








多粒度知识融合与决策
引用:Su Y, Zhao H, Zheng Y, et al. Few-shot Learning with Multi-Granularity Knowledge Fusion and Decision-Making[J]. IEEE Transactions on Big Data, 2024.
论文地址:下载地址
github:https://github.com/fhqxa/MGKFD
Abstract
Few-shot learning (FSL) 是一项具有挑战性的任务,旨在从少量标记样本中对新类别进行分类。许多现有模型将类别的结构知识作为先验知识嵌入,以增强FSL对数据稀缺的适应能力。然而,这些方法在连接类别结构知识与有限视觉信息方面表现不足,而视觉信息在FSL模型性能中起着决定性作用。本文提出了一种结合多粒度知识融合与决策的统一FSL框架(MGKFD),以克服这一局限性。我们旨在同时探索视觉信息和结构知识,以互为补充的方式增强FSL。一方面,我们通过多粒度类别知识强关联全局和局部视觉信息,以探索图像内部和类别之间的关系,从有限图像中生成特定的多粒度类别表示。另一方面,引入一种权重融合策略,将多粒度知识与视觉信息整合起来,做出FSL分类决策。这使得模型能够从有限的标记样本中更高效地学习,并能够推广到新类别。此外,针对不同程度的错误预测,基于结构知识构建了一种层次化损失函数,以最小化分类损失,其中对更大程度的错误分类给予更高的惩罚。实验结果表明,在三个基准数据集上,MGKFD相较于多个先进模型具有明显优势。
1. INTRODUCTION
少样本学习(FSL) 是机器学习领域的一个重要且热门的研究课题,其目标是在少量样本的情况下识别新类别 1。由于仅有一个或少量样本,这对机器学习的泛化能力提出了挑战。2000年,Miller等人首次提出了从极少样本中学习的问题 2。此后,越来越多的研究工作投入到FSL的探索中。近年来,FSL模型已经广泛应用于计算机视觉、自然语言处理和数据分析等多个研究领域 3 4。
FSL的关键目标是建立基础类别知识与新类别识别之间的联系,并使用少量数据有效地识别新类别。在FSL的方法中,度量学习是主要的研究方向之一,其致力于寻找一个最佳的相似性度量空间,以弥合基础类别与新类别之间的差距 5。例如,Matching Network 6、Prototypical Network 7 和 Relation Network 8 等经典FSL模型,分别利用余弦距离、欧几里得距离或可学习模块来构建基础类别与新类别的公共度量空间。
此外,Zhang等人 9 发现,仅计算两个全局特征之间的距离可能会受到复杂背景和类别内部外观变化较大的影响。因此,他们利用地球移动距离(Earth Mover’s Distance)最小化两个样本间局部特征的匹配成本。有别于单尺度建模,一些学者进一步从多尺度角度进行研究,以挖掘更多潜在信息 10 11 12。例如,Jiang等人 10 提取多尺度特征并学习样本之间的多尺度关系用于FSL。同样,提出了一个双相似度网络(Bi-similarity Network),通过两种相似性度量获取判别性特征图 11。这些模型无论从单尺度还是多尺度出发,意在挖掘数据中的视觉信息,但它们无法满足FSL发展的需求。它们未能充分捕获和利用数据结构知识中潜在的信息。
数据的结构知识通常涉及不同类别之间的内在关系和依赖性,这能够弥补FSL中的数据稀缺问题 13 14。例如,层次类别结构(hierarchical class structure)展示了细粒度与粗粒度类别之间的多粒度关联,为FSL提供了重要的外部知识指导 15 16 17。Li等人 17 利用类别层次结构作为先验知识构建了一个粗到细的FSL分类器。同样,Zhang等人 18 采用层次结构设计了一个可解释的基于决策树的分类器。然而,尽管这些模型取得了一定的成果,但它们未能在视觉数据和结构知识之间建立一致的联系,特别是在有限数据的情况下。这些研究主要集中于如何将结构信息嵌入到FSL中,而未充分利用数据的视觉信息,而视觉信息在增强FSL中起着同等重要的作用。
在本文中,我们提出了一种基于多粒度知识融合与决策(MGKFD)的新型少样本学习(FSL)模型,该模型将来自图像和类别层次的视觉信息和结构知识进行连接。我们致力于同时挖掘丰富的视觉信息和结构知识,并以互为补充的方式服务于FSL。具体而言,MGKFD主要分为两部分:多粒度特征提取以及多粒度知识融合与决策。
对于一幅图像,该模型显式表示类别特定和详细的信息,其中全局特征是图像内容的粗略表示,而局部特征更擅长捕捉图像中物体的区分性信息。同样地,在层次类别结构中,粗粒度类别具有更高的泛化性能,而细粒度类别通常具有较少的特征多样性。因此,我们最初将全局特征表示为粗粒度类别的表示,而将局部特征视为细粒度类别的表示。这使得我们能够同时研究图像内部和类别间的关系,从而在少量样本图像中生成清晰的类别表示。
接下来,我们融合多粒度知识以指导FSL分类决策。粗粒度类别的表示和判别性知识与细粒度类别强相关,这对于细粒度类别的学习具有重要价值。通过这种方式,我们引入了一种融合策略,将多粒度知识整合用于最终的FSL决策。此外,我们提出了一种层次化损失函数,用于最小化分类错误。该损失函数根据由结构知识引导的错误分类程度分配不同的分类风险,而不是假设分类错误是等权重的通用损失函数。总而言之,我们旨在显式利用结构知识,结合有限的视觉信息,从而最终提高FSL任务的模型性能。
为了验证MGKFD的性能,我们在多个公开数据集上进行了大量实验。实验结果从不同的角度证明了我们的模型相较于几种先进的FSL模型的有效性。本文的主要贡献总结如下:
- 我们提出了一种新的少样本学习框架,通过显式连接丰富的类别结构知识与有限的视觉信息,用于FSL分类决策。
- 我们设计了一种融合策略,以整合多粒度知识,从而降低比粗到细决策方式的跨层错误传递风险。
- 提出了一种层次化损失函数,区别于假设分类错误等权重的通用损失函数,该损失函数为不同程度的分类错误分配不同的权重。
在后续章节中,我们在第二部分简要回顾了相关工作;接着在第三部分介绍了所提模型;随后在第四部分介绍了实验设置;在第五部分报告并分析了实验结果;最后在第六部分总结了本文的结论以及未来研究方向。
2. RELATED WORK
在本节中,我们将简要介绍与我们研究相关的工作,包括少样本学习以及基于结构知识的少样本学习。
2.1. Few-Shot Learning
少样本学习(FSL)模型通常基于元学习(meta-learning),旨在从少量数据中学习可迁移的知识以应用于新任务 19。现有模型可以分为三种类型:
第一,数据增强是一种有效的方法,可以增加训练样本或增强数据特征 5。它通过增加数据量来解决数据不足的问题。
第二,一些学者专注于优化模型以解决少样本学习问题,而无需数据增强,这被称为基于优化的方法(optimization-based method)。其目标是在少量支持样本的情况下,快速在线更新模型,例如MAML 20 和 MetaOptNet 20。
第三种方法是度量学习(metric learning),其目标是学习查询图像与支持图像之间的相似性 8。例如,FSL中首先采用了余弦距离和欧几里得距离来测量图像相似性 6 7。此外,Kang等人 21 利用了图像内部和图像之间的关系模式来测量其相似性。另外,为了避免复杂背景和较大的类别内部外观变化的影响,Zhang等人 9 使用地球移动距离(Earth Mover’s Distance)通过最小匹配成本来测量图像相似性。
与单尺度度量学习不同,许多学者进一步从多尺度的角度构建FSL模型 10 11 12。在特征方面,Jiang等人 10 提出了一种多尺度关系生成网络,用于学习样本之间的多尺度关系。在度量角度,提出了双相似度网络(Bi-similarity Network),通过两种相似度度量获取判别性特征图 11。无论是从单尺度还是多尺度的角度,这些模型都专注于利用数据中潜在的视觉信息,但它们无法挖掘类别之间潜在的结构知识。
2.2. Few-Shot Learning Based on Structural Knowledge 基于结构知识的少样本学习
类别中固有的结构知识提供了强大的类别语义信息,许多研究利用层次类别结构应用于少样本学习(FSL),得益于其在层次分类中的优异性能 22 23。层次结构主要根据WordNet 14 中的多粒度语义关联构建。它展示了细粒度与粗粒度类别在多个粒度层次上的关联性,可以作为指导FSL过程的重要外部资源 24 25。
在特征表示学习方面,Zhu等人 16 提出了由层次结构引导的多粒度情景对比学习。一些模型利用层次结构来辅助FSL分类器的构建。例如,Li等人 15 通过聚类层次结构为大规模FSL分类学习可迁移的视觉特征。此外,文献 17 中通过层次结构实现了粗到细的FSL分类器。同样,Zhang等人 18 设计了一种基于决策树的可解释分类器。
尽管上述模型取得了令人鼓舞的成功,但它们未能将类别结构知识与有限的视觉信息建立起联系。对于少样本学习而言,有限视觉信息的学习对模型性能起着决定性作用。本文的目标是建立类别的视觉信息与结构知识之间的强连接与协同作用,以增强FSL。在类别结构知识的引导下,我们整合了全局与局部视觉信息,以探索图像内部和类别间的关系,从而使模型能够学习到更具区分性的类别信息。通过整合视觉信息与类别结构知识来引导分类决策,模型能够有效地从有限的标注样本中学习,并在新类别上实现更高的泛化精度。
不同于“粗到细”分类器,融合策略能够缓解跨层错误传递问题。此外,这些模型通常假设目标学习中遇到的分类错误是等同的,仅考虑预测是否正确。而在实际应用中,不同的分类结果应具有不同的分类风险。因此,在结构知识的引导下,提出了一种层次化损失函数,根据层次结构分配不同的权重来最小化分类错误的程度。
总之,我们致力于同时研究视觉信息和结构知识,以互为补充的方式来增强小样本学习。
3. PROPOSED MODEL
在本节中,我们详细介绍了MGKFD,框架如图1所示。MGKFD主要分为两个部分:首先,我们将全局特征划分为五个局部特征,并根据层次结构获取多粒度特征。其次,我们融合多粒度知识与丰富的视觉信息,用于相似性度量和FSL分类决策。此外,还建立了一种层次化损失函数,以最小化分类错误。
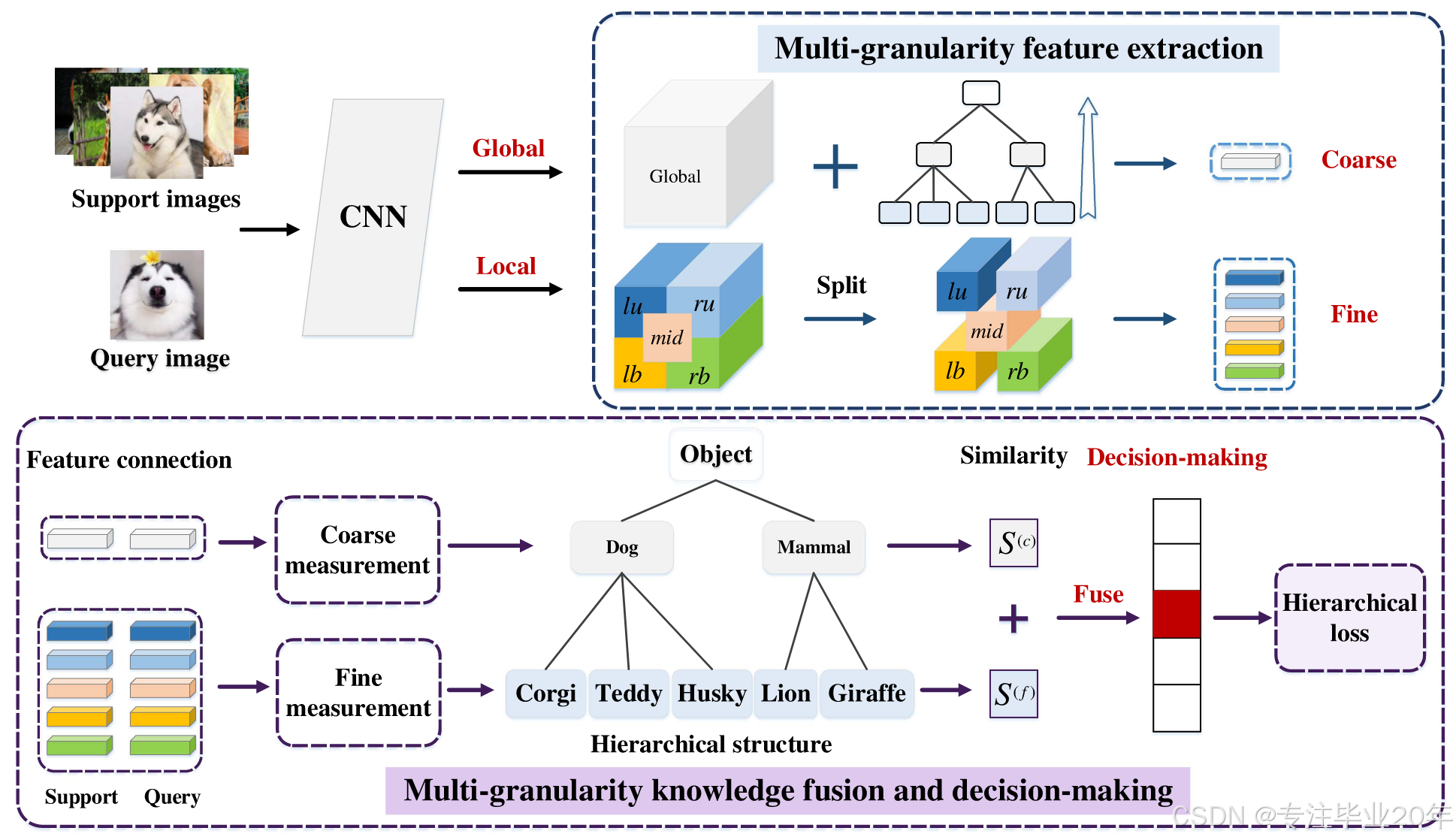
图 1. MGKFD 框架:MGKFD 主要由两部分组成:多粒度特征提取和多粒度知识融合与决策。参数
l
u
lu
lu、
r
u
ru
ru、
m
i
d
mid
mid、
l
b
lb
lb 和
r
b
rb
rb 分别表示左上、右上、中间、左下和右下区域的局部特征;
S
(
c
)
S^{(c)}
S(c) 和
S
(
f
)
S^{(f)}
S(f) 分别表示粗粒度和细粒度的相似性。
3.1. Multi-Granularity Feature Extraction 多粒度特征提取
在本节中,我们结合全局特征与局部特征,以及层次类别结构中不同粒度类别的相关性,获取多粒度特征。
许多现有的少样本学习方法直接利用卷积神经网络(Convolutional Neural Network, CNN)提取的特征进行图像相似性度量,并取得了有效的结果。然而,这些方法存在以下两个缺点: 1) CNN提取的特征代表图像的混合全局特征,这些特征模糊且不适合细粒度分类。 2) 混合全局特征会降解并丢失图像的局部特征,难以区分图像之间的细微差异。 我们从数据集 tieredImageNet 26 中随机提取了10,000张图像,并分析了图像中主要目标的位置分布,如图2(a)所示。主要目标主要分布在图像的中间,其余分布在四周。因此,我们从全局特征中重新提取局部特征,将全局特征均匀裁剪为五个区域,包括左上(lu)、右上(ru)、中间(mid)、左下(lb)和右下(rb)区域,如图2(b)所示。每个区域的长度为全局长度的一半。

