








具有代表性的全局原型的小样本学习
引用:Liu Y, Shi D, Lin H. Few-shot learning with representative global prototype[J]. Neural Networks, 2024, 180: 106600.
论文地址:下载地址
Abstract
小样本学习通常面临低泛化性能的问题,因为它假设新类别和基础类别的数据分布是相似的,而模型仅在基础类别上进行训练。为了缓解上述问题,我们提出了一种基于代表性全局原型的小样本学习方法。具体来说,为了增强对新类别的泛化能力,我们提出了一种方法,通过选择代表性和非代表性的样本,分别优化代表性全局原型,从而联合训练基础类别和新类别。此外,我们还提出了一种方法,通过条件语义嵌入有机地结合基础类别的样本,利用原始数据生成新类别的样本,从而增强新类别的数据。结果表明,这种训练方法提高了模型描述新类别的能力,改善了小样本分类的性能。在两个流行的基准数据集上进行了大量实验,实验结果表明该方法显著提高了小样本学习任务的分类能力,并达到了当前最先进的性能。
1. Introduction
深度学习的优势依赖于大数据,在大数据的驱动下,机器可以有效地进行学习。然而,数据量不足会导致一些问题,如模型过拟合,这使得模型在训练数据之外的数据集上的拟合效果不佳,表现出较弱的泛化能力。因此,小样本学习(Few-shot Learning, FSL)已成为解决这一问题的关键技术。小样本学习是指每个类别使用少量标注数据进行训练,使得模型展现出更高的性能,这符合人类学习的规律。
元学习(Meta-learning)是大多数现有小样本学习方法的基础。在元学习中,训练被建模为一种测试任务,即基础类别和新类别都从 N-way K-shot 的少量样本中学习任务,之后从基础类别中通过适当的初始条件进行知识迁移。这些方法的核心是通过嵌入或优化策略来传递知识。然而,所有这些方法都有一个根本性的局限性:模型假设基础类别数据和新类别数据的分布是相似的,因此大多数仅使用基础类别数据进行学习,而这并不保证它们能够很好地泛化到新类别的数据上。
一种小样本学习方法利用知识的可迁移性,通过少量标记样本学习表征新类别样本的能力,而传统的机器学习和深度学习在训练开始时将所有类别的样本都输入模型中。一旦数据分布的一致性较低,转移的知识就无法有效地推广到新类别的数据上。因此,学习所有类别数据的全局表示可以缓解机器学习和深度学习中基础类别过拟合的问题。新类别数据在一开始就进行学习,度量新类别数据和全局表示增强了新类别样本的判别性。同时,Wang 等人提出的样本合成策略被用来增强新类别的样本,以缓解样本不平衡问题。然而,由于全局原型是直接使用所有样本进行优化的,因此它并不具有代表性。此外,样本生成方法实际上要求基础类别数据和新类别数据具有相似的分布,这并没有打破基本的限制。最后,生成过程并没有直接参与样本训练,也无法优化生成样本的质量。
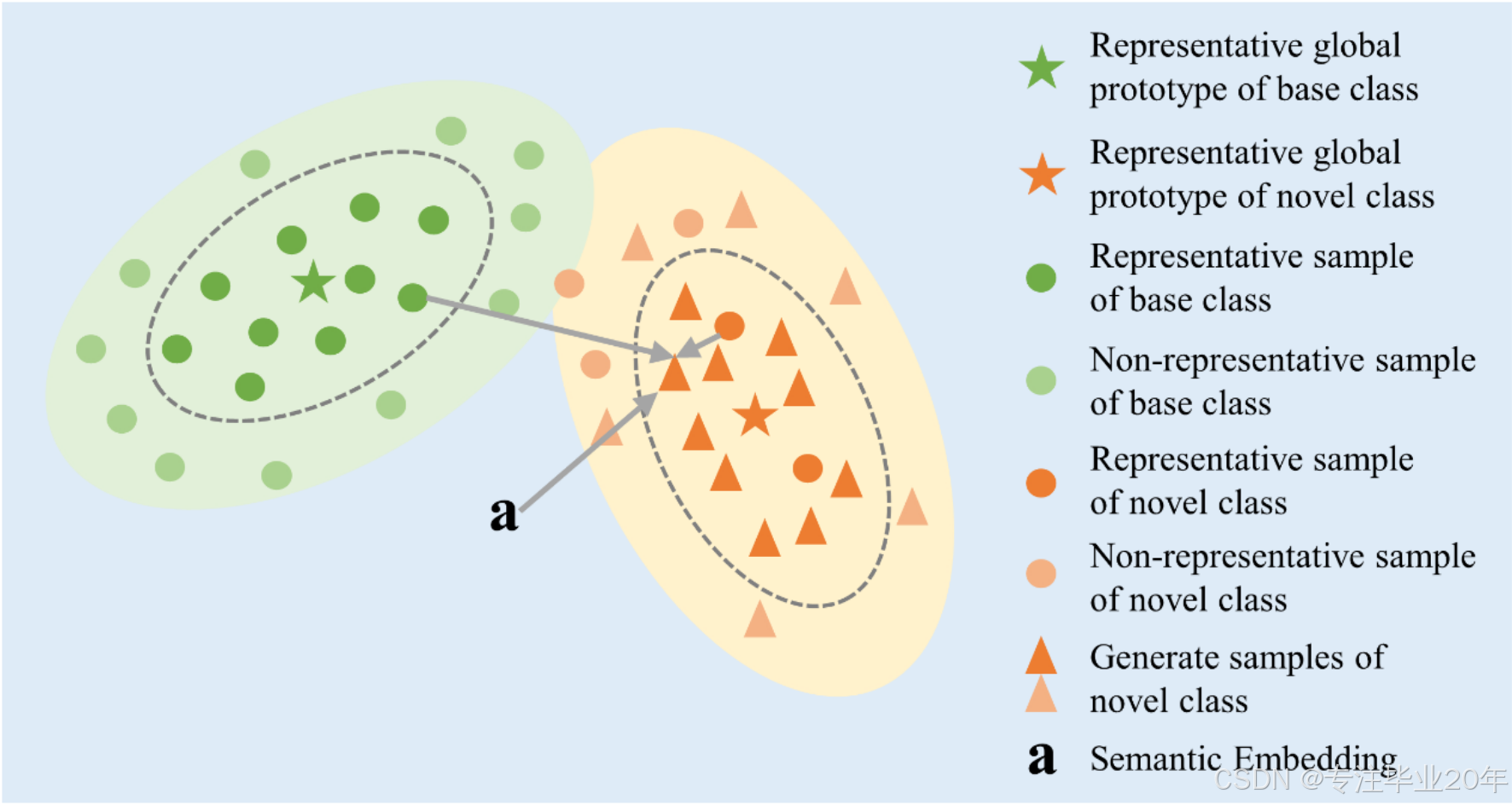
图 1:代表性全局原型的示意图。通过结合基础类的代表性样本、语义嵌入和新类样本,我们能够生成新的样本,这些样本随后用于训练代表性全局原型。
因此,我们提出了一种新的小样本学习方法,以解决小样本数据的泛化能力差和样本不平衡的问题,更好地描述新类别的数据。新类别和从基础类别中选取的代表性和非代表性数据一起输入网络,共同学习数据的表征能力,因此称为代表性全局原型。在我们看来,小样本学习模型不必满足新类别和基础类别数据分布相似的障碍,并且在训练时使用新类别数据会更适合识别新类别。 然而,尝试学习基础类别和新类别的全局原型需要克服新类别中稀疏数据的不平衡问题。为了解决基础类别和新类别数据分布之间的强相关性,我们提出了一种新的样本生成策略。具体来说,如同 Xu所述,使用 CVAE生成模型,基于语义嵌入选择更多代表性样本来为新类别生成更多代表性特征。在上述操作中,我们获得了与新类别强相关的增强数据,并将基础类别作为辅助信息。
