







•机器学习方法
•生成方法(无监督学习),所学到的模型称为生成式模型。
•判别方法(有监督学习),所学到的模型称为判别式模型。
生成方法通过观测数据学习样本与标签的联合概率分布P(X, Y), 训练好的模型,即生成式模型,能够生成符合样本分布的新数据。
在没 有目标类标签信息的情况下捕捉观测到或可见数据的高阶相关性。
判别方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X) 作为预测的模型,即判别模型。
判别方法关心的是对给定的输入X,应该预测什么样的输出Y。
有监督学习经常比无监督学习获得更好的模型。 •但是有监督学习需要大量的标注数据
支持无监督学习的生成式模型遇到两大困难:
1.需要大量的先验知识去对真实世界进行建模
2.用来拟合模型的计算量往 往非常庞大
GAN
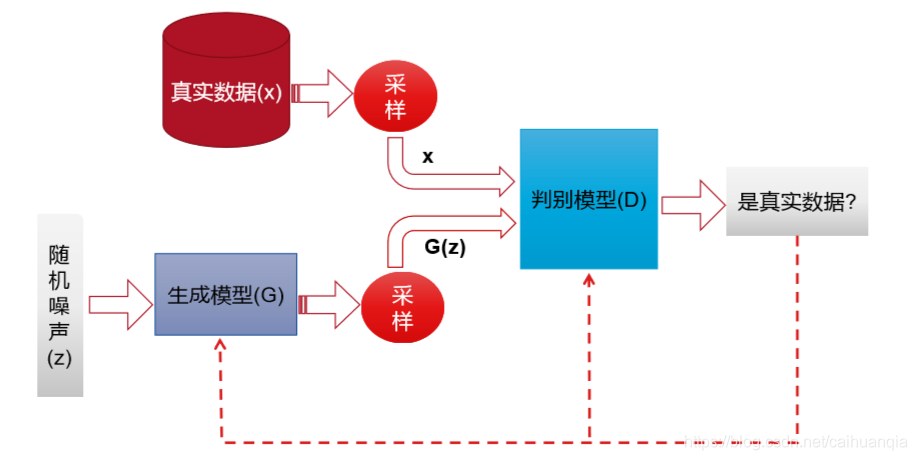
Gan的论文集•https://github.com/hindupuravinash/the-gan-zoo
Gan Paper: https://arxiv.org/abs/1701.00160
•Video: https://channel9.msdn.com/Events/Neural-InformationProcessing-Systems-Conference/Neural-Information-ProcessingSystems-Conference-NIPS-2016/Generative-Adversarial-Networks
•由两个互为敌手的模型组成:
•生成模型(假币制造者团队)
•判别模型(警察团队)
•竞争使得两个团队不断改进他们 的方法直到无法区分假币与真币
生成模型:捕捉样本数据的分布,用服从某一分布(均匀分布、高斯分布)的噪声生成一个类似真实训练数据的样本,追求的效果是越像真实的数据越好。
生成模型相当于一个映射函数,当数据集是图片的时候,那么我们输入的随机噪声相当于低维的数据,经过生成模型G的映射之后就编程一张图片。
判别模型:二分类器,估计一个样本来自训练数据的概率,如果来自真实样本,则输出大概率;否则小概率。
目标函数:判别模型希望目标函数最大化,即判别模型判断真实本为真,判断生成样本为假的概率最大化。尽量最大化自己的判别准确率。
相反,生成模型希望目标函数最小化