图 2. 图像中目标中心位置的分布:参数
l
u
lu
lu、
r
u
ru
ru、
m
i
d
mid
mid、
l
b
lb
lb 和
r
b
rb
rb 分别表示左上、右上、中间、左下和右下局部区域。
对于少样本任务,在元学习框架下采用“
N
N
N-way
K
K
K-shot”的训练任务策略,该策略由支持集和查询集组成。支持集包含从训练集
D
train
D_{\text{train}}
Dtrain 中随机选择的
N
N
N 个类别的
K
K
K 个标记样本,其余
K
′
K'
K′ 个样本构成
N
N
N 个类别的查询集。 最初,令支持集为
S
=
{
(
x
1
,
y
1
)
,
…
,
(
x
n
s
,
y
n
s
)
}
S = \{(x_1, y_1), \dots, (x_{n_s}, y_{n_s})\}
S={(x1,y1),…,(xns,yns)},查询集为
Q
=
{
(
x
~
1
,
y
~
1
)
,
…
,
(
x
~
n
q
,
y
~
n
q
)
}
Q = \{(\tilde{x}_1, \tilde{y}_1), \dots, (\tilde{x}_{n_q}, \tilde{y}_{n_q})\}
Q={(x~1,y~1),…,(x~nq,y~nq)},其中
x
n
s
x_{n_s}
xns 和
x
n
q
x_{n_q}
xnq 分别为支持集和查询集中的样本数量。对于 1-shot (
K
=
1
K=1
K=1) 的设置,每个支持样本的特征代表其所属类别的特征。假设
x
~
i
\tilde{x}_i
x~i 和
x
j
x_j
xj 分别为查询集
Q
Q
Q 和支持集
S
S
S 中的任意样本,定义特征提取的 CNN 为
F
ϕ
F_\phi
Fϕ,其中
ϕ
\phi
ϕ 为 CNN 的参数。将
x
~
i
\tilde{x}_i
x~i 和
x
j
x_j
xj 输入到
F
ϕ
F_\phi
Fϕ,可得到全局特征:
X
~
i
(
g
)
=
F
ϕ
(
x
~
i
)
,
X
j
(
g
)
=
F
ϕ
(
x
j
)
,
(1)
\tilde{X}_i^{(g)} = F_\phi(\tilde{x}_i), \quad X_j^{(g)} = F_\phi(x_j),\tag{1}
X~i(g)=Fϕ(x~i),Xj(g)=Fϕ(xj),(1)
其中
X
~
i
(
g
)
\tilde{X}_i^{(g)}
X~i(g) 是查询样本
x
~
i
\tilde{x}_i
x~i 的全局特征,
X
j
(
g
)
X_j^{(g)}
Xj(g) 是第
j
j
j 个支持类别的全局特征。对于
K
K
K-shot (
K
>
1
K > 1
K>1) 的设置,我们使用结构化全连接层 9 来为每个类别的所有样本学习更优的全局类别特征。
然后,我们将全局特征裁剪为五个局部区域,以提取局部特征,如下所示:
X
~
i
(
l
)
=
[
L
~
i
(
l
u
)
;
L
~
i
(
r
u
)
;
L
~
i
(
m
i
d
)
;
L
~
i
(
l
b
)
;
L
~
i
(
r
b
)
]
,
X
j
(
l
)
=
[
L
j
(
l
u
)
;
L
j
(
r
u
)
;
L
j
(
m
i
d
)
;
L
j
(
l
b
)
;
L
j
(
r
b
)
]
,
(2)
\begin{aligned} \tilde{X}^{(l)}_i &= [\tilde{L}^{(lu)}_i ; \tilde{L}^{(ru)}_i ; \tilde{L}^{(mid)}_i ; \tilde{L}^{(lb)}_i ; \tilde{L}^{(rb)}_i], \\ X^{(l)}_j &= [L^{(lu)}_j ; L^{(ru)}_j ; L^{(mid)}_j ; L^{(lb)}_j ; L^{(rb)}_j], \tag{2} \end{aligned}
X~i(l)Xj(l)=[L~i(lu);L~i(ru);L~i(mid);L~i(lb);L~i(rb)],=[Lj(lu);Lj(ru);Lj(mid);Lj(lb);Lj(rb)],(2)
其中,
X
~
i
(
l
)
\tilde{X}^{(l)}_i
X~i(l) 是查询样本
x
~
i
\tilde{x}_i
x~i 的局部特征,
X
j
(
l
)
X^{(l)}_j
Xj(l) 表示第
j
j
j 个支持类别的局部特征。
L
~
i
(
l
u
)
\tilde{L}^{(lu)}_i
L~i(lu)、
L
~
i
(
r
u
)
\tilde{L}^{(ru)}_i
L~i(ru)、
L
~
i
(
m
i
d
)
\tilde{L}^{(mid)}_i
L~i(mid)、
L
~
i
(
l
b
)
\tilde{L}^{(lb)}_i
L~i(lb) 和
L
~
i
(
r
b
)
\tilde{L}^{(rb)}_i
L~i(rb) 分别是查询样本
x
~
i
\tilde{x}_i
x~i 的五个局部特征,而
L
j
(
l
u
)
L^{(lu)}_j
Lj(lu)、
L
j
(
r
u
)
L^{(ru)}_j
Lj(ru)、
L
j
(
m
i
d
)
L^{(mid)}_j
Lj(mid)、
L
j
(
l
b
)
L^{(lb)}_j
Lj(lb) 和
L
j
(
r
b
)
L^{(rb)}_j
Lj(rb) 是第
j
j
j 个支持类别的五个局部特征。总结而言,我们可以获得
x
~
i
\tilde{x}_i
x~i 和第
j
j
j 个支持类别的全局-局部特征:
X
~
i
=
[
X
~
i
(
g
)
;
X
~
i
(
l
)
]
,
X
j
=
[
X
j
(
g
)
;
X
j
(
l
)
]
.
(3)
\begin{aligned} \tilde{X}_i &= [\tilde{X}^{(g)}_i ; \tilde{X}^{(l)}_i], \\ X_j &= [X^{(g)}_j ; X^{(l)}_j]. \tag{3} \end{aligned}
X~iXj=[X~i(g);X~i(l)],=[Xj(g);Xj(l)].(3)
视觉表示可以显式捕捉重要的特征和属性,有助于理解和识别对象或概念。全局特征包含图像内容的粗略表示,而局部特征能够捕捉图像的区分性信息。然而,由于训练数据的稀缺,模型容易陷入次优状态,并且泛化能力有限。另一方面,结构知识是关于类别的组织化信息,通常以层次化或关系化的形式表示。像层次类别结构这样的结构知识可以指导模型学习类别之间的相似性和差异性,即使在少量样本的情况下,也能够提升模型的泛化能力和区分能力。在层次类别结构中,粗粒度类别包含其所属多个细粒度类别的共性,与细粒度类别相比,它更加粗略;而细粒度类别揭示了类别之间的差异性 25。层次结构由粗粒度和细粒度类别组成,是基于类别之间的多粒度关联构建的 14。多粒度关联通常通过测量 WordNet 中任意两个类别的语义相似性获得。
因此,我们利用层次结构结合全局与局部特征,探索更具区分性的特征嵌入。我们将全局特征表示为粗粒度类别特征,将局部特征表示为细粒度类别特征。对于查询样本,我们将全局特征定义为粗粒度特征,局部特征定义为细粒度特征。对于支持集,我们将局部特征定义为细粒度特征,而粗粒度类别特征通过其细粒度类别的全局特征的平均值计算,如下所示:
X
(
c
i
)
=
1
m
c
i
∑
k
=
1
m
c
i
X
k
(
g
)
,
(4)
X^{(c_i)} = \frac{1}{m_{c_i}} \sum_{k=1}^{m_{c_i}} X^{(g)}_k, \tag{4}
X(ci)=mci1k=1∑mciXk(g),(4)
其中,
c
i
c_i
ci 表示支持集的第
i
i
i 个粗粒度类别,
m
c
i
m_{c_i}
mci 表示其细粒度类别的数量。接下来,通过以下示例展示支持样本层次特征的计算过程。
示例 1:在图 3 中,展示了一个包含两类粗粒度类别和五类细粒度类别的层次结构,适用于 5-way 1-shot 设置。每个样本的特征包括全局特征和局部特征。该示例的层次特征计算如下:细粒度特征: X ( f i ) = X i ( l ) , 其中 i = 1 , … , 5 X^{(f_i)} = X^{(l)}_i, 其中\quad i = 1, \dots, 5 X(fi)=Xi(l),其中i=1,…,5 ;粗粒度特征: X ( c 1 ) = 1 3 ( X 1 ( g ) + X 2 ( g ) + X 3 ( g ) ) X^{(c_1)} = \frac{1}{3} \left(X^{(g)}_1 + X^{(g)}_2 + X^{(g)}_3\right) X(c1)=31(X1(g)+X2(g)+X3(g)) 以及 X ( c 2 ) = 1 2 ( X 4 ( g ) + X 5 ( g ) ) X^{(c_2)} = \frac{1}{2} \left(X^{(g)}_4 + X^{(g)}_5\right) X(c2)=21(X4(g)+X5(g))

