







A Survey on Machine Learning from Few Samples
小样本机器学习综述
引用:Lu, Jiang, et al. “A survey on machine learning from few samples.” Pattern Recognition 139 (2023): 109480.
论文链接 :https://arxiv.org/pdf/2009.02653
Abstract 摘要
小样本学习(FSL)在机器学习领域是一项重要且具有挑战性的研究课题。成功从极少量样本中学习和泛化的能力是人工智能与人类智能之间显著的区别,因为人类可以通过单个或少数例子对新事物建立认知,而机器学习算法通常需要数百或数千个有监督的样本来确保泛化能力。尽管小样本学习早在21世纪初就有了悠久的历史,并且近年来随着深度学习技术的快速发展受到了广泛关注,但至今针对小样本学习的调查或综述却寥寥无几。在此背景下,我们对从2000年至2019年期间发表的300多篇关于小样本学习的论文进行了广泛综述,为小样本学习提供了一份及时且全面的综述。在这篇综述中,我们回顾了小样本学习的发展历程和当前进展,并按照基本原理将小样本学习的方法分为生成模型和判别模型两大类,特别强调了基于元学习(Meta Learning)的小样本学习方法。我们还总结了一些近期出现的小样本学习的扩展性主题,并回顾了这些主题的最新进展。此外,我们强调了小样本学习在许多研究热点中的重要应用,包括计算机视觉、自然语言处理、音频与语音、强化学习与机器人、数据分析等领域。最后,我们对未来的发展趋势进行了讨论,希望能为后续研究提供指导和启示。
1 Introduction 引言
人类智能的一个显著标志是能够从单个或少数例子中快速建立对新概念的认知。许多认知和心理学证据1 2 3表明,人类可以通过极少量图像来识别视觉对象4,甚至儿童也能通过一次接触来记住一个新的词汇5 6。虽然究竟是什么支持了人类从极少样本中学习和泛化的能力仍然是一个深奥的谜团,但一些神经生物学研究7 8 9认为,人类卓越的学习能力得益于大脑中的前额皮质(PFC)和工作记忆,特别是前额皮质特有的神经生物机制与大脑中存储的既往经验之间的相互作用。相比之下,大多数最前沿的机器学习算法对数据的需求量非常大,尤其是最为广泛知晓的深度学习10,它将人工智能推向了新的高潮。作为机器学习发展的重要里程碑,深度学习在包括视觉11 12 13、语言1415、语音16、游戏17、人口学18、医学19、植物病理学20和动物学21等一系列研究领域都取得了卓越成就。通常来说,深度学习的成功归功于三个关键因素:强大的计算资源(如GPU)、复杂的神经网络(如卷积神经网络CNN11、长短时记忆网络LSTM22)以及大规模数据集(如ImageNet23、Pascal-VOC24)。然而,在许多实际应用场景中,比如医学、军事和金融领域,受限于隐私、安全或高昂的数据标注成本等因素,无法获得足够的有标签训练样本。因此,几乎所有机器学习研究者都迫切希望能够让学习系统从极少样本中高效学习和泛化。
从更高层面来看,研究小样本学习(FSL)在理论和实践上的意义主要体现在三个方面。首先,FSL方法期望不依赖大规模训练样本,从而避免在某些特定应用中高昂的数据准备成本。其次,FSL可以缩小人类智能与人工智能之间的差距,是开发通用人工智能(universal AI)25所需的重要一步。第三,FSL可以实现对仅有少量样本的新兴任务的低成本和快速模型部署,有助于更早揭示任务中的潜在规律。
尽管小样本学习(FSL)具备这些令人鼓舞的优点,但由于其固有的难度,过去几十年中 FSL 的研究进展相比大样本学习要缓慢得多。我们从优化的角度来说明这一困难。设想一个通用的机器学习问题,它由一个已准备好的监督训练集 D t = { ( x i , y i ) } i = 1 n D_t = \{(x_i, y_i)\}_{i=1}^n Dt={(xi,yi)}i=1n 描述,其中 x ∈ X x \in X x∈X, y ∈ Y y \in Y y∈Y 是从联合分布 P X × Y P_{X \times Y} PX×Y 中抽取的。学习算法的目标是产生一个映射函数 f ∈ F : X → Y f \in F: X \rightarrow Y f∈F:X→Y,使得期望误差 E e x = E ( x , y ) ∼ P X × Y L ( f ( x ) , y ) E_{ex} = E_{(x,y) \sim P_{X \times Y}} L(f(x), y) Eex=E(x,y)∼PX×YL(f(x),y) 最小化,其中 L ( f ( x ) , y ) L(f(x), y) L(f(x),y) 表示将预测值 f ( x ) f(x) f(x) 与其监督目标 y y y 进行比较的损失函数。
实际上,联合分布 P X × Y P_{X \times Y} PX×Y 是未知的,因此学习算法通常旨在最小化经验误差 E e m = E ( x , y ) ∼ D t L ( f ( x ) , y ) E_{em} = E_{(x,y) \sim D_t} L(f(x), y) Eem=E(x,y)∼DtL(f(x),y)。在这种情况下,一个典型的问题是:如果学习算法从中选择函数 f f f 的函数空间 F F F 太大,那么泛化误差 E = ∣ E e x − E e m ∣ E = |E_{ex} - E_{em}| E=∣Eex−Eem∣ 会变大,从而可能导致过拟合问题的出现。
我们可以从以下角度重新审视这个问题:
min
f
E
e
m
,
s.t.
f
(
x
i
)
=
y
i
,
∀
(
x
i
,
y
i
)
∈
D
t
.
(1)
\min_f E_{em}, \quad \text{s.t.} \quad f(x_i) = y_i, \forall (x_i, y_i) \in D_t. \tag{1}
fminEem,s.t.f(xi)=yi,∀(xi,yi)∈Dt.(1)
如果
D
t
D_t
Dt 中包含更多的监督样本,则对
f
f
f 的约束会更多,这意味着函数
f
f
f 所在的空间会更小,从而有助于良好的泛化。相反,稀缺的监督训练集自然会导致较差的泛化性能。本质上,由每个监督样本形成的约束可以被视为对函数
f
f
f 的正则化,它能够压缩函数
f
f
f 冗余的可选空间,从而减少其泛化误差。因此,可以得出结论:如果一个学习算法仅使用基础的学习技术而没有任何复杂的学习策略或特定的网络设计来处理一个小样本学习任务,该学习算法将面临严重的过拟合问题。
小样本学习(Few Sample Learning,FSL),又称小样本或单样本学习(Small or One Sample Learning)、少样本或单次学习(Few-Shot or One-Shot Learning),最早可以追溯到21世纪初。尽管其研究历史接近20年,并且在理论和应用层面具有重要意义,但至今相关的综述或评论却很少。在本文中,我们对从2000年至2019年几乎所有与FSL相关的科学论文进行了广泛研究,旨在阐明FSL系统性的综述。需要强调的是,这里讨论的FSL与零样本学习(Zero-Shot Learning,ZSL)26是正交的,后者是机器学习的另一个热点话题。ZSL的设定涉及特定概念的辅助信息,以支持跨概念知识转移,这与FSL的设定有很大不同。据我们所知,目前只有两篇与FSL相关的预印本综述2728。与它们相比,本文的创新性和贡献主要来自以下五个方面:
- 我们提供了一份更全面且及时的综述,涵盖了从2000年至2019年300多篇与FSL相关的论文,涵盖了从最早的Congealing模型29到最新的元学习(Meta Learning)方法的所有FSL方法。详尽的阐述有助于把握FSL的发展全过程,以及构建FSL的完整知识体系。
- 我们提供了一个易于理解的分层分类法,基于FSL问题的建模原理,将现有的FSL方法划分为基于生成模型的方法和基于判别模型的方法。在每个类别中,我们进一步根据其可泛化特性进行更详细的分类。
- 我们着重介绍了当前主流的FSL方法,即基于元学习的FSL方法,并根据它们希望通过元学习策略学到的内容将其分为五大类:Learn-to-Measure,Learn-to-Finetune,Learn-to-Parameterize,Learn-to-Adjust和Learn-to-Remember。此外,本综述还揭示了各种基于元学习的FSL方法之间的内在发展关系。
- 我们总结了最近涌现的一些超越基础FSL的扩展性研究主题,并回顾了这些主题的最新进展。这些主题包括半监督FSL、无监督FSL、跨领域FSL、广义FSL和多模态FSL,它们虽然具有挑战性,但为解决许多实际的机器学习问题赋予了重要的现实意义。之前的综述很少涉及这些扩展性主题。
- 我们广泛总结了FSL在计算机视觉、自然语言处理、音频和语音、强化学习与机器人、数据分析等各种领域的现有应用,以及FSL在基准测试中的性能,旨在为后续研究提供手册参考,这也是之前综述所未探讨的。
本文的其余部分安排如下:第二节,我们对FSL的整体情况进行概述,包括FSL的发展历程、后续使用的符号和定义,以及提出的现有FSL方法的分类法。基于生成模型的方法和基于判别模型的方法将在第三节和第四节分别详细讨论。随后,在第五节总结了一些FSL的新兴扩展性主题。在第六节中,我们广泛探讨了FSL在各个领域的应用以及FSL在基准测试中的性能表现。最后在第八节,我们对本综述进行了总结并讨论了未来的发展方向。
2 Overview 概述
在本节中,我们首先在第 2.1 节简要回顾 FSL 的演化历史。然后,在第 2.2 节中引入一些符号和定义。最后,我们在第 2.3 节中提供了现有 FSL 方法的高级分类。
2.1 Evolution History 进化历史
机器学习的一般机制是使用在先前准备的训练样本上学习到的统计模型对未来数据进行预测。在大多数情况下,模型的泛化能力是由足够数量的训练样本所保证的。然而,在许多现实应用中,我们可能只能获取非常少量的用于新概念的训练数据,极限情况下,每个概念只有一个样本。例如,我们可能需要识别几种罕见的动物,但由于其稀有性,只有几张带注释的图片。同样地,我们可能需要基于移动传感器信息验证一些新用户的身份,而这些用户的历史使用记录可能只有几条。E. G. Miller 等人在 2000 年首次提出了从极少样本中学习的问题 29,他们假设数字变换共享一个密度,并提出了“凝结算法(Congealing algorithm)”来将测试数字图像与特定类别的凝结数字图像相对应。此后,越来越多的研究投入到了小样本学习(FSL)的领域。
FSL 研究的发展过程可以大致分为两个阶段,非深度阶段(2000 至 2015 年)和深度阶段(2015 年至今),如图 1 所示。分隔这两个阶段的分水岭是 G. Koch 等人在 2015 年首次将深度学习技术与 FSL 问题相结合 30。在此之前,所有针对 FSL 问题提出的解决方案都基于非深度学习,非深度阶段中早期 FSL 的经典方法多基于生成模型。它们试图在非常少的训练样本上估计联合分布 P ( X , Y ) P(X, Y) P(X,Y) 或条件分布 P ( X ∣ Y ) P(X|Y) P(X∣Y),然后从贝叶斯决策的角度为测试样本做出预测。非深度阶段中基于生成模型的 FSL 研究里程碑包括 E. G. Miller 等人的凝结算法 29,L. Fei-Fei 等人提出的变分贝叶斯框架(VBF)31, 32, 33,以及 B. M. Lake 等人提出的贝叶斯程序学习(BPL)34 35 36 37。其中,凝结算法 29 是研究如何从极少样本中学习的最早开创性工作,而 VBF 31 则是首次阐明了“单次学习(one-shot learning)”这一术语。相比较而言,BPL 37 利用人类在认知新概念时具备的组合性、因果性和想象力,实现了与人类水平相当的单次字符分类性能。在非深度阶段中,也有一些基于判别模型的 FSL 方法 38 39 40 41 42 43,尽管在该阶段它们并不是主流。与生成模型相对,基于判别模型的 FSL 方法寻求的是条件分布 P ( Y ∣ X ) P(Y|X) P(Y∣X),它能够在给定一个观察样本时直接预测概率。尽管上述研究取得了一些进展,但 FSL 在非深度阶段的演进依然较为缓慢。
随着深度学习的蓬勃发展,特别是卷积神经网络(CNN)在视觉任务上的巨大成功 11 12 13,许多 FSL 研究者开始从非深度模型转向深度模型。在 2015 年,G. Koch 等人 30 率先将深度学习引入到 FSL 问题的解决方案中,提出了一个基于 Siamese CNN 的方法来学习成对样本间与类别无关的相似度度量,这标志着 FSL 新时代的开始,即深度阶段。此后,随后的 FSL 方法充分利用了深度神经网络在特征表示和端到端模型优化方面的优势,从数据增强 44、度量学习 45 和元学习 46 等不同角度解决 FSL 问题,将 FSL 研究推入了快速发展的新阶段。尽管在深度阶段也提出了一些基于生成模型的方法,如 Neural Statistician 47 和 Sequential Generative Model 48,但基于判别模型的 FSL 方法主导了 FSL 研究的演变。尤其是近年来,大量基于元学习的 FSL 方法如雨后春笋般涌现,包括 O. Vinyals 等人提出的 Matching Nets 49,C. Finn 等人的 MAML 50,S. Ravi 和 H. Larochelle 提出的 Meta-Learner LSTM 51,A. Santoro 等人的 MANN 52,T. Munkhdalai 和 H. Yu 的 MetaNet 53,J. Snell 等人的 Prototypical Nets 54,F. Sung 等人的 Relation Net 55,以及 H. Li 等人的 LGM-Nets 56 等。值得注意的是,元学习策略已成为 FSL 的主流思想。在这个阶段,这些先进的 FSL 方法已被直接应用或改进以应对计算机视觉、自然语言处理、音频和语音、数据分析、机器人等多个领域的各种应用。同时,越来越多与 FSL 相关的具有挑战性的扩展主题,如半监督 FSL、无监督 FSL、跨领域 FSL、广义 FSL 和多模态 FSL,也被挖掘出来。
简而言之,FSL 的发展历史见证了从非深度阶段到深度阶段的转变,生成模型和判别模型之间主流方法的交替,以及经典元学习思想的复兴。如今,与 FSL 相关的研究经常出现在机器学习或其应用的许多顶级会议上,吸引了机器学习社区的广泛关注。
2.2 Notations and Definitions 符号和定义
正式地,我们用 x x x 表示输入数据,用 y y y 表示监督目标,分别用 X X X 和 Y Y Y 表示输入数据的空间和监督目标的空间。一个 FSL 任务 T T T 是由一个特定于 T T T 的数据集 D T = { D trn , D tst } D_T = \{D_{\text{trn}}, D_{\text{tst}}\} DT={Dtrn,Dtst} 描述的,其中 D trn = { ( x i , y i ) } i = 1 N trn D_{\text{trn}} = \{(x_i, y_i)\}_{i=1}^{N_{\text{trn}}} Dtrn={(xi,yi)}i=1Ntrn, D tst = { x j } j = 1 N tst D_{\text{tst}} = \{x_j\}_{j=1}^{N_{\text{tst}}} Dtst={xj}j=1Ntst,且 x i , x j ∈ X T ⊂ X x_i, x_j \in X_T \subset X xi,xj∈XT⊂X, y i ∈ Y T ⊂ Y y_i \in Y_T \subset Y yi∈YT⊂Y。任务 T T T 的样本 x i , x j x_i, x_j xi,xj 来自于特定领域 D T = { X T , P ( X T ) } D_T = \{X_T, P(X_T)\} DT={XT,P(XT)},其中包括数据空间 X T X_T XT 和边缘概率分布 P ( X T ) P(X_T) P(XT)。通常, T T T 中有 C C C 个任务类别,每个类别在 D trn D_{\text{trn}} Dtrn 中只有 K K K 个样本(例如 K = 1 K = 1 K=1 或 K = 5 K = 5 K=5),即 N trn = C × K N_{\text{trn}} = C \times K Ntrn=C×K,因此 T T T 也称为 C C C-way K K K-shot 任务。目标是产生一个目标预测函数 f ∈ F : X → Y f \in F: X \to Y f∈F:X→Y,它能够对 D tst D_{\text{tst}} Dtst 中的测试样本进行预测。基于我们在第 1 节的分析,仅利用稀缺的 D trn D_{\text{trn}} Dtrn 来构建高质量的 f f f 是困难的。因此,在大多数情况下,研究人员可以利用一个监督的辅助数据集 D A = { ( x i a , y i a ) } i = 1 N aux D_A = \{(x_i^a, y_i^a)\}_{i=1}^{N_{\text{aux}}} DA={(xia,yia)}i=1Naux,其中 x i a ∈ X A ⊂ X x_i^a \in X_A \subset X xia∈XA⊂X, y i a ∈ Y A ⊂ Y y_i^a \in Y_A \subset Y yia∈YA⊂Y。该辅助数据集包含了充分的样本和类别( N aux ≫ N trn N_{\text{aux}} \gg N_{\text{trn}} Naux≫Ntrn, ∣ Y A ∣ ≫ ∣ Y T ∣ |Y_A| \gg |Y_T| ∣YA∣≫∣YT∣),这些样本基于先前已知的概念收集而来。需要注意的是, D A D_A DA 不包含属于 T T T 中类别的数据,即 Y T ∩ Y A = ∅ Y_T \cap Y_A = \emptyset YT∩YA=∅,且 D T D_T DT 和 D A D_A DA 的数据来自同一领域,即 D T = D A D_T = D_A DT=DA, X T = X A X_T = X_A XT=XA,且 P ( X T ) = P ( X A ) P(X_T) = P(X_A) P(XT)=P(XA),其中 D A = { X A , P ( X A ) } D_A = \{X_A, P(X_A)\} DA={XA,P(XA)}。这种设定是稳固且合理的,因为 D A D_A DA 很容易从与任务 T T T 相关的许多历史、离线或公开标注良好的数据中获取,尤其是在当今的大数据时代。
基于这些基础,我们给出了 FSL 的统一定义。定义 1(小样本学习) 给定一个由任务特定数据集 D T D_T DT 描述的任务 T T T,其中仅有少量监督信息可用,以及一个与 T T T 无关的辅助数据集 D A D_A DA(如果存在),小样本学习的目标是为任务 T T T 构建一个函数 f f f,该函数使用 D T D_T DT 中的极少量监督信息以及 D A D_A DA 中的知识将输入映射到目标。
上述定义中的“与 T T T 无关”一词意味着 D T D_T DT 和 D A D_A DA 中的目标是正交的,即 Y T ∩ Y A = ∅ Y_T \cap Y_A = \emptyset YT∩YA=∅。如果 D A D_A DA 涵盖了 T T T 中的类别,即 Y T ∩ Y A = Y T Y_T \cap Y_A = Y_T YT∩YA=YT,则 FSL 问题将退化为传统的大样本学习问题。特别地,如果 ∣ Y T ∣ = 2 |Y_T| = 2 ∣YT∣=2,则 T T T 是一个二分类 FSL 任务;如果 ∣ Y T ∣ > 2 |Y_T| > 2 ∣YT∣>2,那么我们称 T T T 为多分类 FSL 任务。此外,基于上述符号和定义,我们总结了 FSL 的几个重要扩展主题。
- 半监督 FSL. 除了 C × K C \times K C×K 个监督样本外, D trn D_{\text{trn}} Dtrn 还包含一些未标记的训练样本。
- 无监督 FSL. 虽然 D A D_A DA 包含来自非任务类别的充足样本,但它是完全无监督的。
- 跨领域 FSL. D T D_T DT 和 D A D_A DA 中的样本来自两个不同的数据域,即 D T ≠ D A D_T \neq D_A DT=DA。
- 广义 FSL. 函数 f f f 被要求在联合标签空间 Y T ∪ Y A Y_T \cup Y_A YT∪YA 上进行推断,而不是仅在单一的 Y T Y_T YT 上。
- 多模态 FSL. 它有两种情况:多模态匹配和多模态融合。在前一种情况下,标记样本对 ( x i , y i ) (x_i, y_i) (xi,yi) 中的目标 y i y_i yi 不是简单的类别标签,而是来自与输入 x i x_i xi 不同模态的另一个数据。在后一种情况下,为属于其他模态的输入 x i x_i xi 提供了额外的信息 I i I_i Ii。
关于上述五个扩展主题的详细问题描述和文献综述,我们将在第 5 节中给出。
2.3 Taxonomy 分类
如图 1 所示,我们根据 FSL 问题的建模原则将 FSL 方法组织为两大类,即基于生成模型的方法和基于判别模型的方法。对于一个测试样本
x
j
x_j
xj,所有 FSL 解决方案都追求以下能够预测类别后验概率的统计模型:
y
^
j
=
arg
max
y
∈
Y
T
p
(
y
∣
x
j
)
,
(2)
\hat{y}_j = \arg \max_{y \in Y_T} p(y|x_j), \tag{2}
y^j=argy∈YTmaxp(y∣xj),(2)
其中
y
^
j
\hat{y}_j
y^j 表示该模型预测的目标。基于判别模型的 FSL 方法旨在直接建模后验概率
p
(
y
∣
x
)
p(y|x)
p(y∣x),将
x
x
x 作为判别模型的输入,输出
x
x
x 属于
C
C
C 个任务类别之一的概率分布。相反,基于生成模型的方法则使用贝叶斯决策来解决此问题:
p
(
y
∣
x
)
=
p
(
x
∣
y
)
p
(
y
)
p
(
x
,
y
)
.
p(y|x) = \frac{p(x|y)p(y)}{p(x, y)}.
p(y∣x)=p(x,y)p(x∣y)p(y).因此,式 (2) 中对后验概率的最大化转换为:
y
^
j
=
arg
max
y
∈
Y
T
p
(
x
j
∣
y
)
p
(
y
)
,
(3)
\hat{y}_j = \arg \max_{y \in Y_T} p(x_j|y)p(y), \tag{3}
y^j=argy∈YTmaxp(xj∣y)p(y),(3)
其中
p
(
y
)
p(y)
p(y) 是目标类别的先验分布,
p
(
x
j
∣
y
)
p(x_j|y)
p(xj∣y) 是给定类别
y
y
y 时数据的条件分布。在大多数情况下,
p
(
y
)
p(y)
p(y) 被认为是类别之间的均匀分布,或者根据不同类别中数据的频率比率计算。因此,基于生成模型的 FSL 方法的核心目标是比较
p
(
x
∣
y
)
,
y
∈
Y
T
p(x|y), y \in Y_T
p(x∣y),y∈YT。
对于生成模型类别,研究人员通过某些中间潜在变量在 x x x 和 y y y 之间建立联系,以便可以数学计算条件分布 p ( x ∣ y ) p(x|y) p(x∣y)。该类别中的大多数 FSL 方法需要对潜在变量的分布做出必要的假设。我们将在第 3 节简要讨论基于生成模型的方法。
对于判别模型类别,总结了三种主流方法,包括数据增强、度量学习和元学习。根据是否使用额外的监督信息(如属性注释、词嵌入等),增强方法进一步分为有监督增强和无监督增强。作为近年来处理 FSL 问题最热门的方式,基于元学习的方法涉及从多种角度实现“学习如何学习”的目标。我们根据元学习策略背后希望被元学习的内容,将现有的基于元学习的 FSL 方法划分为五大类:Learn-to-Measure(学习度量)、Learn-to-Finetune(学习微调)、Learn-to-Parameterize(学习参数化)、Learn-to-Adjust(学习调整)和 Learn-to-Remember(学习记忆)。从广义上讲,Learn-to-Measure 方法属于度量学习的范畴,因为它们都追求一种使同类样本接近、异类样本分离的度量空间。即便如此,我们将 学习度量 方法归入元学习的一个重要依据是它们使用了元学习策略。此外,还有其他一些细分方向用于解决 FSL 问题。我们将在第 4 节回顾基于判别模型的 FSL 方法。
3 Generative model based approaches 基于生成模型的方法
如第 2.3 节所述,基于生成模型的 FSL 方法试图建模后验概率
p
(
x
∣
y
)
p(x|y)
p(x∣y)。然而,在大多数情况下,数据
x
x
x 和目标
y
y
y 之间的概率关系并不直接。例如,在小样本图像分类中,
x
x
x 表示一张图像,
y
y
y 表示其类别标签,它们之间的数学关系无法直接描述。为了在
x
x
x 和
y
y
y 之间建立联系,一个可行的策略是引入一个中间潜在变量
z
z
z,如下所示:
p
(
x
∣
y
)
=
∫
z
p
(
x
,
z
∣
y
)
d
z
=
∫
z
p
(
z
∣
y
)
p
(
x
∣
z
,
y
)
d
z
.
(4)
p(x|y) = \int_z p(x, z|y) dz = \int_z p(z|y) p(x|z, y) dz. \tag{4}
p(x∣y)=∫zp(x,z∣y)dz=∫zp(z∣y)p(x∣z,y)dz.(4)
几乎所有基于生成模型的 FSL 方法都遵循这一高层策略,尽管它们在具体的
z
z
z 形式上可能有所不同。以下总结了
z
z
z 的几种经典形式。
-
Transformation 转换
作为首个尝试从一个样本中学习的工作,Congealing 算法 29 假设每个数字类别都存在一个潜在图像,该类别的所有观察到的图像都是通过某些底层变换 z tran z_{\text{tran}} ztran 从潜在图像生成的。此外,变换的密度被假设在不同类别之间是共享的,这意味着变换概率与类别无关。因此,式 (4) 可以写为:
p ( x ∣ y ) = ∫ z tran p ( z tran ) p ( x ∣ z tran , y ) d z tran . (5) p(x|y) = \int_{z_{\text{tran}}} p(z_{\text{tran}}) p(x|z_{\text{tran}}, y) dz_{\text{tran}}. \tag{5} p(x∣y)=∫ztranp(ztran)p(x∣ztran,y)dztran.(5)
重要的是, p ( z tran ) p(z_{\text{tran}}) p(ztran) 可以在辅助集 D A D_A DA 上学习。我们必须强调,Congealing 算法仅适用于简单的数字或字母字符灰度图像,因为对其他自然 RGB 图像来说,数学上建模这种类别共享的变换是不现实的。 -
Parameters 参数
VBF 31 32 33 使用概率模型来衡量一个物体存在于 RGB 图像中的概率。概率模型涉及许多需要学习的参数 z para z_{\text{para}} zpara。因此,VBF 使用所谓的星座模型(constellation model)来定义 p ( z para ∣ y ) p(z_{\text{para}}|y) p(zpara∣y),并利用变分方法在辅助集 D A D_A DA 上估计 z para z_{\text{para}} zpara。 -
Superclass 超类
在文献 57 中,通过在类别之上引入超类关系,提出了一种分层贝叶斯(Hierarchical Bayesian, HB)模型。其核心思想是,同一超类下的类别继承相同的相似度度量。通过引入超类变量 z sup z_{\text{sup}} zsup,式 (4) 可以转化为:
p ( x ∣ y ) = ∑ z sup p ( z y sup ) p ( x ∣ z y sup ) , (6) p(x|y) = \sum_{z_{\text{sup}}} p(z_{y_{\text{sup}}}) p(x|z_{y_{\text{sup}}}), \tag{6} p(x∣y)=zsup∑p(zysup)p(x∣zysup),(6)
其中 p ( z y sup ) = p ( z sup ∣ y ) p(z_{y_{\text{sup}}}) = p(z_{\text{sup}}|y) p(zysup)=p(zsup∣y) 是 y y y 所属的超类的先验分布, p ( x ∣ z y sup ) = p ( x ∣ z sup , y ) p(x|z_{y_{\text{sup}}}) = p(x|z_{\text{sup}}, y) p(x∣zysup)=p(x∣zsup,y) 是条件于超类 z y sup z_{y_{\text{sup}}} zysup 的数据分布。 -
Programs 程序
BPL 34, 35, 36, 37 使用贝叶斯过程(Bayesian Process)将字符对象的生成过程建模为一个概率程序。该程序对基本元素、子部分、部分、类型、符号和图像进行自下而上的解析分析。此外,生成程序中的中间类型和符号被视为潜在变量 z prog z_{\text{prog}} zprog。通过为每个字符概念明确建模概率程序,BPL 能够捕捉字符对象的组合性和因果性,并可以执行单次分类、基于一个样本生成新的示例以及生成新的字符类别。 -
Splits 分割
Chopping 模型 58 引入了辅助集 D A D_A DA 的随机数据分割,作为潜在变量 z spl z_{\text{spl}} zspl,以建立原始图像 x x x 和标签 y y y 之间的数学依赖。该模型通过将辅助类别的一半赋予标签 1,另一半赋予标签 0,对 D A D_A DA 进行了多次分割,然后为每个分割训练一个预测器。对于 D T D_T DT 中的一幅图像,Chopping 模型会将所有分割特定的预测器的预测结果结合起来,以实现贝叶斯后验决策。 -
Reconstruction 重构
与 BPL 34, 35, 36, 37 不同,文献 59 提出了一个不依赖字符图像中动态笔画知识的组合式补丁模型(Compositional Patch Model, CPM)。与 BPL 类似,该模型的核心假设是同类字符图像共享相同的基于补丁的结构。因此,该模型首先将每个类别在 D trn D_{\text{trn}} Dtrn 中的单个样本分割为一组组件,然后利用 AND-OR 图来重构 D tst D_{\text{tst}} Dtst 中的测试样本。重构本质上是潜在变量 z rec z_{\text{rec}} zrec,用于对测试样本进行最终的单次分类。 -
Statistics 统计
Neural Statistician 模型 60 部署了一个深度网络来生成描述每个 D trn D_{\text{trn}} Dtrn 的生成模型的统计量。具体而言,这些统计量由均值和方差描述,指定了潜在空间中的高斯分布。利用潜在变量 z stat z_{\text{stat}} zstat,Neural Statistician 可以实现单次生成和分类。
表 1 对上述主流基于生成模型的小样本学习(FSL)方法进行了直观的比较,这些方法从不同角度构建了潜在变量 z z z。除了 Neural Statistician 以外,其他方法均产生于 FSL 发展的非深度阶段,其中大多数是针对特定任务形式或数据形式量身定制的,缺乏对更一般情况的可扩展性。此外,这些早期工作在不同的实验数据集和评估设置下进行验证,当时尚未为后续 FSL 研究形成可比较的基准。
表 1 不同基于生成模型的小样本学习(FSL)方法总结
| 方法 | 潜在变量 | 任务类型 | 实验数据集 | 备注 |
|---|---|---|---|---|
| Congealing 29 | 变换 z tran z_{\text{tran}} ztran | 多分类图像分类 | NIST Special Database 19 61 | FSL 的创始方法/仅适用于简单的数字或字母字符灰度图像 |
| VBF 31 32 33 | 参数 z para z_{\text{para}} zpara | 二分类图像分类 | Caltech 4 数据集 31 62, Caltech 101 数据集 32, 33 | 首个提出“一次学习”的工作/难以适应多分类任务 |
| HB 57 | 超类 z sup z_{\text{sup}} zsup | 二分类图像分类 | MNIST 63, MSR Cambridge 数据集 57 | 依赖于类别间的底层层次关系/难以适应多分类任务 |
| BPL 34 35 36 37 | 程序 z prog z_{\text{prog}} zprog | 多分类图像分类,图像生成 | Omniglot 37 | 需要字符对象的动态笔画信息和生成规则 |
| Chopping 58 | 分割 z spl z_{\text{spl}} zspl | 二分类图像分类 | COIL-100 数据库 64, LaTeX 符号 58 | 类似于概率“集成”方法/难以适应多分类任务 |
| CPM 59 | 重构 z rec z_{\text{rec}} zrec | 多分类图像分类 | MNIST 63, USPS 65 | 仅适用于简单的数字或字母字符灰度图像/不需要辅助集 D A D_A DA |
| Neural Statistician 60 | 统计 z stat z_{\text{stat}} zstat | 多分类图像分类,图像生成 | MNIST 63, Omniglot 37, YouTube Faces 数据库 66 | 变分自编码器的扩展/包含一些深度神经网络 |
4 Discriminative Model Based Approaches 基于判别模型的方法
与上述基于生成模型的小样本学习(FSL)方法不同,基于判别模型的 FSL 方法试图直接通过稀缺的训练集 D trn D_{\text{trn}} Dtrn 来为任务 T T T 建模后验概率 p ( y ∣ x ) p(y|x) p(y∣x)。用于 p ( y ∣ x ) p(y|x) p(y∣x) 的计算模型通常包含特征提取器和预测器。例如,对于小样本图像识别任务,特征提取器和预测器分别可能是卷积神经网络(CNN)和 softmax 层。由于 D trn D_{\text{trn}} Dtrn 中样本稀缺,在仅利用 D trn D_{\text{trn}} Dtrn 进行 p ( y ∣ x ) p(y|x) p(y∣x) 拟合时,很容易陷入过拟合。因此,现有的基于判别模型的 FSL 方法从不同的角度追求构建 p ( y ∣ x ) p(y|x) p(y∣x)。我们将其总结为以下几类。
第一类是基于增强的方法,该方法主张从辅助数据集
D
A
D_A
DA 学习一个通用的增强函数
A
(
⋅
)
A(\cdot)
A(⋅),以增强
D
trn
D_{\text{trn}}
Dtrn 中样本或样本特征。基于增强的 FSL 方法在第 4.1 节进行了回顾。
第二类是基于度量学习的方法,其目的是在
D
A
D_A
DA 上学习一个成对的相似度度量
S
(
⋅
,
⋅
)
S(\cdot, \cdot)
S(⋅,⋅)。借助该度量,可以使用最近邻分类器进行最终预测。基于度量学习的 FSL 方法在第 4.2 节进行了介绍。
第三类是基于元学习的方法,该方法利用
D
A
D_A
DA 构建与任务
T
T
T 类似的许多任务,并采用跨任务训练策略来提炼一些可迁移的模型、算法或参数。基于元学习的 FSL 方法在第 4.3 节详细介绍。
此外,还有一些其他的 FSL 方法,在第 4.4 节中讨论。
4.1 Augmentation 数据增强
增强是一种直观的方法,可以增加训练样本的数量并提高数据多样性。在视觉领域,一些基本的增强操作包括旋转、翻转、裁剪、平移以及在图像中添加噪声 11 67 68。对于 FSL 任务,这些低级别的增强手段不足以显著提升 FSL 模型的泛化能力。在这种情况下,针对 FSL 定制的更复杂的增强模型、算法或网络被提出,它们主要出现在 FSL 发展的深度阶段。图 2 展示了基于增强的 FSL 方法的一般框架。除了 DAGAN 69 在数据层面对
D
trn
D_{\text{trn}}
Dtrn 中的样本进行增强外,其他方法均在特征层面对任务
T
T
T 中的训练样本进行增强。根据增强是否依赖外部辅助信息(如语义属性 70、词向量 71 等),我们进一步将现有的基于增强的 FSL 方法分为有监督和无监督两类。

