







Python文字处理
从技术角度出发,没有任何难度,只是一些python下基于固定规则对string的切割操作。但扬州疫情,我看群里不少老年人不会进行在线表格登记操作,只能通过微信接龙进行生活物资的团购。所以,为了降低工作人员的工作强度,贡献一点点小作用,就有了这个想法。
#接龙
1. 21栋二单元1408
2. 14幢304 13222222222
3. 23 幢150813222222222
4. 19栋二单元1404 ,13222222222
5. 17-1703 一单元13222222222
6. 英16栋203. 13222222222
7. 14幢304 二单元 13222222222
文字切割
文字切割是进行文本关键信息提取分类的重要方式,一般使用split函数:
string.split(separator, maxsplit)
可以有2个有效参数:
- 第一个参数,separator,是我们要用来切割的基信息,一般我们用“ . / = + , ,。”等字符来进行切割
- 第二个参数,maxsplit,是我们要切割成几块,默认是有多少块切多少块。为什么要有这个呢?比如,在下面场景下,如果104.132222222222是一个有效数据,那么如果不限定切割块的个数,就会被分割出来,需要额外拼接动作。
a.split('.')
['26', ' 一切随缘 21幢104', '13222222222']
a.split('.', 2)
['26', ' 一切随缘 21幢104', '13222222222']
a.split('.', 1)
['26', ' 一切随缘 21幢104.13222222222']
a.split('.', 0)
['26. 一切随缘 21幢104.13222222222']
电话号码提取
为了方便联系,要提取电话信息,这里用到了re这个库,可以匹配13/14/15…开头的手机号码
def judge_phone_number(account):
a = re.findall(r'(1[3|4|5|6|7|8|9]\d{9})', account)
try:
res = a[0]
except:
res = 0
return res
生成excel表格
这里用到了StyleFrame,来对Pandas DF数据进行格式化
安装方式
pip install StyleFrame
具体使用介绍,可以点这个StyleFrame介绍参考
粗暴点,待会下去做核酸了,先直接贴代码了,有空再回来改改
df = pd.DataFrame(columns=[u'编号', u'用户', u'内容', u'电话号码', u'原信息,人工校准下'])
df.loc[0] = [int(no), usr, cont, phone_num, k[i]]
filt = "Excel(*.xlsx)"
fileName, ok = QFileDialog.getSaveFileName(None, "文件保存", os.getcwd(), filt)
# 这里开始是格式化,不使用pandas.ExcelWriter,没法很好的格式化
excel_writer = StyleFrame.ExcelWriter(fileName)
style_df = StyleFrame(df)
style_df.to_excel(excel_writer=excel_writer, best_fit=df.columns.to_list())