图 3. 支持样本的层次化全局-局部特征提取示例:参数说明: g g g 表示全局特征, l l l 表示局部特征, c c c 表示粗粒度特征, f f f 表示细粒度特征。
3.2. Multi-Granularity Knowledge Fusion and Decision-Making 多粒度知识融合与决策
在分类阶段,许多少样本学习模型采用基于余弦距离或欧几里得距离的度量学习 7 21。此外,Zhang 等人 9 发现,地球移动距离(Earth Mover’s Distance, EMD)更适合利用局部特征的相关性,并能避免复杂背景的影响。然而,仅依赖视觉信息建模容易因为数据稀少而导致过拟合问题。因此,通过在类别的视觉信息与结构知识之间建立强连接与协同作用,我们融合这两类知识以增强少样本学习的最终决策,使模型能够从有限的标注样本中更高效地学习,并泛化到新类别。
具体来说,我们利用地球移动距离来测量查询样本与支持集多粒度特征之间的相似性,并将多粒度相似性融合用于最终的少样本学习决策。地球移动距离通过解决经典的运输问题生成结构元素之间的最优匹配流量,其目标是最小化匹配成本,公式描述如下:给定一组来源
S
=
{
s
i
∣
i
=
1
,
…
,
m
}
S = \{s_i \mid i = 1, \dots, m\}
S={si∣i=1,…,m} 和一组目标
D
=
{
d
j
∣
j
=
1
,
…
,
n
}
D = \{d_j \mid j = 1, \dots, n\}
D={dj∣j=1,…,n},其中
s
i
s_i
si 表示第
i
i
i 个供应单元,
d
j
d_j
dj 表示第
j
j
j 个需求单元,
m
m
m 和
n
n
n 分别是它们的总数量。令从第
i
i
i 个供应商到第
j
j
j 个需求者的单位运输成本为
c
i
j
c_{ij}
cij,运输数量为
x
i
j
x_{ij}
xij。目标是找到最优匹配流量,公式如下:
min
x
i
j
∑
i
=
1
m
∑
j
=
1
n
c
i
j
x
i
j
,
\min_{x_{ij}} \sum_{i=1}^m \sum_{j=1}^n c_{ij} x_{ij},
xijmini=1∑mj=1∑ncijxij,
满足约束条件:
x
i
j
≥
0
,
i
=
1
,
…
,
m
,
j
=
1
,
…
,
n
,
x_{ij} \geq 0, \quad i = 1, \dots, m, \quad j = 1, \dots, n,
xij≥0,i=1,…,m,j=1,…,n,
∑
j
=
1
n
x
i
j
=
s
i
,
i
=
1
,
…
,
m
,
\sum_{j=1}^n x_{ij} = s_i, \quad i = 1, \dots, m,
j=1∑nxij=si,i=1,…,m,
∑
i
=
1
m
x
i
j
=
d
j
,
j
=
1
,
…
,
n
,
(5)
\sum_{i=1}^m x_{ij} = d_j, \quad j = 1, \dots, n, \tag{5}
i=1∑mxij=dj,j=1,…,n,(5)
其中,
X
=
{
x
i
j
∣
i
=
1
,
…
,
m
,
j
=
1
,
…
,
n
}
X = \{x_{ij} \mid i = 1, \dots, m, j = 1, \dots, n\}
X={xij∣i=1,…,m,j=1,…,n} 表示运输流量。
我们使用两个特征向量集合的最佳匹配成本来表示两幅图像之间的相似性。定义
U
=
[
u
1
,
…
,
u
i
,
…
,
u
d
]
U = [u_1, \dots, u_i, \dots, u_d]
U=[u1,…,ui,…,ud] 和
V
=
[
v
1
,
…
,
v
j
,
…
,
v
d
]
V = [v_1, \dots, v_j, \dots, v_d]
V=[v1,…,vj,…,vd] 为两个随机特征集合,其中
U
,
V
∈
R
H
×
W
×
C
U, V \in \mathbb{R}^{H \times W \times C}
U,V∈RH×W×C,
u
i
,
v
j
∈
R
1
×
1
×
C
u_i, v_j \in \mathbb{R}^{1 \times 1 \times C}
ui,vj∈R1×1×C,
d
=
H
×
W
d = H \times W
d=H×W,
C
C
C 为特征维度,
H
H
H 和
W
W
W 分别为特征图的高度和宽度。根据地球移动距离的原始公式 (5),两组特征向量的图像相似性计算如下:
S
(
U
,
V
)
=
∑
i
=
1
d
∑
j
=
1
d
(
1
−
c
i
j
)
,
(6)
S(U, V) = \sum_{i=1}^d \sum_{j=1}^d (1 - c_{ij}), \tag{6}
S(U,V)=i=1∑dj=1∑d(1−cij),(6)
其中
c
i
j
c_{ij}
cij 为单位匹配成本,定义为:
c
i
j
=
1
−
u
i
⊤
v
j
∥
u
i
∥
∥
v
j
∥
,
(7)
c_{ij} = 1 - \frac{u_i^\top v_j}{\|u_i\| \|v_j\|}, \tag{7}
cij=1−∥ui∥∥vj∥ui⊤vj,(7)
相似的特征向量之间产生较小的匹配成本。
然而,不同特征向量之间的相似性可能具有显著差异,这可能对图像相似性度量不利。在图 4 中,
{
u
1
,
u
2
,
u
3
}
\{u_1, u_2, u_3\}
{u1,u2,u3} 和
{
v
1
,
v
2
,
v
3
}
\{v_1, v_2, v_3\}
{v1,v2,v3} 是样本
u
u
u 和
v
v
v 的一些特征子向量。特征子向量
u
1
u_1
u1 和
v
3
v_3
v3,
u
3
u_3
u3 和
v
2
v_2
v2 彼此相似,而
u
3
u_3
u3 和
v
1
v_1
v1 的相似性较低。我们为不同的特征匹配对赋予不同的权重,权重较大的匹配对在图像匹配中起更重要的作用,而权重较小的匹配对对整体匹配成本影响较小。权重由特征向量的点积生成:
w
i
j
=
max
{
u
i
⊤
v
j
,
0
}
,
(8)
w_{ij} = \max\{u_i^\top v_j, 0\}, \tag{8}
wij=max{ui⊤vj,0},(8)
其中
w
i
j
w_{ij}
wij 表示
u
i
u_i
ui 和
v
j
v_j
vj 之间的权重,
max
\max
max 保证权重非负。权重一般归一化处理:
w
^
i
j
=
w
i
j
∑
k
=
1
d
w
k
j
,
(9)
\hat{w}_{ij} = \frac{w_{ij}}{\sum_{k=1}^d w_{kj}}, \tag{9}
w^ij=∑k=1dwkjwij,(9)
其中
w
^
i
j
\hat{w}_{ij}
w^ij 是归一化后的权重。因此,我们结合公式 (6) 和 (9),得到加权的图像相似性:
S
(
U
,
V
)
=
∑
i
=
1
d
∑
j
=
1
d
w
^
i
j
(
1
−
c
i
j
)
.
(10)
S(U, V) = \sum_{i=1}^d \sum_{j=1}^d \hat{w}_{ij} (1 - c_{ij}). \tag{10}
S(U,V)=i=1∑dj=1∑dw^ij(1−cij).(10)
在图像相似性度量中,更高的图像相似性对应更小的匹配成本。同时,权重越大,越有利于图像的相似性度量。
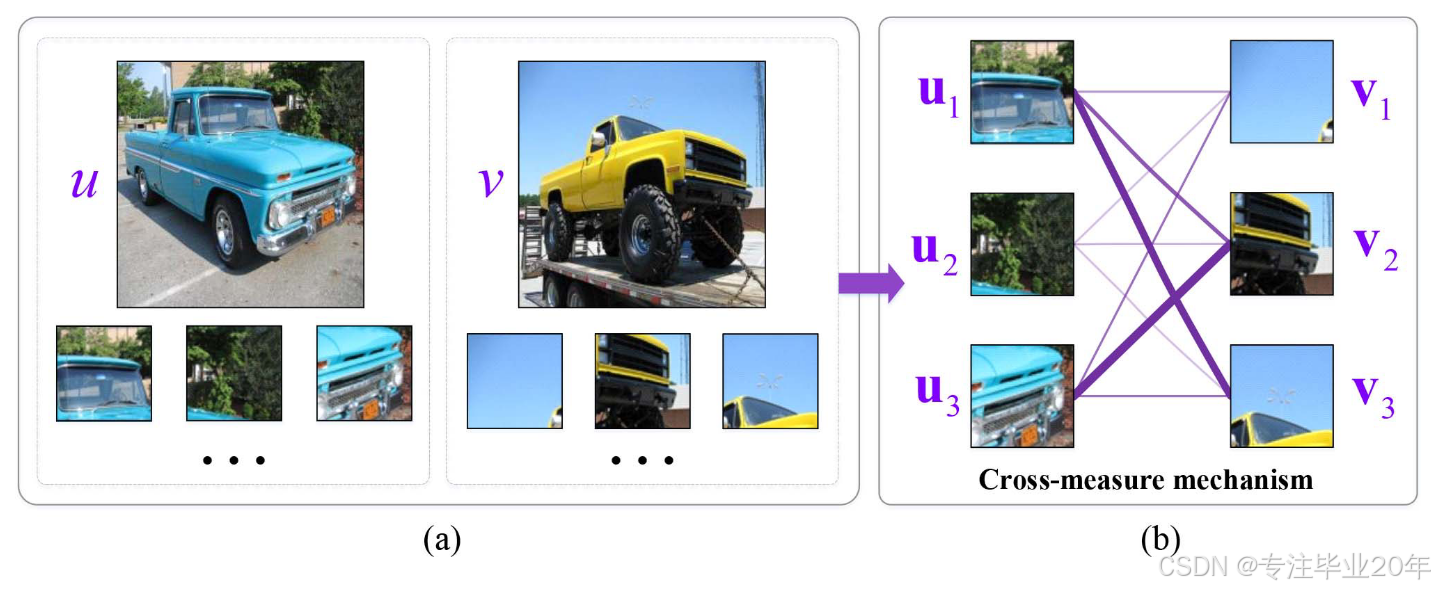
图 4. 特征匹配可视化示例:线条的宽度越粗,表示两幅图像之间的相似性越高。
u
u
u 和
v
v
v 分别表示两幅图像样本,
{
u
1
,
u
2
,
u
3
}
\{u_1, u_2, u_3\}
{u1,u2,u3} 和
{
v
1
,
v
2
,
v
3
}
\{v_1, v_2, v_3\}
{v1,v2,v3} 分别是它们的一些特征子向量。
然后,我们融合多粒度相似性以获得层次相似性,通过粗粒度类别的知识来指导细粒度分类。层次相似性计算公式如下:
S
i
j
(
h
)
=
λ
S
i
j
(
c
)
+
(
1
−
λ
)
S
i
j
(
f
)
,
(11)
S_{ij}^{(h)} = \lambda S_{ij}^{(c)} + (1 - \lambda) S_{ij}^{(f)}, \tag{11}
Sij(h)=λSij(c)+(1−λ)Sij(f),(11)
其中,
c
c
c 表示粗粒度类别,
f
f
f 表示细粒度类别,
S
i
j
(
h
)
S_{ij}^{(h)}
Sij(h) 是查询样本
x
~
i
\tilde{x}_i
x~i 和第
j
j
j 个支持类别之间的层次相似性,
λ
\lambda
λ 是平衡因子。相似性
S
i
j
(
c
)
S_{ij}^{(c)}
Sij(c) 和
S
i
j
(
f
)
S_{ij}^{(f)}
Sij(f) 分别表示粗粒度和细粒度的相似性,其计算如下:
S
i
j
(
c
)
=
S
(
X
~
(
c
i
)
,
X
(
c
j
)
)
,
S
i
j
(
f
)
=
S
(
X
~
(
f
i
)
,
X
(
f
j
)
)
,
(12)
\begin{aligned} S_{ij}^{(c)} &= S(\tilde{X}^{(c_i)}, X^{(c_j)}), \\ S_{ij}^{(f)} &= S(\tilde{X}^{(f_i)}, X^{(f_j)}), \tag{12} \end{aligned}
Sij(c)Sij(f)=S(X~(ci),X(cj)),=S(X~(fi),X(fj)),(12)
其中,
X
~
(
c
i
)
\tilde{X}^{(c_i)}
X~(ci) 和
X
~
(
f
i
)
\tilde{X}^{(f_i)}
X~(fi) 分别是查询样本
x
~
i
\tilde{x}_i
x~i 的粗粒度和细粒度特征;
X
(
f
j
)
X^{(f_j)}
X(fj) 是第
j
j
j 个支持类别的细粒度特征,
X
(
c
j
)
X^{(c_j)}
X(cj) 是其所属的粗粒度特征。通过融合多粒度知识,我们根据获得的层次相似性进行最终分类决策。具有最高层次相似性的支持细粒度类别即为查询样本的预测类别。
我们利用交叉熵损失计算分类损失,其公式如下:
L
=
−
1
n
q
∑
i
=
1
n
q
∑
j
=
1
N
y
i
j
log
(
exp
(
−
S
i
j
(
h
)
)
∑
k
=
1
N
exp
(
−
S
i
k
(
h
)
)
)
,
(13)
L = -\frac{1}{n_q} \sum_{i=1}^{n_q} \sum_{j=1}^{N} y_{ij} \log\left(\frac{\exp(-S_{ij}^{(h)})}{\sum_{k=1}^{N} \exp(-S_{ik}^{(h)})}\right), \tag{13}
L=−nq1i=1∑nqj=1∑Nyijlog(∑k=1Nexp(−Sik(h))exp(−Sij(h))),(13)
其中,当查询样本
x
~
i
\tilde{x}_i
x~i 的真实类别为第
j
j
j 类时,
y
i
j
=
1
y_{ij} = 1
yij=1,否则
y
i
j
=
0
y_{ij} = 0
yij=0;
S
i
j
(
h
)
S_{ij}^{(h)}
Sij(h) 是查询样本
x
~
i
\tilde{x}_i
x~i 和第
j
j
j 个支持类别之间的层次相似性;
n
q
n_q
nq 表示所有查询样本的数量,
N
N
N 表示每个
N
N
N-way
K
K
K-shot 任务中的类别数。
然而,标准交叉熵损失函数采用 one-hot 策略,将所有分类错误视为等同,仅定义预测结果为正确或错误两种情况。例如,无论查询样本被错误分类为 Bear 还是 Butterfly,其分类错误被认为是相同的,如图 5(a) 所示。但实际上,分类错误是有区别的。图 5(b) 提供了一个直观的解释。与类 Butterfly 相比,根据支持类别的层次结构,类 Bear 更接近类 Panda,因为 Bear 和 Panda 都属于粗粒度类别 Mammal,而 Butterfly 属于 Insect。从类别之间的关系来看,将查询样本分类为 Butterfly 的错误程度高于分类为 Bear 的错误程度。
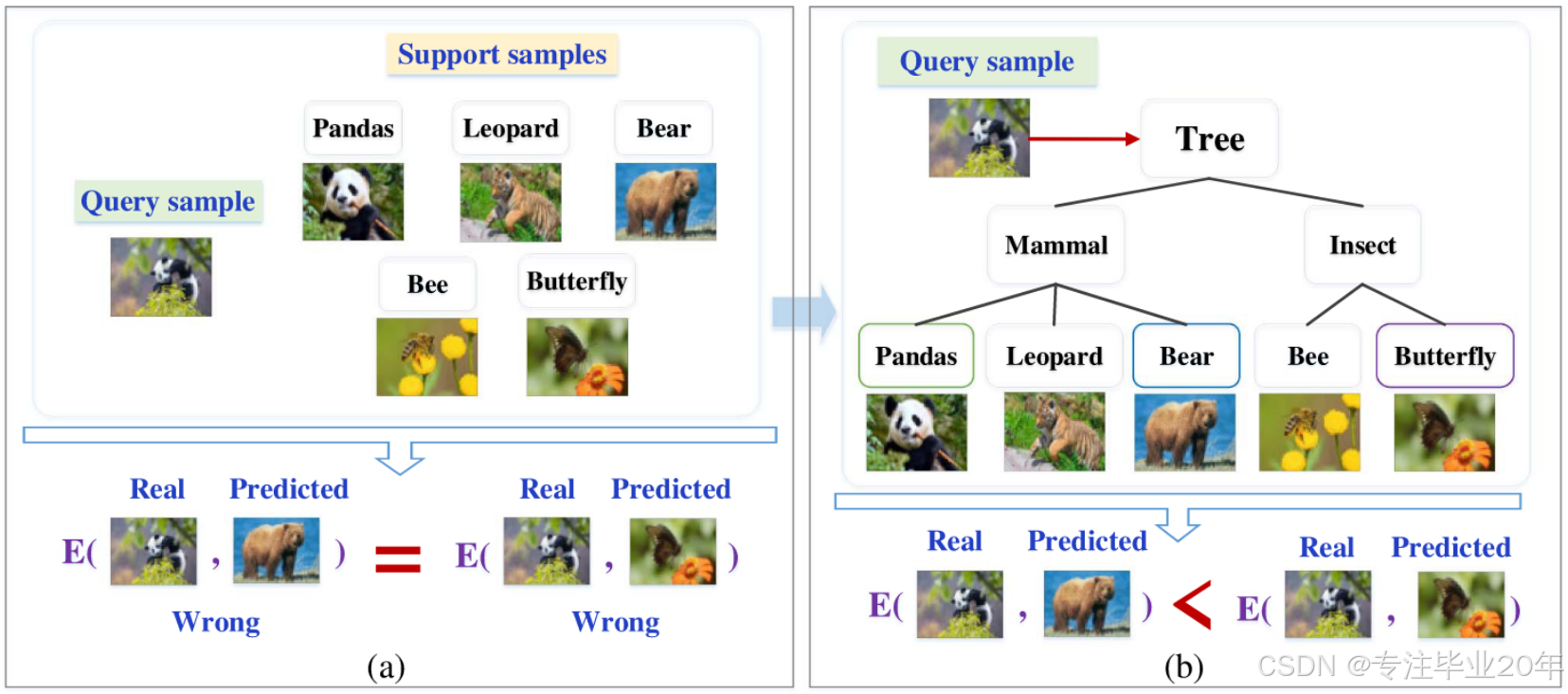
图 5. 不同分类错误:
E
(
⋅
,
⋅
)
E(\cdot, \cdot)
E(⋅,⋅) 表示分类错误的程度。
因此,我们设计了一种层次化损失函数,利用层次结构对分类结果进行不同的加权。不同的分类错误会导致不同程度的惩罚。我们引入了树诱导误差(Tree Induced Error, TIE)来衡量分类错误的风险。TIE 通过计算从真实类别到预测类别在层次结构中经过的边数,来反映样本的错误分类程度。其形式化表示如下:
TIE ( y ~ i , y j ) = ∣ E H ( y ~ i , y j ) ∣ , (14) \text{TIE}(\tilde{y}_i, y_j) = |\mathcal{E}_H(\tilde{y}_i, y_j)|, \tag{14} TIE(y~i,yj)=∣EH(y~i,yj)∣,(14)
其中, y ~ i \tilde{y}_i y~i 是查询样本 x ~ i \tilde{x}_i x~i 的真实类别, y j y_j yj 是其预测类别; E H ( y ~ i , y j ) \mathcal{E}_H(\tilde{y}_i, y_j) EH(y~i,yj) 表示从 y ~ i \tilde{y}_i y~i 到 y j y_j yj 的路径上的边集, ∣ ⋅ ∣ | \cdot | ∣⋅∣ 表示集合中元素的数量。
然后,我们定义分类错误的权重为:
t i j = TIE ( y ~ i , y j ) max TIE ( y ~ i , ∗ ) , (15) t_{ij} = \frac{\text{TIE}(\tilde{y}_i, y_j)}{\max \text{TIE}(\tilde{y}_i, \ast)}, \tag{15} tij=maxTIE(y~i,∗)TIE(y~i,yj),(15)
其中, t i j t_{ij} tij 是当查询样本 x ~ i \tilde{x}_i x~i 被分类为第 j j j 类时的分类错误权重, max TIE ( y ~ i , ∗ ) \max \text{TIE}(\tilde{y}_i, \ast) maxTIE(y~i,∗) 表示预测类别与 x ~ i \tilde{x}_i x~i 的真实类别 y ~ i \tilde{y}_i y~i 之间的最大 TIE。
示例 2:在图 6 中,Predicted 1 和 Predicted 2 是查询样本的两种分类结果。如图所示: TIE ( y 0 , y 1 ) = 0 , TIE ( y 0 , y 3 ) = 2 , TIE ( y 0 , y 5 ) = 4 , max TIE ( y 0 , ∗ ) = 4. \begin{aligned}\text{TIE}(y_0, y_1) &= 0, \text{TIE}(y_0, y_3) &= 2, \text{TIE}(y_0, y_5) &= 4, \max \text{TIE}(y_0, \ast) &= 4.\end{aligned} TIE(y0,y1)=0,TIE(y0,y3)=2,TIE(y0,y5)=4,maxTIE(y0,∗)=4.,对应的权重计算如下: t 01 = 0 4 = 0 , t 03 = 2 4 = 1 2 , t 05 = 4 4 = 1. t_{01} = \frac{0}{4} = 0, \quad t_{03} = \frac{2}{4} = \frac{1}{2}, \quad t_{05} = \frac{4}{4} = 1. t01=40=0,t03=42=21,t05=44=1.。其中, TIE ( y 0 , y 1 ) = 0 \text{TIE}(y_0, y_1) = 0 TIE(y0,y1)=0 表示分类正确; t 03 < t 05 t_{03} < t_{05} t03<t05 表示将查询样本分类为 Predicted 1 的分类错误程度小于分类为 Predicted 2 的分类错误程度。