图2. 基于增强的FSL方法的总体框架
4.1.1 Supervised Augmentation 有监督数据增强
一些基于有监督增强的小样本学习(FSL)方法包括 Feature Trajectory Transfer(FTT)72、AGA 73、Dual TriNet 74, 75、Author-Topic(AT)42 和 ABS-Net 76。为了简化符号,设 Ω fe \Omega_{\text{fe}} Ωfe 为特征空间, Ω si \Omega_{\text{si}} Ωsi 为辅助信息空间。这些方法所学习的增强 A ( ⋅ ) A(\cdot) A(⋅) 本质上是 Ω fe \Omega_{\text{fe}} Ωfe 和 Ω si \Omega_{\text{si}} Ωsi 之间的映射关系,尽管它们在映射方向和映射模块上有所不同,如图 3 所示。

图3. 不同监督增强方法中特征与辅助信息之间的映射关系
FTT 72 主要针对单样本场景图像分类,利用场景图像中的连续属性(例如“下雨”、“黑暗”或“晴朗”)为单样本任务场景类别定向合成特征。具体而言,FTT 建议在辅助场景类别上学习一个线性映射轨迹,将属性
a
∈
R
+
a \in \mathbb{R}^+
a∈R+ 映射到特征
x
∈
R
d
x \in \mathbb{R}^d
x∈Rd:
x
=
w
⋅
a
+
b
+
ϵ
,
(7)
x = w \cdot a + b + \epsilon, \tag{7}
x=w⋅a+b+ϵ,(7)
其中
w
,
b
∈
R
d
w, b \in \mathbb{R}^d
w,b∈Rd 是可学习的参数,
ϵ
\epsilon
ϵ 表示高斯噪声。该映射轨迹被期望能够从辅助类别迁移到任务类别。如图 4 所示,给定一个任务场景类别的一个训练样本,可以人为设定其属性的强度(例如“晴朗”的程度),通过在式 (7) 中学到的线性映射轨迹生成许多合成特征。然而,我们必须注意到 FTT 需要精细且连续的属性注释,这会带来极高的数据准备成本。

图4. 特征轨迹传递(FTT)72示意图。每个场景图像右上角的数字表示“晴朗”程度
相比之下,AGA 73 开发了一个编码器-解码器网络,将样本的特征映射为具有不同属性强度的另一种合成特征。例如,如图 5 所示,AGA 旨在在辅助类别(例如桌子、椅子)上学习一个类无关的特征传递模块
ϕ
3
[
1
,
2
]
\phi_{3[1,2]}
ϕ3[1,2],该模块以深度在 1-2 [m] 范围内的物体特征为输入,输出深度为 3 [m] 的合成特征。使用该特征传递模块,可以用不同的深度强度增强任务类别的单个样本。这个想法与 FTT 72 类似,但存在两个不同之处。首先,AGA 的映射方向为
Ω
fe
→
Ω
fe
\Omega_{\text{fe}} \to \Omega_{\text{fe}}
Ωfe→Ωfe,而 FTT 的映射方向为
Ω
si
→
Ω
fe
\Omega_{\text{si}} \to \Omega_{\text{fe}}
Ωsi→Ωfe。其次,FTT 中的特征合成是通过将所需的属性强度直接分配给其线性映射模型来指导的,而 AGA 中的特征合成是通过专门在两个明确属性强度之间进行特征映射的编码器-解码器网络来实现的。
![图5. 属性引导增强(AGA)[73]示意图。深度是属性,桌子和椅子是两个辅助类别。φ3 [1,2] 是一个编码器-解码器网络,它将深度在1-2 [m] 范围内的物体特征转换为深度为3 [m] 的另一特征](https://i-blog.csdnimg.cn/direct/0f793e39014446f1ab400e546e7ec343.png#pic_center)
图5. 属性引导增强(AGA)73示意图。深度是属性,桌子和椅子是两个辅助类别。
φ
3
[
1
,
2
]
φ3_[1,2]
φ3[1,2] 是一个编码器-解码器网络,它将深度在1-2 [m] 范围内的物体特征转换为深度为3 [m] 的另一特征
同样地,Dual TriNet 74 75 也利用编码器-解码器网络实现特征级别的增强。除了它们所用的编码器-解码器网络结构不同(Dual TriNet 使用 CNN,而 AGA 使用 MLP),另一个主要区别在于编码器和解码器之间的瓶颈嵌入:Dual TriNet 的瓶颈嵌入是语义属性或词向量,而 AGA 的则是普通的潜在嵌入。Dual TriNet 将瓶颈嵌入空间建模为语义高斯(Semantic Gaussian)或语义邻域(Semantic Neighbourhood),其中可以采样大量语义向量并将其解码为合成特征。从这个角度来看,Dual TriNet 的映射方向为 Ω fe → Ω si → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{si}} \to \Omega_{\text{fe}} Ωfe→Ωsi→Ωfe。
AT 42 使用主题模型 77 来建模图像与属性之间的关系,将每个图像视为包含多个主题(即属性)的文档,而每个主题由单词(即特征)的概率分布表示。这个概率分布的参数在辅助数据集 D A D_A DA 上进行估计。通过显式的分布,可以根据特定类别的属性生成大量该类别的特征。
ABS-Net 76 首先在辅助数据集 D A D_A DA 上进行属性学习过程,建立一个属性特征库。给定某个类别的属性描述,在该特征库上执行概率采样操作,将属性映射到该类别的伪特征。
表 2 的顶部总结了这些基于有监督增强的 FSL 方法的主要特征。考虑到辅助信息的标注成本,以上方法更适用于包含一些辅助信息的任务或数据集。
| 方法 | 辅助信息 | 映射方向 | 映射模块 | 任务类型 | 实验数据集 |
|---|---|---|---|---|---|
| FTT 72 | 瞬时属性 (rainy, sunny 等) | Ω si → Ω fe \Omega_{\text{si}} \to \Omega_{\text{fe}} Ωsi→Ωfe | 线性模型 | 场景位置分类 | Transient Attributes Database (TADB) 78, SUN Attributes Database (SADB) 79 |
| AGA 73 | 属性强度 (depth, pose) | Ω fe → Ω si → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{si}} \to \Omega_{\text{fe}} Ωfe→Ωsi→Ωfe | 编码器-解码器网络 (MLP) | 2D/3D 对象分类 | SUN RGB-D 80 |
| AT 42 | 离散属性 (black, fierce 等) | Ω si → Ω fe \Omega_{\text{si}} \to \Omega_{\text{fe}} Ωsi→Ωfe | 概率分布 | 图像分类 | Animals with Attributes (AwA) 81 |
| Dual TriNet 74 75 | 词向量,离散属性 | Ω fe → Ω si → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{si}} \to \Omega_{\text{fe}} Ωfe→Ωsi→Ωfe | 编码器-解码器网络 (CNN) | 图像分类 | miniImageNet 49, Cifar-100 82, CUB 83, Caltech-256 84 |
| ABS-Net 76 | 离散属性 (ForColor, BackColor) | Ω si → Ω fe \Omega_{\text{si}} \to \Omega_{\text{fe}} Ωsi→Ωfe | 概率采样 | 图像分类 | Colored MNIST 76 |
| GentleBoostKO 39 | – | Ω fe → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{fe}} Ωfe→Ωfe | knockout(特征元素替换) | 二分类图像分类 | Caltech 数据集 85 |
| SH 86 | – | Ω fe → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{fe}} Ωfe→Ωfe | 基于四元组的 MLP(3 个特征 → 1 个特征) | 图像分类 | ImageNet1k 23 |
| Hallucinator 87 | – | Ω fe → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{fe}} Ωfe→Ωfe | 基于 MLP 的生成器(1 个特征 → 1 个特征) | 图像分类 | ImageNet1k 23 |
| CP-ANN 88 | – | latent space → Ω fe \Omega_{\text{fe}} Ωfe | GAN | 图像分类 | ImageNet1k 23 |
| Δ \Delta Δ-encoder 89 | – | Ω fe → Ω fe \Omega_{\text{fe}} \to \Omega_{\text{fe}} Ωfe→Ωfe | 编码器-解码器网络 (MLP)(3 个特征 → 1 个特征) | 图像分类 | miniImageNet 49, Cifar-100 82, CUB 83, Caltech-256 84, AwA 81, aPascal&aYahoo (APY) 90 |
| DAGAN 69 | – | Ω da → Ω da \Omega_{\text{da}} \to \Omega_{\text{da}} Ωda→Ωda | GAN | 图像生成,图像分类 | Omniglot 37, EMNIST 91, VGG-Faces 92 |
| IDeMe-Net 93 | – | Ω da → Ω da \Omega_{\text{da}} \to \Omega_{\text{da}} Ωda→Ωda | Deformation 子网络 (2 images → 1 images) | 图像分类 | ImageNet1k 23, miniImageNet 49 |
4.1.2 Unsupervised Augmentation 无监督数据增强
典型的基于无监督增强的小样本学习(FSL)方法包括 GentleBoostKO 39、Shrinking and Hallucinating(SH)86、Hallucinator 87、CP-ANN 88、 Δ \Delta Δ-encoder 89、DAGAN 69 和 IDeMe-Net 93 等,它们寻求在没有任何外部辅助信息的情况下增强数据或特征。
GentleBoostKO 39 是一种在早期非深度阶段提出的直接 FSL 解决方案,通过一个 knockout 程序合成特征。knockout 通过用同一坐标中另一个特征的元素替换特征的一个元素来实现。其核心思想是创建损坏的样本副本,以增加鲁棒性。
SH 86 的设计灵感在于类内变化可以跨类别进行泛化(例如姿势变换),这与 FTT 72 和 AGA 73 的直觉类似。它们之间的区别在于 FTT 72 和 AGA 73 中的类内变化可以由辅助信息(例如“晴朗”属性的强度、物体的深度值)显式描述,而 SH 中的类内变化需要从隐式变换类比中挖掘出来,并以四元组
(
f
a
1
,
f
a
2
,
f
b
1
,
f
b
2
)
(f_{a_1}, f_{a_2}, f_{b_1}, f_{b_2})
(fa1,fa2,fb1,fb2) 的形式表示,如图 6 所示,其中
a
,
b
a, b
a,b 表示两个类别。这些四元组通过无监督聚类和许多启发式步骤从辅助集挖掘出来。此外,可以基于这些四元组学习一个基于 MLP 的映射模块
G
G
G,其以三个特征为输入并输出一个合成特征,即
f
^
b
2
=
G
(
f
a
1
,
f
a
2
,
f
b
1
)
\hat{f}_{b_2} = G(f_{a_1}, f_{a_2}, f_{b_1})
f^b2=G(fa1,fa2,fb1)。给定任务类别的一个训练样本,可以通过
G
G
G 类比地推导出该类别的其他合成特征。

Fig. 7. Hallucinator 87的框架.
D
Gtrn
D_{\text{Gtrn}}
DGtrn: 增强样本集.
Δ \Delta Δ-encoder 89 的高层动机与 AGA 73、FTT 72 和 SH 86 类似。它同样建议从辅助集 D A D_A DA 中提取可迁移的类内变化(称为 Δ \Delta Δ),并将该变化应用于新任务类别,以便为任务类别合成新的样本。与 SH 86 类似, Δ \Delta Δ-encoder 也基于底层的四元组类比进行 Δ \Delta Δ 的迁移,主要区别在于处理四元组关系的具体映射模块:SH 86 使用了一个简单的 MLP,而 Δ \Delta Δ-encoder 开发了一个编码器-解码器网络,其瓶颈嵌入被期望捕捉类内变化 Δ \Delta Δ。
如图 7 所示,Hallucinator 87 使用基于 MLP 的生成器 G G G 为 D trn D_{\text{trn}} Dtrn 中的训练样本增强特征,即 f ^ = G ( f , z ) \hat{f} = G(f, z) f^=G(f,z),其中 f f f 是原始特征, z z z 是噪声向量。这个生成器被设计为一个即插即用的模块,可以与多种现成的基于元学习的模块相结合,例如 Matching Nets 49、Prototypical Nets 54 或 Prototype Matching Nets 87。基于元学习的 FSL 方法将在第 4.3 节进行回顾。
CP-ANN 88 通过基于生成对抗网络(GAN)94 的集对集翻译实现了对少量支持样本的特征增强,该方法旨在保持增强过程中辅助样本的协方差。DAGAN 69 以 D trn D_{\text{trn}} Dtrn 中的样本作为输入,通过条件 GAN 直接生成类内数据(即 Ω da → Ω da \Omega_{\text{da}} \to \Omega_{\text{da}} Ωda→Ωda)。Z. Chen 等人 93 认为两个相似图像之间的视觉融合可能保留重要的语义信息,有助于形成最终分类器的决策边界,因此提出了 IDeMe-Net 来生成少量支持样本的变形图像。与 Hallucinator 87 类似,DAGAN 69 和 IDeMe-Net 93 也被设计为可以与其他现成的基于元学习的 FSL 方法(如 Matching Nets 49 和 Prototypical Nets 54)协同工作。表 2 底部对以上基于无监督增强的 FSL 方法进行了高层总结。
4.1.3 Discussion 讨论
我们必须强调,基于增强的小样本学习(FSL)方法与其他 FSL 方法(例如基于度量学习或元学习的方法,分别将在第 4.2 节和第 4.3 节中讨论)并不冲突。相反,大多数基于增强的 FSL 方法与它们是互补的,并且可以作为即插即用的模块:人们可以首先采用这些增强策略来丰富 D trn D_{\text{trn}} Dtrn,然后通过其他 FSL 方法在增强后的 D trn aug D_{\text{trn}}^{\text{aug}} Dtrnaug 上进行学习。
4.2 Metric Learning 度量学习
度量学习(metric learning) 45 的一般目标是学习一个成对相似度度量
S
(
⋅
,
⋅
)
S(\cdot, \cdot)
S(⋅,⋅),使得相似样本对获得高相似度分数,而不相似的样本对获得低相似度分数。所有基于度量学习的少样本学习(Few-Shot Learning, FSL)方法都遵循这一原则,如图8所示,它们利用辅助数据集
D
A
D_A
DA 创建相似度度量并将其泛化到任务 $$ 的新类别中。相似度度量可以是简单的距离度量、高级网络或其他能够估计样本或特征间成对相似度的模块或算法。几种代表性的基于度量学习的 FSL 方法包括 Class Relevance Metrics (CRM) 38、KernelBoost 95、Siamese Nets 30、Triplet Ranking Nets 96、Skip Residual Pairwise Net (SRPN) 97、Memory Module (MM) 98 和 AdaptHistLoss 99。这些方法针对 FSL 任务开发了与不同度量损失函数相关的多种形式的相似度度量。

