







 本文介绍了UCI数据集,一个包含622个数据集的机器学习资源,涵盖了交通流量、电力、生物等多个领域的数据。具体探讨了Electricity(用电量)和Traffic(交通流量)数据集,以及空气质量的PM2.5数据,这些数据可用于时间序列预测和数据分类任务。
本文介绍了UCI数据集,一个包含622个数据集的机器学习资源,涵盖了交通流量、电力、生物等多个领域的数据。具体探讨了Electricity(用电量)和Traffic(交通流量)数据集,以及空气质量的PM2.5数据,这些数据可用于时间序列预测和数据分类任务。
文章目录
一.UCI数据集
UCI官方网站
UCI数据集是由加州大学欧文分校维护的用于机器学习的数据库。官方网站收集了622个数据集,可用于时间序列预测、数据分类回归等多种任务,包含交通流量、电力、生物、空气质量、互联网等等各个方面的数据。

选取其中的2种数据:
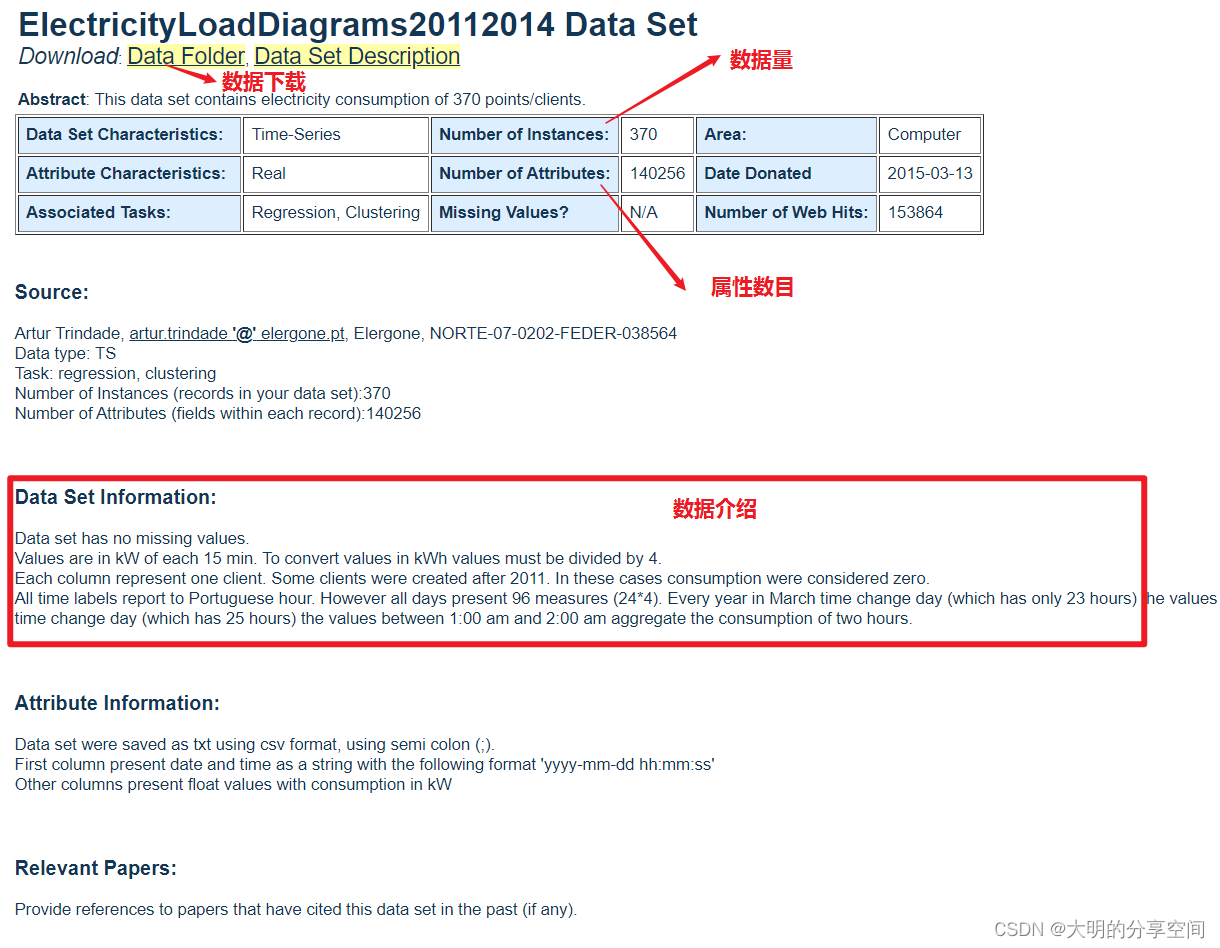
Electricity 数据集(用电量):
ElectricityLoadDiagrams20112014
包含从 321 位客户记录的三年(2012-2014 年)每小时用电量数据,每一列代表一个客户端。该数据每 15 分钟记录一次用电量(kW)。
Traffic 数据集(交通流量):
是来自加利福尼亚交通运输部的 15 个月的每日数据,描述了旧金山湾区高速公路不同车道的占用率。监测值的数值范围介于 0 和 1 之间,每隔 10 分钟对数据进行一次采样。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









