







本文由香港城市大学联合华为诺亚方舟实验室,香港科技大学(广州)等机构合作完成。该工作录用于 ICLR 2025,并且入选 Spotlight(8886)。

论文背景
大型语言模型(LLMs)近年来在多个领域取得了显著的进展,展现出卓越的性能。然而,由于 LLMs 的训练依赖于多种数据源、模型架构和训练方法,它们在不同任务中展现出各自的优势和劣势。某些 LLMs 在理解和生成长文本方面表现突出,而另一些则可能在特定领域的知识获取上更为精确。
因此,单靠从零开始训练一个 LLM 并不能满足所有需求。在这种背景下,创建一个 LLM 集成的方案成为了一个有效的替代方法 [1]。这种集成方法通过结合多个 LLMs 的优点,可以更充分地发挥各个模型的互补优势,从而提高整体的任务性能。
现有的 LLM 集成方法 [2][3],面临两个重大挑战。首先,这些方法仅关注集成技术,忽视了哪些类型的模型可以有效结合的重要讨论。这一疏忽至关重要,因为在架构、规模和分词器上存在显著差异的 LLMs 可能本质上不兼容,从而导致潜在的不兼容性,削弱集成的优势。
其次,这些方法倾向于在每个生成步骤中对整个词汇表的概率进行对齐。这种策略在推理过程中引入了大量的计算开销,从而影响了性能和效率。
我们通过深入分析影响 LLM 集成性能的关键因素,提出了 UniTE 方法,显著提高了集成效率和性能,超越了现有的最先进方法。

论文标题:
Determine-Then-Ensemble: Necessity of Top-k Union for Large Language Model Ensembling
论文链接:
https://arxiv.org/pdf/2410.03777
代码链接:
https://github.com/starrYYxuan/UniTE

集成因素分析
模型融合作为提升性能的有效策略,其效果受多种因素影响,如模型性能、响应过程和词汇冗余等。因此,研究这些关键因素对模型融合性能的影响至关重要。哪些因素对模型融合的性能有着重要影响呢?
我们对真正影响集成性能的因素进行了深入调查。我们的实证分析确定了三个关键因素:模型性能、词汇大小和响应过程。我们在多个公认的基准测试中评估了多种 LLM,以从这些角度探索集成。我们的发现揭示了几个重要见解:
1)基础 LLM 之间性能水平的差异显著影响它们的集成兼容性;
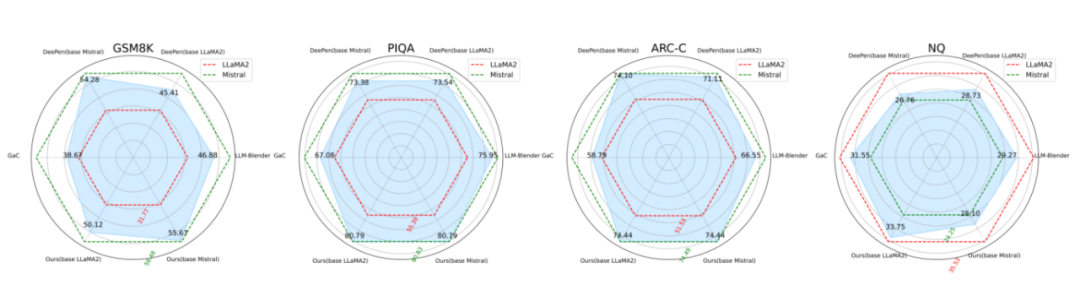
▲ 图1:模型基础性能对融合的影响
为了研究性能差异对模型集成的影响,我们选择了 LLaMA2-13B 和 Mistral-7B 作为基础模型,这两个模型在多个任务中表现出显著的性能差距。我们使用三种比较方法评估了 GSM8K、PIQA、ARC-C 和 NQ 数据集。显而易见,性能差距较大的模型不适合集成。
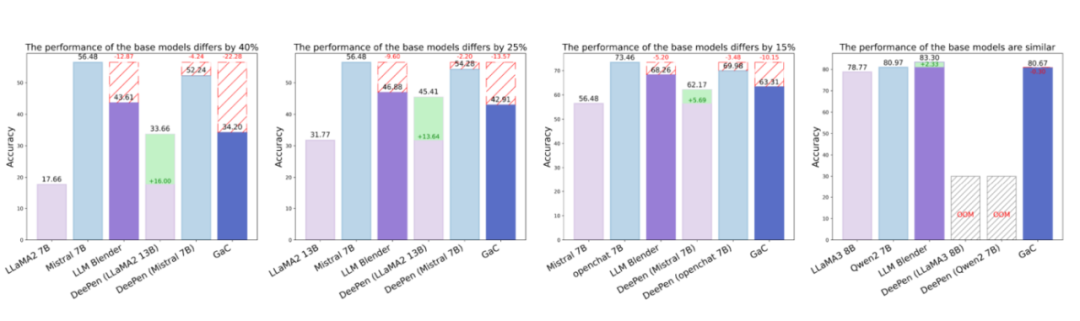
▲ 图2:性能差异对 GSM8K 数据集上模型集成效果的影响
为了进一步了解性能差异如何影响集成,我们根据 GSM8K 数据集确定了模型对,性能差距约为 40%、25%、15% 以及低于 10%。
图 2 显示,随着性能差距的增加,来自劣势模型的集成改进变得更加明显。相反,对于优势模型,集成效果始终低于基准性能。当性能差异在 10% 以内时,集成可能会产生更好的结果。
2)词汇大小的影响有限:
采用不同分词方法(如 BPE 和 BBPE)的较大模型在对牛津 5000 个常用词进行分词时,显示出超过 90% 的重叠。这表明分词方法对模型集成的影响有限,因此我们将重点放在词汇大小对集成性能的影响上。
为此,我们选择了四个在某些数据集上表现相似但词汇表大小不同的模型,即 LLaMA2-13B(词汇大小:32,000)、Mistral-7B(词汇大小:32,768)、Yi-6B(词汇大小:64,000)和 DeepSeek-LLM-7B(词汇大小:102,400)。
▲ 表1:词表大小模型集成效果的影响
从上表可知,词汇表大小对模型集成的影响很小。
3)即使在性能和词汇大小上达成一致,响应中的推理过程存在重大差异也可能阻碍成功的集成。

