






目录
4.3@FeignClient注解中的FallbackClass和FallbackFactory的区别
服务如果因为各种原因而故障, 而我们要将这些故障控制在一定范围,避免全部服务器雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
一.线程隔离
调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。

1.1线程隔离的两种实现方式
-
信号量隔离(Sentinel默认采用):不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
-
线程池隔离(这里不过多介绍):给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果。
在Sentinel控制台里的簇点链路,选择自己的资源名,点击流控
-
QPS:就是每秒的请求数。
-
线程数:是该资源能使用用的tomcat线程数的最大值。也就是通过限制线程数量,实现线程隔离(信号量隔离)。

上图表示的是:给provide/user接口设置流控规则,线程数不能超过5。
二、熔断降级
是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。
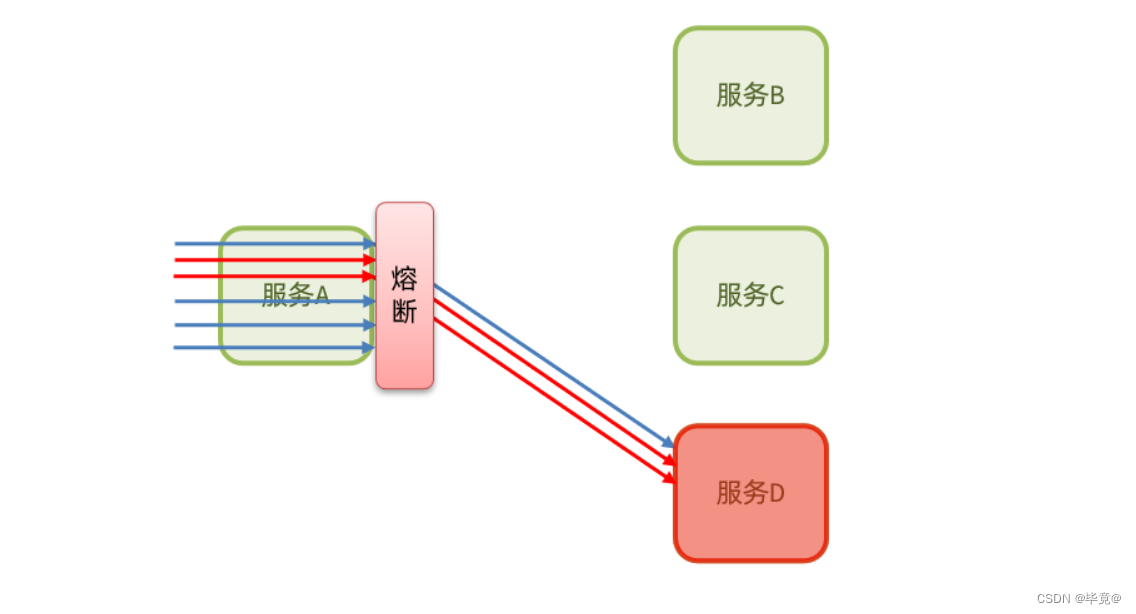
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。断路器熔断策略有三种:慢调用、异常比例、异常数。
2.1慢调用
业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。

 单位时间1s内通过的线程数量>=5, 且平均响应时间(秒级)超出RT阈值200ms时, 触发熔断器。
单位时间1s内通过的线程数量>=5, 且平均响应时间(秒级)超出RT阈值200ms时, 触发熔断器。
2.2异常比例
统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值,则触发熔断。

单位时间1s内通过的线程数量的异常比例超过0.5时时, 触发熔断器。
2.3异常数
统计指定时间内的调用,如果调用次数超过指定请求数,并且出现超过指定异常数 ,则触发熔断。

单位时间1s内通过的线程数量的异常数量超过5时时, 触发熔断器。
三、FeignClient整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。 业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,而我们利用FeignClient整合Sentinel的目的就是为了达到这个效果。
3.1修改配置,开启sentinel功能
修改消费者微服务的application.yml文件,开启Feign的Sentinel功能:
feign:
sentinel:
enabled: true # 开启feign对sentinel的支持3.2编写失败降级逻辑
业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理
3.2.1利用FallbackClass回调失败处理
(1)目录结构

(2)UserClientFeignFallBack 类代码的实现过程
该类需要继承FeignClient远程调用的接口UserClient,并且重写该接口的方法的业务失败后需要实现的逻辑。
@Service
public class UserClientFeignFallBack implements UserClient {
@Override
public UserBean getOne() {
UserBean userBean = new UserBean();
userBean.setUserName("服务器正忙,请稍后重试");
return userBean;
}
}(3) UserClient 接口类代码的编写
这里使用到了@FeignClient注解,里面的value的值是调用的微服务的名称,fallback的值是我们的UserClientFeignFallBack 类。
@FeignClient(value = "provider",fallback = UserClientFeignFallBack.class)//调用的服务名称
public interface UserClient {
@GetMapping("user")
UserBean getOne();
}(4)测试结果

