








基于伪标签的实际半监督元训练在少样本学习中的应用
引用:Dong X, Ouyang T, Liao S, et al. Pseudo-labeling based practical semi-supervised meta-training for few-shot learning[J]. IEEE Transactions on Image Processing, 2024.
论文地址:下载地址
github:https://github.com/ouyangtianran/PLML
Abstract
大多数现有的少样本学习(FSL)方法在元训练过程中需要大量的标注数据,这是一个主要的限制。为了减少对标注数据的需求,提出了一种半监督元训练(SSMT)设置,其中包括少量的标注样本和基类中的大量未标注样本。然而,现有方法在该设置下需要从未标注集中进行类感知样本选择,这违反了未标注集的假设。本文提出了一种实际的半监督元训练设置,使用真正未标注的数据,以促进少样本学习在现实场景中的应用。为了更好地利用标注和真正未标注的数据,我们提出了一个简单有效的元训练框架,称为基于伪标签的元学习(PLML)。首先,我们通过常见的半监督学习(SSL)训练一个分类器,并使用该分类器获得未标注数据的伪标签。然后,我们从标注数据和伪标注数据中构建少样本任务,并设计了一种新颖的微调方法,结合特征平滑和噪声抑制,以便更好地从噪声标签中学习FSL模型。令人惊讶的是,通过在两个FSL数据集上的大量实验,我们发现这个简单的元训练框架有效地防止了在有限标注数据下各种FSL模型的性能退化,并且显著超越了代表性的SSMT模型。此外,得益于元训练,我们的方法还提升了几种代表性的SSL算法。我们提供了训练代码和使用示例,网址:https://github.com/ouyangtianran/PLML。
1. INTRODUCTION
最近,研究人员越来越关注少样本学习(FSL),该方法旨在通过仅从每个类别中的一个或少量示例(支持集)进行学习,来识别新颖(未见过的)物体,同时探索并积累相关技术 1,2。现有的FSL方法根据推理方式分为三类:
(i) 传统的归纳FSL方法 3,4(IFSL)在推理过程中不使用额外的信息,并且逐个评估测试数据;
(ii) 少样本学习的传导推理 5(TFSL)6,7,8 假设我们可以利用所有测试数据来学习模型进行推理;
(iii) 半监督FSL(SSFSL)9,10,11,12,8,13 假设我们可以为推理过程提供额外的未标注数据。
限制 1:对基础数据集的大量标注数据的依赖
尽管这些方法在少量标签的情况下能在新类别上取得令人印象深刻的表现,但大多数FSL方法仍然需要在一个与目标数据集不同但相关的基础数据集上预训练它们的模型,尤其是对于SSFSL方法。具体来说,IFSL和TFSL方法假设它们可以访问大量的基础数据集中的标注样本进行训练。基于迁移学习的SSFSL方法 14,8 也使用基础数据集中的所有标签进行预训练,并在新数据集上使用半监督推理。为了研究限制 1 的影响,我们减少标注数据的数量,并对三种代表性的FSL模型进行重新训练,这些模型有不同的推理方式(归纳式Proto 4、传导式T-EP和半监督S-EP 8),这些方法在元训练时需要完整的标签。正如图1所示,它们在标签减少的情况下出现了明显的性能退化。这表明,大多数FSL方法仍然在很大程度上依赖大量标注数据,这也是昂贵数据标注(如医疗数据)应用中的一个主要限制。

*** 图 1:在少样本学习(FSL)中标签减少引起的性能下降示意图。横轴和纵轴分别表示每个类别的标签数和在 miniImageNet [30] 上的准确率。我们展示了在使用不同数量的训练标签进行各种任务时,三种代表性少样本学习(FSL)模型(归纳式 Proto (a)、传递式 TEP [32] (b) 和半监督 S-EP [32] ©)的性能下降。"Full"表示使用完全标注的数据进行训练,而"PLML"则表示结合了我们的伪标签元学习方法。在 (d) 中,我们比较了两个模型:SPN [31] 和 MPL [17],在原始设置和我们的新设置(-N)下的表现。**
与基于迁移学习的SSFSL方法 14,8 仅在新数据集上使用半监督推理不同,基于元训练的SSFSL方法将基础数据集分为标注集和未标注集,并设计新的元学习方法以减少对标注数据的需求并充分利用未标注数据。如图1d所示,我们评估了两个代表性模型:SPN 12 和 M-PL 10,并使用不同数量的标注数据。我们观察到,当标注数据减少时,评估得分仍然急剧下降,尤其是在每类的标签数量极少(例如20)时。此外,基于元训练的SSFSL模型与基于迁移学习的SSFSL方法在相同有限条件下存在较大的准确度差距(例如图1d中的M-PL与图1c中的S-EP对比)。
限制 2:基于元训练的SSFSL模型中的类别优先选择策略
现有的基于元训练的SSFSL模型 10,12 需要在训练过程中使用类别优先选择策略,而该策略不适用于真正的未标注数据。如图2所示,在任务构造过程中,基于元训练的SSFSL模型首先从标注集和未标注集中选择M个类别,然后从这些类别中随机挑选若干样本来构建任务。为了确保选择的未标注样本来自这些M个类别,实际上需要知道未标注集中的所有样本标签,这违背了未标注集的基本原则。这个策略对于SSFSL是否必要?我们能否去除它?这些仍然是未被探讨的问题。
新设定
为了克服限制 2,我们提出了一种新的实用半监督元训练设定用于少样本学习(FSL)。如图2所示,我们的实用任务只需要从标注集中选择M个类别,并使用任何不基于类别优先的选择策略来挑选未标注样本。具体来说,基础数据集被分为标注集和未标注集,我们禁止对未标注集使用类别优先选择策略,以确保我们无法访问未标注数据的真实标签。对于新数据集,我们采用先前工作中的相同推理方式,以关注标注数据数量的影响。
因此,我们在新设定下重新训练了SPN和M-PL模型,并用不同数量的标签进行实验,分别记为SPN-N和M-PL-N。如图1d所示,SPN-N的性能明显下降,而M-PL-N的准确率轻微下降。这表明不同的模型对类别优先选择策略有不同的敏感性。换句话说,我们不能仅仅根据它们在原始设定下的表现来推断它们在更实用的新设定中的表现。因此,我们使用新的设定进行实验评估,以设计更实用的FSL方法。
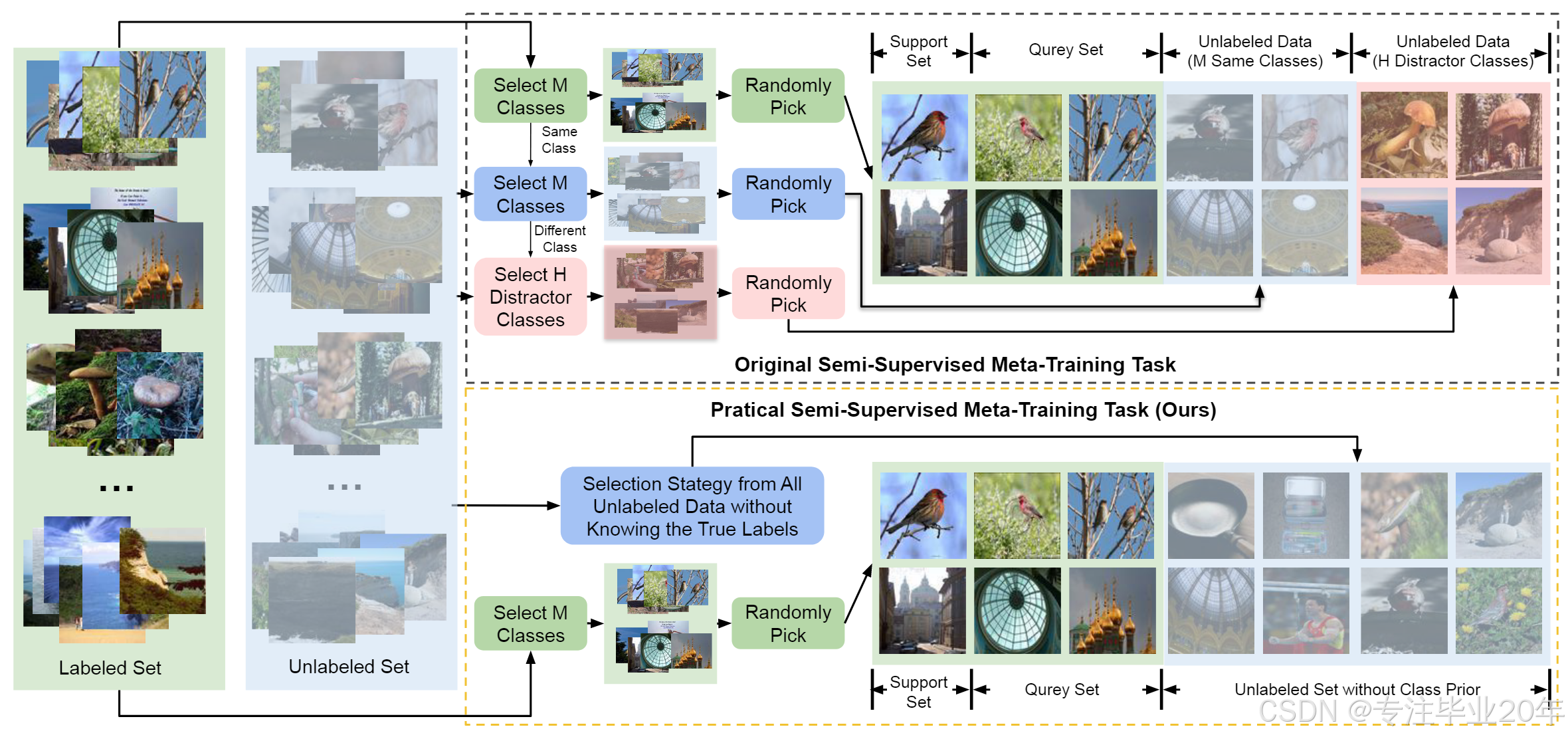
图 2:现有的半监督元训练任务 12(黑框)与提议的任务(黄框)对比。绿色和蓝色框分别表示标注数据和未标注数据。
两阶段元训练框架
为了克服前述限制,我们提出了一种两阶段的元训练框架,称为基于伪标签的元学习(PLML),以充分利用未标注数据。在第一阶段,我们通过半监督学习方法在标注集和未标注集上预训练一个基础分类器。在第二阶段,预训练的分类器首先生成未标注数据的伪标签。然后,我们从标注数据和伪标签数据中构建 episodic 任务,并提出了一种新的微调方法,结合特征平滑和噪声抑制,训练FSL模型,处理包含噪声标签的任务。我们还在第二学习阶段对基础分类器进行微调,探索元学习对半监督分类的影响。
