






摘要
本文介绍如何使用 Python 开发一个集成自定义截图 OCR 识别与360 翻译 API 爬取的中英互译工具。通过 Tkinter 构建 GUI 界面,Pillow 处理图像,pytesseract 实现文字识别,结合 requests 库爬取 360 翻译结果,实现双语互译功能。文章重点解析反爬策略、API 请求参数构造及界面交互逻辑,适合学习 Web 数据采集与桌面应用开发的初学者。
一 :实际实现样式
1.运行代码
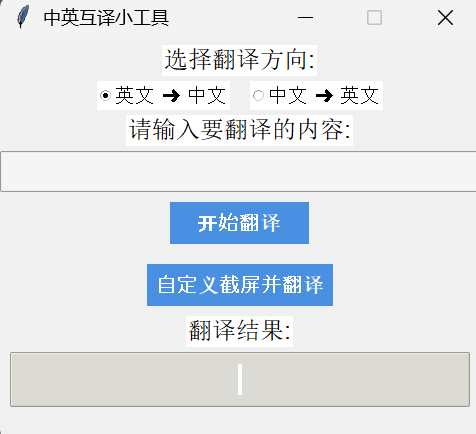
2.代码进行翻译
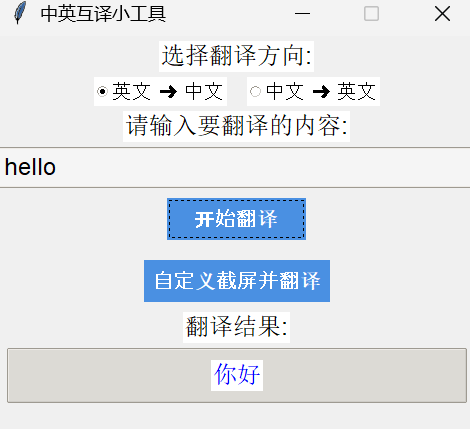
3.翻译后会出现fanyi.txt 里面记录 翻译记录

二 环境安装
1.安装必须模块
# 安装依赖
pip install pillow pytesseract requests fake_useragent2.实现截图翻译功能
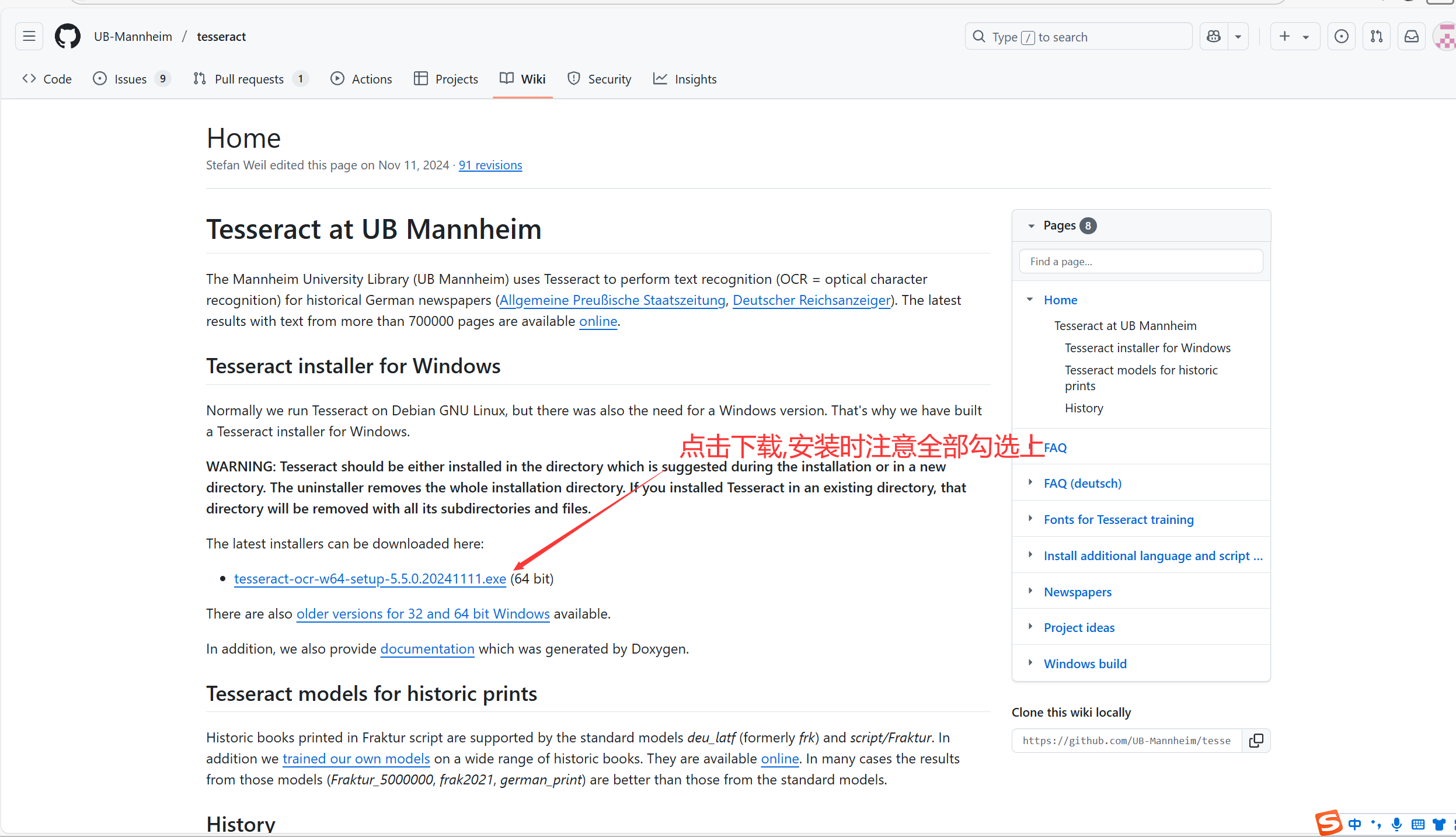
.安装 ocr
Home · UB-Mannheim/tesseract Wiki
三.代码展示与解释
一、环境配置与依赖导入
python
import tkinter as tk
from tkinter import messagebox, filedialog, ttk
from PIL import Image, ImageGrab, ImageTk # 图像处理与截图
import pytesseract # OCR引擎接口
import requests # 网络请求(调用翻译API)
import time # 时间处理
import tempfile # 临时文件存储截图
from fake_useragent import FakeUserAgent # 生成随机User-Agent(反爬)
import ctypes # 设置DPI感知(解决高分辨率界面模糊)
# 解决高DPI屏幕缩放问题(Windows系统)
ctypes.windll.shcore.SetProcessDpiAwareness(1)
# 配置Tesseract路径(需根据实际安装路径修改)
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
- 核心依赖:
Tkinter:Python 内置 GUI 框架,用于创建窗口和组件Pillow:图像处理库,支持截图、预览和保存pytesseract:调用 Tesseract-OCR 引擎,需单独安装 OCR 程序requests:发送 HTTP 请求获取翻译结果fake_useragent:生成随机浏览器标识,绕过翻译网站反爬机制
二、全局变量与界面初始化
python
url = 'https://fanyi.so.com/index/search' # 360翻译API地址