图8.基于度量学习的fsl方法的总体框架。
CRM 38 是一种在非深度学习时代提出的基于度量学习的 FSL 方法基础工作。它使用马氏距离(Mahalanobis distance)来测量成对相似度:
d
(
x
i
,
x
j
)
=
(
x
i
−
x
j
)
⊤
A
(
x
i
−
x
j
)
=
∥
W
x
i
−
W
x
j
∥
2
,
(8)
d(x_i, x_j) = \sqrt{(x_i - x_j)^\top A (x_i - x_j)} = \|W x_i - W x_j\|_2, \tag{8}
d(xi,xj)=(xi−xj)⊤A(xi−xj)=∥Wxi−Wxj∥2,(8)
其中
A
=
W
⊤
W
A = W^\top W
A=W⊤W 是一个需要从辅助数据集
D
A
D_A
DA 中学习的对称正半定矩阵。CRM 的学习目标遵循合页损失(hinge loss)的形式,使得正样本对
(
x
i
,
x
i
+
)
(x_i, x_i^+)
(xi,xi+) 的距离小于负样本对
(
x
j
,
x
j
−
)
(x_j, x_j^-)
(xj,xj−) 的距离至少为
γ
\gamma
γ:
d
(
x
i
,
x
i
+
)
≤
d
(
x
j
,
x
j
−
)
−
γ
.
(9)
d(x_i, x_i^+) \leq d(x_j, x_j^-) - \gamma. \tag{9}
d(xi,xi+)≤d(xj,xj−)−γ.(9)
一旦在
D
A
D_A
DA 上训练完成,马氏距离将被应用于任务
T
T
T 来实现最近邻(NN)分类。
KernelBoost 95 建议通过提升算法(boosting algorithm)以核函数(kernel function)的形式学习成对距离。核函数定义为若干弱核函数的组合:
K
(
x
i
,
x
j
)
=
∑
t
=
1
T
α
t
K
t
(
x
i
,
x
j
)
.
K(x_i, x_j) = \sum_{t=1}^T \alpha_t K_t(x_i, x_j).
K(xi,xj)=∑t=1TαtKt(xi,xj). 每个弱核函数
K
t
(
⋅
,
⋅
)
K_t(\cdot, \cdot)
Kt(⋅,⋅) 学习数据的高斯混合模型(Gaussian Mixture Model, GMM),并且
K
t
(
x
i
,
x
j
)
K_t(x_i, x_j)
Kt(xi,xj) 表示样本
x
i
x_i
xi 和
x
j
x_j
xj 属于第
t
t
t 个 GMM 内相同高斯成分的概率。核函数
K
K
K 通过指数损失优化:
L
=
∑
i
,
j
exp
(
−
y
i
j
K
(
x
i
,
x
j
)
)
,
(10)
\mathcal{L} = \sum_{i,j} \exp(- y_{ij} K(x_i, x_j)), \tag{10}
L=i,j∑exp(−yijK(xi,xj)),(10)
其中
y
i
j
y_{ij}
yij 当
x
i
x_i
xi 和
x
j
x_j
xj 属于同一类别时为 1,否则为 -1。最终可以形成一个核最近邻(kernel NN)分类器。
Siamese Nets 30 是第一个将深度神经网络引入 FSL 任务的工作。它由共享相同权重的孪生卷积神经网络(CNN)组成。孪生 CNN 接受样本对
(
x
i
,
x
j
)
(x_i, x_j)
(xi,xj) 作为输入,在顶层将输出组合起来以输出单一的成对相似度分数
p
(
x
i
,
x
j
)
p(x_i, x_j)
p(xi,xj),如图9所示。孪生 CNN 通过以下二值交叉熵损失(binary cross-entropy loss)进行训练:
L
=
∑
i
,
j
y
i
j
log
p
(
x
i
,
x
j
)
+
(
1
−
y
i
j
)
log
(
1
−
p
(
x
i
,
x
j
)
)
,
(11)
\mathcal{L} = \sum_{i,j} y_{ij} \log p(x_i, x_j) + (1 - y_{ij}) \log(1 - p(x_i, x_j)), \tag{11}
L=i,j∑yijlogp(xi,xj)+(1−yij)log(1−p(xi,xj)),(11)
其中
y
i
j
=
1
y_{ij} = 1
yij=1 当
x
i
x_i
xi 和
x
j
x_j
xj 属于同一类别时,否则为 0。训练好的孪生 CNN 被固定下来,作为一个固定的相似度度量,在 FSL 任务 $$ 上以最近邻方式进行推断。
![图 9. 孪生网络的架构 [30]。孪生cnns共享权重。](https://i-blog.csdnimg.cn/direct/bf1a9558dffe483ba9f4a32c240b8570.png#pic_center)
图 9. 孪生网络的架构 30。孪生cnns共享权重。
Triplet Ranking Nets 96 将 Siamese Nets 30 从成对样本扩展到三元组样本,并使用三元组排序损失(triplet ranking loss) 100 优化度量空间,从而捕捉样本之间的相似性。SRPN 97 也是 Siamese Nets 30 的一种演进,主要有两个改进:(1)将 Siamese Nets 在顶层的简单成对组合替换为更复杂的跳跃残差网络(skip residual network)13,该网络分离了样本对的中间计算,如图10所示。(2)使用额外的 GAN 94 来对跳跃残差网络进行正则化,将跳跃残差网络作为判别器网络,并引入另一个基于自编码器(auto-encoder)的生成器。因此,SRPN 的度量损失自然被纳入 GAN 的对抗损失中。

图10.跳过残差成对网络(Srpn)的体系结构
MM 98 开发了一个终身记忆模块(life-long memory module)来学习相似度度量,它将测试数据的特征视为查询
q
q
q,并存储了与连续更新的键(key)相关的值(即类别标签)。该记忆通过以下基于合页的记忆损失优化:
L
=
∑
q
[
q
⊤
k
−
−
q
⊤
k
+
+
γ
]
+
,
(12)
\mathcal{L} = \sum_q [q^\top k^- - q^\top k^+ + \gamma]_+, \tag{12}
L=q∑[q⊤k−−q⊤k++γ]+,(12)
其中
k
−
k^-
k− 和
k
+
k^+
k+ 分别是关于查询
q
q
q 的负键和正键。一个键是正的还是负的取决于将其值与
q
q
q 的类别标签进行比较的结果。
![图11。一批样本的直方图损失[103]的计算。点表示样本的特征。相同的颜色表示相同的类。](https://i-blog.csdnimg.cn/direct/174530c037c84c3f81e5890a0d5b7a38.png#pic_center)
图11。一批样本的直方图损失101的计算。点表示样本的特征。相同的颜色表示相同的类。
AdaptHistLoss 99 建议采用直方图损失(histogram loss)101 来学习一个特征空间,使得简单的余弦距离可以有效地衡量两个特征之间的相似性。直方图损失建议构建两组相似度:
S
+
=
{
s
(
f
x
i
,
f
x
j
)
∣
y
i
=
y
j
}
,
S
−
=
{
s
(
f
x
i
,
f
x
j
)
∣
y
i
≠
y
j
}
S^+ = \{s(f_{x_i}, f_{x_j}) \mid y_i = y_j\}, \quad S^- = \{s(f_{x_i}, f_{x_j}) \mid y_i \neq y_j\}
S+={s(fxi,fxj)∣yi=yj},S−={s(fxi,fxj)∣yi=yj},其中
f
x
i
f_{x_i}
fxi 表示数据
x
i
x_i
xi 的特征,其类别标签为
y
i
y_i
yi,而
s
(
⋅
,
⋅
)
s(\cdot, \cdot)
s(⋅,⋅) 是特征级的相似度度量(即余弦相似度)。利用
S
+
S^+
S+ 和
S
−
S^-
S−,可以估计正样本对和负样本对的相似度分布为直方图,如图11所示,分别表示为
p
+
(
s
)
p^+(s)
p+(s) 和
p
−
(
s
)
p^-(s)
p−(s)。然后,直方图损失定义为随机负样本对的相似度大于随机正样本对的相似度的反向概率:
L
=
∫
−
1
1
p
−
(
s
)
[
∫
−
1
s
p
+
(
z
)
d
z
]
d
s
=
E
s
∼
p
−
[
∫
−
1
s
p
+
(
z
)
d
z
]
.
(13)
\mathcal{L} = \int_{-1}^1 p^-(s) \left[ \int_{-1}^s p^+(z) dz \right] ds = \mathbb{E}_{s \sim p^-} \left[ \int_{-1}^s p^+(z) dz \right]. \tag{13}
L=∫−11p−(s)[∫−1sp+(z)dz]ds=Es∼p−[∫−1sp+(z)dz].(13)
由于直方图损失只关注正样本对和负样本对的相似度分布,而对类别标签不敏感,该度量可以直接转移到少样本学习(Few-Shot Learning, FSL)任务
T
T
T 中。
表3总结了上述基于度量学习的 FSL 方法的主要特征。除了这些方法外,还应注意 Learn-to-Measure FSL 方法(见第4.3.1节),严格来说,都属于度量学习的范畴。鉴于它们在元学习(meta learning)的范式下寻求相似度度量,我们将在元学习章节中讨论它们。
| 方法 | 相似性度量 S ( ⋅ , ⋅ ) S(\cdot, \cdot) S(⋅,⋅) | 度量损失 | 任务类型 | 实验数据集 |
|---|---|---|---|---|
| CRM 38 | d ( x i , x j ) d(x_i, x_j) d(xi,xj)(马氏距离) | hinge 损失 | 图像分类 | 拉丁字符数据库 38 |
| KernelBoost 95 | K ( x i , x j ) K(x_i, x_j) K(xi,xj)(核函数) | 指数损失 | 图像分类, 图像检索 | UIC 102, MNIST 63, YaleB 103 |
| Siamese Nets 30 | p ( x i , x j ) \mathbf{p}(x_i, x_j) p(xi,xj)(Siamese CNN) | 二元交叉熵损失 | 图像分类 | Omniglot 37 |
| Triplet Ranking Nets 96 | d ( x i , x j ) d(x_i, x_j) d(xi,xj)(欧几里得距离) | 三元组排序损失 | 图像分类 | Omniglot 37, miniImageNet 49 |
| SRPN 97 | p ( x i , x j ) \mathbf{p}(x_i, x_j) p(xi,xj)(GAN + Siamese CNN) | 对抗性损失 | 图像分类 | Omniglot 37, miniImageNet 49 |
| MM 98 | d ( x i , x j ) d(x_i, x_j) d(xi,xj)(记忆 + 点积) | 记忆损失 | 图像分类, 翻译 | Omniglot 104, WMT14 98 |
| AdaptHistLoss 99 | d ( x i , x j ) d(x_i, x_j) d(xi,xj)(余弦距离) | 直方图损失 | 图像分类, 翻译 | MNIST 63, UIC 的 Isolet 数据集 102, Omniglot 37, tinyImageNet 99 |
4.3 Meta Learning 元学习
元学习(meta learning)的理念早在1990年代就被提出 105 106 107。随着深度学习的流行,一些工作提出利用元学习策略来优化深度模型 108 109 110。一般来说,元学习主张在任务间学习,然后适应新任务,如图12所示,旨在任务级别而非样本级别进行学习,并学习任务无关的学习系统,而非任务特定的模型。

图12.基于元学习的fsl方法的总体框架。
FSL 是验证元学习方法跨任务能力的一个自然测试平台,因为在 FSL 中每个任务只有少量标注样本。元学习方法分两个阶段处理 FSL 问题:元训练(meta-train)和元测试(meta-test)。在元训练阶段,模型接触大量独立的监督任务
T
∼
p
(
T
)
T \sim p(T)
T∼p(T),这些任务基于辅助数据集
D
A
D_A
DA 构建(也称为“episode” 49 50),以学习如何适应未来相关任务,其中
P
(
T
)
P(T)
P(T) 定义了任务分布,并且“相关”的意思是所有任务都来自
P
(
T
)
P(T)
P(T) 并遵循相同的任务范式,例如,所有任务都是
C
C
C-way
K
K
K-shot 问题。每个元训练任务
T
T
T 包含一个任务特定的数据集
D
T
=
{
D
trn
,
D
tst
}
D_T = \{D_{\text{trn}}, D_{\text{tst}}\}
DT={Dtrn,Dtst},其中
D
trn
=
{
(
x
i
,
y
i
)
}
i
=
1
N
trn
,
D
tst
=
{
(
x
i
,
y
i
)
}
i
=
1
N
tst
.
D_{\text{trn}} = \{(x_i, y_i)\}_{i=1}^{N_{\text{trn}}}, \quad D_{\text{tst}} = \{(x_i, y_i)\}_{i=1}^{N_{\text{tst}}}.
Dtrn={(xi,yi)}i=1Ntrn,Dtst={(xi,yi)}i=1Ntst.在元测试阶段,模型在新任务
T
∼
p
(
T
)
T \sim p(T)
T∼p(T) 上进行测试,其标签空间与元训练期间所见标签不相交。在大多数情况下,
D
trn
D_{\text{trn}}
Dtrn 被称为支持集(support set)或描述集(description set),
D
tst
D_{\text{tst}}
Dtst 被称为查询集(query set)。相应地,它们的样本被称为支持样本(support samples)和查询样本(query samples)。元学习的目标是找到模型参数
θ
\theta
θ,使得在所有任务上的期望损失
L
(
⋅
;
θ
)
L(\cdot; \theta)
L(⋅;θ) 最小化:
min
θ
E
T
∼
P
(
T
)
[
L
(
D
T
;
θ
)
]
.
(14)
\min_\theta \mathbb{E}_{T \sim P(T)} \left[ L(D_T; \theta) \right]. \tag{14}
θminET∼P(T)[L(DT;θ)].(14)
我们必须强调,元学习是一种高级别的跨任务学习策略,而非特定的 FSL 模型。基于元学习模型在这种学习策略背后试图学习的内容,我们通常将基于元学习的 FSL 方法总结为五个子类别:Learn-to-Measure 度量学习 (L2M)、Learn-to-Finetune 微调学习 (L2F)、Learn-to-Parameterize 参数化学习 (L2P)、Learn-to-Adjust 调整学习 (L2A) 和 Learn-to-Remember 记忆学习 (L2R)。
4.3.1 Learn-to-Measure 度量学习
L2M 方法本质上继承了度量学习的主要思想,如图8所示,但与基于度量学习的 FSL 方法(见第4.2节)在实现层面有所不同:L2M 方法采用元学习策略来学习期望可在不同任务间转移的相似度度量。L2M 一直是基于元学习的 FSL 方法中的重要分支,许多具有里程碑意义的元学习方法,如 Matching Nets 49、Prototypical Nets 54 和 Relation Net 55,都属于 L2M 类别。
我们首先从数学上描述 L2M 的一般流程。对于一个任务
T
T
T,设
x
i
x_i
xi 是
D
trn
D_{\text{trn}}
Dtrn 中的支持样本,
x
j
x_j
xj 是
D
tst
D_{\text{tst}}
Dtst 中的查询样本,并设
f
(
⋅
;
θ
f
)
f(\cdot; \theta_f)
f(⋅;θf) 和
g
(
⋅
;
θ
g
)
g(\cdot; \theta_g)
g(⋅;θg) 分别为将支持样本和查询样本映射到特征的嵌入模型。此外,所有 L2M 方法都包含一个度量模块
S
(
f
,
g
;
θ
S
)
S(f, g; \theta_S)
S(f,g;θS),用于衡量支持样本和查询样本之间的相似性,该模块可能是无参数的距离度量(例如欧氏距离、余弦距离)或可学习的网络。由该度量模块输出的相似性被用来形成查询样本的最终预测概率。现有的 L2M 方法主要在
f
f
f、
g
g
g 和
S
S
S 的模型设计和选择上存在差异,我们在图13中以高度抽象的方式描绘了不同 L2M 方法之间的发展关系。

图 13. 不同学习到度量 fsl 方法之间的开发关系。
4.3.1.1 Prototypical Nets and its Variants 原型网络及其变体
L2M 的先驱是 Micro-set Learning 43,尽管当时并未提到元学习的概念。该方法通过辅助数据集
D
A
D_A
DA 人工构建了许多类似于测试场景的小集合(micro-sets),每个小集合包含一些属于几个非任务类别的支持样本和查询样本。嵌入模型
f
f
f 和
g
g
g 都是通过共享权重的线性投影实现的(即
f
=
g
f = g
f=g),相似度度量
S
S
S 则由欧氏距离(Euclidean distance)计算得到。此外,NCA 111 被用来测量最终概率。实际上,小集合等价于现在所谓的“episodes”,并且每个小集合都是一个元训练任务
T
T
T。重要的是,如果我们将线性投影模型替换为基于深度学习的嵌入模型(如 CNN),Micro-set Learning 43 就会演变成经典的 Prototypical Nets 54。它将同类支持样本嵌入的中心作为该类别的原型:
p
c
=
1
K
∑
(
x
i
,
y
i
)
∈
D
trn
1
(
y
i
=
c
)
f
(
x
i
;
θ
f
)
,
(15)
p_c = \frac{1}{K} \sum_{(x_i, y_i) \in D_{\text{trn}}} \mathbb{1}(y_i = c) f(x_i; \theta_f), \tag{15}
pc=K1(xi,yi)∈Dtrn∑1(yi=c)f(xi;θf),(15)
然后,类似 Micro-set Learning 43,它利用基于欧氏距离的 NCA 来预测概率:
P
(
y
j
=
c
∣
x
j
)
=
exp
(
−
d
(
g
(
x
j
;
θ
g
)
,
p
c
)
)
∑
c
′
=
1
C
exp
(
−
d
(
g
(
x
j
;
θ
g
)
,
p
c
′
)
)
,
(16)
P(y_j = c \mid x_j) = \frac{\exp(- d(g(x_j; \theta_g), p_c))}{\sum_{c' = 1}^C \exp(- d(g(x_j; \theta_g), p_{c'}))}, \tag{16}
P(yj=c∣xj)=∑c′=1Cexp(−d(g(xj;θg),pc′))exp(−d(g(xj;θg),pc)),(16)
其中
f
f
f 和
g
g
g 也是共享权重的嵌入模型(即
f
=
g
f = g
f=g)。这一 L2M 框架是许多后续 FSL 方法的重要基石。在 112 中,mAP-Nets 被提出以从信息检索的角度学习一种信息丰富的相似度度量。它选择在每个元训练任务内使用结构化支持向量机(SVM)113 或直接损失最小化 114 来优化基于 mAP 的排序损失。TADAM 115 进一步通过引入度量缩放因子
α
\alpha
α 来优化 Prototypical Nets 的相似度度量
S
S
S,并通过任务嵌入网络(TEN)115 将原本与任务无关的
f
f
f 转变为任务条件嵌入模型。TEN 遵循 FILM 条件层 116 的关键思想,并根据当前任务表示为嵌入模型
f
f
f 定制一些调整参数(例如缩放和偏移的元参数)。AM3 117 将额外的跨模态信息(例如语义表示)引入到 Prototypical Nets 和 TADAM 中,以增强度量学习过程。具体而言,它利用 GloVe 118 提取语义类别标签的词嵌入,然后通过视觉特征和词嵌入的凸组合构建新的原型。AAM 119 提出在公式 (16) 之前对查询样本的嵌入进行细化,使其更接近对应的类别中心。CFA 120 实现了图像的组合特征提取,而不是直接的图像到向量映射。Ktuplet Nets 121 将 Prototypical Nets 的 NCA 损失替换为 K-tuplet 度量损失。Y. Zheng 等人 122 认为平均原型忽略了不同支持样本的重要性差异,因此提出了 Principal Characteristic Nets。Diversity with Cooperation 123 实现了 Prototypical Nets 的集成,旨在鼓励所有单个网络进行合作,同时鼓励预测多样性。
4.3.1.2 Matching Nets and its Variants 匹配网络及其变体
第一个基于深度学习的 L2M 方法是 Matching Nets 49。如图14所示,它通过测量查询样本
x
j
x_j
xj 的嵌入与每个支持样本的嵌入之间的余弦相似度来预测
x
j
x_j
xj 的概率:
p
(
y
^
j
∣
x
j
,
D
trn
)
=
∑
(
x
i
,
y
i
)
∈
D
trn
a
(
x
j
,
x
i
)
⋅
y
i
,
(17)
p(\hat{y}_j \mid x_j, D_{\text{trn}}) = \sum_{(x_i, y_i) \in D_{\text{trn}}} a(x_j, x_i) \cdot y_i, \tag{17}
p(y^j∣xj,Dtrn)=(xi,yi)∈Dtrn∑a(xj,xi)⋅yi,(17)
其中
y
i
y_i
yi 是对应于标签
y
i
∈
R
1
y_i \in \mathbb{R}^1
yi∈R1 的 C 维一热标签向量(C-way FSL 任务),而
a
(
x
j
,
x
i
)
=
exp
(
c
(
g
(
x
j
;
θ
g
)
,
f
(
x
i
;
θ
f
)
)
)
∑
(
x
,
y
)
∈
D
trn
exp
(
c
(
g
(
x
j
;
θ
g
)
,
f
(
x
;
θ
f
)
)
)
.
(18)
a(x_j, x_i) = \frac{\exp(c(g(x_j; \theta_g), f(x_i; \theta_f)))}{\sum_{(x, y) \in D_{\text{trn}}} \exp(c(g(x_j; \theta_g), f(x; \theta_f)))}. \tag{18}
a(xj,xi)=∑(x,y)∈Dtrnexp(c(g(xj;θg),f(x;θf)))exp(c(g(xj;θg),f(xi;θf))).(18)
Matching Nets 与 Prototypical Nets 在两个方面不同。首先,Matching Nets 的嵌入模型
f
f
f 和
g
g
g 是两个不同的网络。具体来说,
f
f
f 是 CNN 和 BiLSTM 22 的组合,旨在为少量支持样本实现全上下文嵌入(FCE)49,而
g
g
g 是一个
f
f
f-条件模型,通过内容注意力机制为查询样本生成特征。其次,Matching Nets 中的相似度度量
S
S
S 是余弦距离,而非欧氏距离。一些后续工作对 Matching Nets 进行了修改和扩展。例如,Cross-Modulation Nets 124 将
f
f
f 和
g
g
g 之间的条件机制修改为使用 FILM 层 116 的交叉调制机制,从而使支持样本和查询样本在特征嵌入过程中能够交互。MM-Net 125 开发了一个记忆模块 126 来生成特征嵌入,并由该记忆模块生成
g
g
g 的参数。SS Matching Nets 127 考虑了类别标签的语义多样性和相似性,并采用了一种计划采样策略来促进 Matching Nets 的模型训练。

图14。匹配网络架构 49 (例如4路1镜头任务)。
4.3.1.3 Relation Net and its Variants 关系网络及其变体
与使用非参数的欧氏距离或余弦距离来衡量成对特征相似性的 Prototypical Nets 54 和 Matching Nets 49 不同,Relation Net 55 采用了一个可学习的 CNN(这里用 h ( ⋅ ; θ h ) h(\cdot; \theta_h) h(⋅;θh) 表示)来测量成对相似性。它将支持样本 x i x_i xi 和查询样本 x j x_j xj 的特征图拼接作为输入,并输出它们的关系得分 r ( x i , x j ) r(x_i, x_j) r(xi,xj),如图15所示,其公式为:
r ( x i , x j ) = h ( C ( f ( x i ; θ f ) , g ( x j ; θ g ) ) ; θ h ) ∈ [ 0 , 1 ] , (19) r(x_i, x_j) = h(C(f(x_i; \theta_f), g(x_j; \theta_g)); \theta_h) \in [0, 1], \tag{19} r(xi,xj)=h(C(f(xi;θf),g(xj;θg));θh)∈[0,1],(19)
其中
f
=
g
f = g
f=g,
C
C
C 表示特征图的拼接。需要注意的是,对于 Relation Net,
f
f
f(或
g
g
g)输出的嵌入是特征图而非特征向量。基于 Relation Net,MACO 128 在
f
f
f 之后设计了一个关系阶段来形成同类样本对之间的关系特征,然后利用查询条件操作来预测查询样本的概率。Deep Comparison Net 129 通过将关系模块部署到嵌入模型
f
f
f 的每一层来扩展 Relation Net。CovaMNet 130 和 DN4 131 分别用协方差度量网络和基于深度局部描述符的图像到类别度量模块替换了 Relation Net 55 中的关系模块。SoSN 132 选择在特征图的二阶表示上执行关系计算。SARN 133 引入了自注意力机制到 Relation Net 中,以捕获非局部特征并增强表示能力。

图14。匹配网络架构49 (例如4路1镜头任务)。
4.3.1.4 Other L2M Approaches 其他 L2M 方法
除了上述三大主流方法之外,还有一些基于它们的混合变体。例如,GNN 134 将 Prototypical Nets 54 中的欧氏距离和 Matching Nets 49 中的余弦距离替换为一个可学习的图神经网络(Graph Neural Network, GNN),其中节点设置为样本的嵌入,边则表示两个样本之间的相似性。相反,EGNN 135 交换了 GNN 134 中节点和边的角色,将其从节点标注框架转变为边标注框架。Y. Wang 等人 136 提出对 Prototypical Nets 或 GNN 的最终分类损失施加一个大间隔约束(large margin constraint),并通过增加一个间隔损失(margin loss)来增强度量空间的判别能力。考虑到一个特征元素在不同任务中的重要性不同,H. Li 等人引入了 Category Traversal Module (CTM) 137 来选择特征嵌入中与任务最相关的维度。CTM 137 可以作为一个即插即用的模块,用于其他方法,例如 Matching Nets 49、Prototypical Nets 54 和 Relation Net 55。
4.3.2 Learn-to-Finetune 微调学习
L2F 方法建议利用任务 T T T 的少量支持样本微调基学习器(base learner),使其在几个参数更新步骤内快速收敛到这些样本。通常,每个 L2F 方法都包含一个基学习器和一个元学习器(meta learner)。基学习器针对特定任务,接受样本作为输入并输出预测概率。基学习器由在一系列元训练任务上学习的高层次元学习器来学习,以最大化基学习器在所有任务上的综合泛化能力。令 θ b \theta_b θb 和 θ m \theta_m θm 分别表示基学习器和元学习器的参数。L2F 的学习过程发生在两个层面。跨任务的渐进学习用于优化元学习器参数 θ m \theta_m θm,以促进基学习器在每个特定任务上的快速学习。两个里程碑式的 L2F 方法是 MAML 50 和 Meta-Learner LSTM 51。
MAML 50 是一个具有很强解释性的优雅元学习框架,对元学习和 FSL 领域有深远影响。其核心思想是通过跨任务训练策略为
θ
b
\theta_b
θb 搜索一个良好的参数初始化,使得基学习器可以利用该初始化快速泛化新任务,并使用少量支持样本。具体而言,当基学习器处理任务
T
T
T 时,基学习器的单步更新参数
θ
b
T
\theta_b^T
θbT 计算如下:
θ
b
T
=
θ
b
−
α
∇
θ
b
L
(
D
trn
T
,
θ
b
)
,
(20)
\theta_b^T = \theta_b - \alpha \nabla_{\theta_b} L(D_{\text{trn}}^T, \theta_b), \tag{20}
θbT=θb−α∇θbL(DtrnT,θb),(20)
其中
α
\alpha
α 为学习率,
L
(
D
trn
T
,
θ
b
)
L(D_{\text{trn}}^T, \theta_b)
L(DtrnT,θb) 为基学习器参数初始化为
θ
b
\theta_b
θb 时,在任务
T
T
T 的支持集上的损失。在元层面,MAML 通过在多个任务上的更新基学习器
θ
b
T
\theta_b^T
θbT 平衡损失来优化元学习器:
θ
m
=
θ
m
−
β
∇
θ
m
∑
T
∼
P
(
T
)
L
(
D
tst
T
,
θ
b
T
)
.
(21)
\theta_m = \theta_m - \beta \nabla_{\theta_m} \sum_{T \sim P(T)} L(D_{\text{tst}}^T, \theta_b^T). \tag{21}
θm=θm−β∇θmT∼P(T)∑L(DtstT,θbT).(21)
需要注意的是,MAML 50 中的元学习器实际上就是基学习器,即元学习器参数满足
θ
m
=
θ
b
\theta_m = \theta_b
θm=θb。公式 (20) 是旨在微调基学习器以适应特定任务的快速学习过程,而公式 (21) 是旨在为基学习器提炼合适参数初始化的渐进学习过程。