我们的主要贡献总结如下: (1) 我们提出了一种新的小样本学习联合训练策略,通过代表性和非代表性样本打破了元学习的假设。 (2) 我们提出了一种样本合成方法来增强新类别的数据。 (3) 实验结果表明,我们的方法在 miniImageNet 和 tieredImageNet 数据集上展现了最先进的性能。
2. Related Work
2.1. Few-Shot Learning
少样本学习(Few-shot learning, FSL)在我们只有非常有限的训练样本时发挥作用。近年来,大多数深度学习方法依赖于元学习(meta-learning)或学习如何学习(learning-to-learn)策略,通过提供的数据集和元学习者在不同任务之间提取的元知识,来提升新任务的性能。具体来说,元学习者将从许多基础类别任务中学到的知识迁移,以帮助少样本学习完成新类别的训练任务。
目前,通过元学习实现的代表性少样本学习可以分为三类:基于微调的、基于度量的和基于优化的。(1)第一类方法旨在为训练新类别样本学习合适的初始化参数,从而更快更好地训练新分类器。第二类方法学习有效的度量,核心在于通过核函数学习有效的判别特征。具体来说,度量学习通过学习嵌入模块和度量模块计算两个样本之间的相似度。所有类别的样本通过嵌入模块被嵌入到向量空间中,然后基于度量模块给出相似度分数。第三类方法通过替换通用优化方法,为元学习场景适配优化器。然而,上述基于元学习的方法都有一个共同的限制:新类别的样本在训练阶段并未出现,因此模型容易在基础类别上发生过拟合。
2.2. Global Representation Learning
通过学习所有类别数据的全局表示,可以缓解模型过拟合问题。该方法旨在为新类别样本的分类学习全局表示。然而,并非所有标注样本都同样重要,非代表性的样本可能会影响全局表示的准确性。模型训练可以根据采样策略涉及不同的采样实例。大多数主流工作集中在影响决策边界的样本上,这在主动学习中更为常见,其中通过不同的不确定性度量选择影响分类的训练样本。与此不同,采样时对数据分布的代表性关注较少。在少样本学习(FSL)中,Xu 和 Le 提出了一种仅使用代表性样本来拟合全局表示的方法,但该方法忽略了数据的整体分布。因此,提出了一种代表性的全局表示方法。为了优化全局表示的代表性,生成了两个损失函数,分别使用代表性样本和非代表性样本。
2.3. Conditional Variational Autoencoder
过去,条件变分自编码器(Conditional VAE, CVAE)已被用于建模各种计算机视觉任务中的特征分布,包括图像分类、图像生成、图像恢复或视频处理。实际上,VAE模型是通过训练学习训练集的数据分布。如报告所述,VAE可以利用基础类别的数据固定参数生成新类别的数据。然而,问题在于,使用仅包含基础类别数据所学得的参数虽然适合基础类别生成更好的数据,但并不一定适合新类别数据。因此,提出了使用条件变分自编码器(CVAE)的方法,结合提取的基础类别数据的特征,并基于语义嵌入生成新类别数据的特征或图像。通过这种方式,可以利用通用语义嵌入作为基础类别与新类别之间的桥梁,更加准确地生成新类别的数据。然而,这些方法本质上仍然是在元学习的假设下进行的。因此,我们提出了一种新的样本生成策略,充分利用新类别和基础类别数据合成新数据。这种方法不依赖于基础类别数据训练的参数,同时也有助于新类别的分类。
3. Method
我们模型的关键思想是通过使用代表性样本和非代表性样本,联合学习基础类别和新类别的代表性全局原型。此外,我们还采用了一种新的样本生成策略,用于新类别,以克服样本不平衡问题。在本节中,我们将首先讨论这两个关键组件,然后回顾整个过程。
