






什么是哈夫曼树
计算机对数据进行存储通常采用等长码的形式,假如说每个字符计算机都用八位进行存储,一篇一万个字符的文章,总共就需要八万位来存储,但实际上,文章中每个字符出现的频率是不一样的,例如:字符e的出现频率就远大于字符x的出现频率,如果我们能够用更小的存储空间存储字符e,那么即使字符x占用的存储空间变大了,也可以起到提高空间利用率的效果。
那么对于已知频率不一样的字符,我们如何对他们进行编码呢?
在这之前,我们要先知道哈夫曼树是什么。

例如将百分之的考试成绩转换为五分制的成绩,我们可以生成一个判断树,对于这棵判定树,我们可以带入学生的成绩分布频率,得出平均查找次数,也就是查找效率。

我们可以对判定树进行修改以达到更小的平均查找次数
那么我们如何才能构造一棵平均查找次数最小的查找树呢?
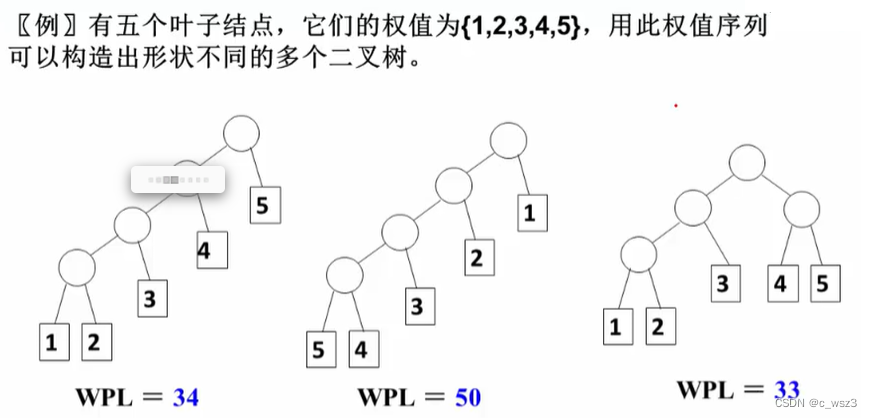
给出树的带权路径长度WPL,和哈夫曼树的定义。
结点的带权路径长度:树的根结点到该结点的路径长度和该结点权重的乘积
树的带权路径长度:在一棵树中,所有叶子结点的带权路径长度之和,被称为树的带权路径长度,也被简称为WPL。
哈夫曼树或者最优二叉树:WPL最小的二叉树。
在例子中,将每个成绩出现的频率看作叶节点的权值,那么我么计算的平均查找次数就是判定树的WPL值。
哈夫曼树的构造
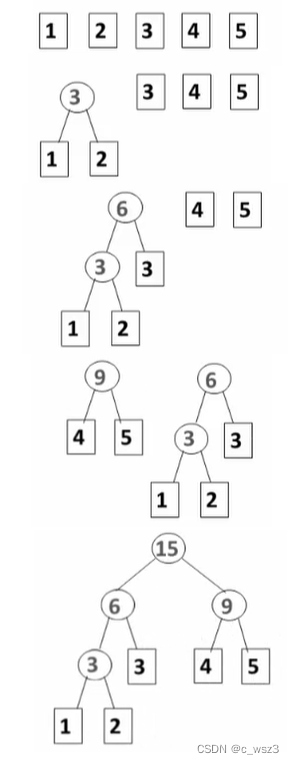
其实哈夫曼树的构造方法很简单,在上面的例子中,我们可以知道,如果我们将权值小的放在离根节点远的地方,权值大的放在离根节点近的地方,那么WPL(每个叶节点权值与其路径长度乘积之和)就会变小。
那么我们可以每次将权值最小的两棵二叉树合并。
例如对于序列1, 2, 3, 4, 5的哈夫曼树构造:
下面给出哈夫曼树构造的代码:
#include <stdio.h>
#include <stdlib.h>
#define MAX 10
#define MINDATA -1
typedef struct _TNode
{
int weight;
struct _TNode* left;
struct _TNode* right;
}TNode;
typedef TNode* HuffmanTree;
struct _MinHeap
{
TNode **data;
int size;
int capacity;
};
typedef struct _MinHeap* MinHeap;
//最小堆 函数开始
MinHeap minheap_creat(int size)
{
MinHeap heap = (MinHeap)malloc(sizeof(struct _MinHeap));
heap -> data = (TNode**)malloc(sizeof(TNode*) * (size + 1));
heap -> data[0] = (TNode*)malloc(sizeof(TNode));
heap -> data[0] -> weight = MINDATA;
heap -> data[0] -> left = NULL;
heap -> data[0] -> right = NULL;
heap -> size = 0;
heap -> capacity = size;
return heap;
}
int minheap_isfull(MinHeap heap)
{
return heap -> size == heap -> capacity;
}
int minheap_isempty(MinHeap heap)
{
return heap -> size == 0;
}
void minheap_insert(MinHeap heap, TNode* item)
{
if(minheap_isfull(heap))
{
printf("the heap is full\n");
return ;
}
int i;
for(i = ++heap -> size; heap -> data[i/2] -> weight > item -> weight; i /= 2)
heap -> data[i] = heap -> data[i/2];
heap -> data[i] = item;
}
TNode* minheap_delete(MinHeap heap)
{
if(minheap_isempty(heap))
{
printf("the heap is empty\n");
return NULL;
}
TNode* mindata = heap -> data[1];