我们的核心思想是将半监督学习(SSL)与基于元学习的半监督少样本学习(SSFSL)相结合,以缓解由于基础数据集标注数据减少而导致的性能下降,同时避免在任务构建中使用不切实际的类别优先选择策略。我们通过两种代表性的元学习算法实例化我们的PLML:Proto 15(IFSL)和EP 8(TFSL和SSFSL),并与近期的半监督学习(SSL)方法进行比较,包括SemCo 16、FlexMatch 17和MarginMatch 18。我们在两个标准基准上进行广泛实验:miniImageNet 19 和 tieredImageNet 12。结果表明,我们的简单元训练框架能够显著缓解由于标签减少导致的现有FSL模型的性能下降,并缩小元训练和基于迁移学习的SSFSL方法之间的巨大差距。如图1c和1d所示,我们基于Semco的S-EP-PLML模型,在每个类别仅使用20个标签样本进行训练,在miniImageNet的5-way 5-shot任务中,取得了69.19%的准确率,相比原始模型(S-EP)和最先进的(SOTA)基于元训练的模型(M-PL-N),分别提高了13.55%和15.41%。值得注意的是,我们发现我们的元学习阶段可以进一步提高近期SSL模型的性能,这表明将元学习与SSL结合可能是开发新SSL方法的一个新方向。
总结
我们的主要贡献包括:
- 我们提出了一个更实用的半监督元训练设定用于FSL,作为一个平台,促进使用少量标注的基础数据来训练FSL模型的研究。这是首次尝试研究并去除SSFSL中的类别优先选择策略。
- 我们提出了一种简单有效的半监督训练算法,命名为基于伪标签的元学习,旨在减少大多数FSL模型对标注基础数据的依赖。我们的方法是首个将半监督预训练方法引入元训练的SSFSL工作。
- 我们发现我们的元学习策略可以进一步提高近期SSL模型的性能,这表明使用元训练可能是开发新SSL方法的一个有前景的方向。
- 我们的方法是模型无关的,并成功将SSL集成到FSL中。我们显著提高了FSL模型(EP和Proto)在有限标注基础数据下的性能。
2. RELATED WORK
2.1. Few-Shot Learning (FSL)
Inductive. 通常,归纳方法基于元学习,可以分为模型、优化和度量三类算法。第一类通过记忆模型(如递归神经网络和记忆增强网络)来提取元知识19,20。第二类旨在学习生成模型的初始化,以便快速适应新任务21 3 22 23 24 25。最后一类则试图学习强大的表示,以区分新的类别26 8 4 27。最近,基于迁移学习的方法28 29 30利用整个训练集来学习强大的表示,而不是进行情节化训练。
Transductive. 常见的方法通过平滑嵌入来结合标签传播6或嵌入传播8。一些研究者专注于如何更好地利用未标记数据,例如子空间31、最优传输32和交叉注意力33。最近,准确的原型估计引起了关注。例如,34引入了一种基于原型补全的元学习框架,而35提出了一种基于原型的标签传播方法。
Semi-Supervised. 现有方法大致分为两类。1) 基于元训练:开创性工作12提出了一种自适应原型网络,用于利用未标记数据。随后的工作介绍了标签传播6和伪标签11。TACO13为未标记数据添加了任务级平滑约束,从而平滑了元模型空间。最近,模型无关元学习3扩展到了SSFSL,通过从未标记数据中选择可靠的训练子集10。2) 基于迁移学习:这些方法9 14 8 36 37因其高准确度而吸引了大量关注。然而,它们需要大量的基础标签,这限制了其在实际场景中的应用。如前所述,大多数FSL模型严重依赖大量的训练标签。本文旨在设计一种新框架,以便在使用更少标签的情况下促进FSL训练。
2.2. Semi-Supervised Learning (SSL)
自开创性工作 II-Model 38 以来,伪标签和一致性正则化技术在SSL社区中引起了广泛关注,并催生了多种算法39 40 41 42。最近提出的模型43 44 16 45 18 46 17结合了这两种技术,通过使用无监督数据增强46。其主要思想是使用弱增强图像的预测作为伪标签,然后强制其与强增强图像的预测一致。例如,UDA46和ReMixMatch43应用基于置信度的策略和锐化的软伪标签来选择足够有信心的数据进行训练,而FixMatch45使用一热硬标签。最近,SemCo16通过引入来自语言模型的语义先验知识47成功地补充了FixMatch。FlexMatch17应用课程学习设计了一个动态阈值函数,并根据学习状态选择高置信度的伪标签。MarginMatch18利用基于边界的策略选择高置信度的伪标签。我们采用了三种SSL算法:SemCo、FlexMatch和MarginMatch进行预训练,并研究了元训练对SSL模型的影响。
3. 实际的半监督元训练
3.1. 小样本学习(FSL)
FSL数据集通常分为基础集和新类别集,这两者之间没有重叠的类别。第一个用于训练FSL模型,后者则用于评估FSL模型对新对象的识别能力。形式上,我们将基础集表示为 D base = { x i , y i } i = 1 N b D_{\text{base}} = \{x_i, y_i\}_{i=1}^{N_b} Dbase={xi,yi}i=1Nb,其中 x i ∈ R D x_i \in \mathbb{R}^D xi∈RD 是样本(图像), y i ∈ Y b = ( y 1 , y 2 , … , y C b ) y_i \in Y_b = (y_1, y_2, \dots, y_{C_b}) yi∈Yb=(y1,y2,…,yCb) 是类别标签, N b N_b Nb 和 C b C_b Cb 分别是样本和类别的数量。类似地,新的类别集表示为 D novel = { x i , y i } i = 1 N n D_{\text{novel}} = \{x_i, y_i\}_{i=1}^{N_n} Dnovel={xi,yi}i=1Nn,其中 y i ∈ Y n = { y j } j = C b + 1 C b + C n y_i \in Y_n = \{y_j\}_{j=C_b+1}^{C_b+C_n} yi∈Yn={yj}j=Cb+1Cb+Cn,其中 C n C_n Cn 表示新类别的数量, Y b Y_b Yb 和 Y n Y_n Yn 分别表示基础和新类别的标签集。
大多数FSL方法使用元学习方式(情节化采样)来生成许多少样本任务进行训练。具体地,为了生成一个
M
M
M 类
K
K
K 样本的任务,我们从基础集中随机选择
M
M
M 个类别,然后从每个选定的类别中随机选择
N
k
N_k
Nk +
N
q
N_q
Nq 个样本,其中
M
N
k
M N_k
MNk 和
M
N
q
M N_q
MNq 样本分别用于构建支持集
S
S
S 和查询集
Q
Q
Q。目标是找到一个模型
f
fsl
f_{\text{fsl}}
ffsl,它通过以下方式对查询样本
x
q
x_q
xq 进行分类:
y
^
q
=
f
fsl
(
x
q
;
θ
fsl
,
S
)
∈
Y
s
⊂
Y
b
\hat{y}_q = f_{\text{fsl}} (x_q ; \theta_{\text{fsl}}, S) \in Y_s \subset Y_b
y^q=ffsl(xq;θfsl,S)∈Ys⊂Yb,其中
Y
s
Y_s
Ys 是支持集
S
S
S 的类别标签集,
θ
fsl
\theta_{\text{fsl}}
θfsl 是
f
fsl
f_{\text{fsl}}
ffsl 的参数集。形式上,模型
f
fsl
f_{\text{fsl}}
ffsl 被学习以最小化这些生成任务的平均损失。损失定义为:
L
f
=
∑
(
x
,
y
)
∈
Q
l
f
(
x
,
y
;
θ
fsl
,
S
)
,
(1)
L_f = \sum_{(x, y) \in Q} l_f(x, y; \theta_{\text{fsl}}, S), \tag{1}
Lf=(x,y)∈Q∑lf(x,y;θfsl,S),(1)
其中损失
l
l
l 测量预测值与真实标签之间的差异。最后,我们在
D
novel
D_{\text{novel}}
Dnovel 上的数千个少样本任务中评估模型,并将平均分类准确度作为最终性能。