3.1. Problem Definition
在本节中,我们进行数据分配。共有 N N N 类样本,记作 Call = c 1 , c 2 , … , c N \text{Call} = { c_1, c_2, \dots, c_N } Call=c1,c2,…,cN。类别集 Call \text{Call} Call 由两个不相交的集合组成:一个是基础类别集 C base C_{\text{base}} Cbase,另一个是新类别集 C novel C_{\text{novel}} Cnovel。请注意,训练集 D train D_{\text{train}} Dtrain 中的类别来自 Call \text{Call} Call 但不属于 C base C_{\text{base}} Cbase。而测试集 D test D_{\text{test}} Dtest 的样本来自于 C novel C_{\text{novel}} Cnovel 中的类别。训练集和测试集的类别集合是互不重叠的,即 D train ∩ D test = ∅ D_{\text{train}} \cap D_{\text{test}} = \emptyset Dtrain∩Dtest=∅。在 D train D_{\text{train}} Dtrain 中,基础类别的样本有足够的标签,但新类别的样本非常有限,只有 n few n_{\text{few}} nfew( n few ≤ 5 n_{\text{few}} \leq 5 nfew≤5)个标注样本。从 D train D_{\text{train}} Dtrain 中采样 n s n_s ns 个代表性的基础类别样本和少量的新类别样本来形成一个支持集 S = ( x i , y i ) , i = 1 , … , n s × N S = { (x_i, y_i), i = 1, \dots, n_s \times N } S=(xi,yi),i=1,…,ns×N,而非代表性的样本则组成查询集 Q = ( x k , y k ) , k = 1 , … , n q × N Q = { (x_k, y_k), k = 1, \dots, n_q \times N } Q=(xk,yk),k=1,…,nq×N。
3.2. Representative Global Prototype Learning
由于仅在基础类别上训练的模型缺乏泛化能力,因此提出了一种联合训练策略,用于学习全局原型。此外,为了增强全局原型的代表性,仅使用代表性的支持集来计算全局损失,而分类损失则使用由非代表性样本组成的查询集来计算,以弥补全局原型的不完整性。
具体来说,我们使用代表性作为选择样本的标准。 S = x j ∣ p ( x j ∣ μ i , Σ i ) > ϵ S = { x_j \mid p(x_j \mid \mu_i, \Sigma_i) > \epsilon } S=xj∣p(xj∣μi,Σi)>ϵ 是通过 Xu 方法选择的基础类别训练样本的代表性集合,其中 p ( ⋅ ) p(\cdot) p(⋅) 是高斯分布 x j x_j xj 的概率密度, μ i \mu_i μi 是类别 i i i 中所有向量的均值,协方差矩阵 Σ i \Sigma_i Σi 是类别 i i i 的分布。使用一个人工阈值 ϵ \epsilon ϵ 来过滤掉低概率的样本。如果样本接近均值向量 μ i \mu_i μi,则该样本的概率 p ( ⋅ ) p(\cdot) p(⋅) 较大,从而更容易识别。为了训练全局损失,我们选择了最接近中心向量的支持集。
全局损失通过对样本的视觉特征以及各类别的全局表示进行度量来计算,这里 $ \mathcal{G} = {\mathbf{g}(i), i \in \mathcal{C}_{all}} $,其中