图16.maml50及其变体之间的发展关系。
此外,最近发展了许多属于 MAML 变体的 L2F 方法 138 139 140 141 142 143 144 145 146 147,它们与 MAML 的关系如图16所示。MetaSGD 138 提出了不仅元学习基学习器的初始化,还元学习基学习器的更新方向和学习率。因此,MetaSGD 将公式 (20) 中的学习率
α
\alpha
α 修改为可学习的向量
α
\alpha
α,并将其添加到元学习器参数中:
θ
b
T
=
θ
b
−
α
∘
∇
θ
b
L
(
D
trn
T
,
θ
b
)
,
(
θ
b
,
α
)
=
(
θ
b
,
α
)
−
β
∇
(
θ
b
,
α
)
∑
T
∼
P
(
T
)
L
(
D
tst
T
,
θ
b
T
)
.
(22)
\theta_b^T = \theta_b - \alpha \circ \nabla_{\theta_b} L(D_{\text{trn}}^T, \theta_b), \\ (\theta_b, \alpha) = (\theta_b, \alpha) - \beta \nabla_{(\theta_b, \alpha)} \sum_{T \sim P(T)} L(D_{\text{tst}}^T, \theta_b^T). \tag{22}
θbT=θb−α∘∇θbL(DtrnT,θb),(θb,α)=(θb,α)−β∇(θb,α)T∼P(T)∑L(DtstT,θbT).(22)
沿着这条思路,DEML 141 对 Meta-SGD 进行了增量改进,为 Meta-SGD 的元学习器配备了一个概念生成器,以实现在高级概念空间中的“学习如何学习”。相比之下,MT-net 139 提出将 MAML 的元学习器参数空间缩小到由每一层的激活空间组成的子空间,并在该子空间上执行快速学习。为了避免在 MAML 的渐进学习中计算二阶导数,A. Nichol 等人开发了 Reptile 140,直接将元学习器参数
θ
m
\theta_m
θm 移向在多个任务上更新的基学习器参数
θ
b
T
\theta_b^T
θbT:
θ
b
=
θ
b
−
β
∑
T
∼
P
(
T
)
(
θ
b
−
θ
b
T
)
.
(23)
\theta_b = \theta_b - \beta \sum_{T \sim P(T)} (\theta_b - \theta_b^T). \tag{23}
θb=θb−βT∼P(T)∑(θb−θbT).(23)
LLAMA 142 从分层贝叶斯的角度重构了 MAML,并从贝叶斯后验估计的角度对 MAML 进行了扩展。考虑到从少量样本中学习时的任务模糊性问题,PLATIPUS 143 使用概率图模型扩展了 MAML,并将其重新表述为图模型推理问题,从而在元测试阶段可以简单有效地对新任务的基学习器进行采样。相比之下,BMAML 144 通过将 MAML 与非参数变分推理(即 Stein Variational Gradient Descent,SVGD 148)相结合来处理从少量样本中学习时的模型不确定性。此外,BMAML 在渐进学习过程中提出了一个新颖的 Chaser 损失 144 来优化元学习器参数
θ
m
\theta_m
θm。
TAML 145 在初始模型上施加了一个无偏的任务无关先验,通过最大化/最小化熵或不等式来防止其在元训练任务上过度表现。LEO 146 设计了一个隐嵌入
z
z
z,由任务
T
T
T 的支持集通过编码器
z
=
E
(
D
trn
T
;
θ
E
)
z = E(D_{\text{trn}}^T; \theta_E)
z=E(DtrnT;θE) 生成基学习器参数
θ
b
\theta_b
θb,即
θ
b
=
G
(
z
;
θ
G
)
\theta_b = G(z; \theta_G)
θb=G(z;θG),并在低维隐空间中而非类似于公式 (20) 的高维基学习器参数空间中进行快速学习:
z
T
=
z
−
α
∘
∇
z
L
(
D
trn
T
,
G
(
z
;
θ
G
)
)
.
(24)
z^T = z - \alpha \circ \nabla_z L(D_{\text{trn}}^T, G(z; \theta_G)). \tag{24}
zT=z−α∘∇zL(DtrnT,G(z;θG)).(24)
显然,编码器
E
(
⋅
;
θ
E
)
E(\cdot; \theta_E)
E(⋅;θE) 和生成器
G
(
⋅
;
θ
G
)
G(\cdot; \theta_G)
G(⋅;θG) 的组合扮演了 LEO 的元学习器角色,因此其渐进学习过程可以描述为
θ
m
=
θ
m
−
β
∇
θ
m
∑
T
∼
P
(
T
)
L
(
D
tst
T
,
G
(
z
T
;
θ
G
)
)
,
(25)
\theta_m = \theta_m - \beta \nabla_{\theta_m} \sum_{T \sim P(T)} L(D_{\text{tst}}^T, G(z^T; \theta_G)), \tag{25}
θm=θm−β∇θmT∼P(T)∑L(DtstT,G(zT;θG)),(25)
其中元学习器参数
θ
m
=
(
θ
E
,
θ
G
,
α
)
\theta_m = (\theta_E, \theta_G, \alpha)
θm=(θE,θG,α)。与 MAML 相比,CAML 147 利用标签结构根据当前任务来调节基学习器的表示。具体来说,设计了一个参数化条件变换模块来执行表示调制。该模块与基学习器的组合充当 CAML 的元学习器,通过 MAML 采用的渐进学习策略进行元学习。
另一个代表性的 L2F 方法是 Meta-Learner LSTM 51,该方法建议通过基于 LSTM 的元学习器在少量支持样本上微调基学习器。如图17所示,基于 LSTM 的元学习器以基学习器关于每个支持样本的损失和梯度为输入,其隐藏状态被视为更新后的基学习器参数,并将用于处理下一个支持样本。在此框架中,基学习器参数的传统基于梯度的优化被 LSTM 取代,以期专门为只需少量更新的场景学习合适的参数更新。

图 17. 一个任务 51 的元学习器 lstm 的前向计算过程。绿色框是基础学习器,蓝色框是元学习器。
J. Nie 等人将 Meta-Learner LSTM 扩展为一个双版本,称为 Meta-Learner Dual-LSTM 149,并将其应用于 3D 模型的少样本分类任务。此外,最近的一个 L2F 方法是 MTL 150,它开发了一个轻量级的缩放和偏移网络,附加在冻结的基学习器上,以减少在少量支持样本上微调时过拟合的可能性。
**4.3.3 Learn-to-Parameterize 参数化学习 **
L2P 是另一种流行的基于元学习的 FSL 方法,其遵循一个简单的思想:为新任务参数化基学习器或基学习器的某些子部分,使其能够专门解决该任务。如图18所示,大多数 L2P 方法也像 L2F 方法一样包含基学习器和元学习器,但不同之处在于,对于 L2P 方法,这两个学习器在每个任务中同步训练,且元学习器本质上是一个任务特定的参数生成器。对于任务 T T T,元学习器根据任务 T T T 的少量支持样本以及处理这些支持样本的当前基学习器状态,为基学习器或其子部分生成一些任务 T T T 特定的参数。在这一点上,L2P 方法试图学习如何参数化基学习器,使其适用于特定任务。
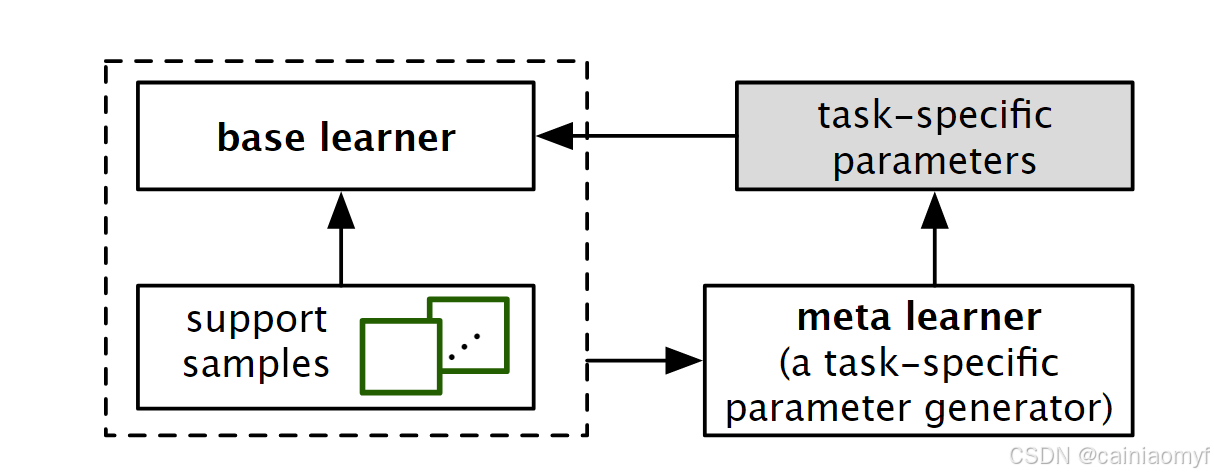
图18.学习参数化fsl方法的通用框架。
近年来,已经提出了许多 L2P 方法,它们开发了不同的参数生成模块来参数化基学习器的不同部分。这些方法可能参数化基学习器中的任务特定预测器 151 152 153 154 155 156 157,或基学习器中的中间特征提取层 56 158 159,甚至是整个基学习器 160 161。不同 L2P 方法的特征总结如表4所示。
| 方法 | 参数生成模块 | 生成的参数 |
|---|---|---|
| Siamese Learnet 158 | 单流 Siamese 网络 30 | 卷积层权重 |
| Regression Nets 160 | 基于 MLP 的权重转换 | SVM 权重 |
| Dynamic Nets 151 | 基于注意力的权重组合 | 预测器权重 |
| Acts2Params 152 | 基于 MLP 的参数预测器 | Softmax 层权重 |
| Imprinting 153 | 基于 MLP 的权重转换 | 预测器权重 |
| DCCN 159 | LSTM 嵌入模块 | 卷积层权重 |
| MeLA 161 | 自动编码器 | 所有卷积层权重 |
| DAE 154 | 图神经网络 | 预测器权重 |
| VERSA 155 | 概率化摊销网络 | Softmax 层权重 |
| R2-D2 156 | 岭回归层 | 预测器权重 |
| MetaOptNet 157 | SVM | 预测器权重 |
| LGM-Net 56 | 类似 VAE 的权重生成器 | 卷积层权重 |

图19.孪生学习器结构158。"∗":卷积层。
Siamese Learnet 158 如图19所示,使用 Siamese Nets 30 作为基学习器,其中一个中间卷积层(图19中的红色块)被设计为对不同任务是动态的。另一个单流的 Siamese Nets 被部署为元学习器,为该卷积层生成任务特定权重。LGM-Net 56 是一个最先进的 L2P 方法,它开发了一个 MetaNet 模块(即元学习器),基于每个 FSL 任务中的少量支持样本生成 TargetNet 模块(即基学习器)的权重,如图20所示。具体而言,LGM-Net 中的 MetaNet 模块将支持样本的平均嵌入作为输入,并通过一个具有多变量高斯采样的编码器-解码器模型为基学习器中的每个卷积层生成权重。一旦参数化,LGM-Net 的基学习器将类似于经典的 Matching Nets 49 进行 FSL 推理。

图 20. lgm-net 架构 56(例如 5 路 1-shot 任务)。
Regression Nets 160 追求一种将基学习器的权重从小样本模型转换为大样本模型的任务无关变换。通过这种权重变换,即使仅在少量训练样本上也可以获得更通用的基学习器权重。Dynamic Nets 151 提倡通过结合少量支持样本的平均表示和非任务预测器权重上的基于注意力的权重组合来参数化任务特定预测器。Acts2Params 152 学习了一个基于 MLP 的参数预测器,将神经元激活映射到最终 Softmax 预测器的权重。一旦训练好,它可以通过将任务的少量支持样本的激活作为输入,直接预测任务特定的 Softmax 权重。类似地,Imprinting 153 也继承了这种映射思想,通过 MLP 将支持样本的嵌入转换为任务特定预测器的权重。VERSA 155 利用了一个通用的摊销网络(amortization network),它接受支持样本作为输入并输出任务特定 Softmax 预测器的参数分布。DAE 154 使用基于图神经网络的去噪自编码器(Auto-Encoder, AE)来生成最终预测器参数。相比之下,R2-D2 156 采用了一个可微分的岭回归层来参数化任务特定预测器,而 MeteOptNet 157 倡导在 SVM 上进行可微分凸优化以生成最终预测器权重。MeLA 161 与 LGM-Net 56 类似,因为它们都试图通过编码器-解码器生成器(MeLA 使用 AE,而 LGM-Net 使用类似变分自编码器 162 的 AE 变体)为特定任务自定义基学习器的卷积层(MeLA 参数化了几个后卷积层,而 LGM-Net 参数化了所有卷积层)。
4.3.4 Learn-to-Adjust 调整参数学习
如图21所示,L2A 方法的核心理念是自适应地调整基学习器中的计算流或计算节点,使其能够与特定样本兼容。人们可能会发现 L2P 和 L2A 都利用元学习器来改变基学习器,但 L2A 方法有两个与 L2P 不同的独特特征:
(1)L2A 方法对基学习器的更改程度较轻,因为它们只对基学习器进行一些增量调整,而不是像 L2P 那样对基学习器或其子部分进行完整的参数化。
(2)L2A 方法对基学习器的更改更精细,因为 L2A 的调整是针对样本的,而 L2P 的参数化是针对任务的。
一些典型的 L2A 方法包括 MetaNet 53、CSNs 163、MetaHebb 164 和 FEAT 165,它们在需要调整的部分选择以及生成的调整设计上有所不同,如表5所示。MetaNet 53 在基学习器的每一层附加了一个快速权重层。每个快速权重层的权重由外部元学习器根据输入样本进行元生成。这些附加分支层用于在前向传播过程中调整输入样本的中间值。CSNs 163 选择调整基学习器中每个隐藏节点的神经元状态(即预激活)。具体来说,它结合了一个内存模块和基于注意力的内存读取机制,以生成基学习器中每个神经元预激活的条件偏移(condition shift)。MetaHebb 164 在 Softmax 之前的层中添加了一个辅助快速权重矩阵,该矩阵通过 Hebbian 学习 166 进行元生成,旨在调整输入传递到最终 Softmax 层的内部表示。FEAT 165 提出了自适应支持样本的嵌入,以使其对当前任务更具判别性,并研究了四种将原始嵌入向量转换为自适应向量的集合到集合函数,包括 BiLSTM 22、DeepSets 167、GCN 168 和 Transformer 169。
4.3.5 Learn-to-Remember 记忆学习
一些典型的 FSL 方法,如 MANN 170、ARCs 171、SNAIL 172 和 APL 173,属于 L2R(Learn-to-Remember)范畴。如图22所示,其主要思想是将 FSL 任务的支持集建模为一个序列,并将 FSL 任务表述为序列学习任务,其中要求查询样本与先前看到的信息(即支持样本)进行匹配。因此,L2R 方法的基学习器通常包含一个时序网络来处理少量支持样本。例如,MANN 52 利用带有记忆增强的神经图灵机(Neural Turing Machine, NTM)174 来快速吸收支持样本,并在查询样本到来时检索它们。ARCs 171 开发了一个基于注意力的 RNN,实现样本之间的动态比较。SNAIL 172 设计了一个带有软注意力的时序卷积网络,以聚合先前看到的信息并定位特定信息。APL 173 设计了一个基于“惊奇”的记忆网络,以记住其遇到的最具信息性的支持样本。
4.3.6 Discussion 讨论
上述五种元学习方法都专注于处理 FSL 问题,但它们各自都有其优点和缺点。L2M 方法不会受到测试场景特定设置的限制,因为它们仅利用样本之间的相似性进行最终推理,而不考虑类别数和每个类别的支持样本数(即对 way/shot 无依赖性)。L2F 方法需要利用少量支持样本对每个新任务进行微调,这可能导致为每个任务准备的适应时间相对较长。L2P 和 L2A 方法面临的一个共同挑战是模型参数数量庞大,因为它们必须部署与基学习器完全不同的另一个元学习器,以生成一系列模型参数或调整参数。此外,元学习器的模型复杂度在很大程度上取决于需要生成的参数数量,从而增加了模型训练的难度。由于序列学习中长期依赖的天花板效应 175,L2R 方法难以将任务中稍多的支持样本情况进行泛化。
4.4 Other Approaches 其他方法
除了前述的三大主流方法,即增强(Section 4.1)、度量学习(Section 4.2)和元学习(Section 4.3),还有一些从其他视角出发的特色判别式 FSL 方法。
多任务学习(Multi-task learning)176 主张通过让上游嵌入模块在不同任务间隐式或显式共享,并让下游任务模块针对特定任务来同步学习多个任务,以期使内部表示更加通用。沿着这一思路,提出了一些基于多任务学习的 FSL 方法 177 178 179。在 177 中,设计了一个正则化惩罚项,强制不同任务的参数相似。MetaGAN 178 引入了一个任务条件 GAN,将其生成和判别的伪样本作为辅助任务,以优化由其他基于元学习的 FSL 方法所形成的决策边界。Z. Hu 等人 179 在最终类别预测之前插入了一个属性预测步骤,并将属性学习损失与主任务损失结合起来以共同优化整个学习器。
自监督学习(Self-supervised learning)在当前非常流行,尤其在视觉 180 181 182 183 184 185 186 187 188 189 和语言 190 191 192 193 领域,其目的是仅利用数据自身固有的结构信息来学习语义上有意义的表示,而不是依赖昂贵的人类标签。研究者利用数据的结构信息作为自监督来训练网络。例如,在 181 185 186 中,无标签的图像被打乱为多个块,然后将这些块的排列作为自监督,从而自监督学习的目标是解决拼图。此外,其他自监督学习任务包括预测图像旋转角度 184、相对块位置 180、增强样本的示例类别 194 等。最近也有一些工作试图从自监督学习的角度解决 FSL 问题 195 196 197 198。例如,如图23所示,195 结合了由 Prototypical Nets 54 构成的监督损失和由旋转任务与拼图任务构成的自监督损失来学习特征表示。S2M2 198 利用自监督任务(即旋转预测和示例预测)和流形混合(Manifold Mixup)198 来正则化特征流形,从而产生一个通用表示的附加损失。196 197 专注于如何将自监督学习纳入半监督 FSL 任务,这将在 Section 5.1 中介绍。本质上,这些自监督 FSL 方法构建了附加于主 FSL 任务的辅助自监督任务,因此它们仍属于多任务学习的范畴。

图23。基于自监督学习的fsl方法概述195。
受推断式传导(transductive inference)199 的启发,Y. Liu 等人 200 假设了一种传导式设置,即在测试时任务中的所有查询样本将同时到达。这样,开发了传导传播网络(Transductive Propagation Network, TPN)200,它利用图模型对所有未标注的查询样本进行标签传播。此外,一些工作提出充分利用额外可用数据或先验知识来促进 FSL。例如,Z. Xu 等人 201 利用大规模机器标注的网络图像,而 M. Bauer 等人 202 利用不同类别之间的概念信息来构建概率 K-shot 学习模型。此外,还有一些来自其他独特视角的方法,例如特征替换 40、基于 LS-SVM 的模型自适应 41、双层规划(Bilevel Programming)203、知识蒸馏 204、密集分类(dense classification)205 和显著性引导数据幻觉(saliency-guided data hallucination)206 等。
随着越来越多的 FSL 解决方案出现,一些研究者将注意力从方法开发转向对现有方法的进一步分析。在 207 中,通过对一些具有代表性的 FSL 方法(如 Prototypical Nets 54、Matching Nets 49、Relation Net 55 和 MAML 50)进行一系列一致的对比实验,分析了基网络深度对 FSL 模型能力的影响。在 208 中,对基于度量学习的 FSL 方法进行了进一步探索,并声称一些简单的特征预处理(例如均值减法和 L2 正则化)可以提高性能。
5 EXTENSIONAL TOPICS 扩展主题
本节详细介绍了 FSL 的几个新兴扩展主题,包括半监督 FSL(Semi-supervised FSL, S-FSL)、无监督 FSL(Unsupervised FSL, U-FSL)、跨域 FSL(Cross-domain FSL, C-FSL)、广义 FSL(Generalized FSL, G-FSL)和多模态 FSL(Multimodal FSL, M-FSL)。它们的数学描述已在 Section 2.2 中给出。基于多种实际应用环境,这五个主题重新规划了 FSL 的应用场景和任务需求,并且它们正成为 FSL 研究的热点方向。
5.1 Semi-supervised Few Sample Learning 半监督少样本学习
S-FSL 假设 N-way K-shot 任务的训练集 D trn D_{\text{trn}} Dtrn 不仅包含 N K NK NK 个带标签的支持样本,还包含一些可能属于任务类别 C C C 的无标签样本。研究者可以利用该半监督训练集来构建 FSL 系统。
在 209 210 211 中,Prototypical Nets 54 通过半监督聚类进行了改进以应对 S-FSL。MetaGAN 178(详见 Section 4.4)被设计为与 S-FSL 设置兼容。在 196 和 197 中,利用自监督学习范式从无标签样本中提取信息。具体而言,如图24所示,196 在无标签图像上构建了自监督任务(即旋转预测和相对块位置),并将该自监督损失添加到主 FSL 任务损失中,这与在 Section 4.4 中讨论的 195 的方法非常相似,不同之处在于它使用带标签的支持样本来构建自监督任务(见图23)。相比之下,197 提出了一个针对 S-FSL 的自训练策略,在无标签数据上预测伪标签,并利用这些伪标签数据微调 FSL 模型。Self-Jig 93 将带标签图像视为探测样本,而将无标签图像视为库样本,然后从中合成新的图像。此外,最近也提出了一些面向特定任务的 S-FSL 模型,如用于问答任务的 SAMIE 212 和用于疾病预测任务的 AffinityNet 213。

图24.s-fsl任务的自我监督方法概述196。
5.2 Unsupervised Few Sample Learning 无监督小样本学习
U-FSL 鼓励一种比普通 FSL 更通用的设置,其中辅助集 D A D_A DA 是完全无监督的。其目标是为执行 FSL 寻求一个相对温和的条件,并削弱构建 FSL 学习器的前提条件,因为收集属于非任务类别的无标签辅助集比收集有标签数据集更易实现。例如,在当今大数据时代,可以通过网络爬虫轻松获取大量的无标签图像。
在 160 中,基学习器的顶层在无标签样本上被预训练为低密度分离器(Low-Density Separator, LDS),以捕捉更通用的表示空间来用于下游 FSL 任务。CACTUs 214 采用了两阶段策略:首先通过无监督表示学习方法(例如 ACAI 215 和 BiGAN 216)和聚类算法在无标签集上合成元训练任务,然后在这些合成任务上运行经典的 MAML 50 或 Prototypical Nets 54。相比之下,UMTRA 216 和 AAL 217 都通过增强无标签样本来合成元训练任务,并将进行增强的祖先样本及其对应的增强数据视为同类样本,之后利用现成的 MAML 50 算法。CACTUs 214、UMTRA 216 和 AAL 217 的共同点在于,它们本质上关注如何为无标签样本分配伪标签,使得现有的 FSL 模型无需修改即可工作。
5.3 Cross-domain Few Sample Learning 跨领域少样本学习
在普通 FSL 设置下,假设辅助数据集
D
A
D_A
DA 和任务特定数据集
D
T
D_T
DT 中的样本都来自相同的数据域,如图25的顶部所示。然而,当需要处理的 FSL 任务来自一个新的领域,而该领域没有相关的辅助样本可用时,我们不得不利用一些跨域样本作为辅助数据,如图25的底部所示。辅助数据集与任务特定数据集之间的域偏移对 FSL 方法提出了更高的挑战。