3.2. 半监督学习(SSL)
与FSL不同,SSL没有用于评估或测试的新类别集。SSL测试集中的类别与训练集中的类别相同。因此,在此设置中,我们不需要使用
D
novel
D_{\text{novel}}
Dnovel。为了评估在少样本和半监督任务上的性能,我们将原始基础集
D
base
D_{\text{base}}
Dbase 分成三个集:
D
l
D_l
Dl、
D
u
D_u
Du 和
D
t
D_t
Dt,分别对应半监督设置中的标记集、未标记集和测试集。具体来说,我们从每个类别中随机选择
N
l
N_l
Nl(少于 20%)和
N
t
N_t
Nt(接近 20%)个样本来构建标记集和测试集。每个类别中剩余的样本用于构建未标记集。SSL的目标是学习一个模型
f
ssl
f_{\text{ssl}}
fssl,它能够分类基础类别的测试实例
x
t
x_t
xt,使得
y
t
=
f
ssl
(
x
t
;
θ
s
)
∈
Y
b
y_t = f_{\text{ssl}} (x_t; \theta_s) \in Y_b
yt=fssl(xt;θs)∈Yb。形式上,我们可以通过最小化以下损失来学习该模型 48:
L
=
∑
(
x
,
y
)
∈
D
l
l
(
x
,
y
;
θ
s
)
+
α
∑
x
∈
D
u
l
u
(
x
;
θ
s
)
+
β
∑
x
∈
D
ˉ
train
r
(
x
;
θ
s
)
,
(2)
L = \sum_{(x, y) \in D_l} l(x, y; \theta_s) + \alpha \sum_{x \in D_u} l_u(x; \theta_s) + \beta \sum_{x \in \bar{D}_{\text{train}}} r(x; \theta_s), \tag{2}
L=(x,y)∈Dl∑l(x,y;θs)+αx∈Du∑lu(x;θs)+βx∈Dˉtrain∑r(x;θs),(2)
其中
l
l
l 是每个样本的监督损失,
l
u
l_u
lu 表示无监督损失,
r
r
r 是正则化项,例如一致性损失或其他正则化项,
D
ˉ
train
=
D
l
∪
D
u
\bar{D}_{\text{train}} = D_l \cup D_u
Dˉtrain=Dl∪Du。
3.2. 半监督元训练用于少样本学习
给定拆分的集合,我们可以将 D ˉ train \bar{D}_{\text{train}} Dˉtrain 作为新提出的半监督元训练设置中的训练(基础)集。新类别集与常见的少样本设置相同,以保持现有方法的相同评估。在我们的实验中,我们在少样本新类别集 D novel D_{\text{novel}} Dnovel 上评估我们的模型,同时在半监督测试集 D t D_t Dt 上进行测试,以探索元学习方式对常见半监督方法的影响。
我们的新训练设置与之前的SSFSL方法完全不同,包括基于元训练的 11, 12 和基于迁移学习的 8, 36 算法。首先,在基于元训练的工作中,每个 M M M-way K K K-shot 任务中都存在一个额外的未标记集 U U U。从每个 M M M 类中选择 U U U 个未标记样本来构建这个未标记集。然而,这种选择策略需要对于这些“未标记”样本的标签的先验信息,在训练阶段这并不合理,且无法利用真正的未标记样本。为了消除对先验标签的要求,并使得半监督少样本设置变得实际,我们将训练集划分为标记集( D l D_l Dl)和未标记集( D u D_u Du),并在训练阶段禁止对未标记集使用上述选择策略。其次,基于迁移学习的算法需要基础类别集中的所有标记数据进行训练,而我们的设置只需要少量的标签。
4. 基于伪标签的元学习
在提出的半监督少样本设置下,我们首先忽略未标记集 D u D_u Du,并使用标记集 D l D_l Dl 来训练现有的少样本模型。我们改变标记数量 N l N_l Nl,并观察三种代表性方法(Proto 4),T-EP 和 S-EP 8 在多个少样本任务上的表现。如图 1 所示,所有模型的评估得分随着 N l N_l Nl 的减少而急剧下降。例如,当我们使用非常少的标记数据,即 N l = 20 N_l = 20 Nl=20( 4 % ∣ D ˉ train ∣ 4\% \, | \, \bar{D}_{\text{train}} | 4%∣Dˉtrain∣),S-EP 模型(使用 Conv4)在 miniImageNet 19 上的准确率在 5-way 5-shot 任务中从 72.45% 急剧下降到 55.64%。那么,我们是否可以使用未标记数据来填补因标记数据减少而产生的巨大差距呢?为了回答这个问题,我们提出了一种新颖的半监督少样本训练框架,旨在充分利用未标记数据。受到近期两阶段方法 8 的启发,我们也将训练方法分解为预训练和微调阶段。我们在图 3 中展示了我们的框架。
4.1. Pre-Training with SSL
FSL 模型
f
fsl
f_{\text{fsl}}
ffsl 通常被分解为一个特征提取器
φ
\varphi
φ,它用于获取样本
x
x
x 的判别特征,即
z
=
φ
(
x
;
θ
φ
)
z = \varphi(x; \theta_{\varphi})
z=φ(x;θφ),和一个 M-way 分类器
c
f
c_f
cf,它根据支持集
S
S
S 来预测类标签,即
y
^
=
c
f
(
z
;
θ
f
,
S
)
∈
R
M
\hat{y} = c_f(z; \theta_f, S) \in \mathbb{R}^M
y^=cf(z;θf,S)∈RM,其中
y
^
\hat{y}
y^ 是
Y
s
Y_s
Ys 中的预测 one-hot 标签。预训练的目标是获得一个好的特征提取器
φ
\varphi
φ 初始化,该初始化包含足够的类先验知识。因此,以前的方法 8,36 为基类集添加了一个新的基分类器
c
b
c_b
cb,即
y
=
c
b
(
z
;
θ
b
)
∈
R
C
b
y = c_b(z; \theta_b) \in \mathbb{R}^{C_b}
y=cb(z;θb)∈RCb,其中
y
y
y 是
Y
b
Y_b
Yb 的预测 one-hot 标签,与
c
f
c_f
cf 只关注支持集中的类不同。然后,
φ
\varphi
φ 和
c
b
c_b
cb 通过监督学习方法进行训练。令人惊讶的是,这一策略在少样本任务中取得了显著的提升。
受此启发,我们在新的半监督 FSL 方法中也使用
c
b
c_b
cb 进行预训练。我们的目标不仅是训练一个好的特征提取器
φ
\varphi
φ,而且还要学习一个判别性的基分类器
c
b
c_b
cb 来预测未标记样本的基类标签。这些预测标签将作为伪标签在微调阶段使用。我们希望预训练方法能够提高
φ
\varphi
φ 和
c
b
c_b
cb 的判别能力。这个目标与常见的半监督学习相同,即旨在学习一个能够分类基类标签(
Y
b
Y_b
Yb)的模型。根据公式(2),我们设置
θ
φ
,
θ
b
⊂
θ
s
{\theta_{\varphi}, \theta_b} \subset \theta_s
θφ,θb⊂θs。然后,我们可以直接采用现有的半监督方法来预训练我们的特征提取器
φ
\varphi
φ 和分类器
c
b
c_b
cb。
4.2. Finetuning with Noise Suppression
为了利用未标记的数据,我们首先使用预训练模型生成伪标签,如下所示:
y
~
i
=
π
(
x
i
)
=
Y
b
[
arg
max
j
c
b
(
φ
(
x
i
)
)
j
]
,
x
i
∈
D
u
.