g
(
i
)
\mathbf{g}(i)
g(i) 是类别
i
i
i 的全局原型表示。
g
(
i
)
\mathbf{g}(i)
g(i) 的初始化为集合
S
S
S 中所有已选代表性样本的嵌入特征均值。对于每个视觉特征
x
j
\mathbf{x}_j
xj,通过度量核函数得到相似度向量
V
j
=
[
v
1
j
,
v
2
j
,
⋯
,
v
N
j
]
T
\mathbf{V}_j = [v_1^j, v_2^j, \cdots, v_N^j]^T
Vj=[v1j,v2j,⋯,vNj]T,其中第
i
i
i 个元素为类别
i
i
i 在嵌入空间中的相似度分数:
v
i
j
=
−
∥
x
j
−
g
(
i
)
∥
2
(
1
)
v_i^j = -\|\mathbf{x}_j - \mathbf{g}(i)\|_2 \quad(1)
vij=−∥xj−g(i)∥2(1)
为了使全局原型更接近一个具有较大后验概率且更易辨识的代表性样本,我们为代表性支持集中的类别
i
i
i 定义一个损失(称为全局损失):
L
g
=
C
E
(
y
j
,
V
j
)
(
2
)
\mathcal{L}_g = CE(y_j, V_j) \quad (2)
Lg=CE(yj,Vj)(2)
其中,
C
E
(
⋅
)
CE(\cdot)
CE(⋅) 为交叉熵损失函数。
接下来,我们使用代表性的全局原型作为该类别的代表,并对查询集中非代表性样本进行识别。由于非代表性样本数量众多,并且我们认为不确定性最大的样本对分类任务更有帮助,因此通过过滤掉部分样本,可降低训练成本并加快训练进程。受到最大间隔不确定性策略的启发,我们测量样本属于某一类别的最大和最小概率值。如果这两者间的差值显著增大,说明分类器对该样本属于该类别的信心更高;相反,如果差值较小,则该样本位于高斯分布的尾部,并且更难确定其类别。基于此,我们实施最大间隔不确定性标准来选择那些最难判断类别归属的样本作为查询集:
Q = { x j ∣ max { p ( y i ∣ x j ) } − min { p ( y i ∣ x j ) } < β } . ( 3 ) Q = \{\,x_j \mid \max\{p(y_i \mid x_j)\} - \min\{p(y_i \mid x_j)\} < \beta \}\,.\quad(3) Q={xj∣max{p(yi∣xj)}−min{p(yi∣xj)}<β}.(3)
一旦确定了查询集数据,我们对代表性全局原型和非代表性样本进行度量。为了在反向传播中使代表性全局原型可微分,我们使用 softmax 作为归一化函数。此时,相似度向量 V j \mathbf{V}_j Vj 会被归一化为概率分布 P j = [ p 1 j , p 2 j , ⋯ , p N j ] T \mathbf{P}_j = [p_1^j, p_2^j, \cdots, p_N^j]^T Pj=[p1j,p2j,⋯,pNj]T。
接着,根据下式更新每个类别的全局原型表示:
g new ( i ) = G P j ( 4 ) \mathbf{g}_{\text{new}}(i) = \mathbf{G} \mathbf{P}_j \quad (4) gnew(i)=GPj(4)
其中, G \mathbf{G} G 为更新前的代表性全局原型所组成的矩阵。
在查询集 Q Q Q 中,对于新的代表性全局原型与非代表性样本 x k \mathbf{x}_k xk 的相似度分数 W k = [ w 1 k , w 2 k , ⋯ , w N k ] T \mathbf{W}_k = [w_1^k, w_2^k, \cdots, w_N^k]^T Wk=[w1k,w2k,⋯,wNk]T 定义如下:
w i k = − ∥ x k − g new ( i ) ∥ 2 ( 5 ) w_i^k = -\|\mathbf{x}_k - \mathbf{g}_{\text{new}}(i)\|_2 \quad (5) wik=−∥xk−gnew(i)∥2(5)
对于查询集中非代表性样本 x k \mathbf{x}_k xk,定义分类损失为:
L c l a = C E ( y k , W k ) ( 6 ) \mathcal{L}_{cla} = CE(y_k, \mathbf{W}_k) \quad (6) Lcla=CE(yk,Wk)(6)
代表性全局原型通过对基础类与新类样本进行联合训练,并同时利用 L g \mathcal{L}_g Lg 与 L c l a \mathcal{L}_{cla} Lcla 来进行优化,从而兼顾样本分布和分类性能。与仅使用代表性样本的方法相比,我们的方法更关注数据分布的完整性。通过简单的样本选择策略,我们在相较于使用全部样本的方法中减少了训练数据量。接下来,我们通过联合生成损失来进一步优化代表性全局原型。
3.3. Feature Generation with CVAE
我们提出了一种样本生成策略,以在不依赖元学习假设的情况下为新类生成样本,从而解决由于数据有限(小样本)导致的样本不平衡问题。本文中,特征生成分为两个步骤:(1) 从基础类的原始样本和语义属性中生成新类的特征;(2) 将第一步获得的全部特征与新类的原始特征用于合成新的特征。
具体而言,我们将基础类数据和语义嵌入相结合,通过 CVAE 模型生成新的特征。将选出的代表性样本作为条件输入 CVAE 模型并结合语义嵌入生成更具代表性的特征,其生成损失函数定义为:
L C V A E = ∑ i = 1 C b a s e ∑ x ⊆ S K L ( q ( z ∣ x , a i ) ∥ p ( z ∣ a i ) ) − E q ( z ∣ x , a i ) [ log p ( x ∣ z , a i ) ] ( 7 ) \mathcal{L}_{CVAE} = \sum_{i=1}^{C_{base}}\sum_{\mathbf{x}\subseteq S} KL\bigl(q(\mathbf{z}\mid \mathbf{x}, \mathbf{a}_i)\|p(\mathbf{z}\mid \mathbf{a}_i)\bigr) - \mathbb{E}_{q(\mathbf{z}\mid \mathbf{x},\mathbf{a}_i)}[\log p(\mathbf{x}\mid \mathbf{z}, \mathbf{a}_i)] \quad (7) LCVAE=i=1∑Cbasex⊆S∑KL(q(z∣x,ai)∥p(z∣ai))−Eq(z∣x,ai)[logp(x∣z,ai)](7)
其中, a i \mathbf{a}_i ai 为类别 i i i 的语义嵌入,这些语义嵌入是对类别的自然语言描述,包含类别信息的属性向量。第一个项为正则化项,通过 Kullback-Leibler 散度将变分分布 q ( z ∣ x , a ) q(\mathbf{z}\mid \mathbf{x}, \mathbf{a}) q(z∣x,a) 与先验分布 p ( z ∣ a ) p(\mathbf{z}\mid \mathbf{a}) p(z∣a) 对齐。第二个项为重构损失,旨在使从编码器得到的 z \mathbf{z} z,通过解码器 p ( x ∣ z , a ) p(\mathbf{x}\mid \mathbf{z}, \mathbf{a}) p(x∣z,a) 所重建的特征尽可能接近原始输入特征。这里假设 N ( 0 , I ) N(0, I) N(0,I) 为先验分布。