图 6. 分类错误风险权重计算示例:不同颜色的箭头表示不同类别之间的路径。
结合公式 (13) 和 (15),我们得到层次化损失函数
L
h
L_h
Lh,其表示如下:
L
h
=
−
1
n
q
∑
i
=
1
n
q
∑
j
=
1
N
(
1
+
t
i
j
)
y
i
j
log
(
exp
(
−
S
i
j
(
h
)
)
∑
k
=
1
N
exp
(
−
S
i
k
(
h
)
)
)
,
(16)
L_h = -\frac{1}{n_q} \sum_{i=1}^{n_q} \sum_{j=1}^{N} (1 + t_{ij}) y_{ij} \log\left(\frac{\exp(-S_{ij}^{(h)})}{\sum_{k=1}^{N} \exp(-S_{ik}^{(h)})}\right), \tag{16}
Lh=−nq1i=1∑nqj=1∑N(1+tij)yijlog(∑k=1Nexp(−Sik(h))exp(−Sij(h))),(16)
其中,当查询样本
x
~
i
\tilde{x}_i
x~i 的真实类别为第
j
j
j 类时,
y
i
j
=
1
y_{ij} = 1
yij=1,否则
y
i
j
=
0
y_{ij} = 0
yij=0。当权重
t
i
j
=
0
t_{ij} = 0
tij=0 时,层次化损失退化为标准的交叉熵损失。
算法 1 描述了MGKFD 训练过程。特别是在训练之前,我们通过 WordNet 获取不同数据集的层次类别结构(我们使用从公开可访问数据集中构建的层次结构)。根据层次类别结构,我们将所有类别定义为细粒度类别,并获取其对应的粗粒度类别。然后在第 5–10 行中提取查询集和支持集的多粒度特征。接着,在第 12–14 行中融合多粒度知识以获得层次相似性,并做出最终分类决策。然后,在第 15–17 行中根据结构通过 TIE 计算分类错误的权重并更新层次化损失。最后,通过反向传播层次化损失更新参数
ϕ
\phi
ϕ。