(3)
\tilde{y}_i = \pi(x_i) = Y_b[\arg \max_j c_b(\varphi(x_i))_j], \quad x_i \in D_u. \tag{3}
y~i=π(xi)=Yb[argjmaxcb(φ(xi))j],xi∈Du.(3)
我们将
D
p
=
{
(
x
i
,
y
~
i
)
∣
x
i
∈
D
u
}
D_p = \{(x_i, \tilde{y}_i) | x_i \in D_u\}
Dp={(xi,y~i)∣xi∈Du} 作为伪标签数据集。结合标记集,我们获得新的训练集
D
~
train
=
D
l
∪
D
p
\tilde{D}_{\text{train}} = D_l \cup D_p
D~train=Dl∪Dp,该训练集可能包含噪声标签。为了减少噪声标签的负面影响,我们提出了一种基于标签一致性的噪声抑制微调框架,旨在处理具有相似特征的样本。我们的核心思想灵感来自于一个假设:具有相似特征的样本更有可能具有相同的标签。因此,我们设计了一个可学习的平滑模块来调整特征,以及一个噪声丢弃策略来进行微调。
4.2.1. 可学习的平滑模块:
对于每个少样本任务,我们的目标是利用任务中的所有样本,通过平滑它们的特征,使其更接近具有正确标签的样本。具体来说,首先我们采用一个深度为1的 Transformer 编码器层
T
T
T 49,通过自注意力机制在任务的所有样本之间平滑特征嵌入。具体地,令特征矩阵为
Z
=
[
z
1
;
z
2
;
⋯
;
z
N
f
]
∈
R
N
f
×
D
f
,
Z = [z_1; z_2; \cdots; z_{N_f}] \in \mathbb{R}^{N_f \times D_f},
Z=[z1;z2;⋯;zNf]∈RNf×Df,其中
D
f
D_f
Df 是特征维度,
N
f
=
∣
Q
~
∪
S
~
∣
N_f = |\tilde{Q} \cup \tilde{S}|
Nf=∣Q~∪S~∣,
S
~
\tilde{S}
S~ 和
Q
~
\tilde{Q}
Q~ 分别表示从
D
~
train
\tilde{D}_{\text{train}}
D~train 中生成的支持集和查询集。然后,Transformer 操作公式为:
Z
t
=
T
(
Z
;
θ
t
)
,
Z_t = T(Z; \theta_t),
Zt=T(Z;θt),.其中
N
f
N_f
Nf 在
Z
Z
Z 中被解释为序列长度或Transformer中的单词数量,因此,Transformer中的自注意力机制可以视为特征传播和平滑层。进一步地,为了让这个模块能够更多地学习相似样本,我们添加了另一个特征(嵌入)传播机制 8, 50 来引导学习过程,并使得噪声特征变得更加平滑。具体来说,首先我们计算邻接矩阵:
A
i
j
=
exp
(
−
d
i
j
2
σ
2
)
,
i
≠
j
,
A
i
i
=
0
,
A_{ij} = \exp\left(-\frac{d_{ij}^2}{\sigma^2}\right), \quad i \neq j, \quad A_{ii} = 0,
Aij=exp(−σ2dij2),i=j,Aii=0,其中
d
i
j
2
=
∥
z
i
t
−
z
j
t
∥
2
2
d_{ij}^2 = \|z_i^t - z_j^t\|_2^2
dij2=∥zit−zjt∥22,
σ
2
=
Var
(
d
i
j
2
)
,
∀
z
i
t
,
z
j
t
∈
Z
t
\sigma^2 = \text{Var}(d_{ij}^2), \quad \forall z_i^t, z_j^t \in Z_t
σ2=Var(dij2),∀zit,zjt∈Zt。给定邻接矩阵,我们得到传播矩阵
P
=
(
I
−
α
p
L
)
−
1
,
P = (I - \alpha_p L)^{-1},
P=(I−αpL)−1,其中
L
=
D
−
1
2
A
D
−
1
2
L = D^{-\frac{1}{2}} A D^{-\frac{1}{2}}
L=D−21AD−21 是拉普拉斯矩阵 50,
D
i
i
=
∑
j
A
i
j
D_{ii} = \sum_j A_{ij}
Dii=∑jAij,
α
p
=
0.2
\alpha_p = 0.2
αp=0.2 是缩放因子,
I
I
I 是单位矩阵。然后,特征被调整为:
Z
p
=
P
Z
t
.
Z_p = P Z_t.
Zp=PZt.可学习的平滑模块为:
z
p
i
=
ms
(
z
i
;
θ
t
)
,
∀
z
p
i
∈
Z
p
.
(4)
z_p^i = \text{ms}(z_i; \theta_t), \quad \forall z_p^i \in Z_p. \tag{4}
zpi=ms(zi;θt),∀zpi∈Zp.(4)
4.2.2. 噪声丢弃策略:
为了进一步抑制噪声,我们根据相似样本之间的标签一致性假设,丢弃一些标签。对于 M-way K-shot 任务中的第
i
i
i 类集,我们随机选择一个样本作为锚点,并将其特征表示为
z
a
i
∈
Z
z_a^i \in Z
zai∈Z。然后,我们计算锚点与其他样本之间的距离:
d
a
i
j
=
∥
z
a
i
−
z
j
∥
2
2
,
∀
z
j
∈
Z
,
y
^
j
=
i
.
d_{a_{ij}} = \|z_a^i - z_j\|_2^2, \quad \forall z_j \in Z, \quad \hat{y}_j = i.
daij=∥zai−zj∥22,∀zj∈Z,y^j=i.
接下来,我们根据距离的升序对这些样本进行排序,并选择前
N
k
N_k
Nk 个样本(包括锚点)来重建支持集,这样可以减少噪声。由于距离较大的样本更可能与锚点具有不一致的标签,因此我们丢弃最后
⌊
α
d
N
q
⌋
\lfloor \alpha_d N_q \rfloor
⌊αdNq⌋ 个样本,并选择剩下的样本来重建查询集,其中
α
d
\alpha_d
αd 是丢弃率(实验设置为 0.1),
N
q
N_q
Nq 是查询样本数。最终,我们获得了更干净的支持集
S
~
r
\tilde{S}_r
S~r 和查询集
Q
~
r
\tilde{Q}_r
Q~r。
4.2.3. 训练损失:
我们的可学习平滑模块和噪声丢弃策略是模型无关的,因此可以与大多数少样本模型结合使用。结合公式(4)和公式(1),我们得到以下损失的通用公式:
L
f
=
∑
(
x
,
y
~
)
∈
Q
~
l
f
(
x
,
y
~
;
θ
ϕ
,
θ
t
,
θ
f
,
S
~
r
)
,
(5)
L_f = \sum_{(x, \tilde{y}) \in \tilde{Q}} l_f(x, \tilde{y}; \theta_\phi, \theta_t, \theta_f, \tilde{S}_r),\tag{5}
Lf=(x,y~)∈Q~∑lf(x,y~;θϕ,θt,θf,S~r),(5)
其中,
l
f
(
x
i
,
y
~
i
)
=
H
(
c
f
(
m
s
(
ϕ
(
x
i
)
)
)
,
y
^
i
)
,
l_f(x_i, \tilde{y}_i) = H(cf(ms(\phi(x_i))), \hat{y}_i),
lf(xi,y~i)=H(cf(ms(ϕ(xi))),y^i),
H
H
H 代表交叉熵损失,
y
^
i
∈
R
M
\hat{y}_i \in \mathbb{R}^M
y^i∈RM 是
M
M
M 类的独热编码标签。此外,我们还会对分类器
c
b
c_b
cb 进行微调,以保持其在基础类别上的判别能力,损失公式为:
L
l
=
∑
(
x
,
y
~
)
∈
Q
~
∪
S
~
l
l
(
x
,
y
~
;
θ
ϕ
,
θ
b
)
,
(6)
L_l = \sum_{(x, \tilde{y}) \in \tilde{Q} \cup \tilde{S}} l_l(x, \tilde{y}; \theta_\phi, \theta_b),\tag{6}
Ll=(x,y~)∈Q~∪S~∑ll(x,y~;θϕ,θb),(6)
其中,
l
l
(
x
i
,
y
~
i
)
=
H
(
c
b
(
ϕ
(
x
i
)
)
,
y
i
)
,
l_l(x_i, \tilde{y}_i) = H(c_b(\phi(x_i)), y_i),
ll(xi,y~i)=H(cb(ϕ(xi)),yi),
y
i
∈
R
C
b
y_i \in \mathbb{R}^{C_b}
yi∈RCb 是基础类别
Y
b
Y_b
Yb 的独热编码标签。最终的损失函数为:
L
f
t
=
L
f
+
γ
L
l
,
L_{ft} = L_f + \gamma L_l,
Lft=Lf+γLl,其中,权衡参数
γ
\gamma
γ 实验上设置为 0.1。
我们在算法 1 中展示了我们提出的框架的伪代码。该伪代码概述了关键步骤和组成部分,为应用我们的方法提供了清晰简洁的指南。具体代码可以在摘要中提到的 GitHub 地址找到。

5. EXPERIMENTS
5.1. Experimental Setting
5.1.1. Datasets.
我们在两个标准数据集上评估了我们的方法:miniImageNet 19 和 tieredImageNet 12。miniImageNet 是 ImageNet 51 的一个子集,由 100 个类别组成,每个类别包含 600 张图像。这些类别被分为 64 个基础类别、16 个验证类别和 20 个新类别。tieredImageNet 是一个比 miniImageNet 更具挑战性且规模更大的数据集,其中类别被分为 20 个基础(351 个类别)、6 个验证(97 个类别)和 8 个新类别(160 个类别)的大类,这些类别从 WordNet 层次结构的超集选择而来。每个类别包含大约 900–1200 张图像。
为了将上述数据集调整为我们的新 SSFSL 设置,我们根据每个类别的图像数量,为不同的数据集设置了不同的 N l N_l Nl 和 N t N_t Nt(在 §III 中提出),以划分标注数据集、未标注数据集和测试集。具体而言,对于 miniImageNet,我们设置 N l = [ 20 , 50 , 100 ] N_l = [20, 50, 100] Nl=[20,50,100] 和 N t = 100 N_t = 100 Nt=100。对于 tieredImageNet,我们增加了数量,即 N l = [ 20 , 100 , 200 ] N_l = [20, 100, 200] Nl=[20,100,200] 和 N t = 200 N_t = 200 Nt=200。需要注意的是,由于我们使用了更少的标注数据,因此我们在所有基础训练数据上的结果低于原始论文中的结果。