图 25. 跨域 fsl (c-fsl) 的任务设置的图示。
C-FSL 与领域自适应(Domain Adaptation, DA)218 自然高度相关,这是机器学习领域的一个经典方向。虽然存在一些个别工作 219 在少量样本下处理 DA,但其任务设置与 C-FSL 不同:在 DA 中,源域和目标域之间的标签空间是共享的,而在 C-FSL 任务中,辅助数据集与任务特定数据集之间的标签空间是不相交的。最近,一些方法从不同角度提出了解决 C-FSL 问题的方案,例如对抗训练 220 221 222 223,特征变换 165 224,域对齐 225,领域特定微调 207,特征组合 120 和集成方法 123 等。为了促进后续的 C-FSL 相关研究,我们在表6中总结了它们使用的具体跨域形式。
| 方法 | 跨领域形式( D A D_A DA to D T D_T DT ) |
|---|---|
| 220 | SVHN 226 0-4 → MNIST^ 63 5-9, ImageNet 23 → UCF-101 227 |
| 221 | Omniglot 37 → EMNIST 91 |
| 222 | 数字数据集:MNIST 63 → USPS 228, MNIST → SVHN 226 USPS → MNIST, SVHN → USPS 办公数据集 229:Amazon → DSLR, Amazon → Webcam, DSLR → Webcam, Webcam → DSLR |
| 223 | 字符数据集:Omniglot → Omniglot-M, Omniglot-M → Omniglot Office-Home 数据集 230:Clipart → Product, Product → Clipart |
| 165 | Office-Home 数据集 230:Clipart → Real World, Real World → Clipart |
| 224 | miniImageNet 49 → CUB^ 83 / Cars 231 / Places 232 / Plantae 233 |
| 234 | MNIST 63 → Cifar-10 82, Cifar-10 → MNIST |
| 207 | miniImageNet 49 → CUB 83 |
| 120 | miniImageNet 49 → CUB 83, Kinetics-CMN 235 → Jester |
| 123 | miniImageNet 49 → CUB 83 |
5.4 Generalized Few Sample Learning 广义少样本学习
普通 FSL 设置很容易导致灾难性遗忘(catastrophic forgetting)问题 236,即大多数 FSL 模型被训练为对新任务的预定义类别进行推理,但无法持续应用于辅助集中之前的类别。然而,在许多类别概念和样本以动态方式到达的应用中,学习系统通常面临类间训练数据极端不平衡的问题,这意味着某些类别提供了充足的训练样本,而另一些只有少量样本。在这种情况下,关键且理想的是对有限数据的新任务类别具备增量学习能力,同时不忘记之前的非任务类别。因此,G-FSL 的重点是使 FSL 模型能够共同处理 D A D_A DA 和 D T D_T DT 中的所有类别。
Section 4.1 中提到的一些基于增强的 FSL 方法(包括 SH 86、Hallucinator 87、CPANN 88 和 IDeMe-Net 93)天然适用于 FSL 和 G-FSL 设置,因为它们的学习过程分为两个独立阶段:首先为稀疏任务类别增强训练样本,然后利用原始和增强样本的组合训练模型。GcGPN 237 使用 GCN 168 将普通 Prototypical Nets 54 扩展到 G-FSL 设置,GCN 将所有新类和现有类的关系建模为节点之间的相互依赖关系。Dynamic Nets 151、Acts2Params 152、DAE 154 和 AAN 238 遵循增量生成新类权重并将其与现有类权重相结合以形成联合决策者的共同原则。在 239 中,引入了类自适应主方向(class adapting principal directions)的概念,以便对新类和现有类的图像进行高效且具有判别力的嵌入。CADA-VAE 240 开发了一个变分自编码器(Variational Auto-Encoder),用于生成新类的潜在空间特征,然后在所有类上训练最终预测器。L2A 方法 FEAT 165 也适用于 G-FSL 设置,因为其集合到集合函数是类无关的,其嵌入适应可以同时对新类和现有类进行操作。
5.5 Multimodal Few Sample Learning 多模态少样本学习
与仅包含单一任务模态的普通 FSL 不同,M-FSL 涉及来自额外模态的信息或数据。根据额外模态的作用,M-FSL 设置可以进一步细分为两种情况,如图26所示。
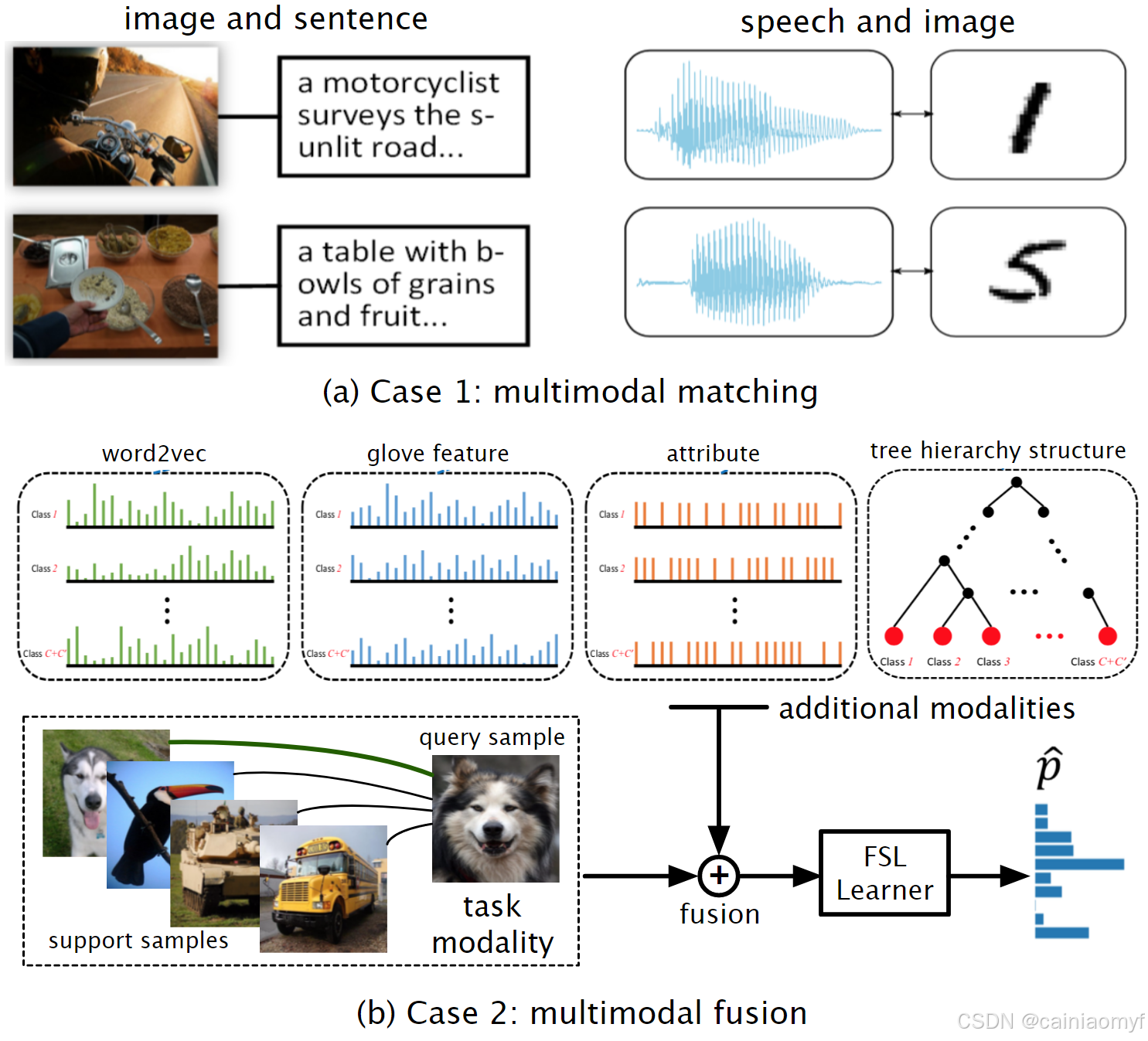
图26。多模态fsl (m-fsl)两种情况的说明。
多模态匹配(Multimodal Matching) 普通 FSL 寻求从任务模态到硬类别标签空间的映射,而 M-FSL 的多模态匹配则旨在学习从一个模态到另一个模态的映射 241 242 243。例如,给定一些图像-句子训练对,FSL 学习器需要确定正确描述查询图像的句子 241 242;或者给定少量语音-图像训练对,FSL 学习器需要找到包含查询语音中所说单词的正确视觉图像 243。这些基于 FSL 的多模态匹配设置非常有意义,尤其是对机器人应用。
多模态融合(Multimodal Fusion) 它允许 FSL 学习器利用来自额外模态的信息来帮助任务模态中的学习。最近的一些工作 117 159 240 244 245 246 247 248 249 250 通过融合多种多模态信息增强了 FSL 模型能力,包括 word2vec 240 246、文本标题 159 244 245 249、属性 240 246 251、glove 特征 246、词嵌入 117, 247、类间树层次结构 246, 250 以及跨风格数据集 248 等。这些额外模态为 FSL 带来了更多的先验知识,为训练样本的不足提供了一种补救措施。
6 APPLICATIONS 应用
由于机器学习系统对大规模训练样本的普遍需求以及 FSL 研究近年来的蓬勃发展,FSL 的方法和理念正广泛应用于各种研究领域,如计算机视觉、自然语言处理、音频和语音、强化学习与机器人学,以及数据分析等。表9总结了 FSL 应用的领域和子领域及其代表性文献。
计算机视觉 由于视觉数据的直观性和可理解性,计算机视觉一直是机器学习算法的主要测试平台,FSL 也不例外。从最早的 Congealing 模型 29 到今天的元学习方法,视觉任务一直是 FSL 方法的试金石,特别是基于少样本的(即少样本)图像分类任务。在表7中,我们列举了几个用于图像分类的流行 FSL 基准数据集,并总结了其统计信息。最常用的两个基准是 Omniglot 37 和 miniImageNet 49。由于灰度字符图像的简单性和足够的元训练类别,许多 FSL 方法在 Omniglot 上取得了接近饱和的良好性能。因此,研究人员倾向于利用 miniImageNet 来评估 FSL 方法的性能。为了更好地参考后续研究,我们在表8中总结了在 miniImageNet 上报告其结果的所有 FSL 方法的性能。可以观察到,从 2016 年到 2019 年的短短三年内,5-way 1/5-shot 的准确性提高了 20% 以上,这表明 FSL 研究的快速发展。此外,FSL 已被引入图像分割 252、目标检测 253 和其他基于图像的视觉任务。在视频数据层面,FSL 也在视频分类 254、视频检测 255、视频对象分割 256 等方面有许多新兴应用。更多关于视觉领域的 FSL 应用可以在表9的第一部分中找到。
自然语言处理 这是 FSL 应用的第二大领域。自然语言处理中的一种常见 FSL 应用是文本分类 257,它试图利用少量文档或单词来推断文档标签。此外,FSL 还被引入到自然语言处理的基础研究主题中,如词表示学习 258、关系学习和知识图谱 259。表9的第二部分详细介绍了更多自然语言处理中的 FSL 应用。
音频与语音 声学数据是一种更复杂的数据形式,通常它们的大规模收集和标注比图像或文本更困难,这导致了对 FSL 方法的更迫切需求。目前,FSL 已被用于解决许多声学任务,从基础的音频分类和关键词识别到具有挑战性的文本转语音和语音生成。表9的第三部分总结了现有的 FSL 应用及其相关文献。
强化学习与机器人学 一个理想的机器人系统应该具备通过少量示范学习新任务的能力,并且不需要针对任务进行长时间的特定训练。然而,新情况可能使机器人陷入有限观察样本的困境,这使得 FSL 成为未来先进机器人系统不可或缺的技能。随着 FSL 方法的流行,许多研究人员重新考虑了在 FSL 体制下的强化学习和机器人学应用 260,包括模仿学习 261、视觉导航 262 和策略学习 263 等。更多相关应用在表9的第四部分中呈现。
数据分析 众所周知,使用稀疏训练数据有效分析数据并挖掘数据中的潜在规律,是数据科学研究人员孜孜不倦追求的目标。幸运的是,FSL 正逐渐被应用于一些经典的数据分析应用中,如数据回归和异常检测 264,如表9的第五部分所述。
跨领域应用 最近,FSL 已被整合到两个流行的跨领域应用中,即图像字幕生成 265 和视觉问答 265 266。在仅给定少量图像-文本训练对的情况下,前者试图为图像生成适当的文本描述,而后者则试图输出针对图像文本问题的准确自然语言答案。
其他应用 除了上述几个机器学习的常见应用领域外,FSL 还被引入其他专业领域,如医学、化学计量学、农业、传感器和互联网安全等。更多详细信息请参见表9的最后一部分。
开放竞赛 随着对 FSL 的关注不断增加,一些相关竞赛也在涌现。据我们所知,2019 年 ICCV 研讨会上发布的“Few-Shot Verb Image Classification”(http://www.lsfsl.net/cl/)是第一个 FSL 竞赛,专注于大规模动词图像分类,并提出了高质量的少样本动词图像数据集。最近,在 CVPR 2020 的“Visual Learning with Limited Labels”研讨会上,提出了一个更具挑战性的竞赛“Cross-Domain Few-Shot Learning Challenge”(https://www.learning-with-limited-labels.com/challenge),与第 5.3 节讨论的 C-FSL 任务保持一致。如图27所示,该竞赛要求参与者在 ImageNet 上训练 FSL 模型,但在来自不同领域的其他四个数据集上进行评估,例如植物病害图像、卫星图像、皮肤病变的皮肤镜图像和 X 光图像。该竞赛包括两个主要赛道,分别允许和不允许使用目标域的无标签图像进行训练。
| 数据集 | 图像数量 | 训练/验证/测试 类别数量 | 内容 |
|---|---|---|---|
| Omniglot 37 | 129,840 | 4,800/-/1,692 | 字符 |
| miniImageNet 49 | 60,000 | 64/16/20 | 常见物体 |
| tieredImageNet 210 | 779,165 | 351/97/160 | 常见物体 |
| CUB 128 | 11,788 | 100/50/50 | 鸟类 |
| Stanford Dogs 131 | 20,580 | 70/20/30 | 狗 |
| Stanford Cars 131 | 16,185 | 130/17/49 | 汽车 |
| Caltech-256 141 | 30,607 | 150/56/50 | 常见物体 |
| Oxford-102 127 | 8,189 | 82/-/20 | 花卉 |
| FC100 115 | 60,000 | 60/20/20 | 常见物体 |
| CIFAR-FS 156 | 60,000 | 64/26/20 | 常见物体 |
| Visual Genome 247 | ~108,000 | 1,211/-/829 | 常见物体 |
| SUN397 251 | 108,754 | 197/-/200 | 场景 |
| ImageNet1K 86 | ~1,000,000 | 389/-/611 | 常见物体 |
| 方法 | 5-way 1-shot | 5-way 5-shot | 方法 | 5-way 1-shot | 5-way 5-shot |
|---|---|---|---|---|---|
| Matching Nets 49 | 43.56 ± 0.84 | 55.31 ± 0.73 | Resnet PN 209 | 54.05 ± 0.47 | 70.92 ± 0.66 |
| Meta-Learner LSTM 51 | 43.44 ± 0.77 | 60.60 ± 0.71 | MetaHebb 164 | 56.84 ± 0.52 | 71.01 ± 0.56 |
| MAML 50 | 48.07 ± 1.75 | 63.15 ± 0.92 | STANet 267 | 58.35 ± 0.57 | 71.07 ± 0.39 |
| MACO 128 | 41.09 ± - | 58.32 ± - | CSNs 163 | 56.88 ± 0.62 | 71.94 ± 0.57 |
| Gauss (MAP pr.) HMC 202 | 50.00 ± 0.50 | 64.30 ± 0.56 | SalNet 206 | 57.45 ± 0.88 | 72.01 ± 0.67 |
| Meta-SGD 138 | 50.47 ± 1.87 | 64.03 ± 0.94 | Dynamic Nets 151 | 56.20 ± 0.86 | 72.81 ± 0.56 |
| Reptile 140 | 48.21 ± 0.69 | 66.00 ± 0.62 | Dual TriNet 74 | 58.12 ± 1.37 | 76.92 ± 0.69 |
| MetaNet 50 | 49.21 ± 0.96 | - | Acts2Params 152 | 59.60 ± 0.41 | 73.74 ± 0.19 |
| LLAMA 142 | 49.40 ± 1.83 | - | TADAM 115 | 58.50 ± 0.30 | 76.70 ± 0.30 |
| Prototypical Nets 54 | 49.42 ± 0.78 | 68.20 ± 0.66 | Deep Comparison Net 129 | 62.88 ± 0.83 | 85.93 ± 0.55 |
| IMP 211 | 49.60 ± 0.80 | 68.10 ± 0.80 | IDEMe-Net 93 | 59.14 ± 0.86 | 74.63 ± 0.74 |
| GNN 134 | 50.33 ± - | 66.41 ± 0.63 | K-tuplet Nets 121 | 58.30 ± 0.36 | 72.37 ± 0.30 |
| Triplet Ranking Nets 96 | 50.58 ± - | - | Self-Jig 93 | 58.30 ± 1.36 | 76.71 ± 0.72 |
| mAP-Nets 112 | 50.32 ± 0.80 | 63.94 ± 0.72 | CAML 147 | 59.36 ± 0.99 | 72.35 ± 0.71 |
| Relation Net 55 | 50.44 ± 0.82 | 65.32 ± 0.70 | CFA 120 | 58.50 ± - | 76.53 ± 0.69 |
| Cross-Modulation Nets 124 | 50.94 ± 0.61 | 66.65 ± 0.63 | SoSN 132 | 59.22 ± 0.91 | 73.24 ± 0.69 |
| Hyper-Represent 203 | 50.54 ± 0.85 | 64.53 ± 0.68 | DAE 154 | 61.07 ± 0.15 | 76.75 ± 0.11 |
| CovaMNet 130 | 51.19 ± 1.78 | - | LEO 146 | 61.76 ± 0.08 | 77.59 ± 0.12 |
| TAML 145 | 51.73 ± 1.88 | 66.05 ± 0.86 | AAM 119 | 62.24 ± 0.72 | 77.24 ± 0.15 |
| Large Margin 136 | 51.41 ± 0.68 | 67.81 ± 0.61 | MTL 150 | 61.28 ± 1.80 | 75.50 ± 0.80 |
| SARN 133 | 51.63 ± 0.31 | 66.16 ± 0.51 | EGNN 135 | 59.24 ± - | - |
| MT-net 139 | 51.70 ± 1.84 | - | Principal Characteristic Nets 122 | 63.29 ± 0.76 | 77.08 ± 0.68 |
| MM-Net 125 | 53.37 ± 0.48 | 66.97 ± 0.35 | AM3 117 | 64.46 ± 0.49 | 78.10 ± 0.36 |
| MetaGAN 178 | 52.71 ± 1.64 | 68.63 ± 0.67 | DC 205 | 62.53 ± 0.19 | 78.95 ± 0.73 |
| VERSA 155 | 53.40 ± 1.82 | 67.37 ± 0.86 | CC+rot 196 | 62.93 ± - | 79.87 ± 0.33 |
| BMAML 144 | 53.80 ± 1.46 | - | MetaOptNet 157 | 64.09 ± 0.62 | 80.00 ± 0.45 |
| SNAIL 172 | 55.71 ± 0.99 | 68.88 ± 0.92 | CTM 137 | 64.12 ± 0.82 | 80.51 ± 0.13 |
| DA-PN 225 | 50.56 ± 0.86 | 69.62 ± 0.78 | LGM-Net 56 | 69.13 ± 1.06 | 71.18 ± 0.68 |
| R2-D2 156 | 51.80 ± 0.69 | 68.70 ± 0.20 | Diversity with Cooperation 123 | 63.73 ± 0.62 | 81.19 ± 0.43 |
| TPN 200 | 55.51 ± - | 69.86 ± - | FEAT 165 | 66.78 ± - | 82.05 ± - |
| SRPN 97 | 55.20 ± - | 69.65 ± - | SimpleShot 208 | 64.92 ± 0.18 | 81.50 ± 0.16 |
| ∆-encoder 89 | 59.90 ± - | 69.77 ± - | S2M2 198 | 64.93 ± 0.18 | 83.18 ± 0.11* |
| DN4 131 | 51.24 ± 0.74 | 71.02 ± 0.64 | LST 197 | 70.10 ± 1.90* | 78.70 ± 0.80 |
| 领域 | 类型 | 子领域 | 参考文献 |
|---|---|---|---|
| 计算机视觉 | 图像 | 图像分类 | 通用图像分类(见 Table 1, 2, 3, 4, 5, 6, Fig. 13, 16),多标签分类 268, 细粒度识别 120 130 131 245 249 269 270 271 272,高光谱图像分类 273 274, 3D 对象/模型分类 149 268 |
| 计算机视觉 | 图像 | 图像分割 | 语义分割 275 276 277 278 279 280 281 282 283,实例分割 284 285, 纹理分割 286 287,医学/生物图像分割 288 289 290 291 |
| 计算机视觉 | 图像 | 目标检测 | 通用对象检测 292 293 294 295,飞行器 296,RGB-D 对象 297 |
| 计算机视觉 | 图像 | 其他应用 | 图像生成 37 48 69 269 298 299 300 301 302,图像检索 112 303, 视线估计 304,深度估计 305,定位 306,场景图预测 307, 基于图像的行人重识别 308 309,图像上色 310,颜色恒定性 311 |
| 计算机视觉 | 视频 | 视频分类 | 通用视频分类 177 235 312 313,手势识别 314 315,动作识别 120 316 317 318 319 320 321 |
| 计算机视觉 | 视频 | 视频检测 | 动作定位 322 323,活动检测 324 |
| 计算机视觉 | 视频 | 其他应用 | 视频预测 161 325,视频目标分割 326 327,语义索引 328, 视频重定向 329,视频生成 330,基于视频的行人重识别 331,目标跟踪 332,动作捕捉 333 |
| 领域 | 子领域 & 参考文献 |
|---|---|
| 自然语言处理 | 文本分类 334 335 336 337 338 339 340 341 342 343 344 345,对话系统 346 347 348 关系学习和知识图谱 349 350 351 352 353,词向量表示 354 355 356 357 358 命名实体识别 359 360 361,词预测 49 163 164,自然语言生成 362 363 364 365, 信息抽取 218,机器翻译 98,序列标注 366 |
| 音频&语音 | 音频/语音/声音分类 367 368 369 370 371 372 文本到语音 373 374 375 376,音频/声音事件检测 377 378 379,语音生成 367 380 关键词检测 381,关键词定位 382,人类跌倒检测 383,说话者识别 384 |
| 强化学习&机器人 | 模仿学习 385 386 387 388 389 390 391 392 393,视觉导航 50 138 145 172,机器人操作 394 395 |
| 数据分析 | 数据回归 50 138 139 140 142 143 144 146 |
| 跨领域 | 图像标注 265,视觉问答 265 266 |
| 其他应用 | 疾病预测 213 396 397 398 399 400 401,生物识别(如掌纹 402,耳 206), 药物发现 403,频谱分类 404,精准农业 405,网络安全 406,移动感知 407 |
7 FUTURE DIRECTIONS 未来方向
近年来,FSL 在方法学和应用方面取得了长足进展,但由于稀疏样本带来的固有困难,仍然存在诸多挑战。在本节中,我们提出了 FSL 的四个未来研究方向。
鲁棒性(Robustness) 目前大多数 FSL 研究基于理想数据假设,但这一假设难以适用于所有实际场景。在许多现实应用中,人们可能会面临一些破坏 FSL 理想设置的不确定干扰。例如,由于仪器故障或人为失误,少量训练数据可能受到异常干扰(例如,噪声样本或标签错误数据)408。这引发了一个问题:现有的 FSL 模型能否有效缓解这些异常样本的影响,并仍然保持可接受的泛化性能。此外,第 5.3 节中描述的辅助数据与任务特定数据之间可能存在的域偏移是另一种对 FSL 理想设置的干扰。因此,提高 FSL 模型对各种潜在干扰因素的鲁棒性具有重要意义。
通用性(Universality) 这里提到的通用性包括两个方面。首先是 FSL 方法的模型级通用性和可扩展性。目前,大多数 FSL 方法过度设计用于特定的基准任务和数据集,削弱了它们对其他更通用任务的适用性。理想的 FSL 框架应该能够处理不同数据复杂性和多样数据形式的各种学习任务。其次是 FSL 方法的应用级通用性和灵活性。目前大多数 FSL 研究关注于小规模任务类别和大规模标注辅助数据的简单应用场景。然而,现实问题可能带来更复杂的应用场景,如大规模任务类别、数据分布的长尾现象 409、任务类别的动态性、标注辅助数据不可用,甚至这些场景的混合。这对 FSL 方法的通用性提出了更高的要求和挑战。
可解释性(Interpretability) FSL 在近年来的激增和成功主要依赖于深度学习技术,但深度学习往往因缺乏可解释性而受到批评。模型可解释性是深度学习中的关键问题 410 411。我们认为,人类令人印象深刻的少样本学习能力受益于多方面,包括对经验知识的合理利用和对任务数据背后潜在知识的巧妙探索(例如,组合关系 37 59、数据组件之间的结构对应关系 412 等)。因此,如何利用外部先验知识和内部数据知识的融合来增强 FSL 模型的可解释性,可能成为未来的研究方向。
理论体系(Theoretical System) 如第 1 节所分析的,由稀疏训练样本引起的根本困难在于,由于缺乏由训练样本形成的有效函数正则化,学习函数 f f f 的搜索空间非常庞大。如果从这一理论视角重新审视现有的 FSL 方法,可以发现,所有 FSL 解决方案本质上都是通过特定技术实现函数正则化。例如,基于增强的 FSL 方法通过直接增加训练样本实现这一目标,而元学习方法则建议引入其他无关的学习任务以跨任务正则化学习函数。因此,从稀疏训练样本下正则化学习函数空间的角度构建系统的 FSL 理论体系,可能为 FSL 研究者带来新的启示。
7 FUTURE DIRECTIONS
让学习系统从少量样本中学习,对于机器学习和人工智能的进一步发展至关重要。本文对少样本学习(Few Sample Learning, FSL)进行了全面综述。特别是,回顾了 FSL 的发展历程和当前进展,并通过简洁且易于理解的分类法对所有 FSL 方法进行了归类。通过深入分析,揭示了主流基于元学习的 FSL 方法之间的潜在发展关系。此外,系统地总结了 FSL 的几个新兴扩展研究主题、在各个领域中的现有应用、当前基准数据集及其性能,以及一些潜在的研究方向。希望本综述能够促进对 FSL 相关知识的掌握,并推动 FSL 研究领域的协同发展。
B. Landau, L. B. Smith, and S. S. Jones, “The importance of shape in early lexical learning,” Cognitive Developement, vol. 3, no. 3, pp. 299–321, 1988. ↩︎
E. M. Markman, Categorization and naming in children: Problems of induction. MIT Press, 1989. ↩︎
F. Xu and J. B. Tenenbaum, “Word learning as bayesian inference.” Psychological Review, vol. 114, no. 2, pp. 245–272, 2007. ↩︎
I. Biederman, “Recognition-by-components: a theory of human image understanding.” Psychological Review, vol. 94, no. 2, pp. 115–147, 1987. ↩︎
S. Carey and E. Bartlett, “Acquiring a single new word.” Papers and Reports on Child Language Development, vol. 15, pp. 17–29, 1978. ↩︎
E. V. Clark, First language acquisition. Cambridge University Press, 2009. ↩︎
N. P. Rougier, D. C. Noelle, T. S. Braver, J. D. Cohen, and R. C. O’Reilly, “Prefrontal cortex and flexible cognitive control: Rules without symbols,” Proc. Nation. Academy Sci., vol. 102, no. 20, pp. 7338–7343, 2005. ↩︎
T. S. Braver, J. L. Paxton, H. S. Locke, and D. M. Barch, “Flexible neural mechanisms of cognitive control within human prefrontal cortex,” Proc. Nation. Academy Sci., vol. 106, no. 18, pp. 7351–7356, 2009. ↩︎
A. A. Kehagia, G. K. Murray, and T. W. Robbins, “Learning and cognitive flexibility: frontostriatal function and monoaminergic modulation,” Current Opinion in Neurobiology, vol. 20, no. 2, pp. 199–204, 2010. ↩︎
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. ↩︎
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2012, pp. 1097–1105. ↩︎ ↩︎ ↩︎ ↩︎
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2015, pp. 1–9. ↩︎ ↩︎
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 770–778. ↩︎ ↩︎ ↩︎
T. Mikolov, M. Karafiát, L. Burget, J. Černocký, and S. Khudanpur, “Recurrent neural network based language model,” in Proc. 11th Annu. Conf. Int. Speech Commun. Assoc. (INTERSPEECH), 2010. ↩︎
I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2014, pp. 3104–3112. ↩︎
G. Hinton, L. Deng, D. Yu, G. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, B. Kingsbury et al., “Deep neural networks for acoustic modeling in speech recognition,” IEEE Signal Process. Mag., vol. 29, no. 6, pp. 82–97, 2012. ↩︎
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot et al., “Mastering the game of go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, 2016. ↩︎
T. Gebru, J. Krause, Y. Wang, D. Chen, J. Deng, E. L. Aiden, and L. Fei-Fei, “Using deep learning and google street view to estimate the demographic makeup of neighborhoods across the united states,” Proc. Nation. Academy Sci., vol. 114, no. 50, pp. 13 108–13 113, 2017. ↩︎
19 ↩︎
S. Ghosal, D. Blystone, A. K. Singh, B. Ganapathysubramanian, A. Singh, and S. Sarkar, “An explainable deep machine vision framework for plant stress phenotyping,” Proc. Nation. Academy Sci., vol. 115, no. 18, pp. 4613–4618, 2018. ↩︎
M. S. Norouzzadeh, A. Nguyen, M. Kosmala, A. Swanson, M. S. Palmer, C. Packer, and J. Clune, “Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning,” Proc. Nation. Academy Sci., vol. 115, no. 25, pp. E5716–E5725, 2018. ↩︎
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997. ↩︎ ↩︎ ↩︎
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, 2015. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” Int. J. Comput. Vis., vol. 88, no. 2, pp. 303–338, 2010. ↩︎
S. Legg and M. Hutter, “Universal intelligence: A definition of machine intelligence,” Minds and Machines, vol. 17, no. 4, pp. 391–444, 2007. ↩︎
W. Wang, V. W. Zheng, H. Yu, and C. Miao, “A survey of zero-shot learning: Settings, methods, and applications,” ACM Trans. Intell. Syst. Technology, vol. 10, no. 2, p. 13, 2019. ↩︎
J. Shu, Z. Xu, and D. Meng, “Small sample learning in big data era,” arXiv preprint arXiv:1808.04572, 2018. ↩︎
Y. Wang, Q. Yao, J. T. Kwok, and N. L. M., “Generalizing from a few examples: a survey on few-shot learning,” arXiv preprint arXiv:1904.05046, 2019. ↩︎
E. G. Miller, N. E. Matsakis, and P. A. Viola, “Learning from one example through shared densities on transforms,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2000, pp. 464–471. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for one-shot image recognition,” in Proc. Int. Conf. Mach. Learn. (ICML) Deep Learn. Workshop, vol. 2, 2015. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
L. Fe-Fei, R. Fergus, and P. Perona, “A bayesian approach to unsupervised one-shot learning of object categories,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2003, pp. 1134–1141. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
L. Fei-Fei, R. Fergus, and P. Perona, “Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR) Workshop, 2004. ↩︎ ↩︎ ↩︎ ↩︎
——, “One-shot learning of object categories,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 28, no. 4, pp. 594–611, 2006. ↩︎ ↩︎ ↩︎ ↩︎
B. Lake, R. Salakhutdinov, J. Gross, and J. Tenenbaum, “One shot learning of simple visual concepts,” in Proc. Annu. Meet. Cogni. Sci. Soc. (CogSci), vol. 33, no. 33, 2011. ↩︎ ↩︎ ↩︎ ↩︎
B. Lake, R. Salakhutdinov, and J. Tenenbaum, “Concept learning as motor program induction: A large-scale empirical study,” in Proc. Annu. Meet. Cogni. Sci. Soc. (CogSci), vol. 34, no. 34, 2012. ↩︎ ↩︎ ↩︎ ↩︎
B. M. Lake, R. R. Salakhutdinov, and J. Tenenbaum, “One-shot learning by inverting a compositional causal process,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2013, pp. 2526–2534. ↩︎ ↩︎ ↩︎ ↩︎
B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum, “Humanlevel concept learning through probabilistic program induction,” Science, vol. 350, no. 6266, pp. 1332–1338, 2015. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
M. Fink, “Object classification from a single example utilizing class relevance metrics,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2005, pp. 449–456. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
L. Wolf and I. Martin, “Robust boosting for learning from few examples,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2005, pp. 359–364. ↩︎ ↩︎ ↩︎ ↩︎
E. Bart and S. Ullman, “Cross-generalization: Learning novel classes from a single example by feature replacement,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2005, pp. 672–679. ↩︎ ↩︎
T. Tommasi and B. Caputo, “The more you know, the less you learn: from knowledge transfer to one-shot learning of object categories,” in Proc. British Mach. Vis. Conf. (BMVC), 2009. ↩︎ ↩︎
X. Yu and Y. Aloimonos, “Attribute-based transfer learning for object categorization with zero/one training example,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2010, pp. 127–140. ↩︎ ↩︎ ↩︎ ↩︎
K. D. Tang, M. F. Tappen, R. Sukthankar, and C. H. Lampert, “Optimizing one-shot recognition with micro-set learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2010, pp. 3027–3034. ↩︎ ↩︎ ↩︎ ↩︎
M. A. Tanner and W. H. Wong, “The calculation of posterior distributions by data augmentation,” J. American Statistical Assoc., vol. 82, no. 398, pp. 528–540, 1987. ↩︎
E. P. Xing, M. I. Jordan, S. J. Russell, and A. Y. Ng, “Distance metric learning with application to clustering with side-information,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2003, pp. 521–528. ↩︎ ↩︎
R. Vilalta and Y. Drissi, “A perspective view and survey of metalearning,” Artificial Intell. Review, vol. 18, no. 2, pp. 77–95, 2002. ↩︎
H. Edwards and A. Storkey, “Towards a neural statistician,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2016. ↩︎
D. Rezende, I. Danihelka, K. Gregor, D. Wierstra et al., “One-shot generalization in deep generative models,” in Proc. Int. Conf. Mach. Learn. (ICML), 2016, pp. 1521–1529. ↩︎ ↩︎
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra et al., “Matching networks for one shot learning,” in Proc. Advances Neural Inf. Process. Syst. (NIPS), 2016, pp. 3630–3638. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in Proc. Int. Conf. Mach. Learn. (ICML), 2017, pp. 1126–1135. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
S. Ravi and H. Larochelle, “Optimization as a model for few-shot learning,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap, “Meta-learning with memory-augmented neural networks,” in Proc. Int. Conf. Mach. Learn. (ICML), 2016, pp. 1842–1850. ↩︎ ↩︎
T. Munkhdalai and H. Yu, “Meta networks,” in Proc. Int. Conf. Mach. Learn. (ICML), 2017, pp. 2554–2563. ↩︎ ↩︎ ↩︎
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” in Proc. Advances Neural Inf. Process. Syst. (NIPS), 2017, pp. 4077–4087. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 1199–1208. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
H. Li, W. Dong, X. Mei, C. Ma, F. Huang, and B.-G. Hu, “Lgm-net: Learning to generate matching networks for few-shot learning,” in Proc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 3825–3834. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
R. Salakhutdinov, J. Tenenbaum, and A. Torralba, “One-shot learning with a hierarchical nonparametric bayesian model,” in Proc. Int. Conf. Mach. Learn. (ICML) Workshop on Unsupervised and Transfer Learning, 2012, pp. 195–206. ↩︎ ↩︎ ↩︎