TNode* temp = heap -> data[heap->size--];
int parent, child;
for(parent = 1; parent * 2 <= heap -> size; parent = child)
{
child = parent * 2;
if(child != heap -> size && heap -> data[child+1] -> weight < heap -> data[child] -> weight)
child++;
if(heap -> data[child] -> weight > temp -> weight)
break;
heap -> data[parent] = heap -> data[child];
}
heap -> data[parent] = temp;
return mindata;
}
//最小堆函数结束
//哈夫曼树构造
HuffmanTree huffmantree_built(MinHeap heap)
{
while(heap -> size > 1)
{
TNode* tn = (TNode*)malloc(sizeof(TNode));
tn -> left = minheap_delete(heap);
tn -> right = minheap_delete(heap);
tn -> weight = tn -> left -> weight + tn -> right -> weight;
minheap_insert(heap, tn);
}
return minheap_delete(heap);
}在哈夫曼构造代码中,我们先是传入了一个树的最小堆,在循环中先创建一个新的树节点,他的左右子树分别赋为堆中最小的两个元素,然后将新节点的权值赋为两子节点权值之和再插入最小堆中,如此反复直到最小堆中只有一个树节点,这个节点就是哈夫曼树的根节点。
哈夫曼树的特点:
没有度为1的节点
n个叶子节点的哈夫曼树共有2n-1个节点
(树中叶节点永远比度为2的节点多一个,n0-1=n2,又因为哈夫曼树没有度为1的节点)
哈夫曼树任意非叶节点的左右子树交换后仍是哈夫曼树。
对于一组权值,存在两棵不同构的哈夫曼树
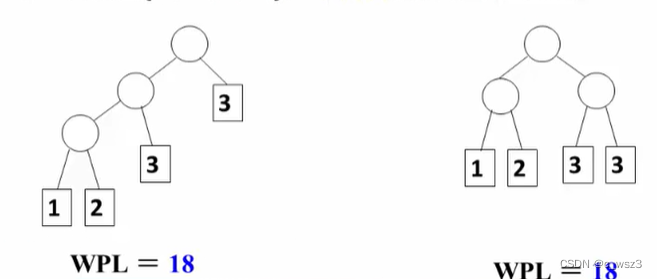
对于一组权值{1,2,3,3},有两棵不同构的哈夫曼树,但其WPL相等。
哈夫曼编码
回到最开始的问题,如何对字符串进行编码使得字符串编码存储空间最小。

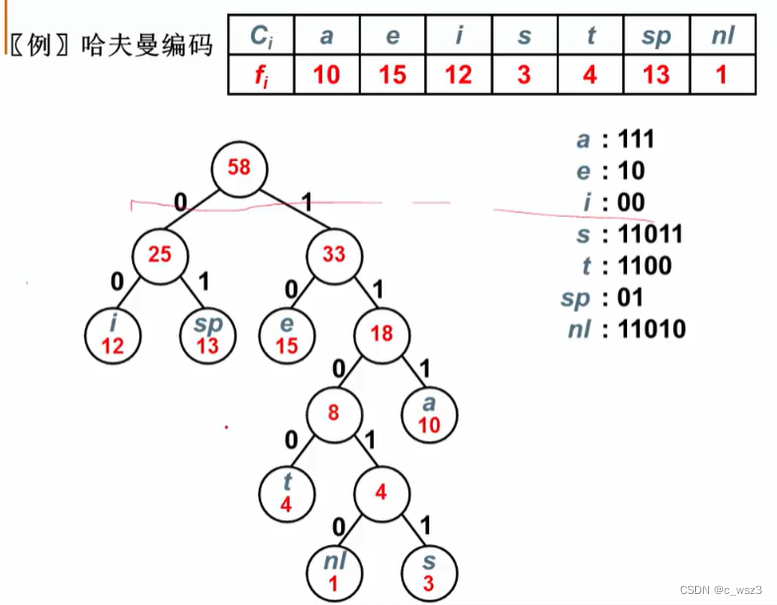
要是得存储空间最小的话,我们就要利用字符出现的频率来构建字符的不等长编码,但不等长编码还有一个问题如下图:
我们看到上面的编码出现了不同的解码结果,之所以会这样是因为在s,t,的编码中,包含了a,e,的编码,使得解码出现了二义性,为了避免这种情况,我们要采用前缀码:
前缀码:对某个字符集进行编码,要求字符集中任意字符的编码都不是其他字符的编码的前缀
要注意:虽然它叫前缀码,但它要求字符编码不是其他字符编码的前缀。
对于前缀码,我们可以用二叉树来构建,当然要确定两个规则
1:二叉树的左右分支编码为0,1(当然1,0也可以)
2:字符只出现在叶节点上。
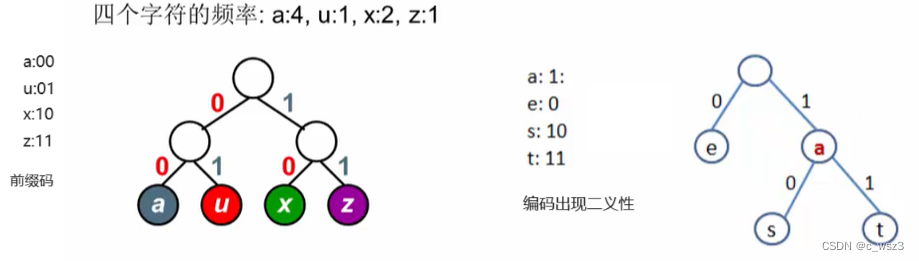
字符只在叶节点上,不会出现二义性 字符出现在不是叶节点的节点上,必然出现二义性
当然,知道了前缀码的实现方法,我们只要用上面的哈夫曼树来构建这样一棵二叉树,不就得到了每个字符的最优编码了吗。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define NUM 56
#define MAX 10000
#define MINDATA -1
typedef struct _TNode
{
int weight;
char data;
struct _TNode* left;
struct _TNode* right;
}TNode;
typedef TNode* HuffmanTree;
struct _MinHeap
{
TNode** data;
int size;
int capacity;
};
typedef struct _MinHeap* MinHeap;
MinHeap minheap_creat(int size)
{
MinHeap heap = (MinHeap)malloc(sizeof(struct _MinHeap));
