







一、安装
1. JDK1.8.0_144
解压:tar -zxvf jdk.tar.gz -C /usr/local/
配置:vim /etc/profile
#my srttings
export JAVA_HOME= /usr/java/jdk1.8.0_144
export PATE=$PATH:$JAVA_HOME/bin:
source /etc/profile
错误:source /etc/profile -提示找不到命令
试试:A)locate source /etc/profile
试试:B)usr/bin/source /etc/profile
2. Zookeeper 3.4.6
下载地址:http://mirror.bit.edu.cn/apache/zookeeper/
解压:tar -zxvf ./AppPackage/zookeeper-3.4.6.tar.gz ./
创建zoo.cfg
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-3.4.6/data
dataLogDir=/usr/local/zookeeper-3.4.6/logs
clientPort=2181
配置环境变量
3. hadoop 3.1.2
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
解压:tar -zxvf hadoop-3.1.2.tar.gz
二、设置配置文件
1. vim hadoop-env.sh
修改 JAVA_HOME参数:vim hadoop-env.sh
#The java implementation to use. By default, this environment
#variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/java/jdk1.8.0_144
2. vim core-site.xml
在configuration中添加各配置项:vim core-site.xml,
1)配置默认采用的文件系统。
由于存储层和运算层松耦合,要为它们指定使用hadoop原生的分布式文件系统hdfs。value填入的是uri,参数是分布式集群中主节点的地址: 指定端口号
<property>
<name>fs.defaultFS</name>
<value>hdfs://ZHT3:9000/</value>
</property>
2)配置hadoop的公共目录
指定hadoop进程运行中产生的数据存放的工作目录,NameNode、DataNode等就在本地工作目录下建子目录存放数据。但事实上在生产系统里,NameNode、DataNode等进程都应单独配置目录,而且配置的应该是磁盘挂载点,以方便挂载更多的磁盘扩展容量。
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.1.2/data/</value>
</property>
3. vim hdfs-site.xml
配置hdfs的副本数:vim hdfs-site.xml
客户端将文件存到hdfs的时候,会存放在多个副本。value一般指定3,但因为搭建的是伪分布式就只有一台机器,所以只能写1。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4. vim mapred-site.xml
指定MapReduce程序应该放在哪个资源调度集群上运行。若不指定为yarn,那么MapReduce程序就只会在本地运行而非在整个集群中运行。
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5. vim yarn-site.xml
vim yarn-site.xml,要配置的参数有2个:
1)指定yarn集群中的老大(就是本机)
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ZHT3</value>
</property>
2)配置yarn集群中的重节点,指定map产生的中间结果传递给reduce采用的机制是shuffle
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
三、配置环境变量PATH
vim /etc/profile
加入以及修改PATH,追加参数
export HADOOP_HOME=/usr/local/hadoop-3.1.2
export CLASSPATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
然后记得 source /etc/profile
错误:source /etc/profile -提示找不到命令
试试:A)locate source /etc/profile