is_translating = False # 防止重复翻译的标志
root = tk.Tk()
root.title("中英互译小工具")
root.geometry("480x400")
root.resizable(False, False) # 禁止调整窗口大小
# 界面样式配置(ttk主题)
style = ttk.Style()
style.theme_use('clam') # 使用现代风格主题
# 自定义按钮样式(蓝色主色调,扁平化设计)
style.configure("TButton",
padding=6, relief="flat", background="#4A90E2", foreground="white",
font=("Arial", 10, "bold")
)
style.map("TButton",
background=[('active', '#357ABD')] # 鼠标悬停时变色
)
- 界面特点:
- 固定窗口大小(480x400),适合桌面工具
- 使用 ttk 组件(比原生 tkinter 更美观),配置蓝色主色调和扁平化按钮
is_translating防止用户连续点击导致重复请求
三、翻译日志记录功能
def log_translation(text, result):
"""记录翻译内容到本地文本文件"""
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
current_dir = os.path.dirname(os.path.abspath(__file__)) # 获取当前脚本路径
log_path = os.path.join(current_dir, "fanyi.txt") # 日志文件路径
with open(log_path, "a", encoding="utf-8") as f:
# ljust(20) 使字段左对齐并填充至20字符宽度
f.write(f"时间: {now_time.ljust(20)} 原文: {text.ljust(20)} 结果: {result.ljust(20)}\n")
f.write("-" * 60 + "\n") # 分隔线
- 功能作用:
- 在当前脚本目录下创建 / 追加
fanyi.txt - 记录每次翻译的时间、原文和结果,方便追溯
- 使用 UTF-8 编码避免中文乱码
- 在当前脚本目录下创建 / 追加
四、核心翻译逻辑
python
def translate(text):
"""调用360翻译API进行文本翻译"""
global is_translating
if not text or is_translating:
return # 防止空文本或重复请求
is_translating = True
translate_btn.config(state=tk.DISABLED) # 禁用按钮防止误操作
output_var.set("正在翻译...")