▲ 表2:回复方式的显著差异或将造成集成失效
如表 2 所示,在相同的提示条件下,LLaMA3 倾向于直接返回答案,而 Qwen2 则倾向于进行分析。响应长度显著影响判断。在我们对 100 个随机选择的 NQ 和 TriviaQA 响应的分析中,Blender 在约 80% 和 70% 的情况下分别将较长的响应作为答案,这可能与其训练数据的特征有关。
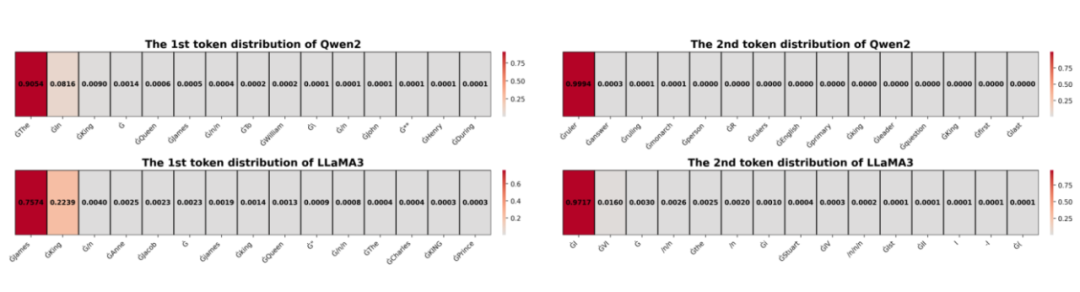
▲ 图3:不同模型的词概率分布
图 3 显示 LLaMA3 和 Qwen2 在前两个 token 的概率分布存在明显差异。直接对概率进行平均可能导致分布过于平滑,这并不合适。这一现象的根本原因可能是 LLM 训练数据的差异。因此,在特定任务中需谨慎。
综上,我们提出了一种策略,通过比较模型在目标任务上的表现和响应风格,评估其集成兼容性,并指导从候选模型池中选择基础模型。理想情况下,性能差距应在 10% 以内,且响应长度应合理匹配,以实现有效的集成。
除了模型选择策略,我们还努力提高模型集成的效率和性能。现有的概率级模型集成方法试图通过完全的词汇对齐来组合模型。
我们认为这种方法并不理想,因为候选下一个 token 通常位于前 k 个 token 中。相反,纳入概率较低的 token 可能会引入不必要的噪声,从而降低集成的整体准确性和有效性。
基于此,我们提出了 Union Top-k Ensembling(UniTE),一种新颖且高效的集成方法,仅在每次解码步骤中对齐前 K 个 token。


