








随着多模态大模型(Large Multimodal Models, LMMs)的快速发展,其在语言、视觉等多领域展现出强大的理解能力。然而,近期 o1, R1, o3-mini 等推理模型的出现不禁使人好奇:最先进的 LMMs 是否也和 R1 一样具备类似人类的推理能力?
为了回答这一问题,腾讯 Hunyuan 团队提出了一个新的多模态推理基准测试框架——MM-IQ,旨在系统地评估多模态模型的抽象推理和逻辑思维能力。

论文标题:
MM-IQ: Benchmarking Human-Like Abstraction and Reasoning in Multimodal Models
论文地址:
https://arxiv.org/pdf/2502.00698
代码仓库:
https://github.com/AceCHQ/MMIQ/tree/main/
项目主页:
https://acechq.github.io/MMIQ-benchmark/
数据集地址:
https://huggingface.co/datasets/huanqia/MM-IQ
效果展示
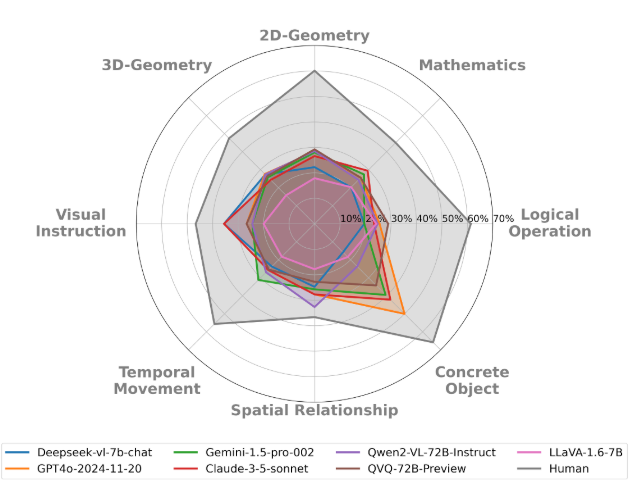
▲ 图1.1:多模态模型以及人类在 MM-IQ 基准测试中的表现
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