F. Fleuret and G. Blanchard, “Pattern recognition from one example by chopping,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2006, pp. 371–378. ↩︎ ↩︎ ↩︎
A. Wong and A. L. Yuille, “One shot learning via compositions of meaningful patches,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015, pp. 1197–1205. ↩︎ ↩︎ ↩︎
H. Edwards and A. Storkey, “Towards a neural statistician,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017. ↩︎ ↩︎
P. J. Grother, “Nist special database 19-hand-printed forms and characters database,” National Institute of Standards and Technology, Tech. Rep., 1995. ↩︎
M. Weber, M. Welling, and P. Perona, “Unsupervised learning of models for recognition,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2000, pp. 18–32. ↩︎
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
S. A. Nene, S. K. Nayar, and H. Murase, “Columbia object image library (coil-100),” CUCS-006-96, Columbia University, Tech. Rep., 1996. ↩︎
J. J. Hull, “A database for handwritten text recognition research,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 16, no. 5, pp. 550–554, 1994. ↩︎
L. Wolf, T. Hassner, and I. Maoz, “Face recognition in unconstrained videos with matched background similarity,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2011, pp. 529–534. ↩︎
K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman, “Return of the devil in the details: Delving deep into convolutional nets,” in Proc. British Mach. Vis. Conf. (BMVC), 2014. ↩︎
M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2014, pp. 818–833. ↩︎
A. Antoniou, A. Storkey, and H. Edwards, “Data augmentation generative adversarial networks,” in Proc. Int. Conf. Learn. Represent. (ICLR) Workshop, 2018. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
C. H. Lampert, H. Nickisch, and S. Harmeling, “Attribute-based classification for zero-shot visual object categorization,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 3, pp. 453–465, 2013. ↩︎
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2013, pp. 3111–3119. ↩︎
R. Kwitt, S. Hegenbart, and M. Niethammer, “One-shot learning of scene locations via feature trajectory transfer,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 78–86. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
M. Dixit, R. Kwitt, M. Niethammer, and N. Vasconcelos, “Aga: Attribute-guided augmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 7455–7463. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Z. Chen, Y. Fu, Y. Zhang, Y.-G. Jiang, X. Xue, and L. Sigal, “Semantic feature augmentation in few-shot learning,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018. ↩︎ ↩︎ ↩︎ ↩︎
Z. Chen, Y. Fu, Y.-G. Jiang, X. Xue, and L. Sigal, “Multi-level semantic feature augmentation for one-shot learning,” IEEE Trans. Image Process., vol. 28, no. 9, pp. 4594–4605, 2019. ↩︎ ↩︎ ↩︎
J. Lu, J. Li, Z. Yan, F. Mei, and C. Zhang, “Attribute-based synthetic network (abs-net): Learning more from pseudo feature representations,” Pattern Recognit., vol. 80, pp. 129–142, 2018. ↩︎ ↩︎ ↩︎ ↩︎
M. Rosen-Zvi, C. Chemudugunta, T. Griffiths, P. Smyth, and M. Steyvers, “Learning author-topic models from text corpora,” ACM Trans. Inf. Syst., vol. 28, no. 1, pp. 1–38, 2010. ↩︎
P.-Y. Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays, “Transient attributes for high-level understanding and editing of outdoor scenes,” ACM Trans. Graphics, vol. 33, no. 4, pp. 1–11, 2014. ↩︎
G. Patterson, C. Xu, H. Su, and J. Hays, “The sun attribute database: Beyond categories for deeper scene understanding,” Int. J. Comput. Vis., vol. 108, no. 1-2, pp. 59–81, 2014. ↩︎
S. Song, S. P. Lichtenberg, and J. Xiao, “Sun rgb-d: A rgb-d scene understanding benchmark suite,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2015, pp. 567–576. ↩︎
C. H. Lampert, H. Nickisch, and S. Harmeling, “Learning to detect unseen object classes by between-class attribute transfer,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2009, pp. 951–958. ↩︎ ↩︎
A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” Citeseer, Princeton, NJ, USA, Tech. Rep., 2009. ↩︎ ↩︎ ↩︎
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” California Institute of Technology, Tech. Rep., 2011. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
G. Griffin, A. Holub, and P. Perona, “Caltech-256 object category dataset,” 2007. ↩︎ ↩︎
R. Fergus, P. Perona, and A. Zisserman, “Object class recognition by unsupervised scale-invariant learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), vol. 2, 2003, pp. II–II. ↩︎
B. Hariharan and R. Girshick, “Low-shot visual recognition by shrinking and hallucinating features,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017, pp. 3018–3027. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Y.-X. Wang, R. Girshick, M. Hebert, and B. Hariharan, “Low-shot learning from imaginary data,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 7278–7286. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
H. Gao, Z. Shou, A. Zareian, H. Zhang, and S.-F. Chang, “Lowshot learning via covariance-preserving adversarial augmentation networks,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 975–985. ↩︎ ↩︎ ↩︎ ↩︎
E. Schwartz, L. Karlinsky, J. Shtok, S. Harary, M. Marder, A. Kumar, R. Feris, R. Giryes, and A. Bronstein, “Delta-encoder: an effective sample synthesis method for few-shot object recognition,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 2845–2855. ↩︎ ↩︎ ↩︎ ↩︎
A. Farhadi, I. Endres, D. Hoiem, and D. Forsyth, “Describing objects by their attributes,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2009, pp. 1778–1785. ↩︎
G. Cohen, S. Afshar, J. Tapson, and A. Van Schaik, “Emnist: Extending mnist to handwritten letters,” in Proc. Int. Joint Conf. Neural Net. (IJCNN), 2017, pp. 2921–2926. ↩︎ ↩︎
O. M. Parkhi, A. Vedaldi, and A. Zisserman, “Deep face recognition,” in Proc. British Mach. Vis. Conf. (BMVC), 2015. ↩︎
Z. Chen, Y. Fu, Y.-X. Wang, L. Ma, W. Liu, and M. Hebert, “Image deformation meta-networks for one-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 8680–8689. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2014, pp. 2672–2680. ↩︎ ↩︎
T. Hertz, A. B. Hillel, and D. Weinshall, “Learning a kernel function for classification with small training samples,” in Proc. Int. Conf. Mach. Learn. (ICML), 2006, pp. 401–408. ↩︎ ↩︎ ↩︎
M. Ye and Y. Guo, “Deep triplet ranking networks for one-shot recognition,” arXiv preprint arXiv:1804.07275, 2018. ↩︎ ↩︎ ↩︎ ↩︎
A. Mehrotra and A. Dukkipati, “Generative adversarial residual pairwise networks for one shot learning,” arXiv preprint arXiv:1703.08033, 2017. ↩︎ ↩︎ ↩︎ ↩︎
Ł. Kaiser, O. Nachum, A. Roy, and S. Bengio, “Learning to remember rare events,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
T. Scott, K. Ridgeway, and M. C. Mozer, “Adapted deep embeddings: A synthesis of methods for k-shot inductive transfer learning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 76–85. ↩︎ ↩︎ ↩︎ ↩︎
J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu, “Learning fine-grained image similarity with deep ranking,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2014, pp. 1386–1393. ↩︎
E. Ustinova and V. Lempitsky, “Learning deep embeddings with histogram loss,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2016, pp. 4170–4178. ↩︎ ↩︎
C. L. Blake and C. J. Merz, “Uci repository of machine learning databases, 1998,” 1998. [Online]. Available: http://www.ics.uci.edu/~mlearn/MLRepository.html ↩︎ ↩︎
A. S. Georghiades, P. N. Belhumeur, and D. J. Kriegman, “From few to many: Generative models for recognition under variable pose and illumination,” in Proc. IEEE Int. Conf. Automatic Face and Gesture recognit. (cat. no. pr00580), 2000, pp. 277–284. ↩︎
37 ↩︎
Y. Bengio, S. Bengio, and J. Cloutier, Learning a synaptic learning rule. Université de Montréal, Département d’informatique et de recherche, 1990. ↩︎
D. K. Naik and R. Mammone, “Meta-neural networks that learn by learning,” in Proc. Int. Joint Conf. Neural Net. (IJCNN), 1992. ↩︎
S. Thrun and L. Pratt, Learning to learn. Springer Science & Business Media, 1998. ↩︎
M. Andrychowicz, M. Denil, S. Gomez, M. W. Hoffman, D. Pfau, T. Schaul, B. Shillingford, and N. De Freitas, “Learning to learn by gradient descent by gradient descent,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2016, pp. 3981–3989. ↩︎
K. Li and J. Malik, “Learning to optimize,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017. ↩︎
Y. Chen, M. W. Hoffman, S. G. Colmenarejo, M. Denil, T. P. Lillicrap, M. Botvinick, and N. de Freitas, “Learning to learn without gradient descent by gradient descent,” in Proc. Int. Conf. Mach. Learn. (ICML), 2017, pp. 748–756. ↩︎
J. Goldberger, G. E. Hinton, S. T. Roweis, and R. R. Salakhutdinov, “Neighbourhood components analysis,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2005, pp. 513–520. ↩︎
E. Triantafillou, R. Zemel, and R. Urtasun, “Few-shot learning through an information retrieval lens,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 2255–2265. ↩︎ ↩︎ ↩︎
I. Tsochantaridis, T. Joachims, T. Hofmann, and Y. Altun, “Large margin methods for structured and interdependent output variables,” J. Mach. Learn. Research, vol. 6, no. Sep, pp. 1453–1484, 2005. ↩︎
T. Hazan, J. Keshet, and D. A. McAllester, “Direct loss minimization for structured prediction,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2010, pp. 1594–1602. ↩︎
B. Oreshkin, P. R. López, and A. Lacoste, “Tadam: Task dependent adaptive metric for improved few-shot learning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 721–731. ↩︎ ↩︎ ↩︎ ↩︎
E. Perez, F. Strub, H. De Vries, V. Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” in Proc. AAAI Conf. Artificial Intell. (AAAI), 2018, pp. 3942–3951. ↩︎ ↩︎
C. Xing, N. Rostamzadeh, B. Oreshkin, and P. O. Pinheiro, “Adaptive cross-modal few-shot learning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 4848–4858. ↩︎ ↩︎ ↩︎ ↩︎
J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2014, pp. 1532–1543. ↩︎
F. Hao, J. Cheng, L. Wang, and J. Cao, “Instance-level embedding adaptation for few-shot learning,” IEEE Access, vol. 7, pp. 100 501–100 511, 2019. ↩︎ ↩︎
P. Hu, X. Sun, K. Saenko, and S. Sclaroff, “Weakly-supervised compositional feature aggregation for few-shot recognition,” arXiv preprint arXiv:1906.04833, 2019. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
X. Li, L. Yu, C.-W. Fu, M. Fang, and P.-A. Heng, “Revisiting metric learning for few-shot image classification,” Neurocomputing, 2020. ↩︎ ↩︎
Y. Zheng, R. Wang, J. Yang, L. Xue, and M. Hu, “Principal characteristic networks for few-shot learning,” J. Vis. Commun. Image Represent., vol. 59, pp. 563–573, 2019. ↩︎ ↩︎
N. Dvornik, C. Schmid, and J. Mairal, “Diversity with cooperation: Ensemble methods for few-shot classification,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 3723–3731. ↩︎ ↩︎ ↩︎ ↩︎
H. Prol, V. Dumoulin, and L. Herranz, “Cross-modulation networks for few-shot learning,” arXiv preprint arXiv:1812.00273, 2018. ↩︎ ↩︎
Q. Cai, Y. Pan, T. Yao, C. Yan, and T. Mei, “Memory matching networks for one-shot image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 4080–4088. ↩︎ ↩︎
J. Weston, S. Chopra, and A. Bordes, “Memory networks,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2014. ↩︎
L. Zhang, J. Liu, M. Luo, X. Chang, Q. Zheng, and A. G. Hauptmann, “Scheduled sampling for one-shot learning via matching network,” Pattern Recognit., vol. 96, p. 106962, 2019. ↩︎ ↩︎
N. Hilliard, L. Phillips, S. Howland, A. Yankov, C. D. Corley, and N. O. Hodas, “Few-shot learning with metric-agnostic conditional embeddings,” arXiv preprint arXiv:1802.04376, 2018. ↩︎ ↩︎ ↩︎
X. Zhang, F. Sung, Y. Qiang, Y. Yang, and T. M. Hospedales, “Deep comparison: Relation columns for few-shot learning,” arXiv preprint arXiv:1811.07100, 2018. ↩︎ ↩︎
W. Li, J. Xu, J. Huo, L. Wang, Y. Gao, and J. Luo, “Distribution consistency based covariance metric networks for few-shot learning,” in Proc. AAAI Conf. Artificial Intell. (AAAI), vol. 33, 2019, pp. 8642–8649. ↩︎ ↩︎ ↩︎
W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo, “Revisiting local descriptor based image-to-class measure for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 7260–7268. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
H. Zhang and P. Koniusz, “Power normalizing second-order similarity network for few-shot learning,” in Proc. IEEE Winter Conf. Applica. Comput. Vis. (WACV), 2019, pp. 1185–1193. ↩︎ ↩︎
B. Hui, P. Zhu, Q. Hu, and Q. Wang, “Self-attention relation network for few-shot learning,” in Proc. IEEE Int. Conf. Multimedia Expo Workshops (ICMEW), 2019, pp. 198–203. ↩︎ ↩︎
V. Garcia and J. Bruna, “Few-shot learning with graph neural networks,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2018. ↩︎ ↩︎ ↩︎
J. Kim, T. Kim, S. Kim, and C. D. Yoo, “Edge-labeling graph neural network for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 11–20. ↩︎ ↩︎
Y. Wang, X.-M. Wu, Q. Li, J. Gu, W. Xiang, L. Zhang, and V. O. Li, “Large margin few-shot learning,” arXiv preprint arXiv:1807.02872, 2018. ↩︎ ↩︎
H. Li, D. Eigen, S. Dodge, M. Zeiler, and X. Wang, “Finding taskrelevant features for few-shot learning by category traversal,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 1–10. ↩︎ ↩︎ ↩︎
Z. Li, F. Zhou, F. Chen, and H. Li, “Meta-sgd: Learning to learn quickly for few-shot learning,” arXiv preprint arXiv:1707.09835, 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Y. Lee and S. Choi, “Gradient-based meta-learning with learned layerwise metric and subspace,” in Proc. Int. Conf. Mach. Learn. (ICML), 2018, pp. 2927–2936. ↩︎ ↩︎ ↩︎ ↩︎
A. Nichol and J. Schulman, “Reptile: a scalable metalearning algorithm,” arXiv preprint arXiv:1803.02999, vol. 2, p. 2, 2018. ↩︎ ↩︎ ↩︎ ↩︎
F. Zhou, B. Wu, and Z. Li, “Deep meta-learning: Learning to learn in the concept space,” arXiv preprint arXiv:1802.03596, 2018. ↩︎ ↩︎ ↩︎
E. Grant, C. Finn, S. Levine, T. Darrell, and T. Griffiths, “Recasting gradient-based meta-learning as hierarchical bayes,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2018. ↩︎ ↩︎ ↩︎ ↩︎
C. Finn, K. Xu, and S. Levine, “Probabilistic model-agnostic metalearning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 9516–9527. ↩︎ ↩︎ ↩︎
J. Yoon, T. Kim, O. Dia, S. Kim, Y. Bengio, and S. Ahn, “Bayesian model-agnostic meta-learning,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 7332–7343. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
M. A. Jamal and G.-J. Qi, “Task agnostic meta-learning for fewshot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 11 719–11 727. ↩︎ ↩︎ ↩︎ ↩︎
A. A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanu, S. Osindero, and R. Hadsell, “Meta-learning with latent embedding optimization,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎ ↩︎ ↩︎
X. Jiang, M. Havaei, F. Varno, G. Chartrand, N. Chapados, and S. Matwin, “Learning to learn with conditional class dependencies,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎ ↩︎
Q. Liu and D. Wang, “Stein variational gradient descent: A general purpose bayesian inference algorithm,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2016, pp. 2378–2386. ↩︎
J. Nie, N. Xu, M. Zhou, G. Yan, and Z. Wei, “3d model classification based on few-shot learning,” Neurocomputing, vol. 398, pp. 539–546, 2020. ↩︎ ↩︎
Q. Sun, Y. Liu, T.-S. Chua, and B. Schiele, “Meta-transfer learning for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 403–412. ↩︎ ↩︎
S. Gidaris and N. Komodakis, “Dynamic few-shot visual learning without forgetting,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 4367–4375. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
S. Qiao, C. Liu, W. Shen, and A. L. Yuille, “Few-shot image recognition by predicting parameters from activations,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 7229–7238. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
H. Qi, M. Brown, and D. G. Lowe, “Low-shot learning with imprinted weights,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 5822–5830. ↩︎ ↩︎ ↩︎
S. Gidaris and N. Komodakis, “Generating classification weights with gnn denoising autoencoders for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 21–30. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
J. Gordon, J. Bronskill, M. Bauer, S. Nowozin, and R. E. Turner, “Meta-learning probabilistic inference for prediction,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎ ↩︎ ↩︎
L. Bertinetto, J. F. Henriques, P. H. Torr, and A. Vedaldi, “Metalearning with differentiable closed-form solvers,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
K. Lee, S. Maji, A. Ravichandran, and S. Soatto, “Meta-learning with differentiable convex optimization,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 10 657–10 665. ↩︎ ↩︎ ↩︎ ↩︎
L. Bertinetto, J. F. Henriques, J. Valmadre, P. Torr, and A. Vedaldi, “Learning feed-forward one-shot learners,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2016, pp. 523–531. ↩︎ ↩︎ ↩︎ ↩︎
F. Zhao, J. Zhao, S. Yan, and J. Feng, “Dynamic conditional networks for few-shot learning,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 19–35. ↩︎ ↩︎ ↩︎ ↩︎
Y.-X. Wang and M. Hebert, “Learning to learn: Model regression networks for easy small sample learning,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2016, pp. 616–634. ↩︎ ↩︎ ↩︎ ↩︎
T. Wu, J. Peurifoy, I. L. Chuang, and M. Tegmark, “Metalearning autoencoders for few-shot prediction,” arXiv preprint arXiv:1807.09912, 2018. ↩︎ ↩︎ ↩︎ ↩︎
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2014. ↩︎
T. Munkhdalai, X. Yuan, S. Mehri, and A. Trischler, “Rapid adaptation with conditionally shifted neurons,” in Proc. Int. Conf. Mach. Learn. (ICML), 2018, pp. 3664–3673. ↩︎ ↩︎ ↩︎ ↩︎
T. Munkhdalai and A. Trischler, “Metalearning with hebbian fast weights,” arXiv preprint arXiv:1807.05076, 2018. ↩︎ ↩︎ ↩︎ ↩︎
H.-J. Ye, H. Hu, D.-C. Zhan, and F. Sha, “Few-shot learning via embedding adaptation with set-to-set functions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
D. O. Hebb, The organization of behavior: a neuropsychological theory. J. Wiley; Chapman & Hall, 1949. ↩︎
M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. R. Salakhutdinov, and A. J. Smola, “Deep sets,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 3391–3401. ↩︎
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017. ↩︎ ↩︎
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 5998–6008. ↩︎
A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap, “Meta-learning with memory-augmented neural networks,” in Proc. Int. Conf. Mach. Learn. (ICML), 2016, pp. 1842–1850. ↩︎
P. Shyam, S. Gupta, and A. Dukkipati, “Attentive recurrent comparators,” in Proc. Int. Conf. Mach. Learn. (ICML), 2017, pp. 3173–3181. ↩︎ ↩︎
N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel, “A simple neural attentive meta-learner,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2018. ↩︎ ↩︎ ↩︎ ↩︎
T. Ramalho and M. Garnelo, “Adaptive posterior learning: few-shot learning with a surprise-based memory module,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎
A. Graves, G. Wayne, and I. Danihelka, “Neural turing machines,” arXiv preprint arXiv:1410.5401, 2014. ↩︎
S. Hochreiter, Y. Bengio, P. Frasconi, J. Schmidhuber et al., “Gradient flow in recurrent nets: the difficulty of learning long-term dependencies.” A field guide to dynamical recurrent neural networks. IEEE Press, 2001. ↩︎
Y. Zhang and Q. Yang, “A survey on multi-task learning,” arXiv preprint arXiv:1707.08114, 2017. ↩︎
W. Yan, J. Yap, and G. Mori, “Multi-task transfer methods to improve one-shot learning for multimedia event detection,” in Proc. British Mach. Vis. Conf. (BMVC), 2015, pp. 3701–3713. ↩︎ ↩︎ ↩︎
R. Zhang, T. Che, Z. Ghahramani, Y. Bengio, and Y. Song, “Metagan: An adversarial approach to few-shot learning,” in Proc. Advances Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 2365–2374. ↩︎ ↩︎ ↩︎ ↩︎
Z. Hu, X. Li, C. Tu, Z. Liu, and M. Sun, “Few-shot charge prediction with discriminative legal attributes,” in Proc. Int. Conf. Computational Linguistics, 2018, pp. 487–498. ↩︎ ↩︎
C. Doersch, A. Gupta, and A. A. Efros, “Unsupervised visual representation learning by context prediction,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015, pp. 1422–1430. ↩︎ ↩︎