UNITE 的具体实现
给定一组基础模型(LLMs),每个模型都有独立的分词器和词汇表。对于输入的文本提示,每个模型生成一个概率分布,表示下一个可能的词元及其概率。
1. Top-k 候选词元提取:提取每个模型概率分布中前 k 个最高概率的词元,并记录其概率。
2. 联合集合构建与对齐:将所有模型的 Top-k 词元合并成一个联合集合,并根据以下规则更新概率分布:
如果词元同时在联合集合和某模型的 Top-k 中,则保留其原始概率。
如果词元在联合集合中但不在某模型的 Top-k 中且在该模型词汇表中,则添加并更新其概率。
如果词元不在某模型的词汇表中,则用该模型的分词器对其分词,并更新 Top-k 词元。
3. 概率聚合与下一步预测:对更新后的 Top-k 词元进行归一化处理,计算所有模型的平均概率。然后,使用贪婪策略从联合集合中选择下一个词元,添加到输入文本中,重复此过程直到满足停止条件。

实验结果
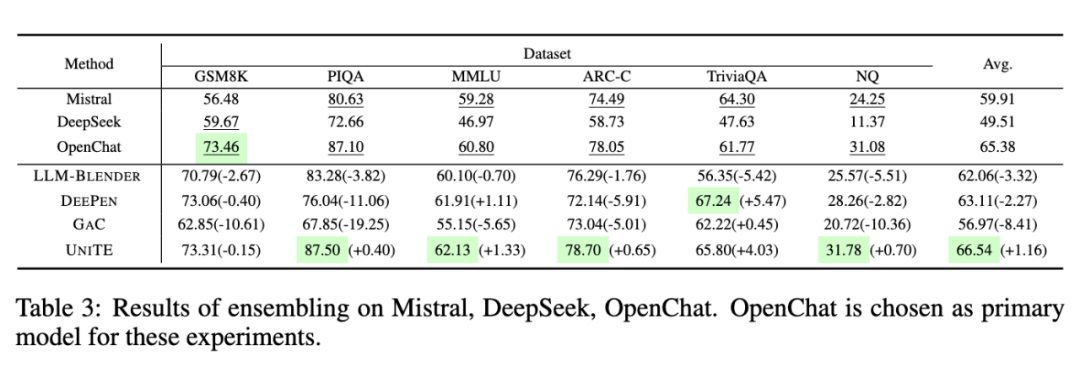
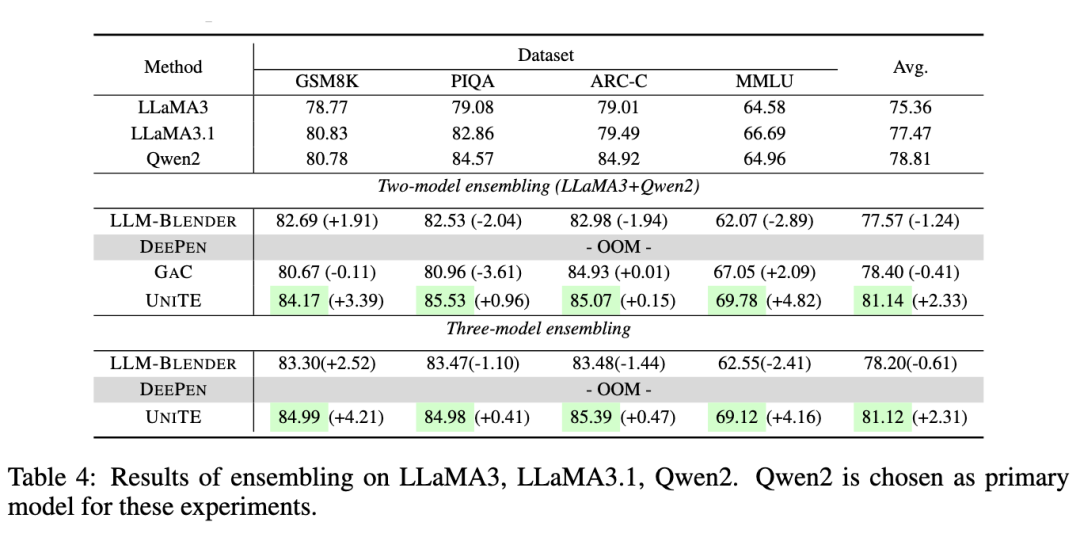
我们的实验使用了多种常用模型,包括 LLaMA2 和 LLaMA3 系列、Mistral、DeepSeek、Yi、OpenChat 以及 Qwen 等。评价基准分为三类:综合理解、推理能力以及知识能力。
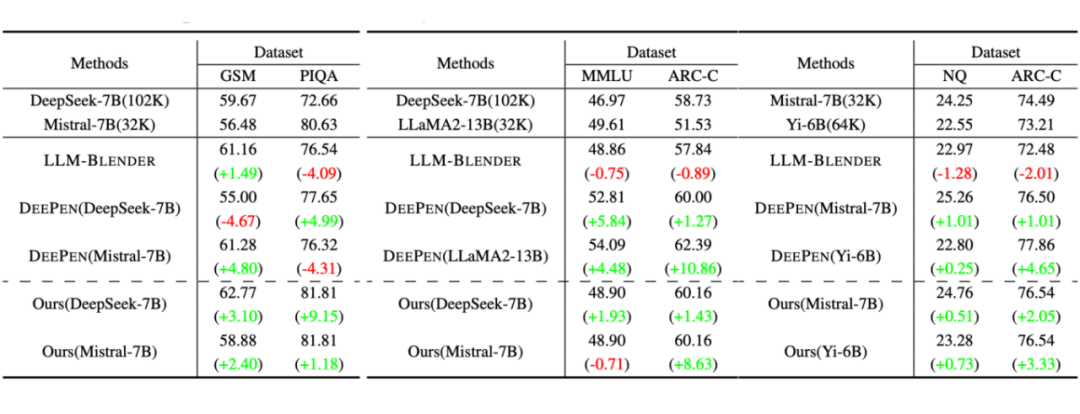
如上表所示:
(1)UNITE 在基础模型性能相似时提升了表现:OpenChat 的集成平均提高约 1.2%。然而,GSM8K 任务中 DeepSeek 与 OpenChat 的 15% 性能差距导致整体性能略降,验证了模型性能紧密对齐时集成效果最佳。
(2)UNITE 展现出更强的鲁棒性:尽管 LLM-BLENDER 在 GSM8K 上表现提升,但在 PIQA、ARC-C 和 MMLU 中明显低于基线模型。相比之下,UNITE 在大多数任务中实现了最高性能提升。