也相当于损失函数的形式:
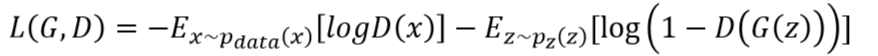
Pdata是真实数据的分布;Pz是噪声的分布;G(z)是生成模型(多层感知器);D(x)表示x来自真实数据而非生成数据的概率。
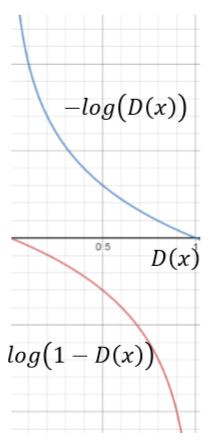
采用零和博弈时,由于实际操作中,收敛很慢,改进为目标函数只关注后半部分。
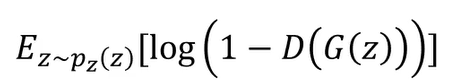
改进,由于1-的原因,由波形可以看出,刚开始收敛很慢,去掉1之后,收敛就很快了
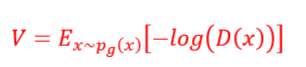
训练的时候是固定一方,更新另外一方的网络权重。交替得到,双方极力优化自己网络,形成竞争对抗,最终达到动态平衡–纳什均衡
生成样本则无限接近于训练数据的分布,判别模型判别不出来真实的数据和生成数据了,准确率为50%。
优势:
1.任何一个可微分函数可以参数化D和G
2.支持无监督方法实现数据生成,减少了数据标注工作
3.G的参数更新不是来自数据样本本身,而是来自判别模型D的一个反传梯度。
不足:
无需预先建模,数据生成的自由度太大
得到的是概率分布,没有表达式,可解释性差
D和G训练无法同步,训练难度大,会产生梯度消失问题。
GAN的优化和改进:
•CGAN:Conditional Generative Adversarial Nets
•InfoGAN:Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
•Improved Techniques for Training GANs
•GP-GAN: Towards Realistic High-Resolution Image Blending
•Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks
InfoGan
InfoGAN模型在z之外, 又增加了一个隐含输入 c(latent code),然后通 过约束c与生成数据之间 的关系,使得c里面可以 包含某些语义特征 (semantic feature)。
•比如MNIST实验的c就可 以由一个取值范围为0-9 的离散随机变量(用于 表示数字)和两个连续 的随机变量(分别用于 表示倾斜度和粗细度) 构成。
迭代式生成优化
LAPGAN:Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
•Generative Adversarial Text to Image Synthesis
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Network
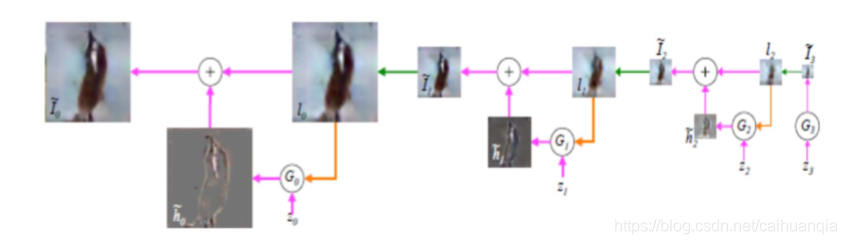
LAPGAN
GAN和CGAN只能生成1616, 2828, 3232 这种 低像素小尺寸的图片。
LPGAN首次实现6464 的图像生成。这样样每一步生 成的时候,可以基于上一步的结果,而且还只需要“填充”和 “补全”新图片所需要的那些信息
从右到左:逐步生成
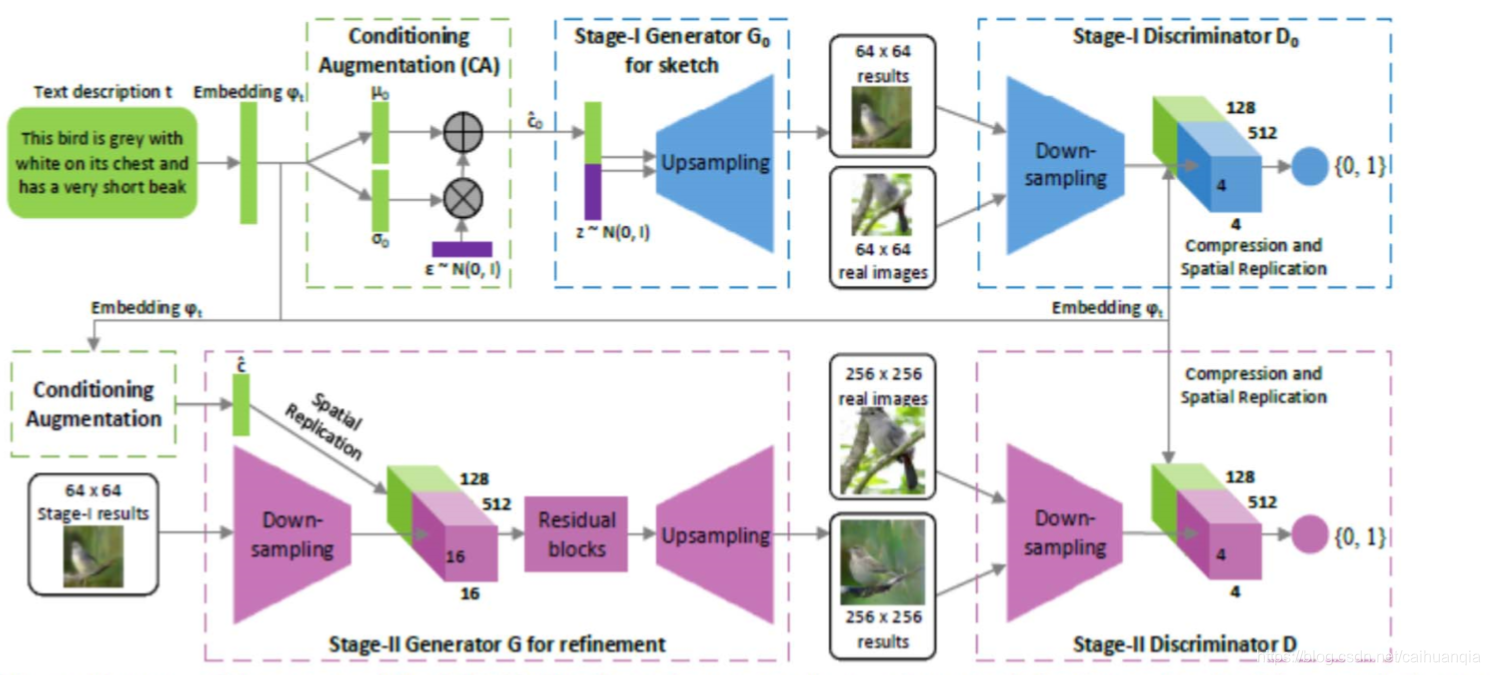
STACKGAN
解决从文本到图像生成分辨率不高的问题,采用coarse-to-fine的思路,构建两个GAN
第一个GAN是用于根据文本描述生成一张低分辨率的图像
第二个GAN将低分辨率图像和文本作为输入,修正之前生成的图像并添加细节纹理,生成高分辨率图像。
结构优化:
DCGAN
所有的pooling层使用步幅卷积(判别网络)和微步幅卷积(生成网络)进行 替换。
对更深的架构移除全连接隐藏层。
在生成网络三维输出层使用Tanh激活函数,其他层使用ReLU激活函 数,判别网络的所有层上使用LeakyReLU激活函数
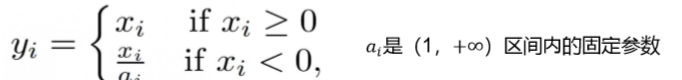
GAN主要应用:
图像生成、修复、迁移、预测、合成。














 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