关于生成新类特征 x j ′ \mathbf{x}'_j xj′ 的方法,我们将每个新类的语义嵌入 a i \mathbf{a}_i ai 和潜变量 z \mathbf{z} z 输入解码器,以获得对应类的新特征。
对原始基础类样本使用该方法后,我们可为每个新类获得共计 k t k_t kt 个样本。此后,我们继续从每个类的 k t k_t kt 个样本中合成新特征。为增强生成特征 x j ′ \mathbf{x}'_j xj′ 的可区分性,我们计算 x j ′ \mathbf{x}'_j xj′ 与全局表示 g ( i ) \mathbf{g}(i) g(i) 的相似度,记为: U j = [ u 1 j , u 2 j , ⋯ , u t j ] T \mathbf{U}_j = [u_1^j, u_2^j, \cdots, u_t^j]^T Uj=[u1j,u2j,⋯,utj]T,其中
u i j = − ∥ x j ′ − g ( i ) ∥ 2 ( 8 ) u_i^j = -\|\mathbf{x}'_j - \mathbf{g}(i)\|_2 \quad (8) uij=−∥xj′−g(i)∥2(8)
请注意,这里只选择与新类最相似的得分。
为获得最终的增强特征 x ^ j \hat{\mathbf{x}}_j x^j,对相似度得分 U j \mathbf{U}_j Uj 使用 softmax 归一化为 P n o v e l = [ p 1 j , p 2 j , ⋯ , p t j ] T \mathbf{P}_{novel} = [p_1^j, p_2^j, \cdots, p_t^j]^T Pnovel=[p1j,p2j,⋯,ptj]T,并将其作为权重加入到生成特征 x j ′ \mathbf{x}'_j xj′ 与原始全局原型表示中:
x ^ j = g ( i ) + x j ′ P n o v e l , i ∈ C n o v e l ( 9 ) \hat{\mathbf{x}}_j = \mathbf{g}(i) + \mathbf{x}'_j \mathbf{P}_{novel}, \quad i \in \mathcal{C}_{novel} \quad(9) x^j=g(i)+xj′Pnovel,i∈Cnovel(9)
通过上述操作,我们在以基础类为辅助信息的前提下获得了与新类强相关的增强数据。最后,将新类中的 x ^ j \hat{\mathbf{x}}_j x^j 和原始基础类的 x j \mathbf{x}_j xj 一同输入模型,以优化代表性全局原型。
3.4. Model Review
我们将整个模型划分为两个部分(如图 2 所示):代表性全局原型学习和样本生成。基础类、新类以及其语义嵌入被同时利用来为新类生成数据。随后,通过联合训练新类与基础类的数据,以优化全局表示。同时,对代表性样本进行训练,从而优化代表性全局原型。整个模型的损失函数如下所示:
L t o t a l = L g + L c l a + L C V A E ( 10 ) \mathcal{L}_{total} = \mathcal{L}_g + \mathcal{L}_{cla} + \mathcal{L}_{CVAE} \quad (10) Ltotal=Lg+Lcla+LCVAE(10)
在测试阶段,我们采用相同的步骤对
C
n
o
v
e
l
\mathcal{C}_{novel}
Cnovel 中未标记数据进行预测。为了增加新类中的样本数量,我们使用样本生成策略。接下来,我们计算测试样本的特征向量与新类代表性全局原型之间的欧氏距离,并进行最近邻搜索来预测其标签。
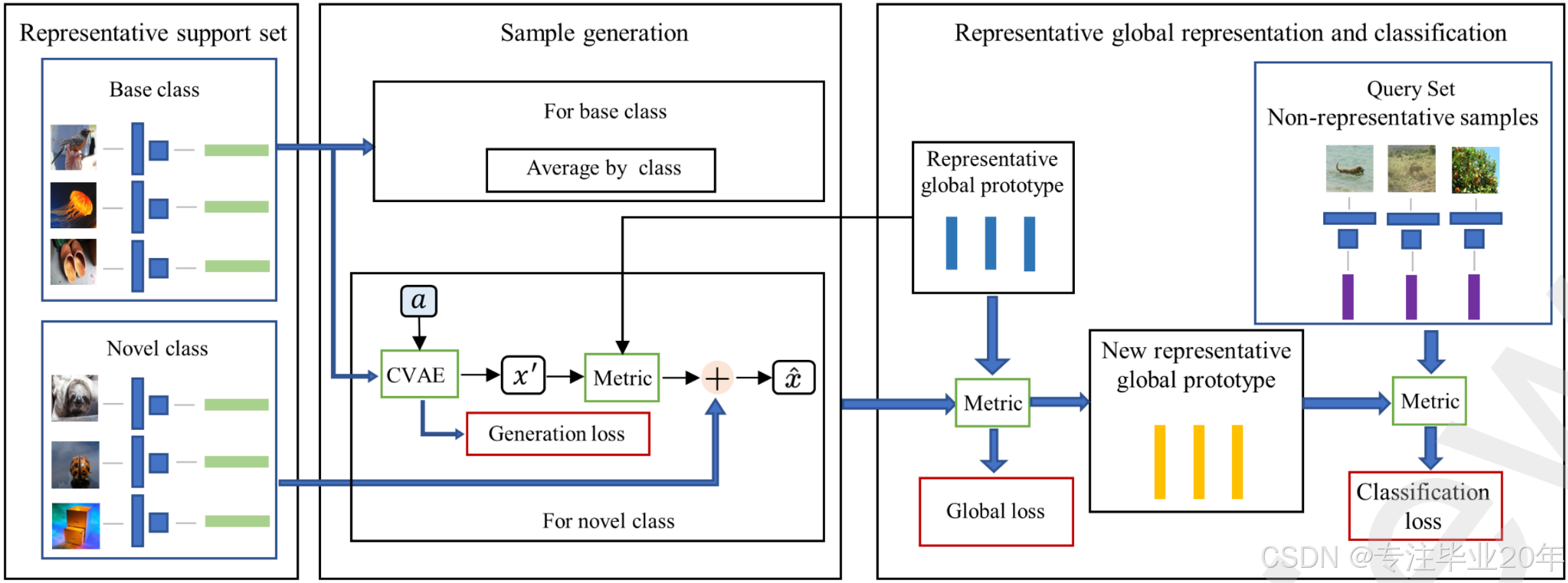
