






1. 为什么要了解PARL的架构设计
PARL是百度推出的基于paddlepaddle深度学习框架构设计并实现的深度强化学习扩展库。它主打轻量级,意味着,其使用简单,架构简单实用,易于理解,但许多常规代码需要开发者定制。而要基于它熟练地把强化学习方法落地到实际场景,就必须了解其架构设计,以便在具体问题场景中既能遵循规范,加快开发速度,又能发挥框架提供的灵活的可扩展性。
2. 从面向对象的角度看强化学习算法的开发
从使用者的角度来看,任何强化学习任务,都包含两种基本的类对象,即环境和智能体。
环境体现了任务场景,它满足马尔科夫性,即:环境的未来状态只与当前状态和要采取的动作有关,与历史状态与动作无关。对于智能体来说,它可以不知道环境的动力学模型,但它至少可以观测到环境的初始状态(部分和全部,统称为observation),智能体可以给环境一个动作,环境能接受动作,并基于当前状态和环境自身的动力学特性,转移到一个新的状态,并反馈给智能体一个称为奖励(reward)的信号。因此,从面向对象的角度讲,环境类至少要包含智能体开始决策时为其输出初始状态的方法(即reset方法),当智能体根据当前状态,与环境交互,环境应该返回下一个状态、奖励、并且应该告诉智能体,任务是否结束或因时间过长而终止,于是,环境对象还应该包含接受并执行每一步决策行动后返回下一状态、奖励、任务是否结束,是否某种因素被强制终止等信息的方法(即step方法)。目前,使用最广泛的环境类要数gym.Env,最新版本是gymnasium.Env。gymnasium是gym的后续版本,它是一个强化学习环境扩展库,为强化学习算法开发者提供了可自定义、预定义的环境。该库采用面向对象和面向抽象编程的设计思想。大多数强化学习算法扩展库支持gym或gymnasium
智能体是强化学习算法的集中体现。它从一个初始策略出发,根据一定方法(兼顾探索与利用),与环境交互,获得状态、状态转移、奖励、任务终止或强制终止的基本信息,然后根据这些信息,评估和更新策略,使策略一步步朝着能最大化累计回报的方向演进,直到策略趋于最优。这个过程,我们称之为学习或者训练过程。
一旦策略最优或满足某种要求,智能体就能够根据策略直接依据当前状态,作出应当采取的动作的预测。
因此,智能体,有两种状态,一种是学习状态(learn或train),一种是预测状态(predict或eval)。学习状态是强化学习算法实现的关键,它涉及到的问题有:决策模型的表示、如何依据当前决策模型与环境交互以采集经验数据、数据保存到哪里以及如何保存及取出、如何根据经验数据更新决策模型。强化学习算法库的软件架构设计的关键是选择何种相对稳定的结构表示智能体的学习。