5.1.2. Training and Inference Details.
我们使用了两种常见的特征提取器(骨干网络):(i) Conv4:一个具有 64 个通道的 4 层卷积网络 4,以及 (ii) ResNet12:一个 12 层残差网络 52。对于所有数据集,我们将图像调整为 84×84 的大小。
在预训练阶段,我们采用 EP 8 中相同的策略作为基础训练方法,并使用官方代码中的默认超参数设置训练 SSL 模型(SemCo 16、FlexMatch 17 和 MarginMatch 18)。在逐次微调阶段,对于 miniImageNet 和 tieredImageNet,每个 episode 随机采样 5 个类别,并在每个类别中分别选择 5 个样本作为支持集,15 个样本作为查询集。我们使用 SGD 优化模型,初始学习率为 0.01,共训练 200 个 epoch。当验证损失在 10 个 epoch 内没有下降时,我们将学习率减少 10 倍。
我们在 1-shot 或 5-shot 任务的推理过程中,在查询集中使用 15 个样本。对于半监督推理,我们每个类别采用 100 个未标注数据(与 EP 相同)。
5.2. Previous Semi-supervised FSL methods with Fewer Labels
为了研究训练标签数量对以往半监督 FSL 方法的影响,我们选择了两种主流算法,包括基于半监督元训练的方法和基于有监督预训练的方法,作为比较的代表。前者(如 SPN 12 和 M-PL 10)将基础训练集划分为标注集和未标注集,仅通过半监督元训练来学习 FSL 模型。后者使用基础训练集中的所有标签,通过简单的有监督学习进行预训练,以获得具有判别能力的特征提取器。
如表 I 所示,我们在 miniImageNet 的新类别集上对所有方法进行了评估,针对 5-way 1-shot 和 5-shot 任务。所有现有方法在减少标注数据时都遭受了较大的性能下降。开创性工作 SPN 需要大量的标签进行训练。在其原始设置中,标注集包含基础训练集的 40% 标注样本。因此,当我们减少标签时,其性能显著下降。M-PL 在标签减少时表现出更稳定的性能,因为它使用次模互信息选择可靠的未标注集进行元训练。然而,由于缺乏预训练阶段以获得更好的特征表示,这两种方法仍与 EP 和 MFC 存在较大的性能差距。
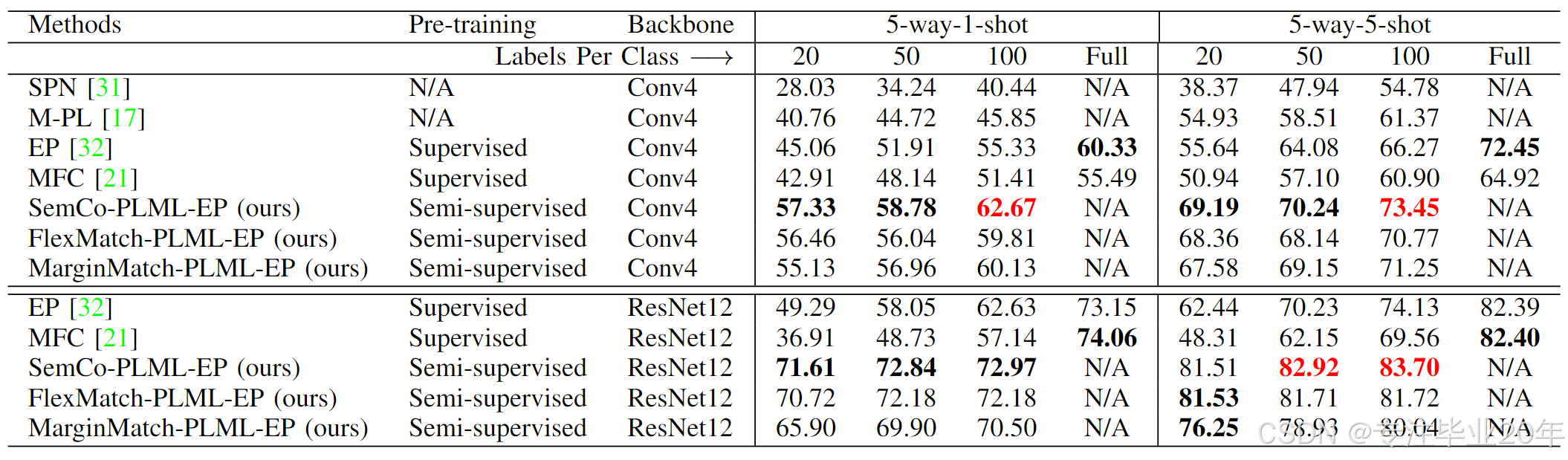
表 I:在 miniImageNet 数据集上使用半监督推理的 M-way K-shot 任务的准确率(%)。我们展示了基于 EP 8 的 FSL 方法和三种 SSL 方法(SemCo 16、FlexMatch 17 和 MarginMatch 18)进行预训练的结果。最佳值以加粗显示。红色值表示我们的 PLML 方法优于使用全标注数据训练的模型。需要注意的是,SPN 和 M-PL 仅使用 Conv4 进行评估,因此我们仅提供了 Conv4 的结果。
EP 和 MFC 在标注数据较少的情况下也有较大的性能下降。例如,在每类仅有 20 个标签的设置下,EP 在四个任务中表现出显著的性能下降,分别下降了 15.27%(使用 Conv4 的 1-shot)、16.80%(使用 Conv4 的 5-shot)、23.86%(使用 ResNet12 的 1-shot),以及最后一个任务中类似的 19.95%。MFC 在四个 FSL 任务中也有类似的大幅下降。
总之,基于半监督元训练的方法和基于预训练的半监督 FSL 方法之间仍然存在一定的性能差距。大多数半监督模型仍然需要大量的标注数据才能达到预期性能。这些结果启发我们设计了一种新的半监督 FSL 模型,以更有效地利用标签。
5.3. Inductive and Transductive Methods with Fewer Labels
为了研究训练标签数量对另外两类 FSL 模型的影响,我们选择 Proto 4 作为归纳 FSL 方法的代表,并选择 EP 8 作为推断 FSL 算法的代表。我们首先使用 EP 的预训练方法(例如表 II 中的 Base)在具有不同标注数据数量的 miniImageNet 子集上训练模型。然后,我们通过 Proto 或 EP 的逐次训练(元学习)方式在相同的子集上微调这些模型。最后,我们通过 5-way 1-shot 和 5-shot 任务中的常用推理方法,在新类别集上评估这些模型。为了进一步研究预训练的影响,我们移除微调阶段,并直接评估预训练模型,例如表 II 中的 Base+N/A。
当我们减少标签数量时,微调阶段在大多数任务中无法带来性能提升。仅有使用 ResNet12 的 Base+EP 在 1/4 的任务中表现优于预训练模型。这表明在基础标签较少的情况下,现有方法并不稳定。因此,我们需要为这种新情况探索新的 FSL 微调方法。此外,如表 II 所示,所有模型在标注数据减少时都遭受了严重的性能下降。例如,在每类仅有 20 个标签的设置下,使用 Conv4 的归纳 Proto 模型(Base+Proto)的准确率在 1-shot 和 5-shot 任务中分别下降了 11.19% 和 14.29%。对于使用 ResNet12 的 Base+EP 模型,性能下降更大,分别达到 19.23% 和 21.49%。使用 Conv4 的推断 EP 模型在两个任务中分别急剧下降了 12.67% 和 14.14%。同样,使用 ResNet12 的版本精度下降更为明显,分别下降了 20.98% 和 21.03%。上述结果表明,目前的 FSL 模型仍然严重依赖基础训练集中大量的标注数据,这限制了它们在实际应用中的使用。
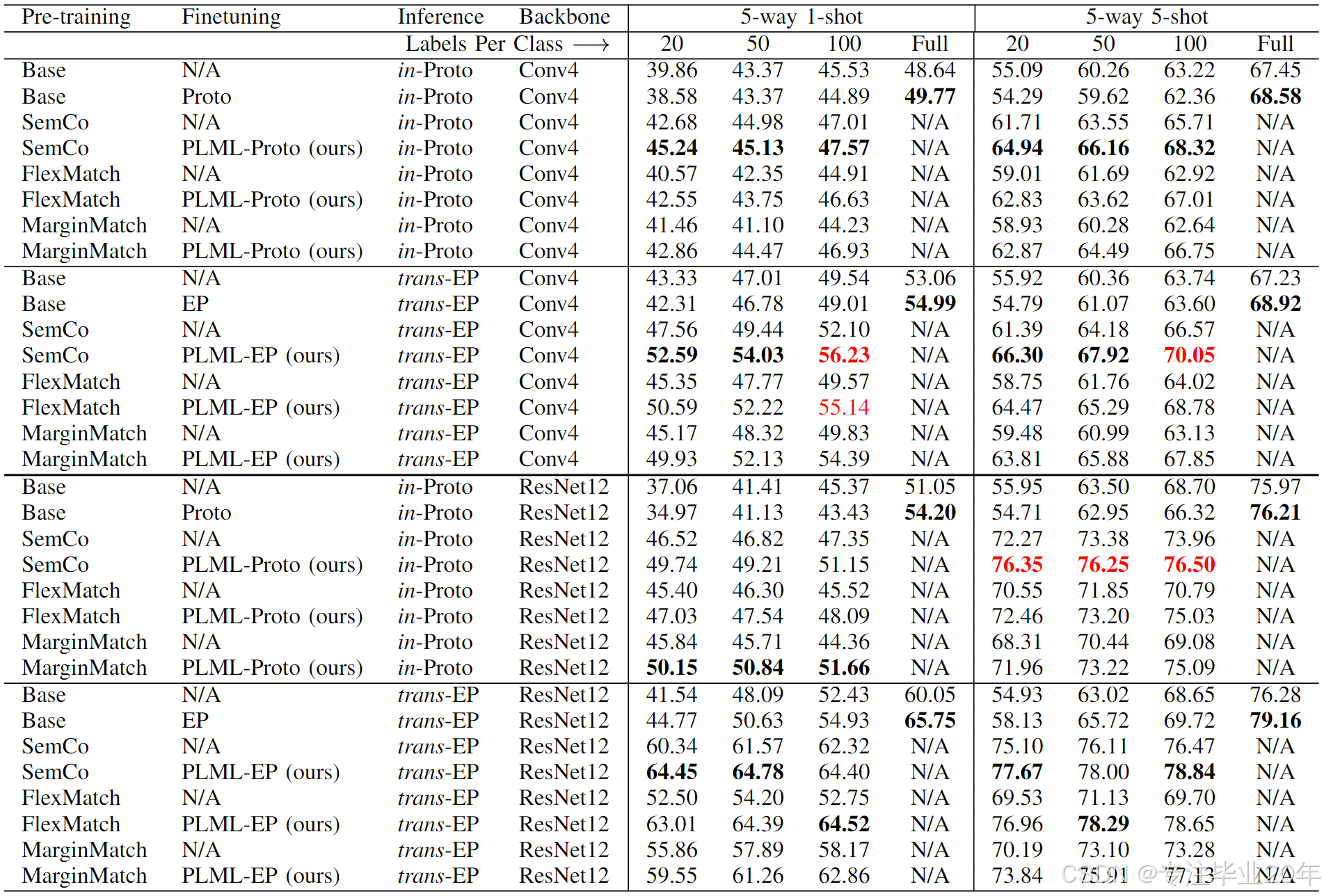
表 II:在 miniImageNet 数据集上使用归纳式(in)、推断式(trans)和半监督(semi)推理的 M-way K-shot 任务的准确率(%)。我们展示了基于两种 FSL 方法(Proto 4 和 EP 8)的结果,这些方法使用了 Base 预训练方法以及两种 SSL 方法(SemCo 16 和 FlexMatch 17)。最佳值以加粗显示。红色值表示我们的 PLML 方法优于使用全标注数据训练的模型。
5.4. Benefits of Our PLML
为了评估我们提出的 PLML 方法的有效性,我们选择 SemCo 16 作为预训练方法,然后使用基于 Proto 和 EP 的 PLML-Proto 和 PLML-EP 方法进行微调。如表 I 和表 II 所示,与基线方法(Base+Proto 或 EP)相比,采用我们 PLML 方法(SemCo+PLML-*)的所有模型在所有评估任务中(包含三种推理方式和更少的标签)均实现了显著的性能提升,尤其是在标签最少(每类 20 个标签)的数据集上。例如,在每类 20 个标签的设置下,使用 ResNet12 的模型在三种推理方式下的 1-shot 任务中获得了 14.77%–22.31% 的显著增益。在 5-shot 任务中,所提方法相较于基线提升了 19.09%–21.63%。对于 Conv4 骨干网络,我们的方法在 1-shot 任务中也实现了 6.66%–12.27% 的性能提升,在 5-shot 任务中提升了 10.65%–13.54%。上述性能提升清晰地表明了我们方法在少量训练标签条件下对 FSL 的优势。
在某些设置中,我们的方法在更少标签的情况下表现出优于全标注模型的性能。这表明在 FSL 任务中,全监督训练与半监督训练之间的差距已大幅缩小。
5.5. Different SSL Methods
为了评估我们 PLML 方法的泛化性,我们使用其他 SSL 方法(FlexMatch 17 和 MarginMatch 18)作为预训练方法。如表 I 和表 II 所示,基于 FlexMatch 和 MarginMatch 的模型在大多数设置中也相较于基线取得了显著的性能提升。这表明我们提出的 PLML 方法对于不同的 SSL 预训练方法具有较强的鲁棒性。总体而言,基于 FlexMatch 和 MarginMatch 的模型的性能略低于对应的 SemCo 基模型,因为 SemCo 引入了语义嵌入特征,从而提供了更好的先验知识。这表明我们的方法能够将 SSL 方法的优势迁移到 FSL 的半监督训练中,并在这两者之间建立桥梁。
此外,我们直接在新类别集上评估这些预训练方法,以探索 SSL 模型的有效性。与基线模型(Base)相比,基于 SemCo、FlexMatch 和 MarginMatch 的模型在大多数设置中均取得了显著的性能提升。然而,与全标注模型相比,这些模型仍存在一定的差距,尤其是在基于 ResNet12 的模型中。在结合了我们 PLML 方法后,这些差距在大多数任务中已被大幅缩小。例如,使用 ResNet12 的基于 SemCo 的模型在 5-way 5-shot 任务中,与全标注模型相比表现相近甚至优于全标注模型。
5.6. Our PLML for Different Datasets
为了进一步展示泛化性,我们在 tieredImageNet 数据集上评估了我们的方法。1-shot 和 5-shot 任务的结果见表 III。我们的 PLML 方法促进了基于 SemCo 和 FlexMatch 的模型在大多数任务中实现了显著的性能提升,并接近全标注基线的表现。特别是在 20 标签子集的 5-way 5-shot 任务中,最高增益达到 11.81%(SemCo+semi-EP)。此外,在 26 个任务中,我们的方法超越了全标注基线(以红色标注)。这表明我们的方法在大规模数据集上的泛化能力。

表 III:在 tieredImageNet 12 数据集上使用归纳式(in)、推断式(trans)和半监督(semi)推理的 M-way K-shot 任务的准确率(%)。我们展示了基于两种 FSL 方法(Proto 4 和 EP 8)的结果,这些方法使用了 Base 预训练方法以及两种 SSL 方法(SemCo 16 和 FlexMatch 17)。PLML 表示我们的方法。最佳值以加粗显示。红色值表示我们的模型优于使用全标注数据训练的原始模型。
5.7. Different SS-Meta-Training Setting
为了研究类别优先选择策略的影响(即,首先选择一些类别,然后从这些类别中选择若干样本),我们通过原始设置和新的设置(使用不同的标签数量)重新训练了两种具有代表性的方法:SPN 12 和 M-PL 10。随后,我们在 miniImageNet 和 tieredImageNet 数据集上,使用包含 15 个查询样本和 100 个未标注样本的半监督推理方法对其进行评估。如表 IV 所示,SPN-N 的准确率大幅下降,而 M-PL-N 的下降幅度较小。这表明,我们无法根据原始设置中获得的结果正确推断新设置下的性能。因此,我们需要新的设置来重新评估这些方法。