heap -> data = (TNode**)malloc(sizeof(TNode*) * (size + 1));
heap -> data[0] = (TNode*)malloc(sizeof(TNode));
heap -> data[0] -> weight = MINDATA;
heap -> data[0] -> left = NULL;
heap -> data[0] -> right = NULL;
heap -> size = 0;
heap -> capacity = size;
return heap;
}
int minheap_isfull(MinHeap heap)
{
return heap -> size == heap -> capacity;
}
int minheap_isempty(MinHeap heap)
{
return heap -> size == 0;
}
void minheap_insert(MinHeap heap, TNode* tn)
{
if(minheap_isfull(heap))
{
printf("the heap is full\n");
return ;
}
int i;
for(i = ++heap -> size; heap -> data[i/2] -> weight > tn -> weight; i /= 2)
heap -> data[i] = heap -> data[i/2];
heap -> data[i] = tn;
}
TNode* minheap_delete(MinHeap heap)
{
if(minheap_isempty(heap))
{
printf("the heap is empty\n");
return NULL;
}
TNode* mindata = heap -> data[1];
TNode* temp = heap -> data[heap->size--];
int parent, child;
for(parent = 1; parent * 2 <= heap -> size; parent = child)
{
child = parent * 2;
if(child != heap -> size && heap -> data[child+1] -> weight < heap -> data[child] -> weight)
child++;
if(heap -> data[child] -> weight > temp -> weight)
break;
heap -> data[parent] = heap -> data[child];
}
heap -> data[parent] = temp;
return mindata;
}
HuffmanTree huffmantree_creat(MinHeap heap)
{
while(heap -> size > 1)
{
TNode* temp = (TNode*)malloc(sizeof(TNode));
temp -> left = minheap_delete(heap);
temp -> right = minheap_delete(heap);
temp -> weight = temp -> left -> weight + temp -> right -> weight;
temp -> data = 0;
minheap_insert(heap, temp);
}
return minheap_delete(heap);
}
char conversion(int n)
{
char ret = 0;
if(n >= 0 && n <= 25)
ret = n + 'a';
else if(n >= 26 && n <= 51)
ret = n - 26 + 'A';
else if(n == 52)
ret = ' ';
else if(n == 53)
ret = ',';
else if(n == 54)
ret = '.';
else
ret = -1;
return ret;
}
int inconversion(char ch)
{
int ret = 0;
if(ch >= 'a' && ch <= 'z')
ret = ch - 'a';
else if(ch >= 'A' && ch <= 'Z')
ret = ch - 'A' + 26;
else if(ch == ' ')
ret = 52;
else if(ch == ',')
ret = 53;
else if(ch == '.')