图 2:概述。首先,我们提出了一种样本生成方法,用于在代表性支持集中生成新类的新样本。其次,根据每个类别特征与代表性全局原型的相似度分数更新代表性全局原型,新的代表性全局原型和非代表性样本随后用于对查询图像进行分类。查询图像的分类损失、全局损失和生成损失被用于联合优化全局表示和生成模块。
4. Experiments
在本章节中,我们将在 miniImageNet 和 tieredImageNet 两个数据集上对我们的方法与当前最先进的多种方法进行评估和比较。首先,我们将详细介绍实验设置。随后,我们会将所提出的方法与多种最新的小样本方法进行对比,以验证其有效性。最后,我们对实验结果进行分析和讨论。
4.1. Datasets
miniImageNet 数据集 Vinyals 等人 (2016) 是从大规模数据集 ImageNet 中精选而成的一个较轻量子集。该数据集包含总计 60,000 张 84×84 尺寸的彩色图像。这些图像共来自 100 个类别,每个类别包含 600 张图像。数据集根据标签划分为三个部分:训练集包含 64 个类别,验证集包含 16 个类别,其余 20 个类别作为测试集。
tieredImageNet 数据集 Ren 等人 (2018) 同样是从 ImageNet 中抽取而来,与 miniImageNet 类似。与 miniImageNet 不同的是,tieredImageNet 按照层次结构对 ImageNet 的类别进行了抽样和分组,以更广泛的类别级别进行数据划分,图像的分辨率同样为 84×84。tieredImageNet 总共包含 608 个类别,这些类别来自 34 个更高层级的类别群,每个更高层级类别群内包含 10 至 30 个类别。其中,20 个大类(共计 351 个具体类别)用于训练集,6 个大类(97 个具体类别)用于验证集,其余 8 个大类(160 个具体类别)用于测试集。
4.2. Detail Settings
在进行全局训练之前,我们使用来自基础类的数据对基于 ResNet-12 的特征提取器进行预训练,从最终层输出特征表示。随后,利用特征提取器对各类别的所有样本视觉特征求均值,以此初始化代表性全局原型。我们采用 Adam 优化器,并将学习率设定为 1 0 − 4 10^{-4} 10−4 来训练整个网络。潜在空间的维度和语义向量的维度均设置为 512。
我们的语义嵌入使用 word2vec 从 Wikipedia 语料库中训练得出,采用 skip-gram 模型。对于支持集和查询集中的图像,我们使用相同的特征提取器。在实验中,我们将 α \alpha α 设置为 0.9, β \beta β 设置为 0.1。
4.3. Results
我们与当前最先进的小样本学习方法进行了对比,其中,我们的方法与 Xu and Le (2022) 最为相关。为保证公平性,所有方法使用的特征提取器层数相近,即使用 ResNet-12 和 ResNet18。在接下来的描述中,我们将使用全部数据训练全局原型的模型称为 GP,而使用选择出的代表性和非代表性数据进行训练的模型称为 RGP,只使用代表性数据但不使用非代表性数据的模型称为 RGP w/o。
表 1 展示了在数据集上进行 5-way k-shot (k = 1 或 5) 分类的结果。结果表明,我们的方法优于当前最先进的方法,尤其是对比结合 CLIP 且使用代表性样本的 R-SVAE。此外,选用代表性样本与部分非代表性样本的策略不仅没有降低模型的分类性能,相反,RGP 相较于使用全部训练数据的 GP 在性能上还有轻微提升。例如,RGP 在 miniImageNet 数据集的 1-shot 分类中较 GP 提高了 0.5%。为了验证非代表性数据的影响,我们对比了 RGP w/o(无非代表性数据)与 RGP(有非代表性数据)。实验结果显示,RGP 略优于 RGP w/o。
表1 在 miniImageNet 和 tieredImageNet 上的 5-way 小样本分类准确率 (%)