3.2.2利用FallbackFactory回调失败处理
(1)目录结构

(2)UserClientFallbackFactory 类代码的实现过程
UserClientFallbackFactory需要继承的是 FallbackFactory并且里面的参数是我们的FeignClient远程调用的接口UserClient,然后需要重写我们FallbackFactory里面的create方法,并且抛出异常,我们这里利用@Slf4j的log.error()方法在控制台输出这个异常。还需要加上Component注解给该类的方法创建bean对象,以便可以被调用。
@Component
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public UserBean getOne() {
log.error("查询用户异常",throwable);
return new UserBean();
}
};
}
}(3) UserClient 接口类代码的编写
这里使用到了@FeignClient注解,里面的value的值是调用的微服务的名称,fallbackFactory(注意不是fallback)的值是我们的UserClientFallbackFactory 类。
@FeignClient(value = "provider",
fallbackFactory = UserClientFallbackFactory.class)//调用的服务名称
public interface UserClient {
@GetMapping("user")
UserBean getOne();
}(4)测试结果

四、总结
4.1线程隔离(舱壁模式)和熔断降级的区别
线程隔离(舱壁模式)和熔断降级是微服务架构中常用的两种保护机制,它们在实现方式和应用场景上有一些区别。
线程隔离(舱壁模式):
(1)线程隔离通过为每个服务请求分配独立的线程池或线程来实现,将不同的服务请求隔离在不同的线程中执行。
(2)线程隔离可以避免由于某个服务请求的故障或高延迟影响其他服务请求的性能。
(3)线程隔离适用于需要保护每个服务请求的性能和稳定性的场景,特别是在面对大量并发请求或请求处理时间不稳定的情况下。
熔断降级:
(1)熔断降级是一种服务保护机制,用于在面对故障或异常情况时临时停止对某个服务的请求,避免影响整体系统的性能和可用性。
(2)熔断降级会根据预设的条件(例如错误率、响应时间等)监控服务请求的状态,并在达到阈值时触发熔断操作,停止向该服务发起请求。
(3)熔断降级可以快速失败并返回预设的默认响应或错误信息,减少对不可用服务的依赖,保护系统的可用性和稳定性。
区别:
(1)线程隔离关注的是请求级别的隔离,将不同的服务请求分配到独立的线程中执行,以保护性能和稳定性。
(2)熔断降级关注的是服务级别的保护,根据预设条件监控服务的状态,并在达到阈值时停止对该服务的请求,以保护整体系统的可用性。
(3)两种机制可以结合使用,通过线程隔离来保护每个服务请求的执行,同时通过熔断降级来避免对不可用服务的继续请求,提高系统的稳定性和容错能力。
两种机制可以结合使用,通过线程隔离来保护每个服务请求的执行,同时通过熔断降级来避免对不可用服务的继续请求,提高系统的稳定性和容错能力。
4.2断路器熔断的三种策略:慢调用、异常比例、异常数的区别
断路器熔断策略是在微服务架构中常用的一种保护机制,用于避免故障服务对整体系统的影响。在断路器熔断策略中,常见的三种策略是慢调用、异常比例和异常数。它们的区别如下:
慢调用(Slow Call):
(1)慢调用策略基于服务请求的响应时间来触发熔断。
(2)当服务请求的响应时间超过预设的阈值,即被定义为慢调用,断路器将会打开,停止对该服务的请求。
(3)慢调用策略关注的是服务请求的响应时间,当响应时间过长时,认为服务不可用,触发熔断保护。
异常比例(Error Percentage):
(1)异常比例策略基于服务请求中的异常比例来触发熔断。
(2)当服务请求中的异常比例超过预设的阈值,即异常比例达到或超过一定百分比时,断路器将会打开,停止对该服务的请求。
(3)异常比例策略关注的是服务请求中异常的比例,当异常比例超过阈值时,认为服务不可用,触发熔断保护。
异常数(Error Count):
(1)异常数策略基于服务请求中的异常数量来触发熔断。
(2)当服务请求中的异常数量超过预设的阈值,即异常数量达到或超过一定数量时,断路器将会打开,停止对该服务的请求。
(3)异常数策略关注的是服务请求中异常的数量,当异常数量超过阈值时,认为服务不可用,触发熔断保护。
慢调用策略基于响应时间,异常比例策略基于异常比例,异常数策略基于异常数量。它们都是用于监控服务请求的状态,当达到预设的阈值时触发熔断操作,停止对服务的请求。选择适合的熔断策略需要根据具体的应用场景和需求进行判断和配置。
4.3@FeignClient注解中的FallbackClass和FallbackFactory的区别
Feign的注解@FeignClient:fallbackFactory与fallback方法不能同时使用,这个两个方法其实都类似于Hystrix的功能,当网络不通时返回默认的配置数据。
区别:
FallbackClass方式是直接创建一个降级逻辑实现类,而FallbackFactory方式通过工厂类创建降级逻辑实例。FallbackFactory提供了更灵活的降级处理选项,可以根据异常信息动态创建不同的降级逻辑实例。FallbackFactory可以在创建降级逻辑实例时获取到触发降级的异常信息,而FallbackClass方式无法直接获取异常信息。
选择使用哪种方式取决于具体的业务需求和降级处理的复杂程度。如果需要根据异常信息动态创建降级逻辑或者实现更复杂的降级处理逻辑,建议使用FallbackFactory。如果降级逻辑比较简单且不需要动态处理,可以使用FallbackClass来实现服务降级。















 2376
2376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