excel_writer.save()
结果
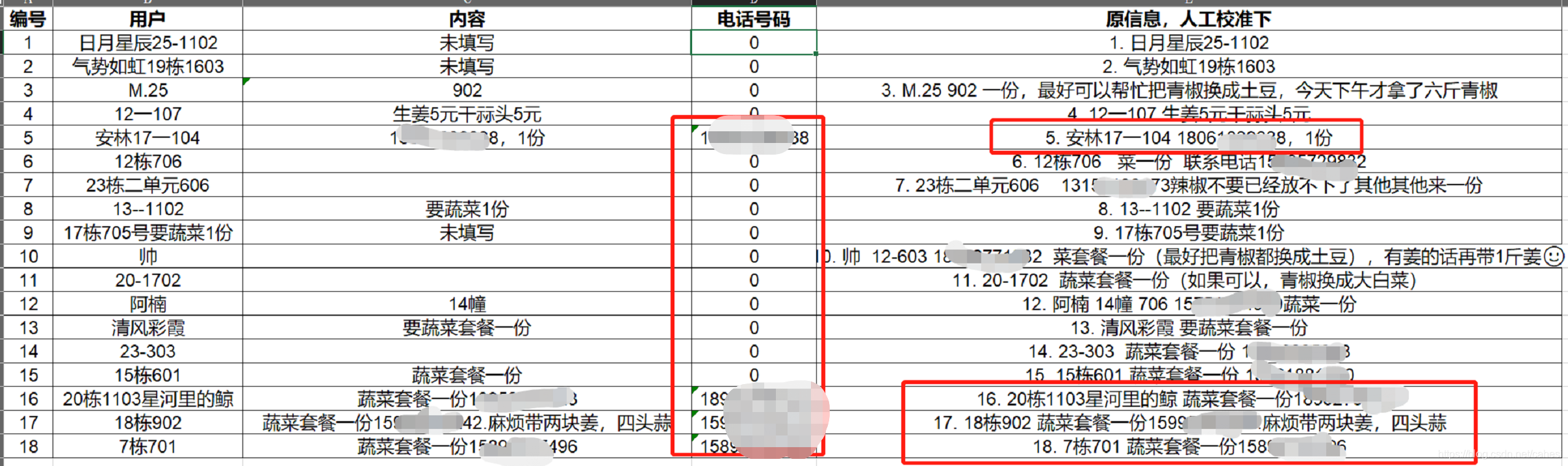
软件截图
本来几行代码就能搞定,但给物业用,得弄个界面。。。
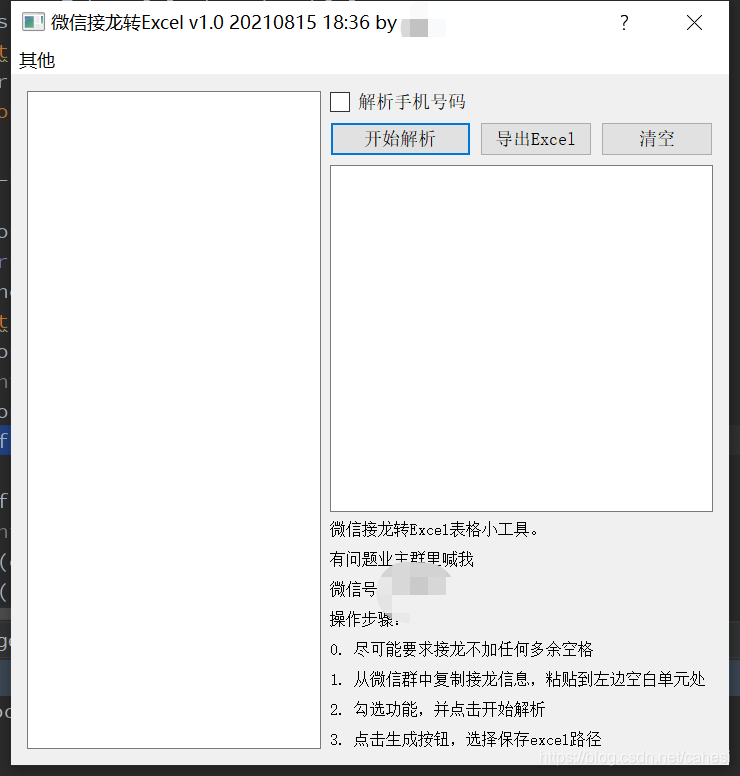
工具连接
TBD
。。。喊做核酸了,先下楼了
20210819分割线…
新需求
今天第13轮次了,110打电话给我,我还以为12次了,会不会被带走啊。。
言归正传,好像也什么正。。。现在政府能力升级了,提供有各种套餐了。有豆制品,有本地扬大奶,有蔬菜,有肉。感谢。。。
#接龙
开始接龙,冷冻肉目前没有了,填写请按照格式填写,写明份数,不写默认是一份,手机号写在最后
例 11-902 30元蔬菜一份,13222222222
1. ZM
2. 8栋208 豆制品套餐一份。13222222222
3. 7-2单元-307 30元蔬菜一份,20元豆制品一份 13222222222
4. 8栋 8-303 30元蔬菜一份,20元豆制品一份,一箱酸奶 13222222222
5. 10栋1单元1204 蔬菜50元套餐一份,豆制品20元套餐一份,酸奶33元套餐一份 13222222222
6. 6幢9O3蔬菜5O元套餐,豆制品2O元套餐。13222222222
7. 11-1402 50蔬菜一份
8. 马爱华 葡桃一份:13222222222
虽然物业/志愿者虽然要求大家按照格式来,可是大家写的也是各种任性。
有把0写成O的
有不写手机号的
有要套餐外东西的
志愿者告诉我,这算好的了,还有人会对肉菜有要求,什么猪腿肉啊,什么只要XX菜啊,都写在上面。让信息提取超级不方便。。。
方案1
这时候,上面那种仅仅用split函数来拆分,已经不再合适了
所以,我们用re正则表达式匹配
# Tips
re.findall(r'(1[3|4|5|6|7|8|9]\d{9})', string)
表达式用法和表达式模式可以参照:传送门
# 匹配 '30元蔬菜套餐3份'
a = re.findall(r'(30\S+?(\d{1})份)', tmp)
if len(a):
c30 = int(a[0][1])
s30 = a[0][0]
# 匹配 '豆制品套餐3份'
d = re.findall(r'(豆\S+?(\d{1})份)', tmp)
if len(d):
cdou = int(d[0][1])
sdou = d[0][0]
# 匹配 '酸奶套餐3份',因为有人喜欢写 扬大奶
e = re.findall(r'([扬大|酸]奶(\d{1})份)', tmp)
if len(e):
cnai = int(e[0][1])
snai = e[0][0]
# 匹配 '肉套餐3份'
f = re.findall(r'(肉\S+?(\d{1})份)', tmp)
if len(f):
crou = int(f[0][1])
srou = f[0][0]
这种规则性编程,太累了。。。
方案2
制作,或者用现成的投票小程序。。。正在向他们推广
可以结案了
https://gitcode.net/-/snippets/1855


















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











