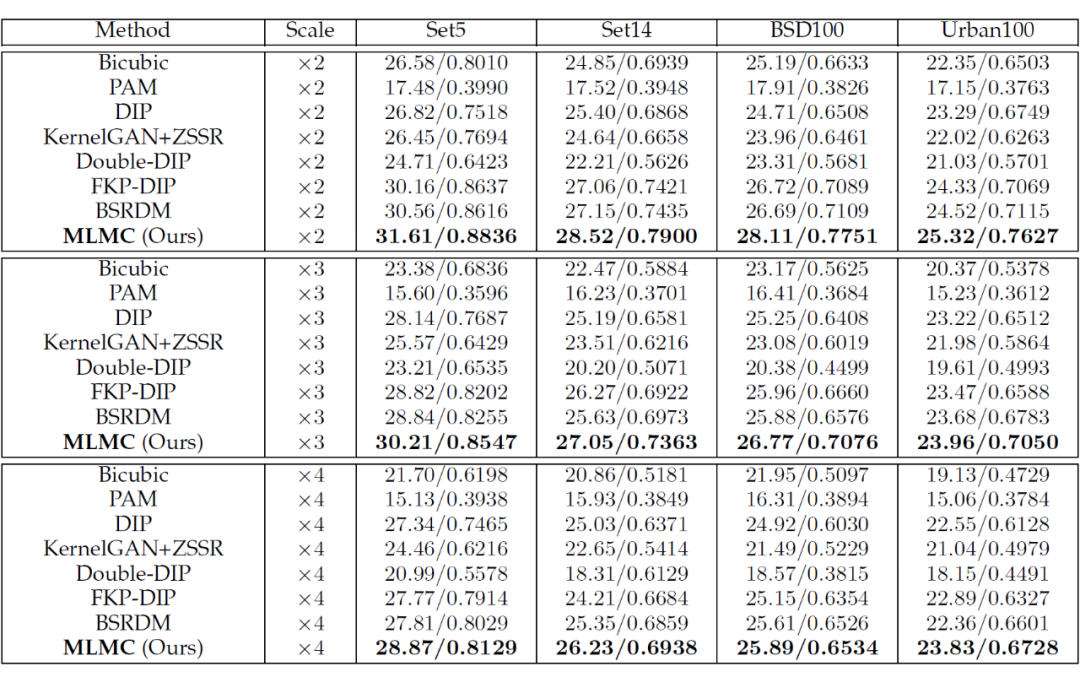
实验设定:我们在各向异性高斯核上进行了大部分实验,在非高斯核上如运动核进行了少量实验。我们使用随机核合成 LR 图像,在基于四个流行的公共基准数据集的测试数据上进行实验,包括 Set5、Set14、BSD100、Urban100 和真实世界数据集 RealSRSet。
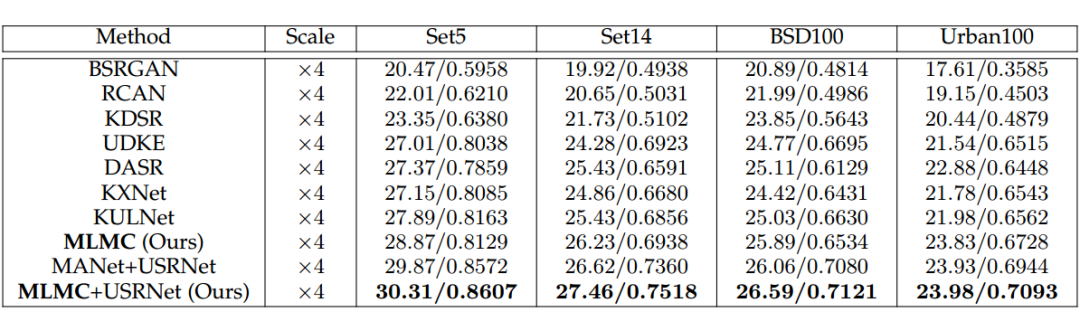
对比了无监督方法 PAM、DIP、KernelGAN+ZSSR、Double-DIP、FKP-DIP 和 BSRDM,以及基于深度学习的方法(模型在 LR-HR 配对数据集上进行了预训练):RCAN、DASR、BSRGAN、KDSR、KULNet、UDKE、KXNet,还使用基于 MANet 的核估计的非盲模型 USRNet 和我们的 MLMC作为两种基于深度学习的方法 MANet+USRNet 和 MLMC+USRNet 进行对比。
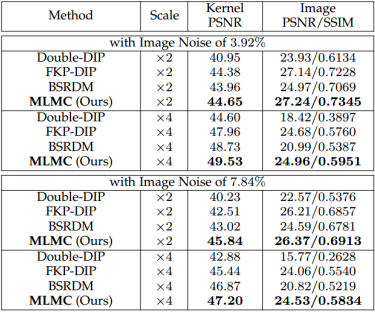
性能分析:所提出的 MLMC 方法在性能指标和可视化效果都取得了相较于其它无监督方法展现出更优异的性能,在核估计结果方面明显优无监督方法 BSRDM,BSRDM 通过对高斯分布的显式建模遵循基于梯度的核估计,而 MLMC 通过网络级朗之万动态以从随机核先验中学习以获得更好的收敛性能。
同时,MLMC 超越了大多数基于深度学习的监督方法,其性能与 KULNet 相当,仅次于 MANet+USRNe,当无监督 MLMC 与预训练图像估计器 USRNet 一起使用时,所提出的 MLMC+USRnet 能够实现比有监督 MANet+USRNet 略好的性能。
在可视化效果上,MLMC 获得了最简洁的模糊核以及恢复的 HR 图像,几乎与原图像保持一致,而 FKP-DIP 和 BSRDM 在估计的核上表现出不同程度的失真,Double-DIP 无法估计合理的模糊核。