试试:B)usr/bin/source /etc/profile
四、SSH免密码登录
通过$:ssh localhost命令查看是否需要密码,如果需要执行以下命令:
[root@centos hadoop]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
[root@centos hadoop]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@centos hadoop]# chmod 0600 ~/.ssh/authorized_keys
ERROR:
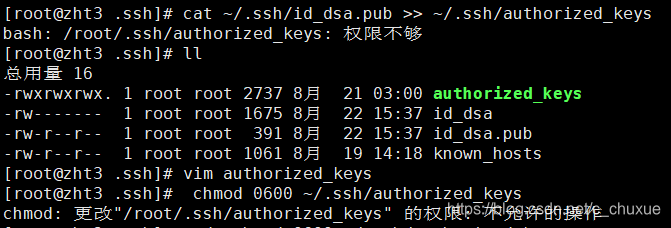
解决:
chattr可以防止关键文件被修改
在linux下,有些配置文件是不允许任何人包括root修改的,为了防止被误删除或修改,可以设定该文件的"不可修改位(immutable)"。
chattr +i authorized_keys
如果需要修改文件则:
chattr -i authorized_keys
以后再修改文件。
五、启动
1. 初始化/格式化namenode
注:以后如需格式化需要删除core-site.xml里面hadoop.tmp.dir配置,即hadoop的公共目录
hadoop namenode –format
2. 启停服务
全启停:
start-all.sh
stop-all.sh
模块启动:
start-dfs.sh
start-yarn.sh
stop-dfs.sh
stop-yarn.sh
单个hdfs模块中的进程启动:
hadoop-daemon.sh start/stop namenode/datanode/secondarynamenode
单个yarn模块中的进程启动:
yarn-daemon.sh start/stop resourcemanager/nodemanager
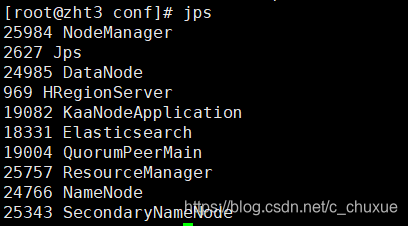
3. 然后输入jps 查看已成功启动的进程(5个):
HDFS:NameNode、DataNode、SeconderNameNode
YARN:ResourceManager、NodeManager
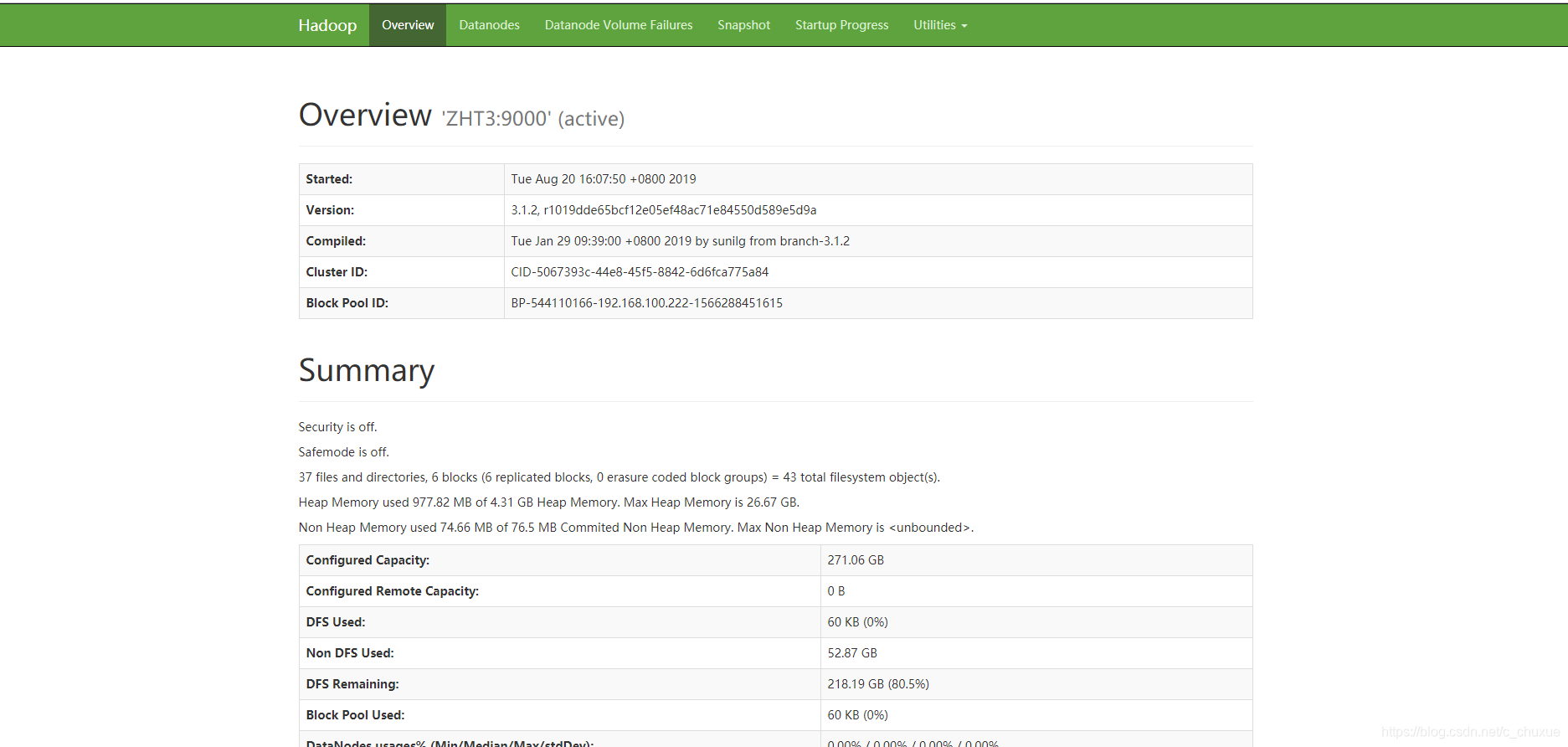
地址:http://192.168.0.110:9870
注:hadoop3.0以下版本web访问端口50070;3.0及以上web访问端口9870
其他命令:
host name hadoop01 //临时改变主机名
vi /etc/sysconfig/network //修改主机名,重启后生效
ifconfig //查看网卡信息
date // 时间
date -s "2018-01-01 12:12:12" //修改时间
vi /ect/hosts //映射
sudo firewall-cmd --state //查看防火墙状态
sudo systemctl stop firewalld.service //关闭防火墙
sudo systemctl disable firewalld.service //禁止开机时防火墙自启
echo "" > /var/log/kaa/kaa-node.log
telnet 192.168.0.110:9000
netstat -tlpn
netstat -apn | grep 3306
ERROR:
1.启动hadoop报错Attempting to operate on hdfs namenode as root
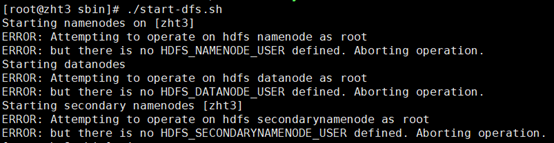
翻译: 尝试使用root 账户去操作hdfs namenode
造成原因:缺少用户定义
解决办法:
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
2.hdfs命令报错:core.site.xml not found
解释: 未能找到core.site.xml
造成原因:默认是个错误的路径所以会跳错
解决办法:
在环境变量 vim /etc/profile添加
export HADOOP_CONF_DIR=/usr/local/hadoop-3.1.2/etc/Hadoop
HADOOP_CONF_DIR 变量修改为自己的Hadoop目录(默认是个错误的路径所以会跳错)
记得source /etc/profile
ERROR:source /etc/profile -提示找不到命令
试试:A)locate source /etc/profile
试试:B)usr/bin/source /etc/profile














 1373
1373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