M. Noroozi and P. Favaro, “Unsupervised learning of visual representations by solving jigsaw puzzles,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2016, pp. 69–84. ↩︎ ↩︎
H.-Y. Tung, H.-W. Tung, E. Yumer, and K. Fragkiadaki, “Self-supervised learning of motion capture,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 5236–5246. ↩︎
B. Fernando, H. Bilen, E. Gavves, and S. Gould, “Self-supervised video representation learning with odd-one-out networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 3636–3645. ↩︎
S. Gidaris, P. Singh, and N. Komodakis, “Unsupervised representation learning by predicting image rotations,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2018. ↩︎ ↩︎
M. Noroozi, A. Vinjimoor, P. Favaro, and H. Pirsiavash, “Boosting self-supervised learning via knowledge transfer,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 9359–9367. ↩︎ ↩︎
T. Nathan Mundhenk, D. Ho, and B. Y. Chen, “Improvements to context based self-supervised learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 9339–9348. ↩︎ ↩︎
D. Hendrycks, M. Mazeika, S. Kadavath, and D. Song, “Using self-supervised learning can improve model robustness and uncertainty,” in Proc. Advances Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 15 663–15 674. ↩︎
A. Kolesnikov, X. Zhai, and L. Beyer, “Revisiting self-supervised visual representation learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 1920–1929. ↩︎
L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., 2020. ↩︎
H. Wang, X. Wang, W. Xiong, M. Yu, X. Guo, S. Chang, and W. Y. Wang, “Self-supervised learning for contextualized extractive summarization,” in Proc. Annu. Meet. Assoc. Computational Linguistics (ACL), 2019, pp. 2221–2227. ↩︎
D. Kang, A. Balakrishnan, P. Shah, P. A. Crook, Y.-L. Boureau, and J. Weston, “Recommendation as a communication game: Self-supervised bot-play for goal-oriented dialogue,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2019, pp. 1951– 1961. ↩︎
X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen, Y.-F. Wang, W. Y. Wang, and L. Zhang, “Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 6629–6638. ↩︎
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2020. ↩︎
A. Dosovitskiy, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with convolutional neural networks,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2014, pp. 766–774. ↩︎
J.-C. Su, S. Maji, and B. Hariharan, “Boosting supervision with self-supervision for few-shot learning,” arXiv preprint arXiv:1906.07079, 2019. ↩︎ ↩︎ ↩︎ ↩︎
S. Gidaris, A. Bursuc, N. Komodakis, P. Pérez, and M. Cord, “Boosting few-shot visual learning with self-supervision,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 8059–8068. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
X. Li, Q. Sun, Y. Liu, Q. Zhou, S. Zheng, T.-S. Chua, and B. Schiele, “Learning to self-train for semi-supervised few-shot classification,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 10 276– 10 286. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
P. Mangla, N. Kumari, A. Sinha, M. Singh, B. Krishnamurthy, and V. N. Balasubramanian, “Charting the right manifold: Manifold mixup for few-shot learning,” in Proc. IEEE Winter Conf. Applica. Comput. Vis. (WACV), 2020, pp. 2218–2227. ↩︎ ↩︎ ↩︎ ↩︎
V. N. Vapnik, “An overview of statistical learning theory,” IEEE Trans. Neural Net., vol. 10, no. 5, pp. 988–999, 1999. ↩︎
Y. Liu, J. Lee, M. Park, S. Kim, E. Yang, S. J. Hwang, and Y. Yang, “Learning to propagate labels: Transductive propagation network for few-shot learning,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎ ↩︎
Z. Xu, L. Zhu, and Y. Yang, “Few-shot object recognition from machine-labeled web images,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 1164–1172. ↩︎
M. Bauer, M. Rojas-Carulla, J. B. ́Swi ̨atkowski, B. Schölkopf, and R. E. Turner, “Discriminative k-shot learning using probabilistic models,” arXiv preprint arXiv:1706.00326, 2017. ↩︎ ↩︎
L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel programming for hyperparameter optimization and metalearning,” in Proc. Int. Conf. Mach. Learn. (ICML), 2018, pp. 1568– 1577. ↩︎ ↩︎
A. Kimura, Z. Ghahramani, K. Takeuchi, T. Iwata, and N. Ueda, “Few-shot learning of neural networks from scratch by pseudo example optimization,” arXiv preprint arXiv:1802.03039, 2018. ↩︎
Y. Lifchitz, Y. Avrithis, S. Picard, and A. Bursuc, “Dense classification and implanting for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 9258–9267. ↩︎ ↩︎
H. Zhang, J. Zhang, and P. Koniusz, “Few-shot learning via saliency-guided hallucination of samples,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 2770–2779. ↩︎ ↩︎ ↩︎
W.-Y. Chen, Y.-C. Liu, Z. Kira, Y.-C. F. Wang, and J.-B. Huang, “A closer look at few-shot classification,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎ ↩︎
Y. Wang, W.-L. Chao, K. Q. Weinberger, and L. van der Maaten, “Simpleshot: Revisiting nearest-neighbor classification for few-shot learning,” arXiv preprint arXiv:1911.04623, 2019. ↩︎ ↩︎
R. Boney and A. Ilin, “Semi-supervised and active few-shot learning with prototypical networks,” arXiv preprint arXiv:1711.10856, 2017. ↩︎ ↩︎
M. Ren, E. Triantafillou, S. Ravi, J. Snell, K. Swersky, J. B. Tenenbaum, H. Larochelle, and R. S. Zemel, “Meta-learning for semisupervised few-shot classification,” arXiv preprint arXiv:1803.00676, 2018. ↩︎ ↩︎
K. R. Allen, E. Shelhamer, H. Shin, and J. B. Tenenbaum, “Infinite mixture prototypes for few-shot learning,” arXiv preprint arXiv:1902.04552, 2019. ↩︎ ↩︎
J. Wang, K. Chen, L. Shou, S. Wu, and S. Mehrotra, “Semisupervised few-shot learning for dual question-answer extraction,” arXiv preprint arXiv:1904.03898, 2019. ↩︎
T. Ma and A. Zhang, “Affinitynet: semi-supervised few-shot learning for disease type prediction,” in Proc. AAAI Conf. Artificial Intell. (AAAI), vol. 33, 2019, pp. 1069–1076. ↩︎ ↩︎
K. Hsu, S. Levine, and C. Finn, “Unsupervised learning via metalearning,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎ ↩︎
D. Berthelot, C. Raffel, A. Roy, and I. Goodfellow, “Understanding and improving interpolation in autoencoders via an adversarial regularizer,” arXiv preprint arXiv:1807.07543, 2018. ↩︎
S. Khodadadeh, L. Boloni, and M. Shah, “Unsupervised metalearning for few-shot image classification,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 10 132–10 142. ↩︎ ↩︎ ↩︎
A. Antoniou and A. Storkey, “Assume, augment and learn: Unsupervised few-shot meta-learning via random labels and data augmentation,” arXiv preprint arXiv:1902.09884, 2019. ↩︎ ↩︎
V. M. Patel, R. Gopalan, R. Li, and R. Chellappa, “Visual domain adaptation: A survey of recent advances,” IEEE Signal Process. Mag., vol. 32, no. 3, pp. 53–69, 2015. ↩︎ ↩︎
S. Motiian, Q. Jones, S. Iranmanesh, and G. Doretto, “Few-shot adversarial domain adaptation,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 6670–6680. ↩︎
Z. Luo, Y. Zou, J. Hoffman, and L. F. Fei-Fei, “Label efficient learning of transferable representations across domains and tasks,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 165–177. ↩︎ ↩︎
N. Dong and E. P. Xing, “Domain adaption in one-shot learning,” in Proc. Joint Eur. Conf. Mach. Learn. Know. Dis. in Databases. Springer, 2018, pp. 573–588. ↩︎ ↩︎
B. Kang and J. Feng, “Transferable meta learning across domains.” in Proc. Conf. Uncertainty in Artificial Intell., 2018, pp. 177–187. ↩︎ ↩︎
D. Sahoo, H. Le, C. Liu, and S. C. Hoi, “Meta-learning with domain adaptation for few-shot learning under domain shift,” submitted to ICLR 2019. ↩︎ ↩︎
H.-Y. Tseng, H.-Y. Lee, J.-B. Huang, and M.-H. Yang, “Crossdomain few-shot classification via learned feature-wise transformation,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2020. ↩︎ ↩︎
J. Lu, Z. Cao, K. Wu, G. Zhang, and C. Zhang, “Boosting few-shot image recognition via domain alignment prototypical networks,” in Proc. IEEE Int. Conf. Tools Artificial Intell. (ICTAI), 2018, pp. 260–264. ↩︎ ↩︎
Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural images with unsupervised feature learning,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS) Workshop on Deep Learning and Unsupervised Feature Learning, 2011, pp. 165–177. ↩︎ ↩︎
226 ↩︎
Y. Le Cun, L. D. Jackel, B. Boser, J. S. Denker, H. P. Graf, I. Guyon, D. Henderson, R. E. Howard, and W. Hubbard, “Handwritten digit recognition: Applications of neural network chips and automatic learning,” IEEE Commun. Mag., vol. 27, no. 11, pp. 41–46, 1989. ↩︎
K. Saenko, B. Kulis, M. Fritz, and T. Darrell, “Adapting visual category models to new domains,” in Proc. Eur. Conf. Comput. Vis. (ECCV). Springer, 2010, pp. 213–226. ↩︎
H. Venkateswara, J. Eusebio, S. Chakraborty, and S. Panchanathan, “Deep hashing network for unsupervised domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 5018–5027. ↩︎ ↩︎
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object representations for fine-grained categorization,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV) Workshop, 2013, pp. 554–561. ↩︎
231 ↩︎
232 ↩︎
224 ↩︎
L. Zhu and Y. Yang, “Compound memory networks for few-shot video classification,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 751–766. ↩︎ ↩︎
I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y. Bengio, “An empirical investigation of catastrophic forgetting in gradientbased neural networks,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2014. ↩︎
X. Shi, L. Salewski, M. Schiegg, Z. Akata, and M. Welling, “Relational generalized few-shot learning,” arXiv preprint arXiv:1907.09557, 2019. ↩︎
M. Ren, R. Liao, E. Fetaya, and R. Zemel, “Incremental few-shot learning with attention attractor networks,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 5276–5286. ↩︎
S. Rahman, S. Khan, and F. Porikli, “A unified approach for conventional zero-shot, generalized zero-shot, and few-shot learning,” IEEE Trans. Image Process., vol. 27, no. 11, pp. 5652–5667, 2018. ↩︎
E. Schonfeld, S. Ebrahimi, S. Sinha, T. Darrell, and Z. Akata, “Generalized zero-and few-shot learning via aligned variational autoencoders,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 8247–8255. ↩︎ ↩︎ ↩︎ ↩︎
Y. Huang and L. Wang, “Acmm: Aligned cross-modal memory for few-shot image and sentence matching,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 5774–5783. ↩︎ ↩︎
Y. Huang, Y. Long, and L. Wang, “Few-shot image and sentence matching via gated visual-semantic embedding,” in Proc. AAAI Conf. Artificial Intell. (AAAI), vol. 33, 2019, pp. 8489–8496. ↩︎ ↩︎
R. Eloff, H. A. Engelbrecht, and H. Kamper, “Multimodal one-shot learning of speech and images,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2019, pp. 8623–8627. ↩︎ ↩︎
F. Pahde, M. Nabi, T. Klein, and P. Jahnichen, “Discriminative hallucination for multi-modal few-shot learning,” in Proc. IEEE Int. Conf. Image Process. (ICIP), 2018, pp. 156–160. ↩︎ ↩︎
F. Pahde, P. Jähnichen, T. Klein, and M. Nabi, “Cross-modal hallucination for few-shot fine-grained recognition,” arXiv preprint arXiv:1806.05147, 2018. ↩︎ ↩︎ ↩︎
Y.-H. H. Tsai and R. Salakhutdinov, “Improving one-shot learning through fusing side information,” arXiv preprint arXiv:1710.08347, 2017. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
M. P. Fortin and B. Chaib-draa, “Few-shot learning with contextual cueing for object recognition in complex scenes,” arXiv preprint arXiv:1912.06679, 2019. ↩︎ ↩︎ ↩︎
R. Vuorio, S.-H. Sun, H. Hu, and J. J. Lim, “Multimodal model-agnostic meta-learning via task-aware modulation,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 1–12. ↩︎ ↩︎
F. Pahde, O. Ostapenko, P. J. Hnichen, T. Klein, and M. Nabi, “Self-paced adversarial training for multimodal few-shot learning,” in Proc. IEEE Winter Conf. Applica. Comput. Vis. (WACV), 2019, pp. 218–226. ↩︎ ↩︎ ↩︎
A. Li, T. Luo, Z. Lu, T. Xiang, and L. Wang, “Large-scale few-shot learning: Knowledge transfer with class hierarchy,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 7212–7220. ↩︎ ↩︎
P. Tokmakov, Y.-X. Wang, and M. Hebert, “Learning compositional representations for few-shot recognition,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 6372–6381. ↩︎ ↩︎
K.-S. Fu and J. Mui, “A survey on image segmentation,” Pattern Recognit., vol. 13, no. 1, pp. 3–16, 1981. ↩︎
L. Liu, W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu, and M. Pietikäinen, “Deep learning for generic object detection: A survey,” Int. J. Comput. Vis., vol. 128, no. 2, pp. 261–318, 2020. ↩︎
D. Brezeale and D. J. Cook, “Automatic video classification: A survey of the literature,” IEEE Trans. on Sys., Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 3, pp. 416–430, 2008. ↩︎
Z. Shou, D. Wang, and S.-F. Chang, “Temporal action localization in untrimmed videos via multi-stage cnns,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 1049–1058. ↩︎
R. Yao, G. Lin, S. Xia, J. Zhao, and Y. Zhou, “Video object segmentation and tracking: A survey,” arXiv preprint arXiv:1904.09172, 2019. ↩︎
V. Korde and C. N. Mahender, “Text classification and classifiers: A survey,” Int. J. Artificial Intell. App., vol. 3, no. 2, p. 85, 2012. ↩︎
J. Camacho-Collados and M. T. Pilehvar, “From word to sense embeddings: A survey on vector representations of meaning,” J. Artificial Intell. Research, vol. 63, pp. 743–788, 2018. ↩︎
M. Nickel, K. Murphy, V. Tresp, and E. Gabrilovich, “A review of relational machine learning for knowledge graphs,” Proc. of the IEEE, vol. 104, no. 1, pp. 11–33, 2015. ↩︎
J. Kober, J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A survey,” Int. J. Robotics Research, vol. 32, no. 11, pp. 1238–1274, 2013. ↩︎
A. Hussein, M. M. Gaber, E. Elyan, and C. Jayne, “Imitation learning: A survey of learning methods,” ACM Computing Surveys, vol. 50, no. 2, pp. 1–35, 2017. ↩︎
F. Bonin-Font, A. Ortiz, and G. Oliver, “Visual navigation for mobile robots: A survey,” J. Intell. Robotic Syst., vol. 53, no. 3, p. 263, 2008. ↩︎
M. P. Deisenroth, G. Neumann, and J. Peters, A survey on policy search for robotics. now publishers, 2013. ↩︎
V. Chandola, A. Banerjee, and V. Kumar, “Anomaly detection: A survey,” ACM Computing Surveys, vol. 41, no. 3, pp. 1–58, 2009. ↩︎
X. Dong, L. Zhu, D. Zhang, Y. Yang, and F. Wu, “Fast parameter adaptation for few-shot image captioning and visual question answering,” in Proc. ACM Int. Conf. Multimedia (AMM), 2018, pp. 54–62. ↩︎ ↩︎ ↩︎ ↩︎
D. Teney and A. van den Hengel, “Visual question answering as a meta learning task,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 219–235. ↩︎ ↩︎
S. Yan, S. Zhang, X. He et al., “A dual attention network with semantic embedding for few-shot learning,” in Proc. AAAI Conf. Artificial Intell. (AAAI), vol. 33, 2019, pp. 9079–9086. ↩︎
A. Alfassy, L. Karlinsky, A. Aides, J. Shtok, S. Harary, R. Feris, R. Giryes, and A. M. Bronstein, “Laso: Label-set operations networks for multi-label few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 6548–6557. ↩︎ ↩︎
A. Ali-Gombe, E. Elyan, Y. Savoye, and C. Jayne, “Few-shot classifier gan,” in Proc. Int. Joint Conf. Neural Net. (IJCNN), 2018, pp. 1–8. ↩︎ ↩︎
F. Pahde, M. Puscas, J. Wolff, T. Klein, N. Sebe, and M. Nabi, “Lowshot learning from imaginary 3d model,” in Proc. IEEE Winter Conf. Applica. Comput. Vis. (WACV), 2019, pp. 978–985. ↩︎
X.-S. Wei, P. Wang, L. Liu, C. Shen, and J. Wu, “Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples,” IEEE Trans. Image Process., vol. 28, no. 12, pp. 6116–6125, 2019. ↩︎
H. Huang, J. Zhang, J. Zhang, J. Xu, and Q. Wu, “Low-rank pairwise alignment bilinear network for few-shot fine-grained image classification,” arXiv preprint arXiv:1908.01313, 2019. ↩︎
B. Liu, X. Yu, A. Yu, P. Zhang, G. Wan, and R. Wang, “Deep fewshot learning for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sensing, vol. 57, no. 4, pp. 2290–2304, 2018. ↩︎
C. Zhang, J. Yue, and Q. Qin, “Deep quadruplet network for hyperspectral image classification with a small number of samples,” Remote Sensing, vol. 12, no. 4, p. 647, 2020. ↩︎
A. Oliver, X. Lladó, A. Torrent, and J. Martí, “One-shot segmentation of breast, pectoral muscle, and background in digitised mammograms,” in Proc. IEEE Int. Conf. Image Process. (ICIP), 2014, pp. 912–916. ↩︎
A. Shaban, S. Bansal, Z. Liu, I. Essa, and B. Boots, “One-shot learning for semantic segmentation,” arXiv preprint arXiv:1709.03410, 2017. ↩︎
K. Rakelly, E. Shelhamer, T. Darrell, A. A. Efros, and S. Levine, “Few-shot segmentation propagation with guided networks,” arXiv preprint arXiv:1806.07373, 2018. ↩︎
N. Dong and E. Xing, “Few-shot semantic segmentation with prototype learning.” in Proc. British Mach. Vis. Conf. (BMVC), vol. 3, no. 4, 2018. ↩︎
X. Zhang, Y. Wei, Y. Yang, and T. Huang, “Sg-one: Similarity guidance network for one-shot semantic segmentation,” arXiv preprint arXiv:1810.09091, 2018. ↩︎
Z. Dong, R. Zhang, X. Shao, and H. Zhou, “Multi-scale discriminative location-aware network for few-shot semantic segmentation,” in Proc. IEEE Annu. Comput. Soft. App. Conf. (COMPSAC), vol. 2, 2019, pp. 42–47. ↩︎
M. Siam, B. N. Oreshkin, and M. Jagersand, “Amp: Adaptive masked proxies for few-shot segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 5249–5258. ↩︎
T. Hu, P. Yang, C. Zhang, G. Yu, Y. Mu, and C. G. Snoek, “Attentionbased multi-context guiding for few-shot semantic segmentation,” in Proc. AAAI Conf. Artificial Intell. (AAAI), vol. 33, 2019, pp. 8441– 8448. ↩︎
C. Zhang, G. Lin, F. Liu, R. Yao, and C. Shen, “Canet: Classagnostic segmentation networks with iterative refinement and attentive few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 5217–5226. ↩︎
C. Michaelis, M. Bethge, and A. Ecker, “One-shot segmentation in clutter,” in Proc. Int. Conf. Mach. Learn. (ICML), 2018, pp. 3549– 3558. ↩︎
A. K. Bhunia, A. K. Bhunia, S. Ghose, A. Das, P. P. Roy, and U. Pal, “A deep one-shot network for query-based logo retrieval,” Pattern Recognit., vol. 96, pp. 1–10, 2019. ↩︎
I. Ustyuzhaninov, C. Michaelis, W. Brendel, and M. Bethge, “Oneshot texture segmentation,” arXiv preprint arXiv:1807.02654, 2018. ↩︎
K. Zhu, W. Zhai, Z.-J. Zha, and Y. Cao, “One-shot texture retrieval with global context metric,” in Proc. Int. Joint Conf. Artificial Intell. (IJCAI), 2019, pp. 4461–4467. ↩︎
A. K. Mondal, J. Dolz, and C. Desrosiers, “Few-shot 3d multimodal medical image segmentation using generative adversarial learning,” arXiv preprint arXiv:1810.12241, 2018. ↩︎
A. Zhao, G. Balakrishnan, F. Durand, J. V. Guttag, and A. V. Dalca, “Data augmentation using learned transforms for one-shot medical image segmentation,” arXiv preprint arXiv:1902.09383, 2019. ↩︎
J. Dietlmeier, K. McGuinness, S. Rugonyi, T. Wilson, A. Nuttall, and N. E. O’Connor, “Few-shot hypercolumn-based mitochondria segmentation in cardiac and outer hair cells in focused ion beamscanning electron microscopy (fib-sem) data,” Pattern Recognit. Letters, vol. 128, pp. 521–528, 2019. ↩︎
A. G. Roy, S. Siddiqui, S. Pölsterl, N. Navab, and C. Wachinger, “'squeeze & excite’guided few-shot segmentation of volumetric images,” Medical Image Anal., vol. 59, pp. 1–12, 2020. ↩︎
X. Dong, L. Zheng, F. Ma, Y. Yang, and D. Meng, “Few-example object detection with model communication,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 7, pp. 1641–1654, 2018. ↩︎
J. Chen, Y. Liu, Y. Liu, S. Wang, and S. Chen, “A few-shot learning framework for air vehicle detection by similarity embedding,” in Proc. Int. Conf. Graphics Image Process. (ICGIP), 2019. ↩︎
Q. Fan, W. Zhuo, and Y.-W. Tai, “Few-shot object detection with attention-rpn and multi-relation detector,” arXiv preprint arXiv:1908.01998, 2019. ↩︎
L. Karlinsky, J. Shtok, S. Harary, E. Schwartz, A. Aides, R. Feris, R. Giryes, and A. M. Bronstein, “Repmet: Representative-based metric learning for classification and few-shot object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 5197–5206. ↩︎
B. Kang, Z. Liu, X. Wang, F. Yu, J. Feng, and T. Darrell, “Few-shot object detection via feature reweighting,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 8420–8429. ↩︎
J. Sun, Y. Zhu, and S. Jiang, “One-shot learning for rgb-d handheld object recognition,” in Proc. Int. Conf. Internet Multimedia Comput. Service, 2018, pp. 1–6. ↩︎
S. Benaim and L. Wolf, “One-shot unsupervised cross domain translation,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 2104–2114. ↩︎