尤其对于真实图像测试结果表明,除 MLMC 之外的所有方法都估计出一个类似高斯的模糊核,而 MLMC 倾向于找到一种非高斯模式,从替代蒙特卡洛模拟中学习到了一种自适应和灵活的核估计原理,因此更适合真实世界的应用。


我们将这些方使用不同的核先验如分布外的核和运动核进行测试,以进一步评估所提出的 MLMC 方法的泛化能力,MLMC 的表现明显优于 Double-DIP、BSRDM 和 FKP-DIP。
由于高度依赖预先训练的核先验,这些方法都存在问题,而 MLMC 仍然表现出优异的性能。即使没有特定的核先验,MLMC 对任意核都具有出色的泛化能力,并且对未见过的核和非高斯核也表现出优异的鲁棒性。
同时,MLMC 可以直接用于解决运动核任务,而无需重新训练验证了 MLMC 对复杂的退化核具有更好的泛化能力。

我们在模糊和下采样后将图像噪声添加到 LR 图像中,MLMC 在所有情况下都表现出优异的恢复性能,并且对不同程度的图像噪声表现出良好的鲁棒性。
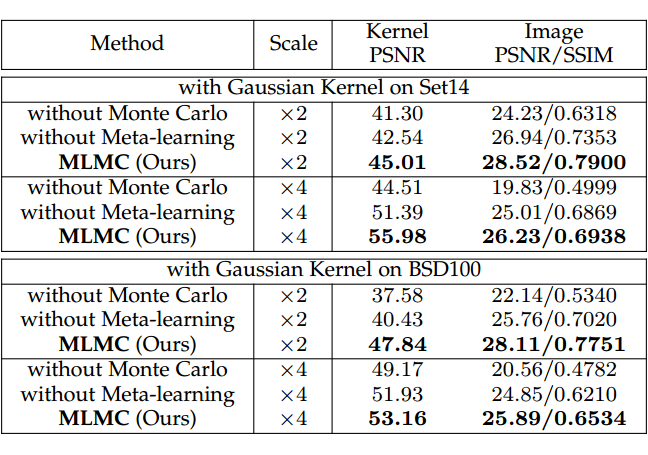
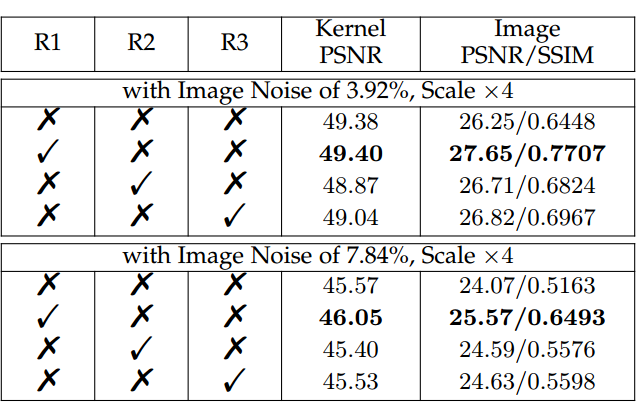
此外,我们通过三个消融实验验证了引入的蒙特卡罗采样核估计和元学习 SISR 阶段的有效性。下图展示了现实世界图像上的消融可视化,与 MLMC 相比,没有蒙特卡罗采样的估计核的 PSNR 下降较多,并且图像失真明显。同时,没有元学习方案会导致优化过程中出现明显的可见偏差,估计的核很容易收敛到局部最优,导致核估计和图像恢复性能不佳。
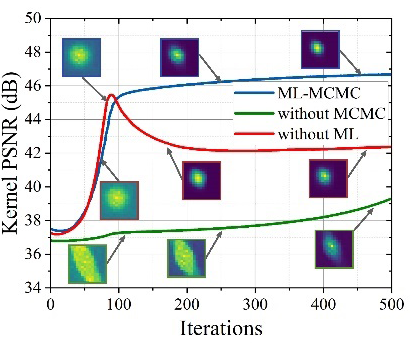

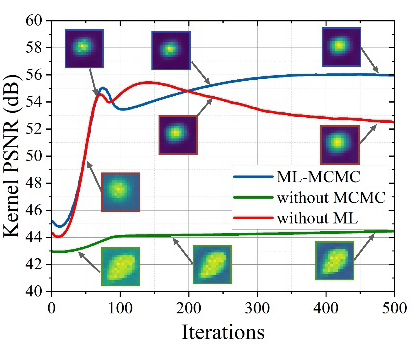
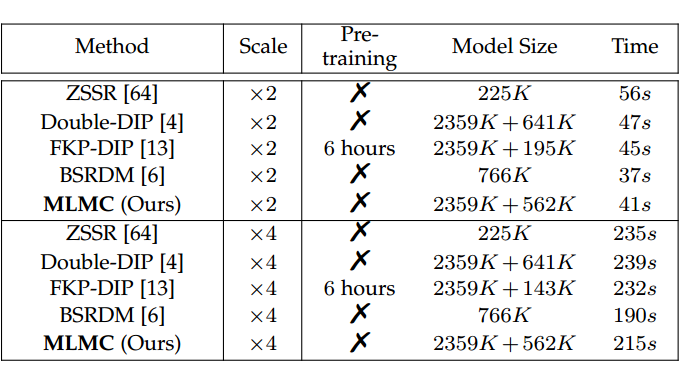
在模型大小(参数数量)、运行时间和预训练要求方面,MLMC 具有与其他方法相似的模型大小,并且具有有竞争力的运行时间。所有模拟过程均由 GeForce RTX 3090 GPU 加速,输入 LR 图像的大小为 256×256,比例因子 s=2、3、4。