4. EXPERIMENTAL SETTINGS
4.1. Implementation Details
在实验中,我们使用 ResNet12 作为网络骨干,并采用 SGD 作为优化器,遵循最近的少样本分类研究 9 21。与先进文献中的常见实现类似,我们采用特征预训练步骤来训练网络 9。我们将区域长度设置为全局特征长度的一半。参数 λ \lambda λ 的值在 tieredImageNet 数据集上设置为 0.4,在 FC100 和 CIFAR-FS 数据集上设置为 0.6。所有图像均调整为大小 84 × 84 × 3 84 \times 84 \times 3 84×84×3。在测试阶段,我们从测试集中随机选择 5,000 个任务样本,并计算 95% 的置信区间。实验在 GeForce RTX 2080 Ti Nvidia GPU 和 Pytorch 环境下进行。所提出模型使用的代码和数据集将开源至 GitHub(https://github.com/fhqxa/MGKFD)。
4.2. Datasets
在少样本学习(FSL)实验中,我们使用了三个常用的基准数据集:tieredImageNet 26、FC100 27 和 CIFAR-FS 28。这些数据集的基本统计信息如下:
-
tieredImageNet 26 是一个源自 ILSVRC-12 数据集的少样本子数据集,总共包含 779,765 张图像。其中包括 608 个细粒度类别和 34 个粗粒度类别。训练/验证/测试集的划分分别包含 20/6/8 个粗粒度类别,这些粗粒度类别是 351/97/160 个细粒度类别的上位集。
-
FC100 27 是一个流行的少样本分类数据集,由 CIFAR100 构建而成。它包含 100 个细粒度类别和 20 个粗粒度类别。训练/验证/测试集的划分分别包含 12/4/4 个粗粒度类别,这些粗粒度类别是 60/20/20 个细粒度类别的上位集。其层次结构如图 7 所示。
-
CIFAR-FS 28 同样源自 CIFAR100 数据集,与 FC100 类似。它包含 100 个细粒度类别和 20 个粗粒度类别。训练/验证/测试集的划分分别包含 20/11/13 个粗粒度类别,对应于 64/16/20 个细粒度类别。这些粗粒度类别是共享的。