ret = 54;
else
ret = 55;
return ret;
}
void encode(char** code, char temp[], TNode* htree)
{
char* ttemp = (char*)malloc(sizeof(char) * 50);
strcpy(ttemp, temp);
if(htree -> left)
{
strcat(temp, "0");
encode(code, temp, htree -> left);
}
strcpy(temp, ttemp);
if(htree -> right)
{
strcat(temp, "1");
encode(code, temp, htree -> right);
}
free(ttemp);
if(htree -> left == NULL && htree -> right == NULL)
{
int n = inconversion(htree->data);
code[n] = (char*)malloc(sizeof(char) * 50);
strcpy(code[n], temp);
// printf("%s\n", temp);
}
}
void check(char** code, int letter[])
{
int i;
for(i = 0; i < NUM; i++)
{
if(!letter[i])
code[i] = NULL;
}
}
char** callback(TNode* htree, int letter[])
{
char **code = (char**)malloc(sizeof(char) * 50 * NUM);
char *temp = (char*)malloc(sizeof(char) * 50);
temp[0] = '\0';
encode(code, temp, htree);
free(temp);
check(code, letter);
return code;
}
int main()
{
int i;
char str[MAX];
int letter[NUM] = {0};
gets(str);
for(i = 0; i < strlen(str); i++)
{
letter[inconversion(str[i])]++;
}
for(i = 0; i < NUM; i++)
{
if(i != NUM - 1)
printf("%c %d\n", conversion(i), letter[i]);
else
printf("else %d\n", letter[i]);
}
MinHeap heap = minheap_creat(NUM);
for(i = 0; i < NUM; i++)
{
if(letter[i])
{
TNode* temp = (TNode*)malloc(sizeof(TNode));
temp -> left = NULL;
temp -> right = NULL;
temp -> weight = letter[i];
temp -> data = conversion(i);
minheap_insert(heap, temp);
}
}
HuffmanTree htree = huffmantree_creat(heap);
char** code = callback(htree, letter);
for(i = 0; i < NUM; i++)
{
if(code[i] && i != NUM - 1)
printf("%c %s\n", conversion(i), code[i]);
if(i == NUM - 1)
printf("else %s", code[i]);
}
return 0;
}这是我自己写的哈夫曼编码函数(编程能力比较差嘻嘻代码写的不够好)
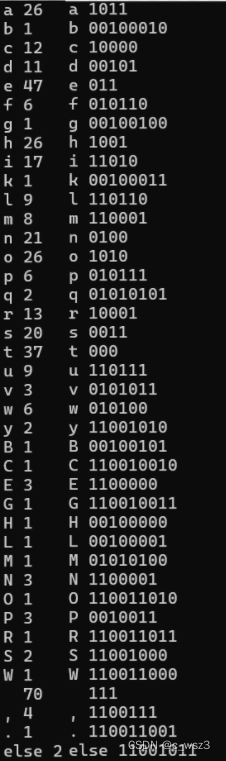
例如我们可以写入独立宣言的英语原文,就可以得到每个字符出现的次数已经据此得到的哈夫曼编码。(同时也可以看到字符e的出现次数是英文中出现最多的)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