try:
# 构造请求参数(eng=1为英→中,eng=0为中→英)
data = {
"eng": "1" if mode_var.get() == "en2zh" else "0",
"query": text
}
# 生成随机User-Agent(反爬关键)
headers = {"User-Agent": FakeUserAgent().random}
response = requests.post(url, headers=headers, data=data, timeout=10)
if response.status_code == 200:
result = response.json()["data"]["fanyi"]
output_var.set(result)
log_translation(text, result) # 记录翻译日志
else:
output_var.set(f"❌ 翻译失败:HTTP {response.status_code}")
except Exception as e:
output_var.set(f"❌ 错误:{str(e)}")
finally:
is_translating = False
translate_btn.config(state=tk.NORMAL) # 恢复按钮状态
- 技术要点:
- 反爬措施:每次请求生成随机 User-Agent,模拟真实浏览器
- 状态管理:通过
is_translating防止并发请求,按钮禁用避免用户重复点击 - 异常处理:捕获网络超时、API 错误等异常,给出友好提示
五、OCR 截图翻译功能
def custom_screenshot():
"""自定义区域截图并翻译"""
# 创建全屏透明窗口用于截图
top = tk.Toplevel()
top.attributes("-fullscreen", True, "-alpha", 0.3) # 30%透明度
canvas = tk.Canvas(top, cursor="cross")
canvas.pack(fill=tk.BOTH)
start_x = start_y = 0
# 鼠标按下:记录起点
def on_mouse_down(event):
nonlocal start_x, start_y
start_x, start_y = event.x_root, event.y_root
# 鼠标拖动:绘制红色选框
def on_mouse_drag(event):
canvas.create_rectangle(start_x, start_y, event.x_root, event.y_root,
outline="red", width=2, tag="rect")
# 鼠标释放:处理截图
def on_mouse_up(event):
x1, y1 = min(start_x, event.x_root), min(start_y, event.y_root)
x2, y2 = max(start_x, event.x_root), max(start_y, event.y_root)
top.destroy()
# 截取指定区域并保存临时文件
screenshot = ImageGrab.grab((x1, y1, x2, y2))
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmpfile:
screenshot.save(tmpfile.name)
# 显示预览窗口
preview = tk.Toplevel()
img = ImageTk.PhotoImage(screenshot.resize((400, 300)))
tk.Label(preview, image=img).pack()
preview.image = img # 防止图片被GC回收
# 异步执行OCR识别和翻译
root.after(100, lambda: ocr_image(screenshot))
- 流程解析:
- 创建透明全屏窗口,允许用户拖动选择翻译区域
- 使用
ImageGrab.grab()截取屏幕指定区域 - 生成临时图片文件并显示预览
- 调用
ocr_image()进行文字识别和翻译
六、OCR 文字识别
def ocr_image(image):
"""对截图进行OCR识别并触发翻译"""
try:
# 调用Tesseract进行中英文混合识别
text = pytesseract.image_to_string(image, lang="eng+chi_sim").strip()
if not text:
messagebox.showwarning("提示", "未识别到文字")
return
input_entry.delete(0, tk.END)
input_entry.insert(0, text) # 将识别结果填充到输入框
root.after(2000, translate, text) # 延迟2秒触发翻译(避免网络拥堵)
except Exception as e:
messagebox.showerror("错误", f"OCR失败:{str(e)}")
- 关键参数:
lang="eng+chi_sim":同时识别英文和简体中文root.after(2000, ...):延迟执行翻译,确保 OCR 结果已填充到输入框
七、界面组件布局
# 翻译方向选择(RadioButton)
mode_var = tk.StringVar(value="en2zh")
ttk.Label(root, text="选择翻译方向:").pack(pady=5)
mode_frame = tk.Frame(root)
ttk.Radiobutton(mode_frame, text="英文 ➜ 中文", variable=mode_var, value="en2zh").pack(side=tk.LEFT)
ttk.Radiobutton(mode_frame, text="中文 ➜ 英文", variable=mode_var, value="zh2en").pack(side=tk.LEFT)
