








TL;DR:本研究提出了一种新的语法纠错系统评估指标,能够根据评估句子类型不同,动态调整子指标的权重,确保评估分数更加符合人类反馈。

论文标题:
DSGram: Dynamic Weighting Sub-Metrics for Grammatical Error Correction in the Era of Large Language Models
作者单位:
北京大学(万小军团队)、北京交通大学
论文链接:
https://arxiv.org/abs/2412.12832
代码链接:
https://github.com/jxtse/GEC-Metrics-DSGram
Highlights
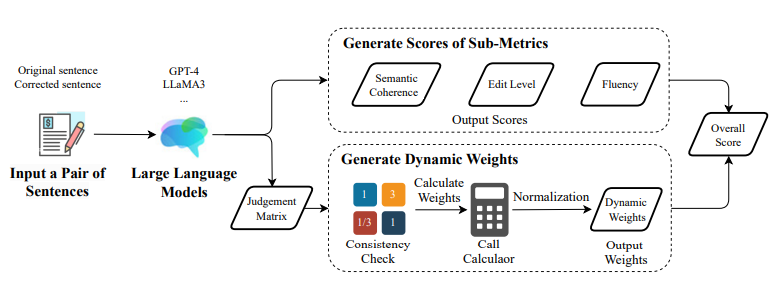
提出了 DSGram 这一创新的评估框架,它通过动态调整子指标的权重,提供了更为精准的评估方法。
整合了语义一致性、编辑水平和流畅性三个关键评价维度,确保评估结果更加符合人类反馈。
开发了两个新数据集,DSGram-Eval 和 DSGram-LLMs,用于模拟人类评分来验证和微调算法。

背景简介
语法纠错(Grammatical Error Correction, GEC)模型旨在自动纠正自然语言文本中的语法错误,提升书面内容的质量和准确性。传统上,GEC 模型的评估运用了多种指标,这些指标可以分为需要参考文本的(reference-based)和不需要参考文本的(reference-free)两类。
基于参考的评估指标,如 BLEU、ERRANT 和 M²,通过将模型生成的文本与正确的参考文本进行比较来评估语法纠正的准确性,并且在这一领域得到了广泛的应用。
尽管这些指标很有用,但它们存在固有的局限性。例如,黄金参考答案(golden reference)可能无法涵盖所有可能的纠正方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