图 7. FC100 的层次结构:展示了 FC100 数据集的训练集、验证集和测试集的层次结构。
4.3. Evaluation Measures
我们采用五种评估指标来验证模型的有效性:分类准确率(ACC)、曲线下面积(AUC)、F1 分数(F1)、树诱导误差(TIE)和层次化 F1 分数(FH)。其中,TIE 和 FH 用于层次分类模型的评估。
层次化 F1 分数(FH)是层次化精确率(PH)和层次化召回率(RH)的联合计算,公式如下:
P H = ∣ D ^ a u g ∩ D a u g ∣ ∣ D ^ a u g ∣ , R H = ∣ D ^ a u g ∩ D a u g ∣ ∣ D a u g ∣ , P_H = \frac{| \hat{D}_{aug} \cap D_{aug} |}{| \hat{D}_{aug} |}, \quad R_H = \frac{| \hat{D}_{aug} \cap D_{aug} |}{| D_{aug} |}, PH=∣D^aug∣∣D^aug∩Daug∣,RH=∣Daug∣∣D^aug∩Daug∣,
其中, D ^ a u g \hat{D}_{aug} D^aug 包含预测类别及其祖先节点, D a u g D_{aug} Daug 表示真实类别及其祖先节点。
层次化 F1 分数(FH)的计算公式为:
F H = 2 P H R H P H + R H . F_H = \frac{2 P_H R_H}{P_H + R_H}. FH=PH+RH2PHRH.
5. EXPERIMENTAL RESULTS AND ANALYSIS
在本节中,我们进行了多项消融研究、对比实验以及可视化分析,以验证和分析 MGKFD 的有效性。为了便于撰写和理解,我们将一些专有名词设置为缩写如下:
- 全局与局部特征: g − l g-l g−l
- 多粒度知识融合与决策:KFD
- 层次化损失:HL
- 均方误差损失:MSE
- 交叉熵损失:CE
5.1. Ablation Studies
5.1.1. 验证多粒度知识融合与决策策略
通过在全局与局部视觉信息和多粒度类别知识之间建立强连接与协同作用,我们融合这两类知识以增强少样本学习(FSL)的最终决策。我们在 tieredImageNet 和 FC100 数据集上构建了消融实验,以验证每个组件的作用。不同组件的性能如图 8 所示,我们发现:
- 每个组件都对多粒度策略有益。
- 通过划分全局与局部特征,我们在两个数据集上分别获得了 71.94% 和 44.33% 的准确率(ACC),相比基线分别提高了约 1.20% 和 0.70%。
- 同样,KFD 相较于基线分别提升了约 1.00% 和 0.40%。
- 此外,通过结合这两种策略,我们的模型性能得到更大的提升。
实验结果验证了全局与局部信息的结合以及多粒度知识的融合对细粒度类别的分类具有重要帮助。
为了直观展示 KFD 的有效性,我们在 tieredImageNet 数据集上可视化了 KFD 的不同推理结果,分类可视化如图 9 所示。可以发现,在粗粒度类别的帮助下,细粒度类别的最终预测得到了纠正。例如,原本真实类别为 Beer bottle 的样本被错误分类为 Eggnog,但在粗粒度类别的影响下被正确分类为 Beer bottle。这证明了类别的多粒度关联在 MGKFD 的分类能力中起到了积极和指导作用。