# 输入框
ttk.Label(root, text="请输入要翻译的内容:").pack(pady=5)
input_entry = ttk.Entry(root, font=("Arial", 12), width=40)
input_entry.pack()
# 功能按钮
translate_btn = ttk.Button(root, text="开始翻译", command=lambda: translate(input_entry.get().strip()))
screenshot_btn = ttk.Button(root, text="自定义截屏并翻译", command=custom_screenshot)
translate_btn.pack(pady=10)
screenshot_btn.pack(pady=10)
# 翻译结果显示
ttk.Label(root, text="翻译结果:").pack()
output_frame = ttk.Frame(root, borderwidth=2, relief="groove")
output_label = ttk.Label(output_frame, textvariable=output_var,
wraplength=440, foreground="blue")
output_label.pack(padx=10, pady=10)
- 布局特点:
- 使用 ttk 组件(如
ttk.Entry、ttk.Button)提升界面美观度 wraplength=440使翻译结果自动换行,适应窗口宽度- 按钮和输入框通过
pack()布局,结构清晰
- 使用 ttk 组件(如
-
使用注意:
- 需手动配置 Tesseract-OCR 路径
- 360 翻译 API 可能限制请求频率,建议添加请求间隔
- 部分系统需安装依赖库(如 Windows 的 Visual C++ 运行时)
四.代码展示
import tkinter as tk
from tkinter import messagebox, filedialog, ttk
from PIL import Image, ImageGrab, ImageTk
import pytesseract
import requests
import time
import tempfile
from fake_useragent import FakeUserAgent
import ctypes
ctypes.windll.shcore.SetProcessDpiAwareness(1) # 设置为 DPI 感知模式
# 设置 Tesseract 路径(根据实际安装路径修改)
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR'
# 全局变量
url = 'https://fanyi.so.com/index/search'
is_translating = False # 防止重复翻译标志
# GUI主窗口
root = tk.Tk()
root.title("中英互译小工具")
root.geometry("480x400")
root.resizable(False, False)
# 在 root 初始化之后添加样式配置
style = ttk.Style()
style.theme_use('clam') # 使用现代感更强的主题
# 自定义样式
style.configure("TButton", padding=6, relief="flat", background="#4A90E2", foreground="white", font=("Arial", 10, "bold"))
style.map("TButton",
background=[('active', '#357ABD')],
foreground=[('pressed', 'black'), ('active', 'white')])
style.configure("TEntry", padding=5, relief="flat", borderwidth=2, fieldbackground="#F5F5F5")
style.configure("TRadiobutton", background="#FFFFFF", font=("Arial", 10))
style.configure("TLabel", background="#FFFFFF", font=("Arial", 10))
# 全局变量初始化
output_var = tk.StringVar()
def get_headers():
"""获取随机 User-Agent"""
ua = FakeUserAgent().random
return {'Pro': 'fanyi', 'User-Agent': ua}
def log_translation(text, result):
"""记录翻译日志"""
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
import os
# 获取当前脚本所在目录
current_dir = os.path.dirname(os.path.abspath(__file__))
log_path = os.path.join(current_dir, "fanyi.txt")
# 写入时自动创建文件(如果不存在)
with open(log_path, "a", encoding="utf-8") as f:
f.write(f"时间: {now_time.ljust(20)} 原文: {text.ljust(20)} 结果: {result.ljust(20)}\n")
f.write("-" * 60 + "\n")
# 翻译逻辑
def translate(text):
global is_translating
if not text or is_translating:
return
is_translating = True
translate_btn.config(state=tk.DISABLED)
output_var.set("正在翻译...")