3.百度PARL的架构特点
从面向对象角度,百度PARL采用了一种组合分层架构,遵循了单一职责原则。具体而言,它就把强化学习智能体当做一个类,即Agent,这个类环境合了环境(Env)和算法(Algorithm)两个组成部分,而Algorithm则包含了Model类对象,架构设计的UML图如下所示。
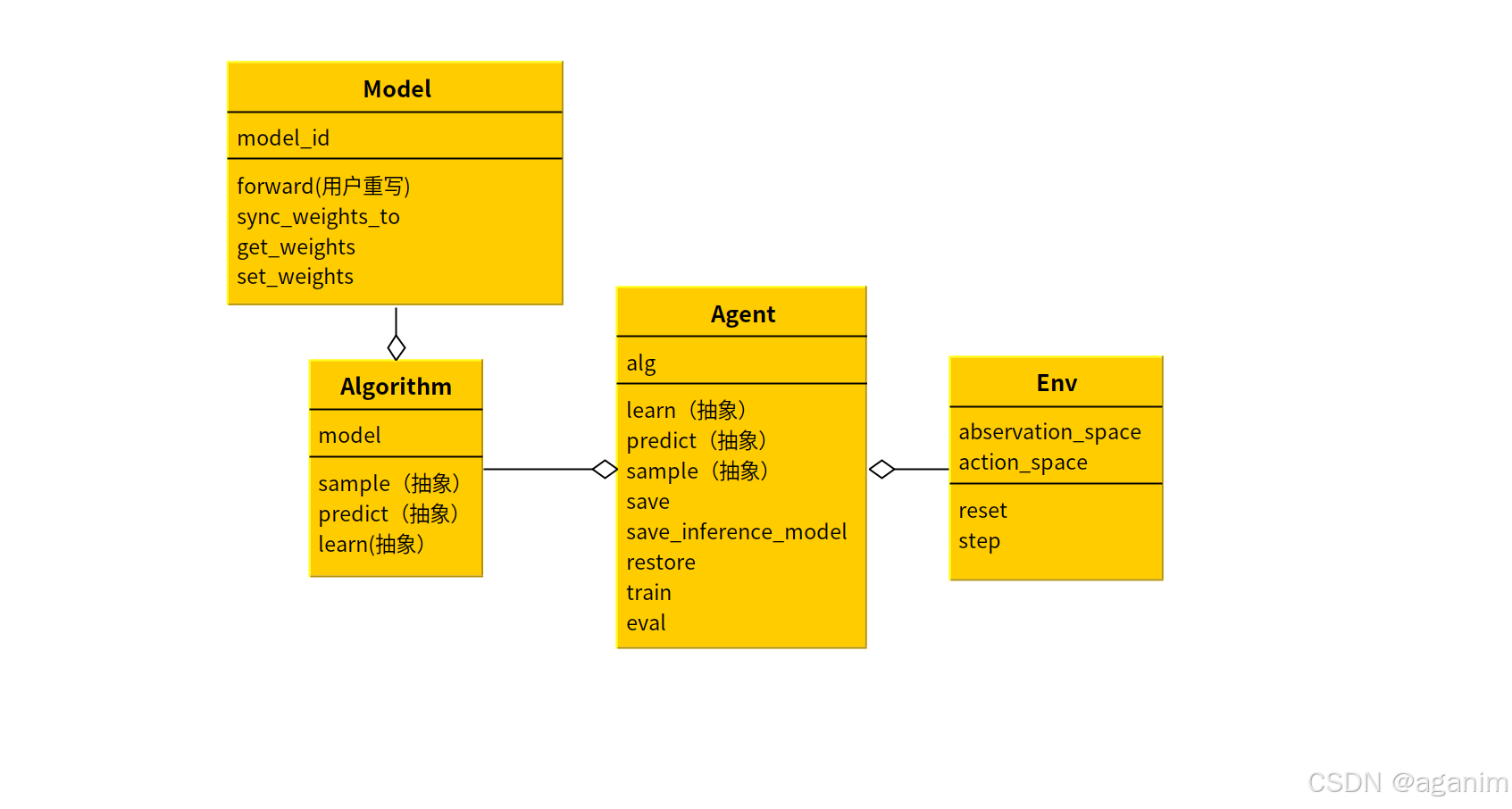
3.1 Model
模型类负责的是使用神经网络表示策略函数π(a∣s)\pi(a|s)π(a∣s)或价值函数Q(s,a)Q(s,a)Q(s,a)或V(s)V(s)V(s),用户要定义深度强化学习中的策略模型或Q网络模型,就可以通过继承该类,重写该类的构造函数和forward函数。其中,forward函数的功能是,给出状态,通过神经网络计算得到输出,输出可能是动作的概率、或各动作的价值。
3.2 Algorithm
这里的Algorithm不应理解为通常意义上的算法,而是在PARL框架下的一个抽象类,它的职责是根据Model属性,在知道状态值的前提下,计算在训练期间应该如何选取与环境交互的动作(sample),预测期间如何选取与环境交互的动作(predic),以及如何根据已知条件(如当前状态、动作、奖励等),更新Model中的参数(learn)。因此,这里的Algorithm是强化学习算法的核心部分,负责对1批或1个环境交互的样本进行计算,以便更新模型参数,或者依据当前模型参数进行训练动作选择或评估性能时的预测动作选择。
3.3 Agent
Agent中有三个抽象方法(严格地说,不是抽象方法),需要用户根据需要去实现,即:如果你需要调用,就去实现它,否则,不用实现。我个人认为,这里的设计不是太清晰。这里的learn和Algorithm中的learn的职责区别在哪里?假设我是架构设计者,我猜测这里的learn更采样指定多步数据进行学习,底层工作还是要调用Algorithm的learn来完成。但由于这里的learn参数为可变参数,因此,没有强行规定。这会导致不同用户才对两个对象的learning理解不一致,而造成代码混乱。
predict和sample设计也具有类似的问题。
在这一点上,还需要改进。tianshou强化学习框架,在这一点上似乎处理得较好。


















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