MLMC 用于生成 1024 × 10 24 大小的 HR 图像的 GPU 大约需要 11GB 内存,接近 Double-DIP(11.2GB)和 DIP-FKP(10.6GB)。这种即插即用的方式和对未知退化的更好灵活性在处理具有真实场景的盲 SR 任务方面具有显著的优势,尤其是那些面对训练数据质量低和复杂模糊的场景,例如太空高速目标(例如卫星、飞机)和医学图像(例如跳动的心脏)。

总结
在本文中,我们提出了一种新的基于学习的盲 SISR 方法,该方法结合了马尔可夫链蒙特卡罗模拟和元学习训练以实现卓越的核估计,值得注意的是所提出的方法不需要任何监督预训练或参数先验。我们主要有以下创新点:
提出了一种基于网络的退化模型的通用统计框架,以阐述基于网络的 SISR 问题方法。在此基础上,建立了一个基于随机高斯分布的 MCMC 模拟模型,并考虑了 LR 图像重建误差,以阐述新的核估计阶段。
与常用的预训练或手动设计的核先验不同,随机核学习方案取代了普通核先验,实现了基于学习但即插即用的核先验生成范式,并有助于实现通用的网络级朗之万动力学优化以改善收敛。
构建了一种基于元学习的自适应策略来解决盲 SISR 问题。它学习以不太贪婪的优化策略优化非凸和不适定的盲 SISR 问题,从而确保在仅依赖于观察到的 LR 图像时更好地收敛到地面实况。在未来的工作中,我们将研究 MLMC 方法的两个主要应用方向,包括:
扩展到更多退化模型,例如压缩伪影、去雨和阴影去除,以提高泛化能力。
应用更先进的预训练 SR 模型,例如 USRNet 和 Diffusion 模型,发挥核先验学习模块的作用,以提高性能。
MLMC 是一个基于学习但即插即用的 SISR 方法,可以直接应用于常见的核估计任务,包括各向同性和各向异性的高斯、非高斯和运动核,与最先进的方法相比,具有具有竞争力的参数数量、运行时间和内存使用量,以及对噪声的鲁棒性。
这种从随机性中学习以提供先验和基于元学习的非凸优化算法,将引领解决盲图像恢复任务的新方向,以有限的计算复杂度实现卓越的性能。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