mode = mode_var.get()
data = {
"eng": "1" if mode == "en2zh" else "0",
"validate": "",
"ignore_trans": "0",
"query": text
}
try:
response = requests.post(url, headers=get_headers(), data=data, timeout=10)
if response.status_code == 200:
result = response.json()['data']['fanyi']
output_var.set(result)
log_translation(text, result)
else:
output_var.set("❌ 翻译失败,请稍后再试")
except requests.exceptions.RequestException as e:
output_var.set(f"❌ 网络异常:{e}")
except Exception as e:
output_var.set(f"❌ 异常:{e}")
finally:
is_translating = False
translate_btn.config(state=tk.NORMAL)
# OCR识别
def ocr_image(image):
try:
text = pytesseract.image_to_string(image).strip()
input_entry.delete(0, tk.END)
input_entry.insert(0, text)
root.after(2000, translate, text) # 延迟翻译
except Exception as e:
messagebox.showerror("错误", f"图像处理失败: {e}")
# 自定义截图功能
def custom_screenshot():
top = tk.Toplevel()
top.attributes("-fullscreen", True)
top.attributes("-alpha", 0.3)
top.config(bg='black')
top.lift()
canvas = tk.Canvas(top, cursor="cross")
canvas.pack(fill=tk.BOTH, expand=True)
rect = None
start_x = start_y = 0
def on_mouse_down(event):
nonlocal start_x, start_y
start_x, start_y = event.x_root, event.y_root
canvas.delete("all")
def on_mouse_drag(event):
end_x, end_y = event.x_root, event.y_root
canvas.delete("all")
canvas.create_rectangle(start_x, start_y, end_x, end_y, outline="red", width=2)
def on_mouse_up(event):
nonlocal start_x, start_y
end_x, end_y = event.x_root, event.y_root
x1, y1 = min(start_x, end_x), min(start_y, end_y)
x2, y2 = max(start_x, end_x), max(start_y, end_y)
top.destroy()
def do_screenshot():
screenshot = ImageGrab.grab(bbox=(x1, y1, x2, y2))
with tempfile.NamedTemporaryFile(suffix=".png", delete=False) as tmpfile:
screenshot_path = tmpfile.name
screenshot.save(screenshot_path)
# 显示预览窗口
preview = tk.Toplevel(root)
preview.title("截图预览")
img = Image.open(screenshot_path)
img.thumbnail((400, 300))
tk_img = ImageTk.PhotoImage(img)
label = tk.Label(preview, image=tk_img)
label.image = tk_img
label.pack(padx=10, pady=10)
def save_screenshot():
save_path = filedialog.asksaveasfilename(defaultextension=".png", filetypes=[("PNG files", "*.png")])
if save_path:
screenshot.save(save_path)
messagebox.showinfo("保存成功", "截图已成功保存!")