表 IV:在原始设置和新设置下 M-way K-shot 任务的准确率(%)。我们展示了基于官方代码的 SPN 12 和 M-PL 10 在 miniImageNet 和 tieredImageNet 数据集上的结果。每个数据集中性能下降最显著的结果以加粗显示。
5.8. Benefits of Meta-Learning for SSL
为了研究元学习对 SSL 模型的影响,我们通过 PLML 微调 SemCo 和 FlexMatch,并在 miniImageNet 和 tieredImageNet 的基础类别测试集上对其进行评估。如图 4 所示,我们的方法在三个数据集的大多数评估任务中均表现出优于基线的性能。具体而言,在 miniImageNet 上(SemCo-trans,20 标签设置),最高增益达到 3.04%;在 tieredImageNet 上(FlexMatch-trans,200 标签设置),最高增益为 2.83%,均超过了最先进的 SSL 算法。这表明元学习对 SSL 具有巨大潜力,因为我们的方法仅是将元学习用于 SSL 的初步和简单尝试。未来可以引入更多技术来将这两个领域相结合。
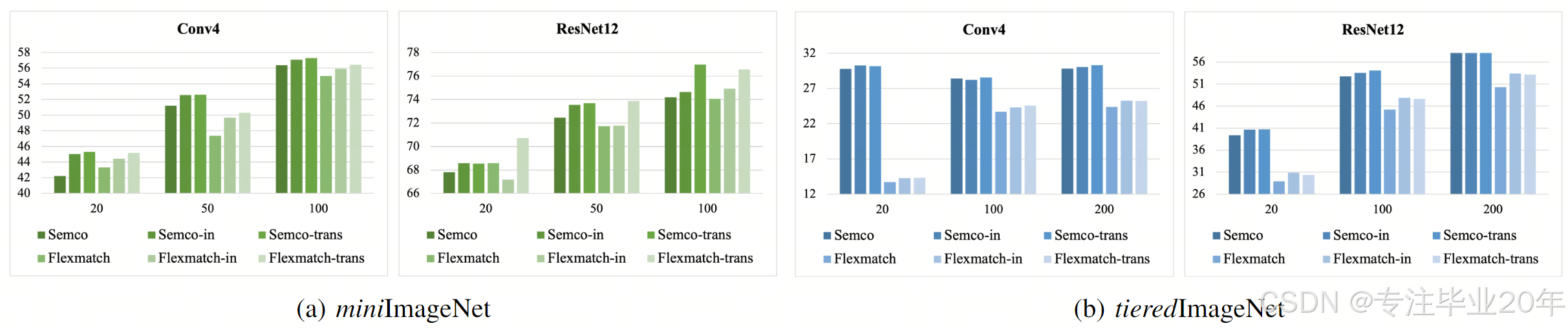 图 4:SSL 方法的准确率(%),包括 SemCo、FlexMatch 以及我们的模型:SemCo-in、SemCo-trans、FlexMatch-in 和 FlexMatch-trans。其中,in 表示归纳式 Proto,trans 表示推断式 EP。
图 4:SSL 方法的准确率(%),包括 SemCo、FlexMatch 以及我们的模型:SemCo-in、SemCo-trans、FlexMatch-in 和 FlexMatch-trans。其中,in 表示归纳式 Proto,trans 表示推断式 EP。
5.9. Relation between the Pseudo-labeling Accuracy and FewShot Learning Performance
为了研究伪标签(Pseudo-labeling, PL)准确率的影响,我们提供了基础数据集训练集上的分类准确率以及相应的 5-way 5-shot 任务中的小样本学习(FSL)准确率。如表 V 所示,PL 和 FSL 的准确率随着每类标签数量的增加而普遍提高。此外,即使 PL 的准确率较低,我们的方法在仅使用 20 个标签的情况下,仍然能够实现与全监督模型相当的性能。更好的骨干网络可以使完整模型的性能差距更小(C4: 2.62% vs. R12: 1.49%),这表明优秀的骨干网络结合我们的方法可以在少量标签的情况下提升准确率。

表 V:基于 SemCo-PLML-transEP 的伪标签(PL)和 5-way 5-shot 小样本学习(FSL)任务在 miniImageNet 数据集上的准确率(%)。
5.10. Ablation Study of Our PLML
为了评估我们 PLML 方法的关键组件,我们在 miniImageNet 数据集上对每类仅有 20 个标签的极少标签设置进行了实验。我们选择基于 Conv4 的推断式 EP 作为基线模型。如表 VI 所示,首先,我们使用 SemCo 对模型进行预训练,与 EP 相比,在 5-shot 和 1-shot 任务上分别取得了显著的性能提升(6.69% 和 5.25%)。随后,我们加入 Learnable Smoothing Module(LSM)进行特征调整,在 5-shot 和 1-shot 任务上分别获得了 4.20% 和 4.30% 的进一步提升。最后,我们额外应用噪声丢弃策略以在训练中去除噪声样本,在两个任务中均观察到了进一步的性能提升。
此外,我们还测试了仅使用 transformer 层或特征传播进行特征调整的方法。然而,这两种方法的性能均低于我们的 LSM,清楚地证明了我们模型的有效性。

表 VI:在 miniImageNet 数据集上每类 20 个标签的准确率(%)。“Ours” 指 SemCo-PLML-trans-EP,“Pre” 指预训练(Pre-train),“LSM” 指可学习平滑模块(Learnable Smoothing Module),“TL” 指 Transformer 层(Transformer Layer),“FP” 指特征传播(Feature Propagation),“ND” 指噪声丢弃(Noise Dropout)。除 EP 外,所有基于 Conv4 的推断式模型均由 SemCo 预训练。最佳值以加粗显示。
5.11. Benefits of Pseudo-Labeling
为了展示基于伪标签的预训练方法的优势,我们在 miniImageNet 数据集上进行了实验。如表 VII 所示,我们将 EP 中的预训练方法替换为我们的伪标签训练阶段(PL-EP),并在所有任务中相比原始 EP 实现了显著的性能提升。这表明,我们的伪标签方法可以轻松与其他 SSFSL 方法结合,以在少量标签的情况下提升性能。
然而,简单的结合仍然存在噪声样本的问题。因此,我们提出了结合噪声抑制的微调策略来缓解这一问题。我们的 PLML-EP 在所有条件下均取得了显著提升。具体而言,在每类 20 个标签的设置下,使用 Conv4 作为骨干网络时的最高增益达到 10.28%,而使用 ResNet12 作为骨干网络时的最高增益达到 19.68%。

表 VII:在 miniImageNet 数据集上 M-way K-shot 任务的准确率(%)。PL-EP 和 PLML-EP 在预训练阶段使用 SemCo,推理方法为 trans-EP。最佳值以加粗显示。
5.12. Ablation Study for Hyperparameter
我们主要的超参数之一是丢弃率
α
d
\alpha_d
αd(在 §IV-B 的噪声丢弃策略中)。我们通过不同的
α
d
\alpha_d
αd 值观察了在 miniImageNet 数据集上 5-way 5-shot 任务(每类 20 个标签)中的性能变化。如表 VIII 所示,当我们仅依赖支持集并且不丢弃任何样本(
α
d
=
0
\alpha_d = 0
αd=0)时,与原始设置(LSM)相比,性能略有提升。随后,我们将
α
d
\alpha_d
αd 从 0.1 增加到 0.3,并获得了类似的改进。这表明丢弃少量样本可以提升性能。然而,当我们将
α
d
\alpha_d
αd 增加到 0.5 时,准确率开始下降。这表明,移除过多样本会因为样本多样性不足而影响最终的训练性能。因此,我们通过实验将丢弃率
α
d
\alpha_d
αd 设置为较小的值,即 0.1。

表 VIII:在 miniImageNet 19 数据集上每类 20 个标签的 5-way 5-shot 任务的准确率(%)。我们展示了基于 SemCo 16 预训练和 PLML-EP 微调方法下,不同权衡参数
α
d
\alpha_d
αd 的结果。骨干网络为 Conv4。最佳值以加粗显示。
另一个主要超参数是基分类损失和小样本学习(FSL)分类损失之间的权衡参数 γ \gamma γ(在 §IV-B 的训练损失中)。为了研究它对两个任务的影响,我们使用不同的 γ \gamma γ 值进行微调。如表 IX 所示,当我们不使用基分类损失( γ = 0 \gamma = 0 γ=0)时,与预训练模型相比,我们的 FSL 性能(65.69% vs. 61.39%)和基分类准确率(44.28% vs. 42.23%)均有提升。随后,我们尝试了不同的 γ \gamma γ 值,发现当 γ = 0.1 \gamma = 0.1 γ=0.1 时,在两个任务上的性能均达到最佳。因此,我们通过实验将 γ \gamma γ 设置为 0.1。

表 IX:在 miniImageNet 19 数据集上每类 20 个标签的 5-way 5-shot 任务和基础分类的准确率(%)。我们展示了基于 SemCo 16 预训练和 PLML-EP 微调方法下,不同权衡参数
γ
\gamma
γ 的结果。“Pre” 指预训练(Pre-training)。骨干网络为 Conv4。最佳值以加粗显示。
5.13. Limits and Discussion
仍然存在一些需要解决的不足之处。首先,要实现与使用完整标注数据训练的模型相当的性能,通常需要较大的标签数量,通常在 100 个左右(见表 I)。在少量标签的任务(如每类 20 或 50 个标签)中,仍有很大的改进空间。其次,实验结果(例如表 II)表明,最终小样本学习方法的有效性与半监督学习的效果密切相关。从这个角度来看,进一步提升性能需要设计更好的训练机制,以充分利用元学习来训练半监督模型。
6.CONCLUSION
我们提出了一种用于小样本学习(FSL)的新型半监督设置,以探索在少量标签条件下的有效训练解决方案。在该设置下,我们发现大多数 FSL 方法在标签数量减少时会遭受显著的性能下降。为了解决这一问题,我们提出了一个简单但有效的两阶段学习框架,称为伪标签元学习(PLML),该框架成功地利用了半监督学习(SSL)和小样本学习(FSL)的优势,从少量标签中实现高效学习。
我们将 PLML 集成到三种 SSL 和 FSL 模型中。在两个数据集上的大量实验结果表明,我们的方法不仅显著提升了 FSL 基线的性能,还超越了 SSL 模型的表现。在某种意义上,PLML 是 FSL 和 SSL 之间的桥梁,我们相信它在促进这两个领域方面具有巨大的潜力。
Wenbin Li, Ziyi Wang, Xuesong Yang, Chuanqi Dong, Pinzhuo Tian, Tiexin Qin, Jing Huo, Yinghuan Shi, Lei Wang, Yang Gao, et al. Libfewshot: A comprehensive library for few-shot learning. IEEE Trans. Pattern Anal. Mach. Intell., 2023. 1 ↩︎
Yisheng Song, Ting Wang, Puyu Cai, Subrota K Mondal, and Jyoti Prakash Sahoo. A comprehensive survey of few-shot learning: Evolution, applications, challenges, and opportunities. ACM Comput. Surv., 55(13s):1–40, 2023. 1 ↩︎
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic metalearning for fast adaptation of deep networks. In Proc. Int. Conf. Mach. Learn., pages 1126–1135, 2017. 1, 3 ↩︎ ↩︎ ↩︎