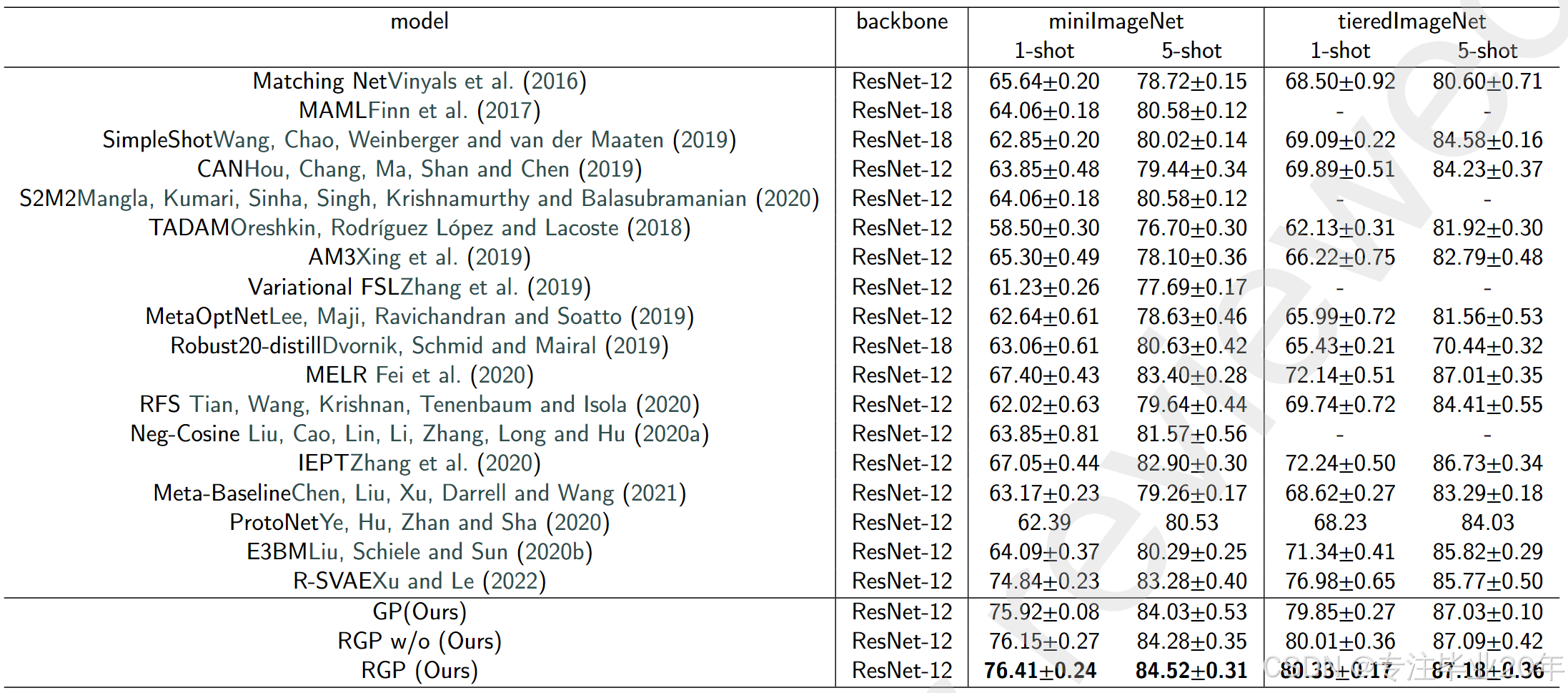
另一个有趣的发现是,在分类任务中,5-shot 的表现不如 1-shot。RGP 相较于已有的最先进方法在 1-shot 上提升了约 1.18% ∼ 3.34%,在 5-shot 上提升了约 0.2% ∼ 1.14%。由于我们的方法将所有类别同时进行训练,因此不必过于担心基础类分布与新类分布的差异。不过,为了验证 RGP 在基础类与新类差异较大时的表现,我们对数据集重新进行了划分。根据基础类与新类原型的相似度(0-1),将数据集分为 9 个等级。正如图 3 所示,当基础类与新类之间存在较大差异时,RGP 的性能优于 R-SVAE Xu and Le (2022)和 GCR Li et al. (2019)。此外,随着相似度曲线的增大,RGP 的表现更加稳定,表明 RGP 受数据分布影响较小。

图 3:在 tieredImageNet 数据集上,不同相似度等级下基础类与新类的 5-way 性能表现。
4.4. Visualization
在训练过程中,图 4 展示了在 tieredImageNet 数据集上使用不同方法生成数据的过程。图 4 的每幅子图中都展示了三个新类的特征,这些特征经过 t-SNE 映射到 2D 空间中。图 4 (d) 显示了我们的合成策略的合理性和有效性,因为与仅使用 CVAE 的方法(如图 4 © 所示)相比,我们的方法所生成的特征更接近真实特征。
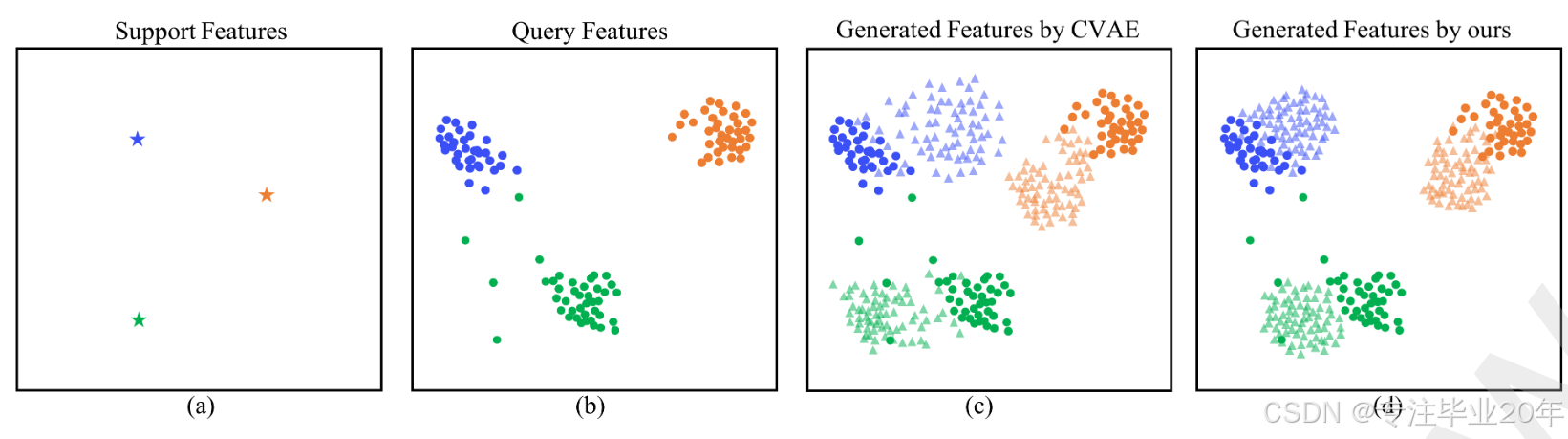
图 4:特征可视化。我们对原始数据和生成数据的特征进行了可视化。透明点为生成的特征,不透明点为原始特征。(a):支持集特征。(b):查询集特征。©:由 CVAE 生成的特征。(d):由我们的方法生成的特征。
根据不同的选择标准,图 5 展示了代表性样本和非代表性样本。代表性样本更接近分布中心,因此具有更高的概率并包含主要的干净特征,更易于识别。而在分布尾部选择的样本被分配较低的概率,这类样本可能包含其他类别的相关特征,因此更容易被误分类或难以识别。
4.5. Ablation Study
我们的主要实验包含四个部分的样本合成过程。在消融实验中,我们将仅使用单一步骤的合成策略与我们的方法进行对比,包括:使用 VAE 的生成策略、利用语义嵌入为条件的 CVAE 生成策略以及不使用合成策略的方法 RGP(NSS)。
表 2 展示了在 miniImageNet 和 tieredImageNet 数据集上,不同样本生成策略在 1-shot 设置下的分类性能。结果表明,基于 VAE 的方法仅固定使用由基础类训练得到的参数,相较于使用嵌入语义信息、可跨越不同分布的 CVAE,效果较差。RGP(NSS) 则只是在 CVAE 后使用生成特征,但没有加入新类数据。最终,这两种方法的分类性能都不如我们所提出的,不依赖相似分布假设的方法。

表2:在 miniImageNet 和 tieredImageNet 上,不同生成方法的 1-shot 分类准确率 (%)
5. Conclusion
本文提出了一种具有代表性全局原型的新型小样本学习框架,以缓解泛化能力不足的问题。为获得在新类性能上具有强泛化能力的代表性全局原型,我们提出了一种联合训练策略,即在代表性与非代表性数据上同时对基础类与新类进行训练。其次,为了缓解联合训练中的样本不平衡问题,我们提出了一种基于语义嵌入、将基础类与新类结合起来的样本合成策略,该策略不受元学习中强假设的限制。最后,我们结合三种损失函数共同训练整个模型。实验结果表明,我们的方法优于现有的小样本方法。未来工作中,我们将进一步探索不同样本选择方法对模型分类性能的影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