save_btn = ttk.Button(preview, text="保存截图", command=save_screenshot)
save_btn.pack(pady=10)
loading = tk.Toplevel(root)
loading.title("正在翻译")
loading.geometry("200x100")
tk.Label(loading, text="加载中...", font=("Arial", 14)).pack(padx=20, pady=20)
def do_ocr():
preview.destroy()
ocr_image(screenshot)
loading.destroy()
root.after(2000, do_ocr)
root.after(150, do_screenshot)
canvas.bind("<ButtonPress-1>", on_mouse_down)
canvas.bind("<B1-Motion>", on_mouse_drag)
canvas.bind("<ButtonRelease-1>", on_mouse_up)
# 翻译方向选择
mode_var = tk.StringVar(value="en2zh")
ttk.Label(root, text="选择翻译方向:", font=("Arial", 12)).pack(pady=5)
mode_frame = tk.Frame(root)
mode_frame.pack()
ttk.Radiobutton(mode_frame, text="英文 ➜ 中文", variable=mode_var, value="en2zh").pack(side=tk.LEFT, padx=10)
ttk.Radiobutton(mode_frame, text="中文 ➜ 英文", variable=mode_var, value="zh2en").pack(side=tk.LEFT, padx=10)
# 输入框
ttk.Label(root, text="请输入要翻译的内容:", font=("Arial", 12)).pack(pady=5)
input_entry = ttk.Entry(root, font=("Arial", 12), width=40)
input_entry.pack()
# 翻译按钮
translate_btn = ttk.Button(root, text="开始翻译", command=lambda: translate(input_entry.get().strip()))
translate_btn.pack(pady=10)
# 自定义截屏按钮
screenshot_btn = ttk.Button(root, text="自定义截屏并翻译", command=custom_screenshot)
screenshot_btn.pack(pady=10)
# 输出结果
ttk.Label(root, text="翻译结果:", font=("Arial", 12)).pack()
output_frame = ttk.Frame(root, borderwidth=2, relief="groove")
output_frame.pack(pady=5, padx=10, fill=tk.X)
output_label = ttk.Label(output_frame, textvariable=output_var, font=("Arial", 12), foreground="blue", wraplength=440, anchor="center")
output_label.pack(padx=10, pady=10)
# 主循环
root.mainloop()
五.仅仅实现翻译
在运行界面输入翻译内容
import requests
from fake_useragent import FakeUserAgent #这个是user,agent代理用户池
ua = FakeUserAgent().random #随机生成用户代理
import time
url = 'https://fanyi.so.com/index/search'
headers = {
'Pro': 'fanyi', #这个是这个网站关键处 没有就没法爬取
'User-Agent': ua
}
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
fanyi_chioce = input("你是需要将 英文 翻译为 中文 吗? 请输入'1',还是将 中文 翻译为 英文 ? 请输入'2':\n")
def fanyi():
if fanyi_chioce == '1':
people_Input = input('输入需要翻译的英文: ')
#下面的这个为表单参数 在载荷里面可以看 (post)
data_format = {
"eng": "1",
"validate": "",
"ignore_trans": "0",
"query": people_Input
}
elif fanyi_chioce == '2':
people_Input = input('输入需要翻译的中文: ')
data_format = {
"eng": "0",
"validate": "",
"ignore_trans": "0",
"query": people_Input
}
else:
print('无效的选择')
return
try:
response = requests.post(url, headers=headers, data=data_format, proxies={"http": None, "https": None})
abc = response.status_code
if abc == 200 :
print("网络请求成功,正在翻译")
data = response.json() #这个数据.txt打印出来是字典(最外面有{}就是字典)说明这个就是json数据
results = data['data']['fanyi']
time.sleep(2)
print('翻译结果是:', results)
with open('fanyi.txt', 'a', encoding='utf-8') as file:
file.write(f"时间: {now_time.ljust(20)}原文: {people_Input.ljust(20)}翻译结果: {results.ljust(20)}\n")
file.write("-" * 60 + "\n") # 用分隔符标记每次翻译结
else:
print("翻译失败,网络连接中断")
except Exception as e:
print(f"网络请求失败请稍后尝试,{e}")
print("翻译失败")
while True:
fanyi()
fanyi_chioce = input("是否需要再次翻译? 输入'1' 翻译英文,'2' 代表翻译为中文。随便按将会退出\n")
if fanyi_chioce not in ['1','2']:
break
# 设置一个常用的用户代理(模拟浏览器)
UA = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0 Safari/537.36"
# 翻译接口和请求头
url = 'https://fanyi.so.com/index/search'
headers = {
'Pro': 'fanyi',
'User-Agent': UA
}
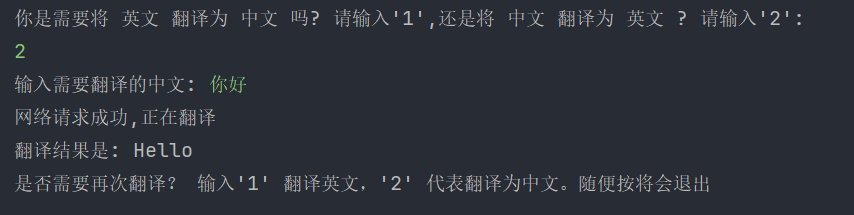
运行样式:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