(3)与性能相似 LLM 的合作不一定带来更好结果:尽管整合 LLaMA3.1 在GSM8K 和 ARC-C 上有所提高,但在 PIQA 和 MMLU 上表现不佳,说明结合相似性能模型的提升并非必然。
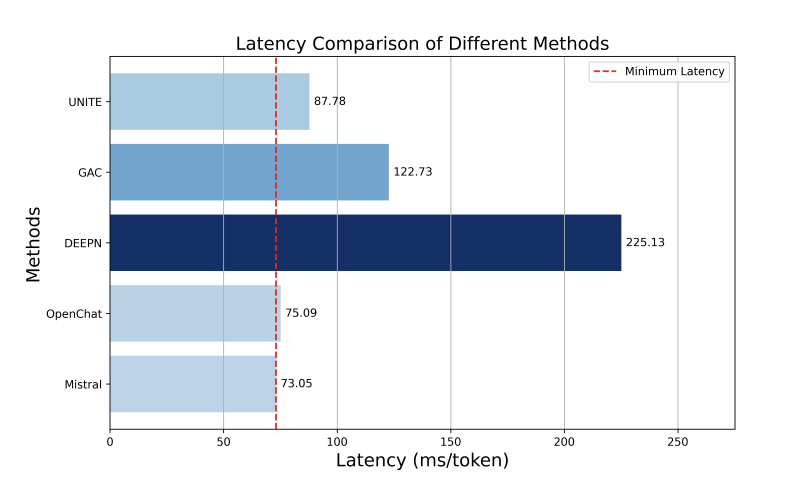
此外,我们还进行了时延分析,发现 UniTE 的延迟为 87.78 毫秒/词元,显著低于其他方法的延迟,仅比单个模型的延迟长约 10 毫秒。

总结
1. 我们的研究强调了集成方法在提升 LLMs 性能方面的有效性。
2. 通过对现有技术的研究,我们识别了影响集成成功的关键因素,如模型性能和响应过程,同时发现词汇大小的影响较小。
3. 我们提出了 UNITE,它能够高效地聚合来自多个 LLMs 的词元,而无需计算开销。通过广泛的实验,UNITE 持续超越最先进的集成方法,证明了其在利用不同 LLMs 优势方面的有效性。我们的贡献不仅推动了对模型集成的理解,还提供了选择和整合 LLMs 以实现更优性能的实用框架。

参考文献
[1] Merge, Ensemble, and Cooperate! A Survey on Collaborative Strategies in the Era of Large Language Models. Arxiv 2024
[2]Ensemble Learning for Heterogeneous Large Language Models with Deep Parallel Collaboration. Neurips 2024
[3]Breaking the Ceiling of the LLM Community by Treating Token Generation as a Classification for Ensembling. EMNLP 2024
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