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In Proc. Adv. Neural Inf. Process. Syst., pages 4077–4087, 2017. 1, 2, 3, 4, 6, 7, 8 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Thorsten Joachims et al. Transductive inference for text classification using support vector machines. In Proc. Int. Conf. Mach. Learn., volume 99, pages 200–209, 1999. 1 ↩︎
Yanbin Liu, Juho Lee, Minseop Park, Saehoon Kim, Eunho Yang, Sung Ju Hwang, and Yi Yang. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv preprint arXiv:1805.10002, 2018. 1, 3 ↩︎ ↩︎ ↩︎
Limeng Qiao, Yemin Shi, Jia Li, Yaowei Wang, Tiejun Huang, and Yonghong Tian. Transductive episodic-wise adaptive metric for fewshot learning. In Proc. IEEE Int. Conf. Comput. Vis., pages 3603–3612, 2019. 1 ↩︎
Pau Rodríguez, Issam Laradji, Alexandre Drouin, and Alexandre Lacoste. Embedding propagation: Smoother manifold for few-shot classification. In Proc. Eur. Conf. Comput. Vis., pages 121–138, 2020. 1, 2, 3, 4, 5, 6, 7, 8 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Michalis Lazarou, Tania Stathaki, and Yannis Avrithis. Iterative label cleaning for transductive and semi-supervised few-shot learning. In Proc. IEEE Int. Conf. Comput. Vis., pages 8751–8760, 2021. 1, 3 ↩︎ ↩︎
Changbin Li, Suraj Kothawade, Feng Chen, and Rishabh Iyer. PLATINUM: Semi-supervised model agnostic meta-learning using submodular mutual information. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors, Proc. Int. Conf. Mach. Learn., volume 162 of Proceedings of Machine Learning Research, pages 12826–12842. PMLR, 17–23 Jul 2022. 1, 2, 3, 6, 7, 9 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Xinzhe Li, Qianru Sun, Yaoyao Liu, Qin Zhou, Shibao Zheng, Tat-Seng Chua, and Bernt Schiele. Learning to self-train for semi-supervised few-shot classification. In Proc. Adv. Neural Inf. Process. Syst., pages 10276–10286, 2019. 1, 3, 4 ↩︎ ↩︎ ↩︎
Mengye Ren, Eleni Triantafillou, Sachin Ravi, Jake Snell, Kevin Swersky, Joshua B Tenenbaum, Hugo Larochelle, and Richard S Zemel. Meta-learning for semi-supervised few-shot classification. In Proc. Int. Conf. Learn. Represent., 2018. 1, 2, 3, 4, 6, 7, 8, 9 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Han-Jia Ye, Xin-Chun Li, and De-Chuan Zhan. Task cooperation for semi-supervised few-shot learning. In Proc. AAAI Conf. Artif. Intell., volume 35, pages 10682–10690, 2021. 1, 3 ↩︎ ↩︎
Jie Ling, Lei Liao, Meng Yang, and Jia Shuai. Semi-supervised few-shot learning via multi-factor clustering. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 14564–14573, 2022. 1, 2, 3, 7 ↩︎ ↩︎ ↩︎
Kyle Hsu, Sergey Levine, and Chelsea Finn. Unsupervised learning via meta-learning. In Proc. Int. Conf. Learn. Represent., 2019. 3 ↩︎
Islam Nassar, Samitha Herath, Ehsan Abbasnejad, Wray Buntine, and Gholamreza Haffari. All labels are not created equal: Enhancing semisupervision via label grouping and co-training. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 7241–7250, 2021. 3, 6, 7, 8, 10 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Bowen Zhang, Yidong Wang, Wenxin Hou, Hao Wu, Jindong Wang, Manabu Okumura, and Takahiro Shinozaki. Flexmatch: Boosting semisupervised learning with curriculum pseudo labeling. In Proc. Adv. Neural Inf. Process. Syst., pages 18408–18419, 2021. 3, 6, 7, 8 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Tiberiu Sosea and Cornelia Caragea. Marginmatch: Improving semisupervised learning with pseudo-margins. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 15773–15782, 2023. 3, 6, 7, 8 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Sachin Ravi and Hugo Larochelle. Optimization as a model for few-shot learning. In Proc. Int. Conf. Learn. Represent., 2017. 1, 3, 4, 6, 10 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy Lillicrap. Meta-learning with memory-augmented neural networks. In Proc. Int. Conf. Mach. Learn., pages 1842–1850, 2016. 3 ↩︎
Luca Bertinetto, Joao F Henriques, Philip HS Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. In Proc. Int. Conf. Learn. Represent., 2019. 3 ↩︎
Chelsea Finn, Kelvin Xu, and Sergey Levine. Probabilistic model-agnostic meta-learning. In Proc. Adv. Neural Inf. Process. Syst., pages 9537–9548, 2018. 3 ↩︎
Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, and Stefano Soatto. Meta-learning with differentiable convex optimization. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 10657–10665, 2019. 3 ↩︎
Aravind Rajeswaran, Chelsea Finn, Sham Kakade, and Sergey Levine. Meta-learning with implicit gradients. In Proc. Adv. Neural Inf. Process. Syst., pages 113–124, 2019. 3 ↩︎