图 8. KFD 不同组件在 tieredImageNet 和 FC100 数据集上的准确率(ACC,%):结果基于 5-way 1-shot 设置。

图 9. MGKFD 在 tieredImageNet 数据集上的分类可视化
5.1.2. 验证层次化损失(HL)
我们验证了 HL 的效果,并与其他损失函数(包括均方误差 MSE 和交叉熵 CE)进行了比较。我们采用三个评估指标来估计模型性能。性能比较结果如表 I 所示,主要结论如下:

表 1 MGKFD 在不同数据集上使用不同损失函数的 ACC(%)(5-Way 1-Shot)
最佳结果以加粗形式标记。ACC(
↑
\uparrow
↑)、TIE(
↓
\downarrow
↓)和
F
H
F_H
FH(
↑
\uparrow
↑)。“
↑
\uparrow
↑”表示值越大性能越好,“
↓
\downarrow
↓”表示值越小性能越好。
- 采用 HL 时性能有所提升,相比使用 MSE 和 CE 的改进更明显。具体而言,使用 HL 时,在 tieredImageNet 和 FC100 数据集上的准确率(ACC)分别比使用 MSE 提高了约 0.50% 和 0.90%,与 FH 指标的表现相似。这表明层次化损失提升了模型的分类能力。
- HL 可以使 MGKFD 具有较低的错误判断程度。TIE 值反映了模型的分类错误程度。使用 HL 的 MGKFD 的 TIE 值小于使用 MSE 和 CE 的模型,突显了通过应用 TIE 以不同权重最小化分类损失的好处。
5.1.3. 验证提出的不同组件
我们通过消融研究验证了 MGKFD 的各个组件,包括全局与局部特征的划分、多粒度知识融合与决策(KFD)、以及层次化损失(HL)。在 tieredImageNet 和 FC100 数据集上的主要实验结果列于表 III,以下是主要结论:

***表 2 不同组件在 MGKFD 中对不同数据集 ACC(%)的贡献(5-Way 1-Shot)
最佳结果以加粗形式标记 ***
- 实验结果表明,这些关键组件在模型中的使用是有效的。KFD + g − l g-l g−l 的效果优于 HL。在 MGKFD 中,使用 HL 相较于基线分别提高了 0.60% 和 0.20%。此外,通过 KFD + g − l g-l g−l,在两个数据集上的改进分别达到了 1.70% 和 1.00%。
- KFD 和 HL 在 tieredImageNet 上的改进通常大于在 FC100 上的改进。可能的原因是 KFD 和 HL 的效果与数据的类别层次树相关。tieredImageNet 的类别规模比 FC100 更大,提供了更丰富的类别信息,有助于模型训练。
- 同时使用这三个组件时,MGKFD 在两个数据集上的 ACC 分别达到了 72.48% 和 44.86%,相比基线分别提升了约 2.00% 和 1.20%。MGKFD 在使用所有组件时最为有效。两个数据集上的一致改进实验证明了我们关于联合优化层次结构知识与全局和局部视觉信息对 FSL 有益的论点。
5.1.4. 参数分析
我们采用权重聚合技术 λ \lambda λ 来融合多粒度知识与全局和局部视觉信息以进行分类决策(如公式 (11))。参数的变化表示粗粒度与细粒度知识融合的程度。我们在实验中使用了三个评估指标,性能结果如表 III 和图 10 所示。主要结论如下:

表 3 不同
λ
\lambda
λ 值在不同数据集上的 ACC 和
F
H
F_H
FH(%,
↑
\uparrow
↑)(5-Way 1-Shot)
“
↑
\uparrow
↑”表示值越大性能越好。最佳结果以加粗形式标记。
- 较大的 ACC 和 FH 值意味着模型性能更优,而较小的 TIE 值表明模型的分类错误程度较低。
- 我们注意到,在 tieredImageNet 和 FC100 上分别设置 λ = 0.4 \lambda = 0.4 λ=0.4 和 λ = 0.6 \lambda = 0.6 λ=0.6 时性能最佳。这表明,在适当的 λ \lambda λ 值下,粗粒度类别表示和判别性知识由于与细粒度类别具有强语义关系,可以有助于细粒度类别的学习。

图 10 不同
λ
\lambda
λ 值在不同数据集上的 TIE(
↓
\downarrow
↓)。“
↓
\downarrow
↓” 表示值越小越好。(a) tieredImageNet,(b) FC100。
5.2. Performance Comparison
我们对 MGKFD 与多个先进 FSL 模型进行了比较。选取了以下四种类型的比较模型:
- 单尺度-全局:基于全局视觉特征建模。
- 单尺度-局部:基于局部视觉特征建模。
- 多尺度:基于全局和局部视觉特征建模。
- 多粒度:基于层次类别结构的多粒度知识建模。
前三种方法致力于挖掘全局和局部信息以提升模型性能,第四种方法主要聚焦于嵌入类别结构知识而忽略了视觉信息的学习。而 MGKFD 旨在同时探索这两类知识,以协同方式提升 FSL 的性能。在 tieredImageNet、FC100 和 CIFAR-FS 三个数据集上的实验结果如表 IV 和表 V 所示。我们可以得出以下观察结论:

***表 4 不同模型在 tieredImageNet 上的准确率比较(ACC%)
最佳结果以加粗形式标记 ***

***表 5 不同平面模型在 FC100 和 CIFAR-FS 上的准确率比较(ACC%)
最佳结果以加粗形式标记 ***
-
MGKFD 优于大多数单尺度和多尺度模型
- 相较于单尺度方法,多尺度和多粒度方法在处理有限数据时具有天然优势,因为它们整合了更多信息。在 1-shot 设置下,MGKFD 在 tieredImageNet 上达到了 72.78% 的准确率(ACC),分别比 RFS-simple 和 infoPatch 提高了约 3.00% 和 1.30%。
- 与随机遮挡部分图像以聚焦局部对象的 infoPatch 不同,我们重新将全局特征提取为五个局部特征,并交叉测量以减少背景知识的干扰。
- 与 MSML 的高低层次多尺度特征相比,我们的多粒度全局-局部特征表现出更大的优势。
-
在多粒度策略下,MGKFD 显示出相对于大多数模型的优势
- wDAE-GNN 通过采用图结构构建类别关联表现良好,而我们的模型通过层次结构中的多粒度类别关系获得了更好的收益。
- 尽管 HMRN 和 HGNN 也使用了层次类别结构作为辅助知识,但我们的模型在分类能力上仍优于它们。然而,在 5-shot 设置下,MGKFD 略逊于 MGECL。
- 原因可能在于 MGECL 采用了对比学习来学习区分性特征,当样本数量不是非常少时,这种方法更加适用。
总结而言,通过融合视觉信息与结构知识以进行分类决策,MGKFD 能够使模型从有限的标注样本中高效学习,并对新类别实现更高的泛化准确率。
为了计算复杂度分析,我们的模型采用了一种常见的卷积网络架构,与大多数现有模型(例如 16, 21, 29)一致。基于 9 的方法,我们的主要工作集中在推理阶段,并通过提出的特定损失函数训练该架构,而无需添加任何新网络。通过公式计算,多粒度知识嵌入的时间几乎可以忽略不计。因此,我们的模型与这些现有模型共享相同的算法复杂度。
此外,这允许我们将 MGKFD 转移到类似 9 的其他模型中,例如 7, 21,因为我们的主要贡献在于推理步骤和损失设计。
5.3. Visualization
我们采用 T-SNE 技术展示了测试视觉特征在使用 MGKFD 训练前后的分布情况,如图 11 所示。主要观察如下:

图 11. tieredImageNet 数据集上的 t-SNE 可视化(5-way 1-shot)。数字 0-4 表示不同的细粒度类别。类别 0 和类别 3 属于同一粗粒度类别,其余类别属于各自独立的粗粒度类别。
- 全局特征:
使用全局特征时,不同类别之间的边界更加清晰,并且属于同一粗粒度类别的类比基线更加紧凑。 - 局部特征:
图 11© 中显示,使用局部特征时,每个类别的分类边界更加明显,类别内部的距离减小。这表明,全局与局部特征的结合以及多粒度类别可以获得更具区分性的特征嵌入。
此外,我们使用热图可视化了 MGKFD 的空间对应性,主要结果如图 12 和图 13 所示。可以观察到,在空间关系方面,我们的模型优于基线模型。MGKFD 在不同场景下通过削弱显著背景的影响,更准确地覆盖了目标对象。

图 12. MGKFD 与基线模型的热图视觉比较。
6. CONCLUSION AND FUTURE WORK
在本文中,我们提出了一种基于多粒度知识融合与决策(MGKFD)的统一少样本学习(FSL)框架。该框架同时考虑了丰富的视觉信息和强大的类别结构知识,以协同方式增强 FSL。通过结合全局和局部特征,利用多粒度知识获取更具区分性的类别特征,从有限数据中更高效地挖掘信息。多粒度知识融合与决策用于整合多粒度知识,从而做出最终的少样本分类决策。由于粗粒度的表示和判别性知识有助于细粒度的学习。此外,我们设计了一种层次化损失,以权衡不同的分类结果,最小化分类损失,同时考虑预测类别与真实类别之间的相关性。我们使用三个评估指标,在三个流行的少样本数据集上验证了 MGKFD 的有效性。实验结果表明,MGKFD 的性能可与多个先进的少样本学习模型相媲美。
MGKFD 存在一些局限性,这将成为未来研究的重点:
- 多粒度知识融合步骤:在不同数据集上调整不同粒度的权重是一个耗时的过程。我们将在未来专注于设计一种自适应融合策略,以自动选择最佳权重。
- 层次结构的局限性:层次结构是一种相对固定的知识形式,其泛化能力有限。而知识图谱涵盖了更广泛的对象和领域,拥有丰富的知识和增强的泛化能力。在未来的工作中,我们将进一步挖掘知识图谱中的丰富连接和信息,以指导少样本学习。

图 13. 不同场景下 MGKFD 的热图可视化。
B. Lake, R. Salakhutdinov, J. Gross, and J. Tenenbaum, “One shot learning of simple visual concepts,” in Proc. Annu. Meeting Cogn. Sci. Soc., 2011, pp. 2568–2573. ↩︎
E. G. Miller, N. E. Matsakis, and P. A. Viola, “Learning from one example through shared densities on transforms,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2000, pp. 464–471. ↩︎
M. A. Jamal and G. J. Qi, “Task agnostic meta-learning for few-shot learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2019, pp. 11711–11719. ↩︎
X. Li, L. Yu, C. Fu, M. Fang, and P. Heng, “Revisiting metric learning for few-shot image classification,” Neurocomputing, vol. 406, pp. 49–58, 2020. ↩︎
Y. Wang, Q. Yao, J. Kwok, and L. Ni, “Generalizing from a few examples: A survey on few-shot learning,” ACM Comput. Surv., vol. 53, no. 3, pp. 1–34, 2020. ↩︎ ↩︎
O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” in Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 3637–3645. ↩︎ ↩︎
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 4080–4090. ↩︎ ↩︎ ↩︎ ↩︎
F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. S. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 1199–1208. ↩︎ ↩︎
C. Zhang, Y. Cai, G. Lin, and C. Shen, “DeepEMD: Few-shot image classification with differentiable Earth mover’s distance and structured classifiers,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2020, pp. 12200–12210. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
W. Jiang, K. Huang, J. Geng, and X. Deng, “Multi-scale metric learning for few-shot learning,” IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 3, pp. 1091–1102, Mar. 2021. ↩︎ ↩︎ ↩︎ ↩︎
X. Li, J. Wu, Z. Sun, Z. Ma, J. Cao, and J. H. Xue, “BSNet: Bi-similarity network for few-shot fine-grained image classification,” IEEE Trans. Image Process., vol. 30, pp. 1318–1331, 2021. ↩︎ ↩︎ ↩︎ ↩︎
S. Fu et al., “Adaptive multi-scale transductive information propagation for few-shot learning,” Knowl.-Based Syst., vol. 249, 2022, Art. no. 108979. ↩︎ ↩︎
H. Chen, R. Liu, Z. Xie, Q. Hu, J. Dai, and J. Zhai, “Majorities help minorities: Hierarchical structure guided transfer learning for few-shot fault recognition,” Pattern Recognit., vol. 123, 2022, Art. no. 108383. ↩︎
H. Zhao, Q. Hu, P. Zhu, Y. Wang, and P. Wang, “A recursive regularization based feature selection framework for hierarchical classification,” IEEE Trans. Knowl. Data Eng., vol. 33, no. 7, pp. 2833–2846, Jul. 2021. ↩︎ ↩︎ ↩︎
A. Li, T. Luo, Z. Lu, T. Xiang, and L. Wang, “Large-scale few-shot learning: Knowledge transfer with class hierarchy,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2019, pp. 7205–7213. ↩︎ ↩︎
P. Zhu, Z. Zhu, Y. Wang, J. Zhang, and S. Zhao, “Multi-granularity episodic contrastive learning for few-shot learning,” Pattern Recognit., vol. 131, 2022, Art. no. 108820. ↩︎ ↩︎ ↩︎
L. Liu, T. Zhou, G. Long, J. Jiang, and C. Zhang, “Many-class few-shot learning on multi-granularity class hierarchy,” IEEE Trans. Knowl. Data Eng., vol. 34, no. 05, pp. 2293–2305, May 2022. ↩︎ ↩︎ ↩︎
B. Zhang et al., “MetaDT: Meta decision tree with class hierarchy for interpretable few-shot learning,” IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 6, pp. 2826–2838, Jun. 2023. ↩︎ ↩︎
R. Feng et al., “Interactive few-shot learning: Limited supervision, better medical image segmentation,” IEEE Trans. Med. Imag., vol. 40, no. 10, pp. 2575–2588, Oct. 2021. ↩︎
K. Lee, S. Maji, A. Ravichandran, and S. Soatto, “Meta-learning with differentiable convex optimization,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2019, pp. 10649–10657. ↩︎ ↩︎
D. Kang, H. Kwon, J. Min, and M. Cho, “Relational embedding for fewshot classification,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2021, pp. 8822–8833. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
C. Chen, K. Li, W. Wei, J. T. Zhou, and Z. Zeng, “Hierarchical graph neural networks for few-shot learning,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 1, pp. 240–252, Jan. 2022. ↩︎
M. Zhang, S. Huang, W. Li, and D. Wang, “Tree structure-aware fewshot image classification via hierarchical aggregation,” in Proc. Eur. Conf. Comput. Vis., 2022, pp. 453–470. ↩︎
S. Wang, X. Chen, Y. Wang, M. Long, and J. Wang, “Progressive adversarial networks for fine-grained domain adaptation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2020, pp. 9210–9219. ↩︎
Y. Wang et al., “Coarse-to-fine: Progressive knowledge transfer-based multitask convolutional neural network for intelligent large-scale fault diagnosis,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 2, pp. 761–774, Feb. 2023. ↩︎ ↩︎
M. Ren et al., “Meta-learning for semi-supervised few-shot classification,” in Proc. 6th Int. Conf. Learn. Representations, 2018, pp. 1–11. ↩︎ ↩︎ ↩︎
B. Oreshkin, P. Rodriguez, and A. Lacoste, “TADAM: Task dependent adaptive metric for improved few-shot learning,” in Proc. Adv. Neural Inf. Process. Syst., 2018, pp. 719–729. ↩︎ ↩︎
L. Bertinetto, J. F. Henriques, P. H. S. Torr, and A. Vedaldi, “Meta-learning with differentiable closed-form solvers,” in Proc. Int. Conf. Learn. Representations, 2019, pp. 1–13. ↩︎ ↩︎
C. Liu et al., “Learning a few-shot embedding model with contrastive learning,” in Proc. AAAI Conf. Artif. Intell., 2021, pp. 8635–8643. ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