L. Clouâtre and M. Demers, “Figr: Few-shot image generation with reptile,” arXiv preprint arXiv:1901.02199, 2019. ↩︎
M.-Y. Liu, X. Huang, A. Mallya, T. Karras, T. Aila, J. Lehtinen, and J. Kautz, “Few-shot unsupervised image-to-image translation,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 10 551–10 560. ↩︎
Y. Gao, Y. Guo, Z. Lian, Y. Tang, and J. Xiao, “Artistic glyph image synthesis via one-stage few-shot learning,” ACM Trans. Graphics, vol. 38, no. 6, pp. 1–12, 2019. ↩︎
Y. Hong, J. Zhang, L. Niu, and L. Zhang, “Matchinggan: Matchingbased few-shot image generation,” arXiv preprint arXiv:2003.03497, 2020. ↩︎
Y.-X. Wang, L. Gui, and M. Hebert, “Few-shot hash learning for image retrieval,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV) Workshop, 2017, pp. 1228–1237. ↩︎
Y. Yu, G. Liu, and J.-M. Odobez, “Improving few-shot user-specific gaze adaptation via gaze redirection synthesis,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 11 937–11 946. ↩︎
S. Li, J. Shi, W. Song, A. Hao, and H. Qin, “Few-shot learning for monocular depth estimation based on local object relationship,” in Proc. IEEE Int. Conf. Tools Artificial Intell. (ICTAI), 2019, pp. 1221–1228. ↩︎
D. Wertheimer and B. Hariharan, “Few-shot learning with localization in realistic settings,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 6558–6567. ↩︎
A. Dornadula, A. Narcomey, R. Krishna, M. Bernstein, and F.-F. Li, “Visual relationships as functions: Enabling few-shot scene graph prediction,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV) Workshop, 2019. ↩︎
L. Xiang, X. Jin, G. Ding, J. Han, and L. Li, “Incremental fewshot learning for pedestrian attribute recognition,” arXiv preprint arXiv:1906.00330, 2019. ↩︎
T. Xu, J. Li, H. Wu, H. Yang, X. Gu, and Y. Chen, “Feature space regularization for person re-identification with one sample,” in Proc. IEEE Int. Conf. Tools Artificial Intell. (ICTAI), 2019, pp. 1463– 1470. ↩︎
S. Yoo, H. Bahng, S. Chung, J. Lee, J. Chang, and J. Choo, “Coloring with limited data: Few-shot colorization via memory augmented networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 11 283–11 292. ↩︎
S. McDonagh, S. Parisot, F. Zhou, X. Zhang, A. Leonardis, Z. Li, and G. Slabaugh, “Formulating camera-adaptive color constancy as a few-shot meta-learning problem,” arXiv, pp. arXiv–1811, 2018. ↩︎
S. Khodadadeh, L. Bölöni, and M. Shah, “Unsupervised metalearning for few-shot image and video classification,” arXiv preprint arXiv:1811.11819, 2018. ↩︎
K. Cao, J. Ji, Z. Cao, C.-Y. Chang, and J. C. Niebles, “Fewshot video classification via temporal alignment,” arXiv preprint arXiv:1906.11415, 2019. ↩︎
X. Li, S. Qin, K. Xu, and Z. Hu, “One-shot learning gesture recognition based on evolution of discrimination with successive memory,” in Proc. IEEE Int. Conf. Intell. Robotic Control Eng. (IRCE), 2018, pp. 263–269. ↩︎
Z. Lu, S. Qin, X. Li, L. Li, and D. Zhang, “One-shot learning hand gesture recognition based on modified 3d convolutional neural networks,” Mach. Vis. App., vol. 30, no. 7-8, pp. 1157–1180, 2019. ↩︎
A. Mishra, V. K. Verma, M. S. K. Reddy, S. Arulkumar, P. Rai, and A. Mittal, “A generative approach to zero-shot and few-shot action recognition,” in Proc. IEEE Winter Conf. Applica. Comput. Vis. (WACV), 2018, pp. 372–380. ↩︎
B. Xu, H. Ye, Y. Zheng, H. Wang, T. Luwang, and Y.-G. Jiang, “Dense dilated network for few shot action recognition,” in Proc. ACM Int. Conf. Multimedia Retrieval, 2018, pp. 379–387. ↩︎
M. Bishay, G. Zoumpourlis, and I. Patras, “Tarn: Temporal attentive relation network for few-shot and zero-shot action recognition,” arXiv preprint arXiv:1907.09021, 2019. ↩︎
S. K. Dwivedi, V. Gupta, R. Mitra, S. Ahmed, and A. Jain, “Protogan: Towards few shot learning for action recognition,” arXiv preprint arXiv:1909.07945, 2019. ↩︎
H. Coskun, Z. Zia, B. Tekin, F. Bogo, N. Navab, F. Tombari, and H. Sawhney, “Domain-specific priors and meta learning for low-shot first-person action recognition,” arXiv preprint arXiv:1907.09382, 2019. ↩︎
R. Memmesheimer, N. Theisen, and D. Paulus, “Signal level deep metric learning for multimodal one-shot action recognition,” arXiv preprint arXiv:2004.11085, 2020. ↩︎
H. Yang, X. He, and F. Porikli, “One-shot action localization by learning sequence matching network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 1450–1459. ↩︎
W. Goo and S. Niekum, “One-shot learning of multi-step tasks from observation via activity localization in auxiliary video,” in Proc. Int. Conf. Robotics Auto. (ICRA), 2019, pp. 7755–7761. ↩︎
H. Xu, B. Kang, X. Sun, J. Feng, K. Saenko, and T. Darrell, “Similarity r-c3d for few-shot temporal activity detection,” arXiv preprint arXiv:1812.10000, 2018. ↩︎
L.-Y. Gui, Y.-X. Wang, D. Ramanan, and J. M. Moura, “Few-shot human motion prediction via meta-learning,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 432–450. ↩︎
S. Caelles, K.-K. Maninis, J. Pont-Tuset, L. Leal-Taixé, D. Cremers, and L. Van Gool, “One-shot video object segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 221– 230. ↩︎
H. Xiao, B. Kang, Y. Liu, M. Zhang, and J. Feng, “Online meta adaptation for fast video object segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., 2019. ↩︎
N. Inoue and K. Shinoda, “Few-shot adaptation for multimedia semantic indexing,” in Proc. ACM Int. Conf. Multimedia (AMM), 2018, pp. 1110–1118. ↩︎
J. Lee, D. Ramanan, and R. Girdhar, “Metapix: Few-shot video retargeting,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2020. ↩︎
E. Zakharov, A. Shysheya, E. Burkov, and V. Lempitsky, “Few-shot adversarial learning of realistic neural talking head models,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 9459–9468. ↩︎
L. Wu, Y. Wang, H. Yin, M. Wang, and L. Shao, “Few-shot deep adversarial learning for video-based person re-identification,” IEEE Trans. Image Process., vol. 29, pp. 1233–1245, 2019. ↩︎
E. Park and A. C. Berg, “Meta-tracker: Fast and robust online adaptation for visual object trackers,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 569–585. ↩︎
I. Mason, S. Starke, H. Zhang, H. Bilen, and T. Komura, “Few-shot learning of homogeneous human locomotion styles,” in Comput. Graphics Forum, vol. 37, no. 7, 2018, pp. 143–153. ↩︎
L. Yan, Y. Zheng, and J. Cao, “Few-shot learning for short text classification,” Multimedia Tools App., vol. 77, no. 22, pp. 29 799– 29 810, 2018. ↩︎
M. Yu, X. Guo, J. Yi, S. Chang, S. Potdar, Y. Cheng, G. Tesauro, H. Wang, and B. Zhou, “Diverse few-shot text classification with multiple metrics,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2018, pp. 1206–1215. ↩︎
W. Liu, X. Chang, Y. Yan, Y. Yang, and A. G. Hauptmann, “Fewshot text and image classification via analogical transfer learning,” ACM Trans. Intell. Syst. Tech. (TIST), vol. 9, no. 6, pp. 1–20, 2018. ↩︎
X. Jiang, M. Havaei, G. Chartrand, H. Chouaib, T. Vincent, A. Jesson, N. Chapados, and S. Matwin, “On the importance of attention in meta-learning for few-shot text classification,” arXiv preprint arXiv:1806.00852, 2018. ↩︎
A. Rios and R. Kavuluru, “Few-shot and zero-shot multi-label learning for structured label spaces,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), vol. 2018, 2018, p. 3132. ↩︎
K. Bailey and S. Chopra, “Few-shot text classification with pretrained word embeddings and a human in the loop,” arXiv preprint arXiv:1804.02063, 2018. ↩︎
Y. Bao, M. Wu, S. Chang, and R. Barzilay, “Few-shot text classification with distributional signatures,” arXiv preprint arXiv:1908.06039, 2019. ↩︎
N. Zhang, Z. Sun, S. Deng, J. Chen, and H. Chen, “Improving fewshot text classification via pretrained language representations,” arXiv preprint arXiv:1908.08788, 2019. ↩︎
R. Geng, B. Li, Y. Li, X. Zhu, P. Jian, and J. Sun, “Induction networks for few-shot text classification,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2019, pp. 3895–3904. ↩︎
S. Sun, Q. Sun, K. Zhou, and T. Lv, “Hierarchical attention prototypical networks for few-shot text classification,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2019, pp. 476–485. ↩︎
C. Pan, J. Huang, J. Gong, and X. Yuan, “Few-shot transfer learning for text classification with lightweight word embedding based models,” IEEE Access, vol. 7, pp. 53 296–53 304, 2019. ↩︎
T. Schick and H. Schütze, “Exploiting cloze questions for few-shot text classification and natural language inference,” arXiv preprint arXiv:2001.07676, 2020. ↩︎
V. Vlasov, A. Drissner-Schmid, and A. Nichol, “Few-shot generalization across dialogue tasks,” arXiv preprint arXiv:1811.11707, 2018. ↩︎
A. Madotto, Z. Lin, C.-S. Wu, and P. Fung, “Personalizing dialogue agents via meta-learning,” in Proc. Annu. Meet. Assoc. Computational Linguistics (ACL), 2019, pp. 5454–5459. ↩︎
K. Qian and Z. Yu, “Domain adaptive dialog generation via meta learning,” in Proc. Annu. Meet. Assoc. Computational Linguistics (ACL), 2019, pp. 2639–2649. ↩︎
X. Han, H. Zhu, P. Yu, Z. Wang, Y. Yao, Z. Liu, and M. Sun, “Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2018, pp. 4803–4809. ↩︎
W. Xiong, M. Yu, S. Chang, X. Guo, and W. Y. Wang, “One-shot relational learning for knowledge graphs,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2018, pp. 1980–1990. ↩︎
C. Zhang, H. Yao, C. Huang, M. Jiang, Z. Li, and N. V. Chawla, “Few-shot knowledge graph completion,” arXiv preprint arXiv:1911.11298, 2019. ↩︎
Z.-X. Ye and Z.-H. Ling, “Multi-level matching and aggregation network for few-shot relation classification,” in Proc. Annu. Meet. Assoc. Computational Linguistics (ACL), 2019, pp. 2872–2881. ↩︎
M. Chen, W. Zhang, W. Zhang, Q. Chen, and H. Chen, “Meta relational learning for few-shot link prediction in knowledge graphs,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2019, pp. 4208–4217. ↩︎
A. K. Lampinen and J. L. McClelland, “One-shot and few-shot learning of word embeddings,” arXiv preprint arXiv:1710.10280, 2017. ↩︎
C. Li, G. Wang, and G. De Melo, “Context-based few-shot word representation learning,” in Proc. IEEE Int. Conf. Semantic Computing (ICSC), 2018, pp. 239–242. ↩︎
J. Sun, S. Wang, and C. Zong, “Memory, show the way: Memory based few shot word representation learning,” in Proc. Conf. Empirical Methods Nat. Language Process. (EMNLP), 2018, pp. 1435– 1444. ↩︎
Q. Liu, D. McCarthy, and A. Korhonen, “Second-order contexts from lexical substitutes for few-shot learning of word representations,” in Proc. Joint Conf. on Lexical and Computational Semantics, 2019, pp. 61–67. ↩︎
Z. Hu, T. Chen, K.-W. Chang, and Y. Sun, “Few-shot representation learning for out-of-vocabulary words,” arXiv preprint arXiv:1907.00505, 2019. ↩︎
M. Hofer, A. Kormilitzin, P. Goldberg, and A. Nevado-Holgado, “Few-shot learning for named entity recognition in medical text,” arXiv preprint arXiv:1811.05468, 2018. ↩︎
A. Fritzler, V. Logacheva, and M. Kretov, “Few-shot classification in named entity recognition task,” in Proc. ACM/SIGAPP Symposium on Applied Computing, 2019, pp. 993–1000. ↩︎
O. U. Florez and E. Mueller, “Learning to control latent representations for few-shot learning of named entities,” arXiv preprint arXiv:1911.08542, 2019. ↩︎
Z. Chen, H. Eavani, W. Chen, Y. Liu, and W. Y. Wang, “Fewshot nlg with pre-trained language model,” arXiv preprint arXiv:1904.09521, 2019. ↩︎
F. Mi, M. Huang, J. Zhang, and B. Faltings, “Meta-learning for lowresource natural language generation in task-oriented dialogue systems,” in Proc. Int. Joint Conf. Artificial Intell. (IJCAI). AAAI Press, 2019, pp. 3151–3157. ↩︎
B. Peng, C. Zhu, C. Li, X. Li, J. Li, M. Zeng, and J. Gao, “Fewshot natural language generation for task-oriented dialog,” arXiv preprint arXiv:2002.12328, 2020. ↩︎
M. Kale and A. Rastogi, “Few-shot natural language generation by rewriting templates,” arXiv preprint arXiv:2004.15006, 2020. ↩︎
Y. Hou, Z. Zhou, Y. Liu, N. Wang, W. Che, H. Liu, and T. Liu, “Fewshot sequence labeling with label dependency transfer,” arXiv preprint arXiv:1906.08711, 2019. ↩︎
B. Lake, C.-y. Lee, J. Glass, and J. Tenenbaum, “One-shot learning of generative speech concepts,” in Proc. Annu. Meet. Cogni. Sci. Soc. (CogSci), vol. 36, no. 36, 2014. ↩︎ ↩︎
J. Pons, J. Serrà, and X. Serra, “Training neural audio classifiers with few data,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2019, pp. 16–20. ↩︎
S. Zhang, Y. Qin, K. Sun, and Y. Lin, “Few-shot audio classification with attentional graph neural networks,” Proc. Interspeech, pp. 3649–3653, 2019. ↩︎
K.-H. Cheng, S.-Y. Chou, and Y.-H. Yang, “Multi-label few-shot learning for sound event recognition,” in Proc. IEEE Int. Workshop on Multimedia Sig. Process. (MMSP), 2019, pp. 1–5. ↩︎
S.-Y. Chou, K.-H. Cheng, J.-S. R. Jang, and Y.-H. Yang, “Learning to match transient sound events using attentional similarity for few-shot sound recognition,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2019, pp. 26–30. ↩︎
J. Naranjo-Alcazar, S. Perez-Castanos, P. Zuccarrello, and M. Cobos, “An open-set recognition and few-shot learning dataset for audio event classification in domestic environments,” arXiv preprint arXiv:2002.11561, 2020. ↩︎
Y. Chen, Y. Assael, B. Shillingford, D. Budden, S. Reed, H. Zen, Q. Wang, L. C. Cobo, A. Trask, B. Laurie et al., “Sample efficient adaptive text-to-speech,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2019. ↩︎
H. B. Moss, V. Aggarwal, N. Prateek, J. González, and R. BarraChicote, “Boffin tts: Few-shot speaker adaptation by bayesian optimization,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2020, pp. 7639–7643. ↩︎
Z. Zhang, Q. Tian, H. Lu, L.-H. Chen, and S. Liu, “Adadurian: Few-shot adaptation for neural text-to-speech with durian,” arXiv preprint arXiv:2005.05642, 2020. ↩︎
S. Choi, S. Han, D. Kim, and S. Ha, “Attentron: Few-shot textto-speech utilizing attention-based variable-length embedding,” arXiv preprint arXiv:2005.08484, 2020. ↩︎
Y. Wang, J. Salamon, N. J. Bryan, and J. P. Bello, “Few-shot sound event detection,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2020, pp. 81–85. ↩︎
K. Shimada, Y. Koyama, and A. Inoue, “Metric learning with background noise class for few-shot detection of rare sound events,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2020, pp. 616–620. ↩︎
B. Shi, M. Sun, K. C. Puvvada, C.-C. Kao, S. Matsoukas, and C. Wang, “Few-shot acoustic event detection via meta learning,” in Proc. IEEE Int. Conf. Acoustics Speech Sig. Process. (ICASSP), 2020, pp. 76–80. ↩︎
S. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou, “Neural voice cloning with a few samples,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 10 019–10 029. ↩︎
B. Higy and P. Bell, “Few-shot learning with attention-based sequence-to-sequence models,” arXiv preprint arXiv:1811.03519, 2018. ↩︎
H. Seth, P. Kumar, and M. M. Srivastava, “Prototypical metric transfer learning for continuous speech keyword spotting with limited training data,” in Proc. Int. Workshop Soft Computing Models Industrial Environmental App., 2019, pp. 273–280. ↩︎
D. Droghini, F. Vesperini, E. Principi, S. Squartini, and F. Piazza, “Few-shot siamese neural networks employing audio features for human-fall detection,” in Proc. Int. Conf. Pattern Recognit. Artificial Intell., 2018, pp. 63–69. ↩︎
P. Anand, A. K. Singh, S. Srivastava, and B. Lall, “Few shot speaker recognition using deep neural networks,” arXiv preprint arXiv:1904.08775, 2019. ↩︎
Y. Duan, M. Andrychowicz, B. Stadie, O. J. Ho, J. Schneider, I. Sutskever, P. Abbeel, and W. Zaremba, “One-shot imitation learning,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), 2017, pp. 1087–1098. ↩︎
C. Finn, T. Yu, T. Zhang, P. Abbeel, and S. Levine, “One-shot visual imitation learning via meta-learning,” in Proc. Conf. on Robot Learn., 2017, pp. 357–368. ↩︎
T. Yu, C. Finn, A. Xie, S. Dasari, T. Zhang, P. Abbeel, and S. Levine, “One-shot imitation from observing humans via domain-adaptive meta-learning,” arXiv preprint arXiv:1802.01557, 2018. ↩︎
T. Yu, P. Abbeel, S. Levine, and C. Finn, “One-shot hierarchical imitation learning of compound visuomotor tasks,” arXiv preprint arXiv:1810.11043, 2018. ↩︎
Y. Aytar, T. Pfaff, D. Budden, T. Paine, Z. Wang, and N. de Freitas, “Playing hard exploration games by watching youtube,” in Proc. Advances Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 2930–2941. ↩︎
S. James, M. Bloesch, and A. J. Davison, “Task-embedded control networks for few-shot imitation learning,” arXiv preprint arXiv:1810.03237, 2018. ↩︎
D.-A. Huang, D. Xu, Y. Zhu, A. Garg, S. Savarese, L. Fei-Fei, and J. C. Niebles, “Continuous relaxation of symbolic planner for one-shot imitation learning,” arXiv preprint arXiv:1908.06769, 2019. ↩︎
Q. Shao, J. Qi, J. Ma, Y. Fang, W. Wang, and J. Hu, “Object detection-based one-shot imitation learning with an rgb-d camera,” Applied Sci., vol. 10, no. 3, p. 803, 2020. ↩︎
A. Bonardi, S. James, and A. J. Davison, “Learning one-shot imitation from humans without humans,” IEEE Robotics Auto. Letters, vol. 5, no. 2, pp. 3533–3539, 2020. ↩︎
A. Xie, A. Singh, S. Levine, and C. Finn, “Few-shot goal inference for visuomotor learning and planning,” in Proc. Conf. on Robot Learn., 2018, pp. 40–52. ↩︎
D. Xu, S. Nair, Y. Zhu, J. Gao, A. Garg, L. Fei-Fei, and S. Savarese, “Neural task programming: Learning to generalize across hierarchical tasks,” in Proc. Int. Conf. Robotics Auto. (ICRA), 2018, pp. 1–8. ↩︎
V. Prabhu, A. Kannan, M. Ravuri, M. Chaplain, D. Sontag, and X. Amatriain, “Few-shot learning for dermatological disease diagnosis,” in Mach. Learn. Healthcare Conf., 2019, pp. 532–552. ↩︎
A. Paul, Y.-X. Tang, and R. M. Summers, “Fast few-shot transfer learning for disease identification from chest x-ray images using autoencoder ensemble,” in Medical Imaging 2020: Computer-Aided Diagnosis, 2020. ↩︎
W. Zhu, H. Liao, W. Li, W. Li, and J. Luo, “Alleviating the incompatibility between cross entropy loss and episode training for fewshot skin disease classification,” arXiv preprint arXiv:2004.09694, 2020. ↩︎
D. Rajan, J. J. Thiagarajan, A. Karargyris, and S. Kashyap, “Selftraining with improved regularization for few-shot chest x-ray classification,” arXiv preprint arXiv:2005.02231, 2020. ↩︎
S. Ali, B. Bhattaria, T.-K. Kim, and J. Rittscher, “Additive angular margin for few shot learning to classify clinical endoscopy images,” arXiv preprint arXiv:2003.10033, 2020. ↩︎
C. Li, D. Zhang, Z. Tian, S. Du, and Y. Qu, “Few-shot learning with deformable convolution for multiscale lesion detection in mammography,” Medical Physics, 2020. ↩︎
X. Du, D. Zhong, and P. Li, “Low-shot palmprint recognition based on meta-siamese network,” in Proc. IEEE Int. Conf. Multimedia Expo (ICME), 2019, pp. 79–84. ↩︎
H. Altae-Tran, B. Ramsundar, A. S. Pappu, and V. Pande, “Low data drug discovery with one-shot learning,” ACS Central Sci., vol. 3, no. 4, pp. 283–293, 2017. ↩︎
J. Liu, S. J. Gibson, J. Mills, and M. Osadchy, “Dynamic spectrum matching with one-shot learning,” Chemometrics Intell. Laboratory Syst., vol. 184, pp. 175–181, 2019. ↩︎
Y. Li and J. Yang, “Few-shot cotton pest recognition and terminal realization,” Computers and Electronics in Agriculture, vol. 169, pp. 1–9, 2020. ↩︎
M. M. U. Chowdhury, F. Hammond, G. Konowicz, C. Xin, H. Wu, and J. Li, “A few-shot deep learning approach for improved intrusion detection,” in Proc. IEEE Annu. Ubiquitous Computing, Electronics and Mobile Communication Conf. (UEMCON), 2017, pp. 456–462. ↩︎
T. Gong, Y. Kim, J. Shin, and S.-J. Lee, “Metasense: few-shot adaptation to untrained conditions in deep mobile sensing,” in Proc. Conf. Embedded Networked Sensor Syst., 2019, pp. 110–123. ↩︎
J. Lu, S. Jin, J. Liang, and C. Zhang, “Robust few-shot learning for user-provided data,” IEEE Trans. Neural Net. Learn. Syst., 2020. ↩︎
Y.-J. Park and A. Tuzhilin, “The long tail of recommender systems and how to leverage it,” in Proc. ACM Conf. Recommender Syst., 2008, pp. 11–18. ↩︎
D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba, “Network dissection: Quantifying interpretability of deep visual representations,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 6541–6549. ↩︎
Q.-s. Zhang and S.-C. Zhu, “Visual interpretability for deep learning: a survey,” Frontiers Infor. Tech. Electronic Eng., vol. 19, no. 1, pp. 27–39, 2018. ↩︎
J. Lu, L. Li, and C. Zhang, “Self-reinforcing unsupervised matching,” arXiv preprint arXiv:1909.04138, 2019. ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