Luisa Zintgraf, Kyriacos Shiarli, Vitaly Kurin, Katja Hofmann, and Shimon Whiteson. Fast context adaptation via meta-learning. In Proc. Int. Conf. Mach. Learn., pages 7693–7702, 2019. 3 ↩︎
Gregory Koch, Richard Zemel, and Ruslan Salakhutdinov. Siamese neural networks for one-shot image recognition. In Proc. Int. Conf. Mach. Learn. Workshop, 2015. 3 ↩︎
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning. In Proc. Adv. Neural Inf. Process. Syst., pages 3630–3638, 2016. 3 ↩︎
Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira, Yu-Chiang Frank Wang, and Jia-Bin Huang. A closer look at few-shot classification. In Proc. Int. Conf. Learn. Represent., 2019. 3 ↩︎
Spyros Gidaris and Nikos Komodakis. Dynamic few-shot visual learning without forgetting. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 4367–4375, 2018. 3 ↩︎
Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B Tenenbaum, and Phillip Isola. Rethinking few-shot image classification: a good embedding is all you need? In Proc. Eur. Conf. Comput. Vis., pages 266–282, 2020. 3 ↩︎
Moshe Lichtenstein, Prasanna Sattigeri, Rogerio Feris, Raja Giryes, and Leonid Karlinsky. Tafssl: Task-adaptive feature sub-space learning for few-shot classification. In Proc. Eur. Conf. Comput. Vis., pages 522–539. Springer, 2020. 3 ↩︎
Yuqing Hu, Vincent Gripon, and Stéphane Pateux. Leveraging the feature distribution in transfer-based few-shot learning. arXiv preprint arXiv:2006.03806, 2020. 3 ↩︎
Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Cross attention network for few-shot classification. In Proc. Adv. Neural Inf. Process. Syst., pages 4005–4016, 2019. 3 ↩︎
Baoquan Zhang, Xutao Li, Yunming Ye, and Shanshan Feng. Prototype completion for few-shot learning. IEEE Trans. Pattern Anal. Mach. Intell., 2023. 3 ↩︎
Hao Zhu and Piotr Koniusz. Transductive few-shot learning with prototype-based label propagation by iterative graph refinement. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 23996–24006, 2023. 3 ↩︎
Yikai Wang, Chengming Xu, Chen Liu, Li Zhang, and Yanwei Fu. Instance credibility inference for few-shot learning. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 12836–12845, 2020. 3, 4 ↩︎ ↩︎ ↩︎
Zhongjie Yu, Lin Chen, Zhongwei Cheng, and Jiebo Luo. Transmatch: A transfer-learning scheme for semi-supervised few-shot learning. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 12856–12864, 2020. 3 ↩︎
Antti Rasmus, Harri Valpola, Mikko Honkala, Mathias Berglund, and Tapani Raiko. Semi-supervised learning with ladder networks. arXiv preprint arXiv:1507.02672, 2015. 3 ↩︎
Chia-Wen Kuo, Chih-Yao Ma, Jia-Bin Huang, and Zsolt Kira. Featmatch: Feature-based augmentation for semi-supervised learning. In Proc. Eur. Conf. Comput. Vis., pages 479–495, 2020. 3 ↩︎
Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell., 41(8):1979–1993, 2018. 3 ↩︎
Laine Samuli and Aila Timo. Temporal ensembling for semi-supervised learning. In Proc. Int. Conf. Learn. Represent., 2017. 3 ↩︎
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proc. Adv. Neural Inf. Process. Syst., pages 1195–1204, 2017. 3 ↩︎
David Berthelot, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Kihyuk Sohn, Han Zhang, and Colin Raffel. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. In Proc. Int. Conf. Learn. Represent., 2020. 3 ↩︎ ↩︎
David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. Mixmatch: A holistic approach to semisupervised learning. In Proc. Adv. Neural Inf. Process. Syst., pages 5050–5060, 2019. 3 ↩︎
Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In Proc. Adv. Neural Inf. Process. Syst., pages 596–608, 2020. 3 ↩︎ ↩︎
Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V Le. Unsupervised data augmentation for consistency training. In Proc. Adv. Neural Inf. Process. Syst., pages 6256–6268, 2020. 3 ↩︎ ↩︎ ↩︎
Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proc. Conf. Empir. Methods Nat. Lang. Process., pages 1532–1543, 2014. 3 ↩︎
Xiangli Yang, Zixing Song, Irwin King, and Zenglin Xu. A survey on deep semi-supervised learning. arXiv preprint arXiv:2103.00550, 2021. 4 ↩︎
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Proc. Adv. Neural Inf. Process. Syst., 30, 2017. 5 ↩︎
Dengyong Zhou, Olivier Bousquet, Thomas Lal, Jason Weston, and Bernhard Scholkopf. Learning with local and global consistency. In Proc. Adv. Neural Inf. Process. Syst., pages 321–328, 2003. 5 ↩︎ ↩︎
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pages 248–255, 2009. 6 ↩︎
Boris N Oreshkin, Pau Rodriguez, and Alexandre Lacoste. Tadam: Task dependent adaptive metric for improved few-shot learning. In Proc. Adv. Neural Inf. Process. Syst., pages 719–729, 2018. 6 ↩︎

















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









